2/5日更新:
2月4日汇总的“疑似病例”人数有点奇怪,有的地方显示累计疑似病例23260,对比昨天只新增了46例。另一些地方显示对比昨日新增3971例,那么就肯定不止23260例。
如果说累计疑似人数是对的,那么防控就起了很好的效果-->假定所有的疑似都转成确诊,人数也控制在4万多了。如果新增疑似人数是对的,那么现在还在持续增加。
加入了2/4日的数据,预测最终确诊人数在3.8万人左右。
2/4日更新:
有几天没来了。起因在于我看了黄冈市唐主任一问三不知的视频以后,意识到可能很多地方对于疫情人数的汇报不准确。因此在整体意义上进行预测意义就不那么大了。(借口)
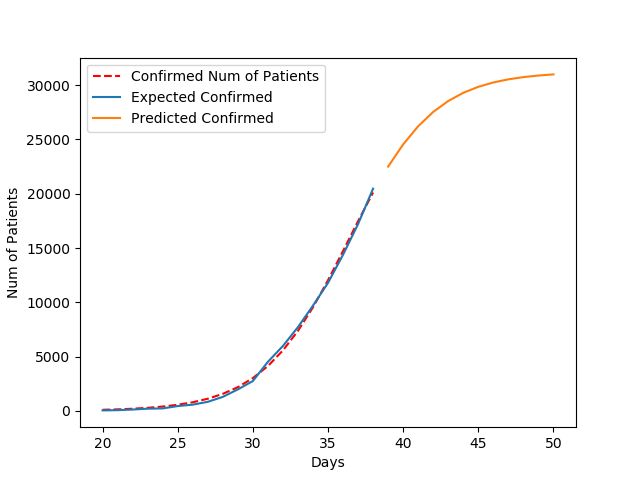
经过几天线性增长以后,我把模型换成了Logistic模型,也就是累计病例会成为一个S形曲线。
这个曲线有一个上限,也就是最终累计确诊人数,目前我的模型预测最终大约会有31240人确诊。大约12天后趋近这个数值。
另外说一下我对趋势的大致判断吧。
截至2/3日,新增确诊3200左右,增速在加快;新增疑似1600左右,在下降。这是一个好趋势。意味着控制起效果了。只要新增疑似控制住了,这个感染人数的上限就基本上定下来了。剩下的就是救治确诊病人。
目前也已经发现一些比较有效的治疗药物,死亡率应该也能控制了。
1/29日更新:
今天一起来就听到好消息,1/28日新增确诊人数为1459,少于1/27日的新增人数17xx人。不过新增疑似人数3248例仍在上升。(注意这里我讨论的是,“每日增加人数”的变化,不是累计人数的变化。)
这样就有两种可能:
- 新增确诊人数下降,但新增疑似人数仍在上升,有一种可能性是确诊人数是受到试剂盒制约而下降,而更多的感染者在“疑似人数”中无法被验证。这样的话,接下来可能新增人数还会增加;
- 假如没有受到制约,1/29日真的是增量拐点,那么应该有一个短期的拉锯。可以反推平均潜伏期约为5天。
要不要把指数模型换成logistic模型不好说,我决定观察一天再定。数据本身的干扰因素太多,预测也不一定准确,只能大概参考一下。
--------------------------------------差点把分割线同志忘记了---------------------------------------------------
1/28日更新:
真香~
事实证明,当模型基本管用的时候,就不应该修改。我前天预测的1/27日确诊人数为4531,今天报道的确诊人数为4515例,误差只有0.3%,昨天修改之后,反而误差更大。
我认为1/26日的确诊人数有问题,因为种种原因,少报了。
预测1/28日确诊人数:6849
--------------------------------------我是一条分割线---------------------------------------------------
1/27日更新:
1/26日确诊人数2744人,与预测2982人误差8.6%,觉得主要有两个原因:
- 检测试剂盒不够 --> 确诊人数受到限制
- 床位不够 --> 能留下来被检测的人数受到限制
修正1/27确诊人数预测:3721
其他
现在比较顾虑的是1/23日武汉封城之前离开的大量人口,其中可能有携带者。按照7-10天潜伏期来算,确诊人数可能在1/30-2/3日到达顶峰,之后预防措施见效,应该就会下降了。
--------------------------------------我是一条分割线---------------------------------------------------
原文,写于1/26日
最近新型冠状病毒的爆发肯定牵动了无数人的心。笔者在这里构建了一个数学模型,希望能够预测感染人数趋势以及给大家提供一些防控指导。
太长不看:
- 传染率大约为1.5,也就是每个人会传播1.5个人左右
- 未来两天的预测结果:
1月26日确诊人数:2982
1月27日确诊人数:4531
由于样本数很小(只有10天),同时早期数据可能存在较大偏差或误报,模型有可能存在overfitting,还需要不断修正。 - 关于干预防控,目前的病例应该都是23日武汉封城之前的,那时候的干预应该还是线性的(影响k*x项)。1/30号以后的病例,应该就是影响指数函数的系数q了,到时候的控制效果会好很多。
一、数据
首先搜集数据,来源是各大网站公开的国内各省市确诊人数和疑似病例人数(不包括外国)。
1月15日前没有找到相关数据。笔者搜集到的数据见表1。
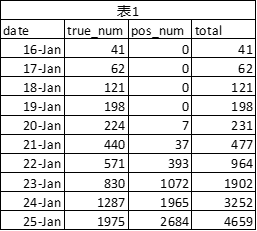
Date:日期
True_num:确诊病例
Pos_num:疑似病例
Total:true_num + sus_num
二、模型
传染病一般按照指数传染,但是因为发现后大家有救治和预防,因此需要修正。在预防中,有一些本会感染的人没有被感染,模型中假定这部分人数与时间成正比。
模型为:
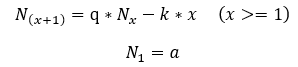
其中:
· 第x天的感染人数Nx
· 疾病传播率为q,q>1表示疾病在扩张
· 第x天本应感染而没有感染的人数为k*x
三、确定病发起点(Zero-Day)
由于网上搜集到的数从1月16日开始,为了使指数模型更精确,需要确定病发起点,即Zero-Day.
