JAVA基础---BIO/NIO/AIO详解
BIO:
blocking即阻塞的IO,何为阻塞IO先不解释,我们传统的socket通信就是基于BIO,下面是我学习时的小Demo一起看一下。
/**
* @author chihai
* @ClassName TraditionalSocketDemo
* @Description TODO
* @CreateTime 2019/4/29 11:56
* @Version V1.0
* inputstream:If no byte is available because the end of the stream
* has been reached, the value -1 is returned. This method
* blocks until input data is available, the end of the stream is detected,
* or an exception is thrown.
* 阻塞IO,只能连接一个客户端 开启多线程(资源有限,连接数大,cpu切换多)
*/
public class TraditionalSocketDemo {
public static void main(String[] args) throws IOException {
// ExecutorService threadPool = Executors.newCachedThreadPool(); 先演示只有主线程环境
ServerSocket serverSocket = new ServerSocket(8080);// 监听 8080 端口进来的 TCP 链接
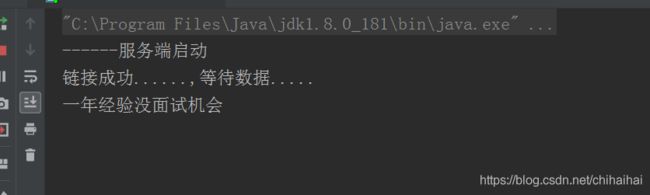
System.out.println("------服务端启动");
while (true){
// 获取socket套接字段 阻塞点1等待连接
Socket socket = serverSocket.accept();
System.out.println("链接成功......,等待数据.....");
// threadPool.execute(()-> {
while (true){
try {
// System.out.println("有新客户端链接上来.....");
// 获取用户输入流 阻塞点2读写操作流程
InputStream inputStream = socket.getInputStream();
byte[] bytes = new byte[1024];
while (true){
int data = inputStream.read(bytes);
if (data != -1){
String info = new String(bytes,0,data,"GBK");
System.out.println(info);
}else {
break;
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
我们可以用window的telnet通信,或者你也可以自己写一个client。telnet功能自己去控制面板打开
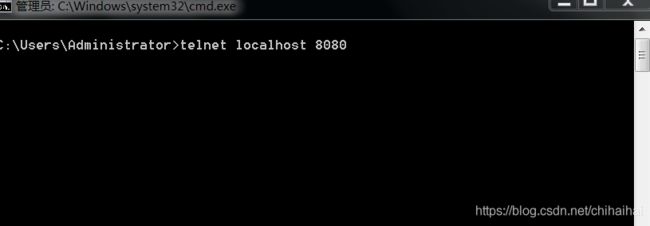
ctrl+]:进入输入模式
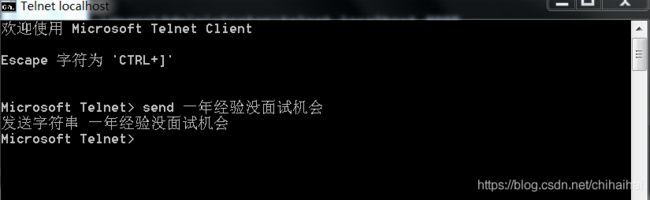
重头戏:
下面我们再来开启一个telnet连接试试能不能正常发送:
1.当我们再启一个telnet窗口连接时控制台并没有打印出连接成功的信息,证明我们第二次连接没有成功而是阻塞在了这里。
2.当我们把前一个telnet窗口关掉后,此时控制台打印出了连接成功的信息,证明我们第二个客户端成功连接。
BIO: 在JDK1.4出来之前,我们建立网络连接的时候采用BIO模式,默认情况下服务端需要对每个请求建立一堆线程等待请求,而客户端发送请求后,先咨询服务端是否有线程相应,如果没有则会一直等待或者遭到拒绝请求(线程就不能做别的事情只能在这里一直阻塞等待),如果有的话,客户端会线程会等待请求结束后才继续执行。到这里我相信已经对BIO有了一个深刻的认识
验证是否一个线程对应一个连接:
最开始代码我注释掉一行,即我们创建一个线程池来执行相关连接。这个时候你就会发现你可以建立多个连接,直至线程池中的线程全部消费掉。未来几天本菜鸟也会把线程池和阻塞队列复习一下。图片我就不贴了大家可以自己验证下。(线程池的使用尽量不要采用Executors的方式,我上面是为了方便演示,至于什么原因请查看阿里巴巴开发手册)
public class TraditionalSocketDemo {
public static void main(String[] args) throws IOException {
ExecutorService threadPool = Executors.newCachedThreadPool();
threadPool.execute(()-> {
});
