二分匹配和一般图匹配
目录
- 二分匹配
- 匈牙利算法
- 练习
- 1
- 2
- 最小覆盖
- 练习
- 1
- 2
- 二分图一般独立集
- 一般图
- 一般图的最大独立集。
- 一般图匹配
- 带花树
- 增广路
- 联系
- BFS神力
- 奇环
- 偶环
- LCA
- 代码
二分匹配
匈牙利算法
例题
不说过程了,也没有动图。。。
因为只是一个比较潦草的学习笔记。
首先,我们找到一个公牛,去找一个母牛,如果她没匹配,就匹配,匹配了,就让她匹配了,就让她的公牛找別的找到了,就可以多算一对了。
当然,这样会超时,为何

虚线为未匹配边,实线为匹配边,这张图会陷入无限死循环。
因此我们要标记这个母牛在这次DFS有没有找过。
而且这样还有个好处,找过的母牛就算其他公牛再找她,最后也是找不到的,毕竟原本我找她都没有,你找她就会有了?
代码:
#include练习
1
1
我们可以把课程与日期相连边,再跑二分匹配。
#include2
2
我们可以判断这个老鼠可不可以在规定时间跑到地洞里去,可以就连边。
#include最小覆盖
例题
一下摘自http://caioj.cn/problem.php?id=1151
最少点覆盖所有边
中山市第一中学 沈楚炎
在oi和ACM比赛中,直接用最大二分匹配(匈牙利算法)解题的题目较少,往往披上一层“最小覆盖”的外衣,这类题目从表面看好像跟最大二分匹配无关,然而应用König定理可以轻松解决这类问题,本文给出König定理的证明,并且应用König定理展示解题中基本的构图技巧。
阅读本文需要读者先理解二分图的概念并且掌握匈牙利算法。
最小点覆盖数:在二分图中选了一个点(X集合或Y集合都行)就相当于覆盖了以它为端点的所有边,求覆盖所有边所需的最少点数。
König定理:一个二分图中的最大匹配数等于这个图中的最小点覆盖数。
在证明定理之前,让我们先用它来解决例题1。
König定理证明:
虽然直接应用König定理可以解决许多最小覆盖的题目,但这类题难点往往在于构图,要做到灵活构图应用König定理,则对其证明需要有一定的了解。König定理的证明是建立在匈牙利算法操作细节上的,掌握匈牙利算法的全过程很重要。
假设二分图G分为左边X和右边Y两个互不相交的点集。G经过匈牙利算法后找到一个最大匹配M,则可知G中再也找不到一条增广路径。
根据König定理从最大匹配边中选M个点。下来说明选点策略,再证明这个策略的正确性。
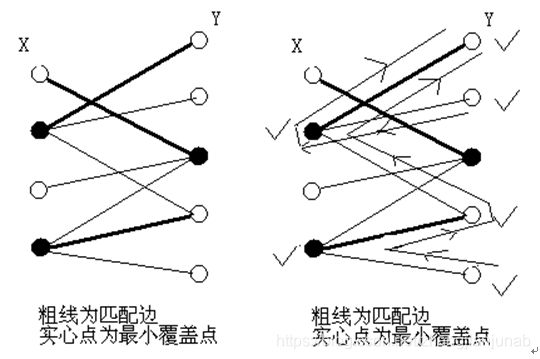
选点策略:
标记右边未匹配边的顶点,并从右边未匹配边的顶点出发,按照边:未匹配→匹配→未匹配→……的原则标记途中经过的顶点,则最后一条经过的边必定为匹配边(否则为增广路经)。重复上述过程,直到右边不再含有未匹配边的点。
记得到的左边已标记的点和右边未标记的点为S, 以下证明S即为所求的最小顶点集。
证明选点策略:
1、| S | 等于 M
左边标记的点全都为匹配边的顶点,右边未标记的点也为匹配边的顶点。因此,我们得到的点与匹配边一一对应。
2、S能覆盖G中所有的边。
根据左右端点是否被标记,G中所有的边有以下四种情况:
① 左右均标记;
② 左右均无标记;
③ 左边标记,右边未标记;
④ 左边未标记,右边标记;
前三种,S 中点(包含:左边的点(标记)+右边的点(未标记))都能得到的,除了④。下面证明④不存在。
假如存在一条边e不属于S所覆盖的边集,且e 左边未标记右边标记。
