deepdive中文关系提取
参考链接:
https://github.com/SongRb/DeepDiveChineseApps
https://github.com/qiangsiwei/DeepDive_Chinese
https://github.com/mcavdar/deepdive/commit/6882178cbd38a5bbbf4eee8b76b1e215537425b2
本文主要记录下提取流程,和遇到的一些坑。。。
1,deepdive中文相关代码和网址
https://github.com/SongRb/DeepDiveChineseApps
https://github.com/qiangsiwei/DeepDive_Chinese
https://github.com/mcavdar/deepdive/commit/6882178cbd38a5bbbf4eee8b76b1e215537425b2
2,下载该路径下代码
https://github.com/SongRb/DeepDiveChineseApps
数据库配置:
执行echo "postgresql://postgres:******@localhost:5432/deepdive_spouse_postgres" >db.url (******对应数据库密码)
即将数据库配置写入db.url
3, 中文NLP工具配置:
1)下载斯坦福中文工具stanford-chinese-corenlp-2016-01-19-models.jar和 stanford-srparser-2014-10-23-models.jar放到udf/bazzar/parser/lib/路径下
2)在udf/bazzar/parser/下再次执行sbt/sbt stage来重建NLP工程,这会重新编译新增的斯坦福中文JAR包
3)命令行./run.sh -p 8080,之后可以在8080端口测试该NLP相关功能
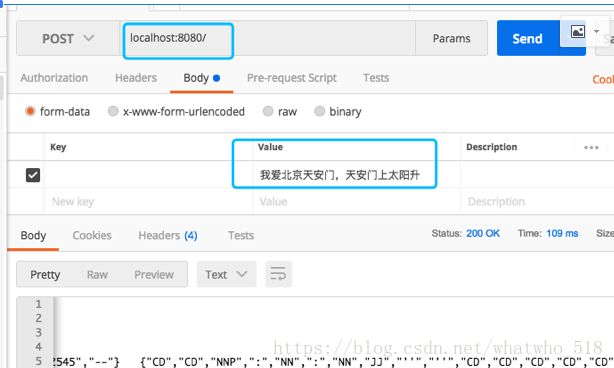
4,原始文本导入:
在路径 */DeepDiveChineseApps-master/spouse/下编译工程: ~/local/bin/deepdive
导入原始文本文件: ~/local/bin/deepdive create table articles ~/local/bin/deepdive load articles input/news-100.tsv.bz2
5,中文NLP处理:
将原始文本拆分成句子,再进行分词,词性标注、命名实体识别等工作
1) ~/local/bin/deepdive do sentences
input/news-100.tsv拷贝为input/articles.tsv
因为内部配置导入的的原始文本为articles.tsv,所以直接执行会报错" [ERROR] input/articles.*: No data source found for articles ‘run/ABORTED’ -> ‘20180305/104532.107734000’"
6,提取每句话中出现的人名
~/local/bin/deepdive compile && ~/local/bin/deepdive do person_mention
这里会从每句话中提取命名实体识别为person的词
7,生成候选配偶对
这里会提取每一句话中出现的两个人名作为spouse的候选样本
~/local/bin/deepdive compile && ~/local/bin/deepdive do spouse_candidate
8, 候选配偶对生成特征
~/local/bin/deepdive compile && ~/local/bin/deepdive do spouse_feature
9,远距离监督对候选配偶对进行标记
1)方案一:使用已标记样本对候选配偶对标记
即对于标记样本中出现的候选配偶对直接进行标记
~/local/bin/deepdive create table spouses_dbpedia~/local/bin/deepdive load spouses_dbpedia input/spouse_dbpedia.csv.bz2
2)方案二:使用简单的启发式规则来进行远距离监督对候选配偶对标记
使用已标记样本训练模型,对所有的候选配偶对spouse_candidate进行标记
~/local/bin/deepdive compile && ~/local/bin/deepdive do has_spouse
这一步已经得到了部分正例和部分反例,以及部分未标记样本

10,使用模型进行学习和推理
根据has_spouse里的标记信息,训练一个分类器,使用分类器进行分类得到结果概率。
~/local/bin/deepdive compile && ~/local/bin/deepdive do probabilities
11,deepdive总结:
1)关系提取流程
通过目标关系,使用NLP相关技术,对原始文本提取候选关系对,并生成特征;
通过手工标注关系对或者通过启发式规则得到标注关系对,训练分类器,得到分类结果,结果正例即是目标关系对,结果为反例即非目标关系对。
articles->sentences->person_mention->spouse_candidate->spouse_feature
spouses_dbpedia->has_spouse->probabilities
2)相关配置文件
- app.ddlog是deepdive的规划文件,此文件定义了数据的来源,数据的结构,数据的处理函数,KBC的构建。
(函数的定义:function nlp_markup over,函数的执行sentences += nlp_markup(doc_id, content) :- articles(doc_id, content). #函数执行,输入为 articles(doc_id, content).即articles表的doc_id字段和content字段)
- db.url,此文件定义了数据库的连接信息
- deepdive.conf deepdive环境配置,不用修改。
- input/ ,此目录放置数据文件,该数据文件需要按照app.ddlog中的规则来命名,该数据文件为应用提供源数据。
- udf/ ,存放用户定义的函数的目录,可以从deepdive.conf引用相对于应用程序根目录的路径名。
3)相关组件
NLP处理组件:应该可以替换,但是内部接口不清楚,斯坦福英文替换为斯坦福中文
生成特征组件:无法替换
推理模型:使用的是因子图模型,提供因子图权重手动设置和自动学习,无法替换