}
}
}
// 中间代码都一样为了节省空间我删掉了
BIO线程开销大消耗内存 ,所以它的儿子来了青出于蓝而胜于蓝
NIO:
NIO有人称为new IO也有人称为非阻塞IO,但是我感觉这两个解释都不是很准确我更喜欢称它为异步阻塞IO(在select函数上阻塞)。下面有一段对多路复用的解释:
IO多路复用:
就是通过一种机制,一个进程可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。从流程上来看,使用select函数进行IO请求和同步阻塞模型没有太大的区别,甚至还多了添加监视socket,以及调用select函数的额外操作,效率更差。但是,使用select以后最大的优势是用户可以在一个线程内同时处理多个socket的IO请求。用户可以注册多个socket,然后不断地调用select读取被激活的socket,即可达到在同一个线程内同时处理多个IO请求的目的。而在同步阻塞模型中,必须通过多线程的方式才能达到这个目的。IO多路复用方式允许单线程内处理多个IO请求,但是每个IO请求的过程还是阻塞的(在select函数上阻塞),平均时间甚至比同步阻塞IO模型还要长。如果用户线程只注册自己感兴趣的socket或者IO请求,然后去做自己的事情,等到数据到来时再进行处理,则可以提高CPU的利用率。由于select函数是阻塞的,因此多路IO复用模型也被称为异步阻塞IO模型。注意,这里的所说的阻塞是指select函数执行时线程被阻塞,而不是指socket。一般在使用IO多路复用模型时,socket都是设置为NONBLOCK的,不过这并不会产生影响,因为用户发起IO请求时,数据已经到达了,用户线程一定不会被阻塞。IO多路复用是最常使用的IO模型,但是其异步程度还不够“彻底”,因为它使用了会阻塞线程的select系统调用。因此IO多路复用只能称为异步阻塞IO,而非真正的异步IO。
NIO 中 Selector 是对底层操作系统实现的一个抽象,管理通道状态其实都是底层系统实现的,这里简单介绍下在不同系统下的实现。
select:
上世纪 80 年代就实现了,它支持注册 FD_SETSIZE(1024) 个 socket,在那个年代肯定是够用的,不过现在嘛,肯定是不行了。
poll:
1997 年,出现了 poll 作为 select 的替代者,最大的区别就是,poll 不再限制 socket 数量。
select 和 poll 都有一个共同的问题,那就是它们都只会告诉你有几个通道准备好了,但是不会告诉你具体是哪几个通道。所以,一旦知道有通道准备好以后,自己还是需要进行一次扫描,显然这个不太好,通道少的时候还行,一旦通道的数量是几十万个以上的时候,扫描一次的时间都很可观了,时间复杂度 O(n)。所以,后来才催生了以下实现。
epoll:
2002 年随 Linux 内核 2.5.44 发布,epoll 能直接返回具体的准备好的通道,时间复杂度 O(1)。
除了 Linux 中的 epoll,2000 年 FreeBSD 出现了 Kqueue,还有就是,Solaris 中有 /dev/poll。
前面说了那么多实现,但是没有出现 Windows,Windows 平台的非阻塞 IO 使用 select,我们也不必觉得 Windows 很落后,在 Windows 中 IOCP 提供的异步 IO 是比较强大的。

下面是我自己学习时的一个小Demo
/**
* @author chihai
* @ClassName NiOSocketDemo
* @Description TODO
* @CreateTime 2019/4/29 13:37
* @Version V1.0
*/
public class NiOSocketDemo {
public static void main(String[] args) throws IOException {
NiOSocketDemo niOSocketDemo = new NiOSocketDemo();
// 初始化服务器
niOSocketDemo.initServer(8182);
niOSocketDemo.listenSelector();
}
private Selector selector; // 通道选择器
public void initServer(int port)throws IOException{
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
// 有新的连接并不代表这个通道就有数据,
// 这里将这个新的 SocketChannel 注册到 Selector,监听 OP_READ 事件,等待数据
serverSocketChannel.configureBlocking(false); // 设置为非阻塞
serverSocketChannel.socket().bind(new InetSocketAddress(port));
this.selector = Selector.open();// 创建一个 Selector,作为类似调度员的角色。