如果e不属于匹配边,那么左端点就可以通过这条边右端点到达(从而得到标记);
如果e属于匹配边,那么右端点的标记从哪里来?它的标记只能是从这条匹配边的左端点过来,那么左端点就应该有标记。
3、S是最小的覆盖。
因为最大匹配M中,M条边两两之间没有共同交点,所以要覆盖这M条匹配边至少就需要M个点。
证毕。
总结:如果你真的超级无敌懒(严重不推荐),那就记住以下结论(如果你理解了以上证明,也要背以下结论):
1、要摧毁所有边,选“最大匹配数”个点。(做题建造模型的时候要着重思考什么当成边,什么当成点)
2、扩展,选最少的点消失,让X集合和Y集合失去联系 (提醒这个是为了以后网络流的最小割做点不知道会起什么作用的铺垫)
#include练习
1
1
我们把每个地雷的行和列连接,跑一边最小覆盖
#include2
2
我们预处理出每个水在几号横向木板和纵向木板,连边。。。
#include二分图一般独立集
例题
一般独立集=点数-最小覆盖数。
#include一般图
一般图的最大独立集。
这道题目是NP问题来的,我们容易知道:一般图的最大独立集=一般图补图的最大团
而最大团怎么做?
在这给大家推介两道题(放的都是https://vjudge.net/上的,容易上去):
HDU-1530
POJ-2989
我们先讲最大团:
我们知道,我们是可以 O ( 2 n ) O(2^{n}) O(2n)计算极大团(在一般图中不能再加入其他点的团)的数量的,也可以计算最大团(极大团中点数最多的团)点个数,但是 O ( 2 n ) O(2^{n}) O(2n)你确定不会炸?
于是我们引进优美的暴力Bron-Kerbosch 算法
怎么做?
以极大团个数为例
首先,我们设立三个数组:some、all、none
all表示目前团中的点
some表示目前与all中所有点有边相连的点,也就是有可能成为团的点。
none表示这个点进过团后出来就进入none,可以理解为不能进入all里了,且none的点与all中所有点有边相连,作用是判重。
show time
- 我们一开始把所有点踢进some里
- 遍历some集合,然后把some里面的点加入团。
- 将加入的点的临点与some和none做交集。
- 做下一层循环,重复2过程
- 循环结束,回复4过程前做的,且把目前加入的点踢入none里面
- 如果some的点个数与none的点数为0,all中的就是极大团了。
- 但是,如果some为0,而none不为0,这就不是极大团了,因为加入none的点不是会更大吗,但是这个团跟以前重复了。
pivot优化:
我们可以在some中选一个pivot点,如果我们选了pivot点,那么他的在some中的临点下次也会被选中,所以,pivot点的临点就不用再DFS了,而且我们可以按度数来排序,这样可以更好的利用pivot点。
POJ-2989
代码:
#include极大团只需记录最大值:
POJ-2989
代码:
#include当然,大家发现了,在最大团中,all跟none都是没用的,而且极大团个数如果不用输出团的点也不用all。
于是我们可以试一试:
题目
代码:
#include真的可以优化!
至此,最大团完成
一般图匹配
带花树
带花树是一个致命的算法,很麻烦,但是我们可以逐步解析。
增广路
按照匈牙利算法,我们也可以找起点->未匹配边->匹配边->…->未匹配边(不能找到匹配边了)。
这条路径有什么好处?
