概率潜在语义分析( PLSA)详解
文章目录
- 生成模型
- 共现模型
- 模型性质
- 模型参数
- 与LSA关系
- PLSA实现算法
概率潜在语义分析(probabilistic latent semantic analysis, PLSA)是一种利用概率生成模型对文本集合进行话题分析的无监督方法。 模型最大的特点是用隐变量表示话题,整个模型表示文本生成话题,话题生成单词,从而得到单词—文本共现数据的过程。 假设每个文本由一个话题分布决定,每个话题由一个单词分布决定。潜在语义分析基于非概率模型,概率潜在语义分析基于概率模型。
生成模型
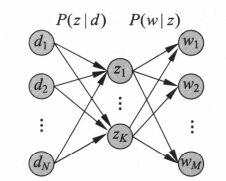
假设有M个单词集合 W = { w 1 , w 2 . … , w M } W=\{w_1,w_2.\ldots,w_M\} W={w1,w2.…,wM},N个文本集合 D = { d 1 , d 2 , … , d N } D=\{d_1,d_2,\ldots,d_N\} D={d1,d2,…,dN},K个话题集合 Z = { z 1 , z 2 , … , z K } Z=\{z_1,z_2,\ldots,z_K\} Z={z1,z2,…,zK},概率分布 P ( d ) P(d) P(d)表示生成文本 d d d 的概率, P ( z ∣ d ) P(z|d) P(z∣d) 表示文本d生成话题 z z z 的概率, P ( w ∣ z ) P(w|z) P(w∣z) 表示话题 z z z 生成单词 w w w的概率。
生成模型步骤如下:
(1)依据概率分布 P ( d ) P(d) P(d) ,从文本集合中随机选取一个文本 d d d,共生成 N N N个文本。
(2)在给定文本 d d d 的条件下,依据条件概率分布 P ( z ∣ d ) P(z|d) P(z∣d) ,从话题集合中随机选取一个话题 z z z,共生成 L L L个话题(L是指文本长度)。
(3)在给定话题 z z z的条件下,依据条件概率分布 P ( w ∣ z ) P(w|z) P(w∣z) ,从单词集合中随机选取一个单词 w w w。
此过程即为概率潜在语义分析的生成模型,生成模型是有向图模型,如下所示:

图中空心圆表示隐变量,方框内的数字表示重复的次数。
从数据生成的过程可以推出,单词—文本共现数据 T T T的生成概率为所有的单词—文本对 ( w , d ) (w,d) (w,d) 的生成概率的乘积:
P ( T ) = ∏ w , d P ( w , d ) n ( w , d ) P(T) = \prod_{w,d} P(w,d)^{n(w,d)} P(T)=w,d∏P(w,d)n(w,d)
其中, n ( w , d ) n(w,d) n(w,d) 表示 ( w , d ) (w,d) (w,d) 出现的次数。每个单词—文本对 ( w , d ) (w,d) (w,d) 的生成概率如下:
P ( w , d ) = P ( d ) P ( w ∣ d ) = P ( d ) ∑ z P ( w , z ∣ d ) = P ( d ) ∑ z P ( z ∣ d ) P ( w ∣ z ) \begin{aligned} P(w,d) & =P(d)P(w|d) \\ &= P(d)\sum_{z} P(w,z|d) \\ & = P(d)\sum_{z} P(z|d)P(w|z) \end{aligned} P(w,d)=P(d)P(w∣d)=P(d)z∑P(w,z∣d)=P(d)z∑P(z∣d)P(w∣z)
这就是生成模型的定义。
共现模型
共现模型与生成模型的不同在于: 每个单词—文本对 ( w , d ) (w,d) (w,d) 的生成概率不同。
P ( w , d ) = ∑ z ∈ Z P ( z ) P ( w ∣ z ) P ( d ∣ z ) P(w,d) = \sum_{z\in Z} P(z)P(w|z)P(d|z) P(w,d)=z∈Z∑P(z)P(w∣z)P(d∣z)
由上式可知:**共现模型假设在话题 z z z 给定的条件下,单词 w w w 与文本 d d d 是条件独立的,**即:
P ( w , d ∣ z ) = P ( w ∣ z ) P ( d ∣ z ) P(w,d|z) = P(w|z)P(d|z) P(w,d∣z)=P(w∣z)P(d∣z)
共现模型如下图所示:

区别:
生成模型刻画文本—单词共现数据生成的过程,共现模型描述文本单词共现数据拥有的模式。生成模型式中单词变量w与文本变量d是非对称的,而共现模型式中单词变量w与文本变量d是对称的;所以前者也称为非对称模型,后者也称为对称模型。
模型性质
模型参数
假设有M个单词,N个文本,如果直接定义单词与文本的共现概率 P ( w , d ) P(w,d) P(w,d) ,模型的参数个数是 O ( M ⋅ N ) O(M\cdot N) O(M⋅N),而PLSA的生成模型和共现模型的参数个数是 O ( M ⋅ K + N ⋅ K ) O(M\cdot K+ N\cdot K) O(M⋅K+N⋅K),其中K是话题数。K远小于M,所以极大的减小了参数个数。下图显示了文本、话题、单词之间的关系。
与LSA关系
PLSA的共现模型:
P ( w , d ) = ∑ z ∈ Z P ( z ) P ( w ∣ z ) P ( d ∣ z ) P(w,d) = \sum_{z\in Z} P(z)P(w|z)P(d|z) P(w,d)=z∈Z∑P(z)P(w∣z)P(d∣z)
也可以表示为三个矩阵的乘积的形式。