// 向 Selector 注册,通过指定 SelectionKey.OP_ACCEPT,告诉调度员,它关注的是新的连接请求。
serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT);// 监听连接事件
System.out.println("------------服务启动");
}
public void listenSelector() throws IOException {
// 轮询监听selector
while (true){
// 等待客户连接 selector模型 多路复用
this.selector.select();
Iterator itekey = this.selector.selectedKeys().iterator();
while (itekey.hasNext()){
SelectionKey key = itekey.next();
itekey.remove();
// 处理请求
handler(key);
}
}
}
/**
* 处理客户端请求
*/
private void handler(SelectionKey key) throws IOException {
if(key.isAcceptable()){
// 处理客户端连接请求事件
ServerSocketChannel socketChannel = (ServerSocketChannel)key.channel();
SocketChannel socketChannel1 = socketChannel.accept();
// 为什么我们要明确配置非阻塞模式呢?这是因为阻塞模式下,注册操作是不允许的,会抛出 IllegalBlockingModeException 异常。
socketChannel1.configureBlocking(false);
// 接收客户端发送的消息时,需要给通道读的权限
socketChannel1.register(selector,SelectionKey.OP_READ);
}else if(key.isReadable()) {
// 处理读事件
SocketChannel socketChanne2 = (SocketChannel)key.channel();
ByteBuffer buffer = ByteBuffer.allocate(1024);
int readData = socketChanne2.read(buffer);
if (readData > 0){
String info = new String(buffer.array(),"GBK").trim();
System.out.println("服务端收到数据:"+info);
}else {
System.out.println("客户端关闭");
key.cancel();
}
}
}
}
两种I/O多路复用模式:
Reactor(反应器)和Proactor(前摄器;)(面试偶尔会问,说道面试就难过我这个一年经验的小白根本不给面试机会呢)英文解释是我百度的。。。
在这两种模式下的事件多路分离器反馈给程序的信息是不一样的:
1.Reactor模式下说明你可以进行读写(收发)操作了。
2.Proactor模式下说明已经完成读写(收发)操作了,具体内容在给定缓冲区中,可以对这些内容进行其他操作了。
Reactor关注的是I/O操作的就绪事件,而Proactor关注的是I/O操作的完成事件
一般地,I/O多路复用机制都依赖于一个事件多路分离器(Event Demultiplexer)。分离器对象可将来自事件源的I/O事件分离出来,并分发到对应的read/write事件处理器(Event Handler)。
Reactor模式采用同步IO,而Proactor采用异步IO。
在Reactor中,事件分离器负责等待文件描述符或socket为读写操作准备就绪,然后将就绪事件传递给对应的处理器,最后由处理器负责完成实际的读写工作。
而在Proactor模式中,处理器或者兼任处理器的事件分离器,只负责发起异步读写操作。IO操作本身由操作系统来完成。传递给操作系统的参数需要包括用户定义的数据缓冲区地址和数据大小,操作系统才能从中得到写出操作所需数据,或写入从socket读到的数据。事件分离器捕获IO操作完成事件,然后将事件传递给对应处理器。比如,在windows上,处理器发起一个异步IO操作,再由事件分离器等待IOCompletion事件。典型的异步模式实现,都建立在操作系统支持异步API的基础之上,我们将这种实现称为“系统级”异步或“真”异步,因为应用程序完全依赖操作系统执行真正的IO工作。
Reactor和Proactor模式的主要区别就是真正的读取和写入操作是有谁来完成的,Reactor中需要应用程序自己读取或者写入数据,而Proactor模式中,应用程序不需要进行实际的读写过程,它只需要从缓存区读取或者写入即可,操作系统会读取缓存区或者写入缓存区到真正的IO设备.