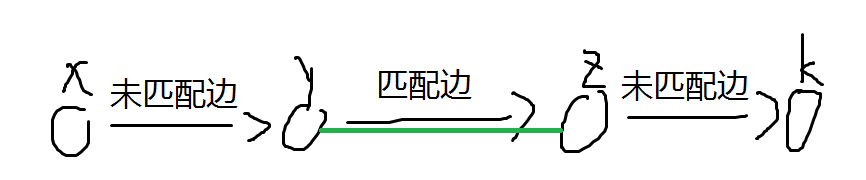
原本, m a t c h [ y ] = z , m a t c h [ z ] = y match[y]=z,match[z]=y match[y]=z,match[z]=y,但是在这条增广路下,我们发现,我们可以把未匹配边变成匹配边,把匹配边变成未匹配边,而在增广路之下,未匹配边比匹配边多一条,所以就可以多一对匹配点。
联系
但是如何从k找回x呢?我们目前知道y、z可以用match联系,但z、k和x、y呢?
于是我们设定一个pre数组, p r e [ y ] = x , p r e [ k ] = z pre[y]=x,pre[k]=z pre[y]=x,pre[k]=z
其实就相当与是未匹配边的联系,不过是单向反过来的而已。
而且pre不能改,这里不需要理解,我们在后面会慢慢讲。
BFS神力
带花树我们使用BFS进行搜索的。
我们标mark标记,0表示没找过,1表示出去找的点,2代表在家呆着的点,起点为1号点,当我们找到一个点时,如果他没匹配过,代表找到增广路,结束,匹配过,标记他为2,标记他的配偶为1,让他的配偶继续找未匹配边。
奇环

我们找到了A,x,y,Q,z,P,Q,k,但是k找到了Q,而Q是什么呢?
Q是1类点!
这个时候,我们会发现:y,z,k,Q,p只要有一个点找到的匹配点,然后A,X匹配,y,z,k,Q,p的另外四个点也各自匹配,就可以多一个点了。
所以当我们找到一个1类点,我们就把奇环(y,z,k,P,Q)当成一个点,简称开花,我们把这朵花里面的点全部设成1号点,且我们需要把未匹配边的两个点的pre互相设置(之前只是单向设置),当然,一些情况pre不能改,代码见。
细节见代码。
偶环
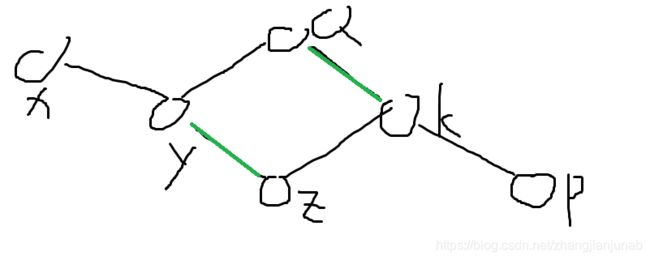
我们现在用BFS找到了x,y,z,k,Q(找不到P,因为k->p是未匹配边)
但是,Q又找到了y,发现了一件事情,y被找过了,而且还是2类点,这就说明这是个偶环,但是这不是奇环,如果我们重复奇环的过程,我们会发现偶环里面只剩奇数个点,必然会破坏原本的匹配,所以偶环我们什么也不理,没有特殊情况。
LCA
其实指的就是BFS路径上的最近公共祖先,不过需要注意的是,奇环是一个点
int vis[N]/*标记*/,ts/*时间戳*/;
int LCA(int x,int y)
{
ts++;//时间增加
while(x!=0)
{
x=find(x);
vis[x]=ts;
x=pre[match[x]];
}
while(y!=0)
{
y=find(y);/*奇环*/if(vis[y]==ts)return y;
vis[y]=ts;
y=pre[match[y]];
}
return 0;
}
那么至此,带花树基本讲解结束。
代码
#include完结撒花