X ′ = U ′ Σ ′ V ′ T X ′ = [ P ( w , d ) ] M × N U ′ = [ P ( w ∣ z ) ] M × K Σ ′ = [ P ( z ) ] K × K V ′ = [ P ( d ∣ z ) ] N × K \begin{aligned} &X' = U'\Sigma' V'^T \\ & X' = [P(w,d)]_{M\times N} \\ & U' = [P(w|z)]_{M\times K}\\ & \Sigma' = [P(z)]_{K\times K}\\ & V' = [P(d|z)]_{N\times K}\\ \end{aligned} X′=U′Σ′V′TX′=[P(w,d)]M×NU′=[P(w∣z)]M×KΣ′=[P(z)]K×KV′=[P(d∣z)]N×K
PLSA实现算法
PLSA是含有隐变量的模型,学习通常使用EM算法。
假设有M个单词集合 W = { w 1 , w 2 . … , w M } W=\{w_1,w_2.\ldots,w_M\} W={w1,w2.…,wM},N个文本集合 D = { d 1 , d 2 , … , d N } D=\{d_1,d_2,\ldots,d_N\} D={d1,d2,…,dN},K个话题集合 Z = { z 1 , z 2 , … , z K } Z=\{z_1,z_2,\ldots,z_K\} Z={z1,z2,…,zK}。给定单词—文本共现数据 T = { n ( w i , d j ) } , i = 1 , 2 , … , M ; j = 1 , 2 , … , N T=\{n(w_i,d_j)\},i=1,2,\ldots,M; j=1,2,\ldots,N T={n(wi,dj)},i=1,2,…,M;j=1,2,…,N,目标是估计PLSA(生成模型)的参数,使用极大似然估计,对数似然函数是:
L ( θ ) = log ∏ i = 1 M ∏ j = 1 N P ( d j , w i ) n ( d j , w i ) = ∑ i M ∑ j N n ( d j , w i ) log P ( d j , w i ) = ∑ i M ∑ j N n ( d j , w i ) log [ ∑ k = 1 K P ( w i ∣ z k ) P ( z k ∣ d j ) ] \begin{aligned}L(\theta)&=\log \prod_{i=1}^M\prod_{j=1}^N P(d_j,w_i)^{n(d_j,w_i)}\\ &=\sum_i^M\sum_j^N n(d_j,w_i)\log P(d_j,w_i)\\ &=\sum_i^M\sum_j^N n(d_j,w_i)\log[\sum_{k=1}^K P(w_i|z_k)P(z_k|d_j)]\\ \end{aligned} L(θ)=logi=1∏Mj=1∏NP(dj,wi)n(dj,wi)=i∑Mj∑Nn(dj,wi)logP(dj,wi)=i∑Mj∑Nn(dj,wi)log[k=1∑KP(wi∣zk)P(zk∣dj)]
模型含有隐变量,对数似然函数的优化方法无法用解析方法求解,使用EM算法进行求解。EM算法推导过程参考李航统计学习方法第二版第18章,这里直接给出了结论。算法流程如下:
输入:有M个单词集合 W = { w 1 , w 2 . … , w M } W=\{w_1,w_2.\ldots,w_M\} W={w1,w2.…,wM},N个文本集合 D = { d 1 , d 2 , … , d N } D=\{d_1,d_2,\ldots,d_N\} D={d1,d2,…,dN},K个话题集合 Z = { z 1 , z 2 , … , z K } Z=\{z_1,z_2,\ldots,z_K\} Z={z1,z2,…,zK}。给定单词—文本共现数据 T = { n ( w i , d j ) } , i = 1 , 2 , … , M ; j = 1 , 2 , … , N T=\{n(w_i,d_j)\},i=1,2,\ldots,M; j=1,2,\ldots,N T={n(wi,dj)},i=1,2,…,M;j=1,2,…,N;
输出: P ( w i ∣ z k ) , P ( z k ∣ d j ) P(w_i|z_k),P(z_k|d_j) P(wi∣zk),P(zk∣dj) 。
(1)设置参数 P ( w i ∣ z k ) , P ( z k ∣ d j ) P(w_i|z_k),P(z_k|d_j) P(wi∣zk),P(zk∣dj)的初始值。
(2)迭代执行E步,M步,直到收敛为止。
E步:
P ( z k ∣ w i , d j ) = P ( w i ∣ z k ) P ( z k ∣ d j ) ∑ k = 1 K P ( w i ∣ z k ) P ( z k ∣ d j ) P(z_k|w_i,d_j) = \frac{P(w_i|z_k)P(z_k|d_j)}{\sum_{k=1}^K P(w_i|z_k)P(z_k|d_j)} P(zk∣wi,dj)=∑k=1KP(wi∣zk)P(zk∣dj)P(wi∣zk)P(zk∣dj)
M步:
P ( w i ∣ z k ) = ∑ j = 1 N n ( w i , d j ) P ( z k ∣ w i , d j ) ∑ i = 1 M ∑ j = 1 N n ( w i , d j ) P ( z k ∣ w i , d j ) P(w_i|z_k) = \frac{\sum_{j=1}^N n(w_i,d_j)P(z_k|w_i,d_j)}{\sum_{i=1}^M\sum_{j=1}^N n(w_i,d_j)P(z_k|w_i,d_j)} P(wi∣zk)=∑i=1M∑j=1Nn(wi,dj)P(zk∣wi,dj)∑j=1Nn(wi,dj)P(zk∣wi,dj)P ( z k ∣ d j ) = ∑ i = 1 M n ( w i , d j ) P ( z k ∣ w i , d j ) n ( d j ) P(z_k|d_j) = \frac{\sum_{i=1}^M n(w_i,d_j)P(z_k|w_i,d_j)}{n(d_j)} P(zk∣dj)=n(dj)∑i=1Mn(wi,dj)P(zk∣wi,dj)