我们的java采取的是Reactor模式:
终于知道为什么面试题中会问到这个了。。。一点半了感觉不能熬下去了啊想睡觉,一年以后再回头看自己写的这些东西会不会很蠢。。。。感觉我这个小白博客不会有别人浏览到吧这么多文字有没有人有耐心读完。
2019.9.11 1:34 睡觉了明天起来继续吧希望能找到心仪的工作啊
Java NIO 中三大组件 Buffer、Channel、Selector :
Buffer:
一个 Buffer 本质上是内存中的一块,我们可以将数据写入这块内存,之后从这块内存获取数据。
java.nio 定义了以下几个 Buffer 的实现,这个图读者应该也在不少地方见过了吧。

其实核心是最后的 ByteBuffer,前面的一大串类只是包装了一下它而已,我们使用最多的通常也是 ByteBuffer。我们应该将 Buffer 理解为一个数组,IntBuffer、CharBuffer、DoubleBuffer 等分别对应 int[]、char[]、double[] 等。MappedByteBuffer 用于实现内存映射文件,也不是本文关注的重点。
我觉得操作 Buffer 和操作数组、类集差不多,只不过大部分时候我们都把它放到了 NIO 的场景里面来使用而已。下面介绍 Buffer 中的几个重要属性和几个重要方法。
public abstract class ByteBuffer
extends Buffer
implements Comparable<ByteBuffer>
{
// These fields are declared here rather than in Heap-X-Buffer in order to
// reduce the number of virtual method invocations needed to access these
// values, which is especially costly when coding small buffers.
//
final byte[] hb; // Non-null only for heap buffers
final int offset;
boolean isReadOnly; // Valid only for heap buffers
// Creates a new buffer with the given mark, position, limit, capacity,
// backing array, and array offset
//
ByteBuffer(int mark, int pos, int lim, int cap, // package-private
byte[] hb, int offset)
{
super(mark, pos, lim, cap);
this.hb = hb;
this.offset = offset;
}
// Creates a new buffer with the given mark, position, limit, and capacity
//
ByteBuffer(int mark, int pos, int lim, int cap) { // package-private
this(mark, pos, lim, cap, null, 0);
}
Buffer 中也有几个重要属性:position、limit、capacity。
capacity:它代表这个缓冲区的容量,一旦设定就不可以更改。比如 capacity 为 1024 的 IntBuffer,代表其一次可以存放 1024 个 int 类型的值。一旦 Buffer 的容量达到 capacity,需要清空 Buffer,才能重新写入值。
position: 的初始值是 0,每往 Buffer 中写入一个值,position 就自动加 1,代表下一次的写入位置。读操作的时候也是类似的,每读一个值,position 就自动加 1。从写操作模式到读操作模式切换的时候(flip),position 都会归零,这样就可以从头开始读写了。
Limit: 写操作模式下,limit 代表的是最大能写入的数据,这个时候 limit 等于 capacity。写结束后,切换到读模式,此时的 limit 等于 Buffer 中实际的数据大小,因为 Buffer 不一定被写满了。
初始化 Buffer:
ByteBuffer byteBuf = ByteBuffer.allocate(1024);
===================================================