在网上查到了以下资料:
公开消息显示,疫情初期(12月8日),由武汉宣传通稿爆出正式收治第一例感染病人,当时网络已爆出有多个疑似感染个案,正在入院检查及治疗,期间有感染者处于危重状态。二十天后的12月28日,武汉市卫建委勉为其难通报疫情信息,称已有27例收治记录,初步认定为病毒性肺炎,并由专家强调“未发现有人传人现象”。
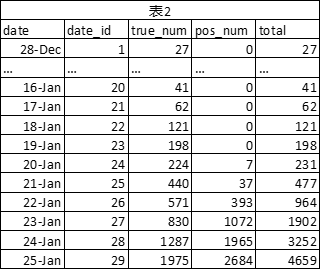
由于12月8日当时的检测手段有限,感染人数不大可靠,因此本人采用了12月28日的数据,在此模型下,1月16号的为第20个数据节点。
因此现在的数据见表2,其中date_id栏为发现疾病后第date_id天。
四、程序
因为现在有些疑似病例因为缺乏试剂无法确诊,因此在模型中,我既预测了确诊病例"Confirmed Num of Patients",也计算了全部病例"Total Num of Patients"(确诊+疑似)
得出的对于全部病例的拟合曲线如下:

误差(RMSE)= 130.4
传染率:q = 1.55
这部分程序如下:
import pandas as pd
import matplotlib.pyplot as plt
from scipy.optimize import curve_fit
import numpy as np
from scipy.optimize import curve_fit
import math
def exp_with_control(x_list, a, q, k):
result_list = []
for x in x_list:
exp_part = a * (1 - q ** x) / (1 - q)
i = 1
while i < x:
sum_q = 0
sum_q = sum_q + (i * q ** (x - 1 - i))
i += 1
poly_part = k * sum_q * x
result_list.append(exp_part - poly_part)
return result_list
# import
data = pd.read_csv('data.csv')
date_id = [i for i in range(20, 30)]
data['date_id'] = date_id
# curve fit
popt_ec, pcov_ec = curve_fit(exp_with_control, xdata=date_id, ydata=data['total'], p0=[1.5, 1.5, 1.5])
y_hat_ec = exp_with_control(date_id, popt_ec[0],popt_ec[1],popt_ec[2])
# plot results
plt.plot(date_id, data['total'], label="Total Num of Patients")
plt.plot(date_id, y_hat_ec,'r--',label="Expected Total")
print("Coefficients", popt_ec)
RMSE_ec = math.sqrt(np.mean((data['total'] - y_hat_ec)**2))
print("RMSE_total", RMSE_ec)
plt.xlabel("Days")
plt.xlabel("Num of Patients")
plt.legend()
plt.show()
对于确诊病例的拟合曲线:
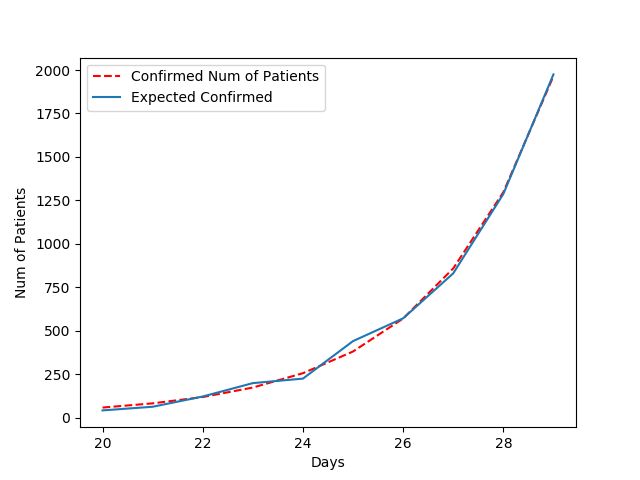
误差(RMSE)= 26.20
传染率:q = 1.52
这部分程序如下:
popt_ec_true, pcov_ec_true = curve_fit(exp_with_control, xdata=date_id, ydata=data['true_num'], p0=[1.5, 1.5, 1.5])
y_hat_ec_true = exp_with_control(date_id, popt_ec_true[0],popt_ec_true[1],popt_ec_true[2])
plt.plot(date_id, y_hat_ec_true,'r--', label="Confirmed Num of Patients")
print("Coefficients", popt_ec_true)
RMSE_ec_true = math.sqrt(np.mean((data['true_num'] - y_hat_ec_true)**2))
print("RMSE Confirmed", RMSE_ec_true)
plt.plot(date_id, data['true_num'], label="Expected Confirmed")
plt.legend()
plt.show()
五、讨论
- 可以看出,模型对于确诊病例的预测误差很小,远好于对于全部病例的预测。对于全部病例的误差,可能是由于疑似病例中很多不是新型肺炎的人误报导致。
- 传染率大约为1.5,也就是每个人会传播1.5个人左右
- 未来两天的预测结果:
1月26日确诊人数:2982
1月27日确诊人数:4531 - 关于防控干预,目前的病例应该都是23日武汉封城之前的,所以那时候的干预应该还是线性的(影响k*x项)。1/30号以后的病例,应该就是影响指数函数的系数q了,那时候的控制效果会好很多。
- 由于样本数很小(只有10天),同时早期数据可能存在较大偏差或误报,模型有可能存在overfitting,还需要不断修正。