Seq2Seq模型理论浅析
Seq2Seq模型理论浅析
一、Seq2Seq模型核心思想
Seq2Seq模型主要是实现一个序列到另一个序列的转换,例如中英文翻译。Seq2Seq模型由两个深度神经网络组成,深度神经网络可以是RNN或者LSTM等其他神经网络。Seq2Seq模型使用一个神经网络将输入序列映射到一个固定维数的向量上,这是一个编码过程;然后另一个神经网络从这个向量映射到目标序列,这是一个解码过程。Seq2Seq的模型结构如图1所示,模型输入句子“ABC”,然后产生“WXYZ”作为输出句子。
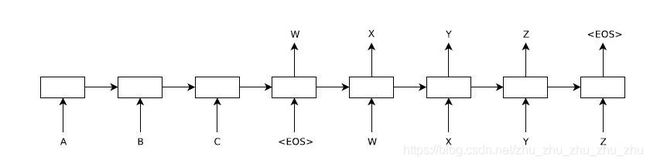
图1 Seq2Seq的模型结构
二、编码与解码
编码与解码是Seq2Seq模型的核心部分,深度学习网络以RNN为例说明编码与解码的原理。编码与解码的结构如图2所示。
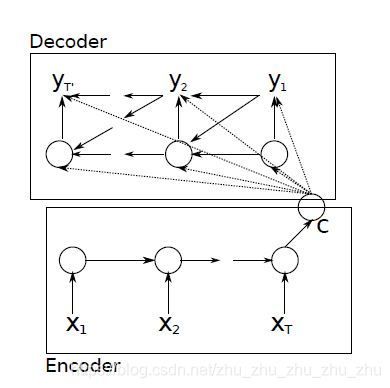
图2 编码与解码的结构
编码:RNN顺序读取输入序列X的每个符号,当读取每个符号时,RNN的隐藏状态h
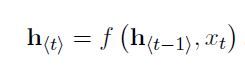
解码:另一个RNN经过训练后,通过预测下一个符号yt生成输出序列,此时解码器在t时间的隐藏状态h
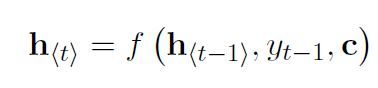
下一个符号的条件分布是
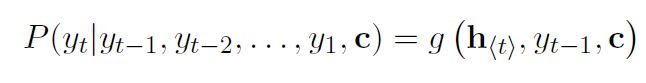
将RNN的编码器和解码器一起训练,求得的最大条件对数似然函数如下:
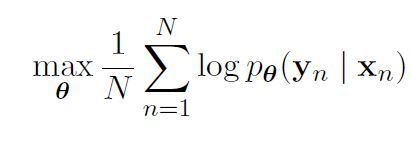
其中的θ是模型参数的集合,每个(Xn,Yn)是来自训练集的输入序列和输出序列组合。
对于RNN的隐藏单元具体结构如图3所示,包括更新门z和重置门r。更新门的作用是选择隐藏状态是否被新的隐藏状态更新。重置门的作用是决定先前的隐藏状态是否被忽视。
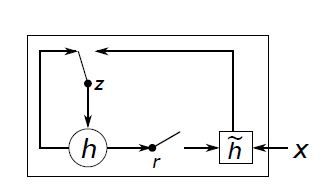
图3 隐藏单元的结构
计算RNN中第j个隐藏单元的激活函数具体过程如下:
首先重置门rj的计算公式是:

其中σ是逻辑sigmoid函数,[.]j表示向量的第j个元素。x和ht-1分别表示输入序列和先前的隐藏状态。Wr和Ur是学习的权重矩阵。
接着同理计算更新门zj:

最后隐藏单元hj的激活函数为:
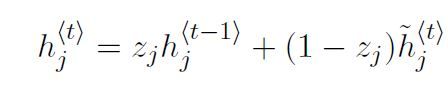
在这个式子中,当重置门接近0时,隐藏状态会强制忽略先前的状态,并用当前的输入进行重置。这个方法可以使隐藏状态删除未来不重要的信息。
三、Attention机制
原始Seq2Seq模型进行翻译时,是将源语句压缩到一个固定长度的向量中,这使得神经网络难以处理长句子。Attention机制提出后有效的解决了这个问题。Attention机制的核心思想:模型在翻译中每次生成单词时,它搜索源语句中信息最相关的一组位置,然后,模型会基于和这些源位置相关联的上下文向量以及先前产生的所有目标单词来预测新的目标单词。

图4 给定源序列(x1,x2,…,xT),尝试生成第t个目标单词yt
Attention机制主要是在编码器和解码器上进行了修改,如图4所示。编码器使用双向RNN,前向RNN按原始顺序读取输入序列(从x1 到xTx),并且计算一个前向隐藏状态序列。后向RNN 按相反的顺序读取序列(从xTx 到x1),得到一个反向隐藏状态序列。将前向隐藏状态和后向隐藏状态连接起来,通过这种方法使得RNN倾向于表示最近的输入。解码器需要注意源句中的部分,通过让解码器有一个注意机制,解决了编码器必须将源语句中的所有信息编码成固定长度向量的问题。利用这种新方法,信息可以散布到注解的序列中,解码器可以相应地选择性检索信息。
Attention机制使模型不必将整个源语句编码为固定长度的向量,并且可以让模型只关注与生成下一个目标词相关的信息。这使得神经网络机器翻译较长句子时结果更好。
四、试验
本文Seq2Seq的案例是通过TensorFlow实现中英文翻译。
试验环境:Python3、TensorFlow1.10、CPU条件下。
数据集:TED演讲数据集。
试验主要分为三个步骤:
1、数据预处理阶段:首先对下载的数据进行切词处理,然后按照词频顺序为每个单词分配一个编号,然后将词汇保存到一个独立的vocab文件中。在确定词汇表后,再将训练文件、测试文件都根据词汇文件转化为单词编号。
2、训练模型:使用循环神经网络作为编码器,使用dynamic_rnn构造编码器和解码器。将训练好的模型保存到checkpoint中。训练阶段cost值变化如图5所示(由于本人电脑配置低,训练模型时简化了神经网络的结构,使训练出来的模型性能不佳。)。
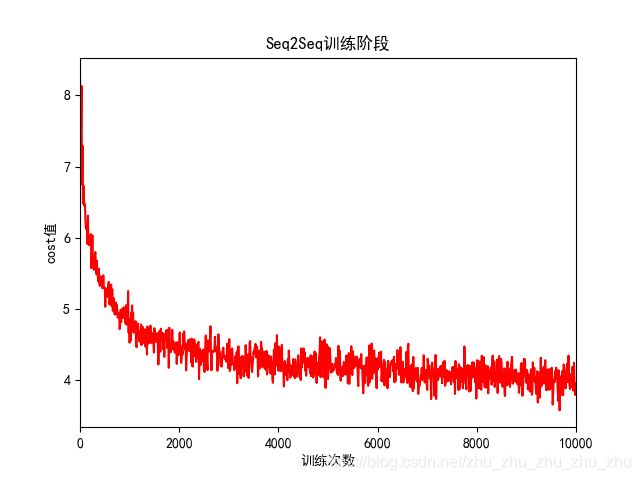
图5 Seq2Seq训练过程
3、模型测试:从checkpoint中读取模型并对一个新的句子进行翻译。解码器在第一步读取
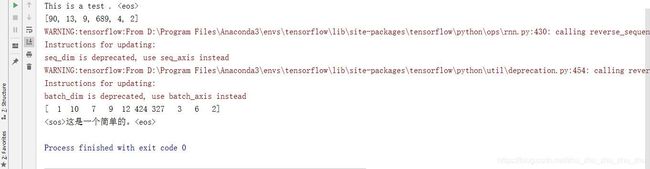
图6 Seq2Seq测试结果