public static ByteBuffer allocate(int capacity) {
if (capacity < 0)
throw new IllegalArgumentException();
return new HeapByteBuffer(capacity, capacity);
}
===================================================
public static ByteBuffer wrap(byte[] array,
int offset, int length)
{
try {
return new HeapByteBuffer(array, offset, length);
} catch (IllegalArgumentException x) {
throw new IndexOutOfBoundsException();
}
}
填充 Buffer:
各个 Buffer 类都提供了一些 put 方法用于将数据填充到 Buffer 中,如 ByteBuffer 中的几个 put 方法:
// 填充一个 byte 值
public abstract ByteBuffer put(byte b);
// 在指定位置填充一个 int 值
public abstract ByteBuffer put(int index, byte b);
// 将一个数组中的值填充进去
public final ByteBuffer put(byte[] src) {...}
public ByteBuffer put(byte[] src, int offset, int length) {...}
上述需要自己控制 Buffer 大小,不能超过 capacity,超过会抛 java.nio.BufferOverflowException 异常。对于 Buffer 来说,另一个常见的操作中就是,我们要将来自 Channel 的数据填充到 Buffer 中,在系统层面上,这个操作我们称为读操作,因为数据是从外部(文件或网络等)读到内存中。
int num = channel.read(buf);//返回从 Channel 中读入到 Buffer 的数据大小。
前面介绍了写操作,每写入一个值,position 的值都需要加 1,所以 position 最后会指向最后一次写入的位置的后面一个,如果 Buffer 写满了,那么 position 等于 capacity(position 从 0 开始)。
如果要读 Buffer 中的值,需要切换模式,从写入模式切换到读出模式。注意,通常在说 NIO 的读操作的时候,我们说的是从 Channel 中读数据到 Buffer 中,对应的是对 Buffer 的写入操作,需要理清楚这个。调用 Buffer 的 flip() 方法,可以从写入模式切换到读取模式。其实这个方法也就是设置了一下 position 和 limit 值罢了。
public final Buffer flip() {
limit = position;/ 将 limit 设置为实际写入的数据数量
position = 0;// 重置 position 为 0
mark = -1;// mark 之后再说
return this;
}
对应写入操作的一系列 put 方法,读操作提供了一系列的 get 方法:
// 根据 position 来获取数据
public abstract byte get();
// 获取指定位置的数据
public abstract byte get(int index);
// 将 Buffer 中的数据写入到数组中
public ByteBuffer get(byte[] dst)
当然了,除了将数据从 Buffer 取出来使用,更常见的操作是将我们写入的数据传输到 Channel 中,如通过 FileChannel 将数据写入到文件中,通过 SocketChannel 将数据写入网络发送到远程机器等。对应的,这种操作,我们称之为写操作。
int num = channel.write(buf);
mark() & reset()
除了 position、limit、capacity 这三个基本的属性外,还有一个常用的属性就是 mark。mark 用于临时保存 position 的值,每次调用 mark() 方法都会将 mark 设值为当前的 position,便于后续需要的时候使用。
/**
* Sets this buffer's mark at its position.
*
* @return This buffer
*/
public final Buffer mark() {
mark = position;
return this;
}
那到底什么时候用呢?考虑以下场景,我们在 position 为 5 的时候,先 mark() 一下,然后继续往下读,读到第 10 的时候,我想重新回到 position 为 5 的地方重新来一遍,那只要调一下 reset() 方法,position 就回到 5 了。
public final Buffer reset() {
int m = mark;
if (m < 0)
throw new InvalidMarkException();
position = m;
return this;
}
rewind() & clear() & compact():
rewind(): 会重置 position 为 0,通常用于重新从头读写 Buffer。
public final Buffer rewind() {
position = 0;
mark = -1;
return this;
}
clear(): 有点重置 Buffer 的意思,相当于重新实例化了一样。通常,我们会先填充 Buffer,然后从 Buffer 读取数据,之后我们再重新往里填充新的数据,我们一般在重新填充之前先调用 clear()。
public final Buffer clear() {
position = 0;
limit = capacity;
mark = -1;
return this;
}
compact(): 和 clear() 一样的是,它们都是在准备往 Buffer 填充新的数据之前调用。
前面说的 clear() 方法会重置几个属性,但是我们要看到,clear() 方法并不会将 Buffer 中的数据清空,只不过后续的写入会覆盖掉原来的数据,也就相当于清空了数据了。而 compact() 方法有点不一样,调用这个方法以后,会先处理还没有读取的数据,也就是 position 到 limit 之间的数据(还没有读过的数据),先将这些数据移到左边,然后在这个基础上再开始写入。很明显,此时 limit 还是等于 capacity,position 指向原来数据的右边。方法的实现在他的子类下
public ByteBuffer compact() {
System.arraycopy(hb, ix(position()), hb, ix(0), remaining());
position(remaining());
limit(capacity());
discardMark();
return this;
}
Channel
所有的 NIO 操作始于通道,通道是数据来源或数据写入的目的地,主要地,我们将关心 java.nio 包中实现的以下几个 Channel:
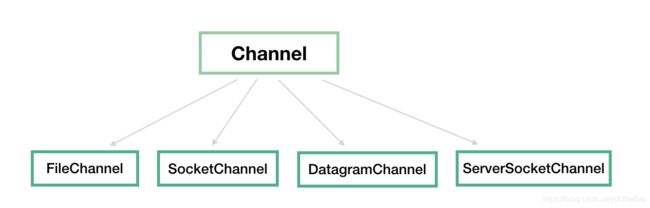
FileChannel:文件通道,用于文件的读和写
DatagramChannel:用于 UDP 连接的接收和发送
SocketChannel:把它理解为 TCP 连接通道,简单理解就是 TCP 客户端
ServerSocketChannel:TCP 对应的服务端,用于监听某个端口进来的请求
Channel 经常翻译为通道,类似 IO 中的流,用于读取和写入。它与前面介绍的 Buffer 打交道,读操作的时候将 Channel 中的数据填充到 Buffer 中,而写操作时将 Buffer 中的数据写入到 Channel 中。
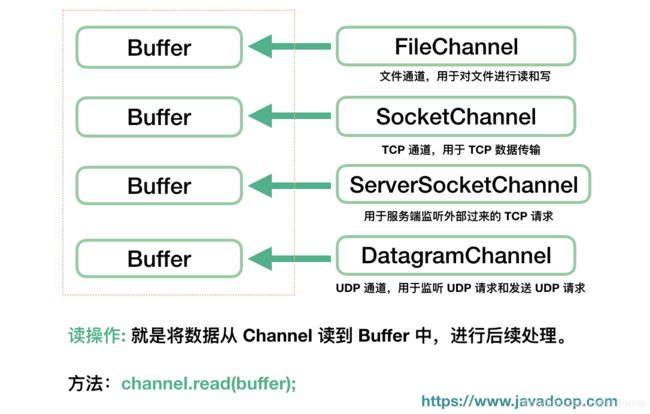
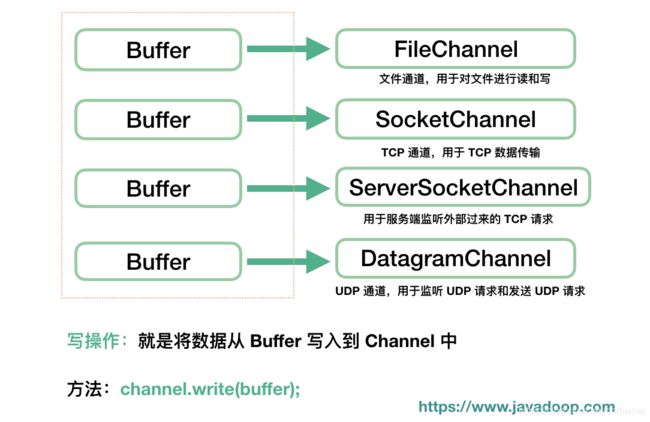
FileChannel
我想文件操作对于大家来说应该是最熟悉的,不过我们在说 NIO 的时候,其实 FileChannel 并不是关注的重点。而且后面我们说非阻塞的时候会看到,FileChannel 是不支持非阻塞的。
SocketChannel
我们前面说了,我们可以将 SocketChannel 理解成一个 TCP 客户端。虽然这么理解有点狭隘,因为我们在介绍 ServerSocketChannel 的时候会看到另一种使用方式。
打开一个 TCP 连接:
SocketChannel socketChannel = SocketChannel.open(new InetSocketAddress("https://www.javadoop.com", 80));
面的这行代码等价于下面的两行:
// 打开一个通道
SocketChannel socketChannel = SocketChannel.open();
// 发起连接
socketChannel.connect(new InetSocketAddress("https://www.javadoop.com", 80));
SocketChannel 的读写和 FileChannel 没什么区别,就是操作缓冲区。
// 读取数据
socketChannel.read(buffer);
// 写入数据到网络连接中
while(buffer.hasRemaining()) {
socketChannel.write(buffer);
}
ServerSocketChannel
之前说 SocketChannel 是 TCP 客户端,这里说的 ServerSocketChannel 就是对应的服务端。
ServerSocketChannel 用于监听机器端口,管理从这个端口进来的 TCP 连接。
/ 实例化
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
// 监听 8080 端口
serverSocketChannel.socket().bind(new InetSocketAddress(8080));
while (true) {
// 一旦有一个 TCP 连接进来,就对应创建一个 SocketChannel 进行处理
SocketChannel socketChannel = serverSocketChannel.accept();
}
到这里,我们应该能理解 SocketChannel 了,它不仅仅是 TCP 客户端,它代表的是一个网络通道,可读可写。ServerSocketChannel 不和 Buffer 打交道了,因为它并不实际处理数据,它一旦接收到请求后,实例化 SocketChannel,之后在这个连接通道上的数据传递它就不管了,因为它需要继续监听端口,等待下一个连接。
DatagramChannel
UDP 和 TCP 不一样,DatagramChannel 一个类处理了服务端和客户端。科普一下,UDP 是面向无连接的,不需要和对方握手,不需要通知对方,就可以直接将数据包投出去,至于能不能送达,它是不知道的
监听端口:
DatagramChannel channel = DatagramChannel.open();
channel.socket().bind(new InetSocketAddress(9090));
=================================================================
ByteBuffer buf = ByteBuffer.allocate(48);
channel.receive(buf);
发送数据:
String newData = "New String to write to file..."
+ System.currentTimeMillis();
ByteBuffer buf = ByteBuffer.allocate(48);
buf.put(newData.getBytes());
buf.flip();
int bytesSent = channel.send(buf, new InetSocketAddress("jenkov.com", 80));
Selector:
NIO 三大组件就剩 Selector 了,Selector 建立在非阻塞的基础之上,大家经常听到的 多路复用 在 Java 世界中指的就是它,用于实现一个线程管理多个 Channel。
1.首先,我们开启一个 Selector。你们爱翻译成选择器也好,多路复用器也好。
Selector selector = Selector.open();
2.将 Channel 注册到 Selector 上。前面我们说了,Selector 建立在非阻塞模式之上,所以注册到 Selector 的 Channel 必须要支持非阻塞模式,FileChannel 不支持非阻塞,我们这里讨论最常见的 SocketChannel 和 ServerSocketChannel。
// 将通道设置为非阻塞模式,因为默认都是阻塞模式的
channel.configureBlocking(false);
// 注册
SelectionKey key = channel.register(selector, SelectionKey.OP_READ);
register 方法的第二个 int 型参数(使用二进制的标记位)用于表明需要监听哪些感兴趣的事件,共以下四种事件:
SelectionKey.OP_READ
对应 00000001,通道中有数据可以进行读取
SelectionKey.OP_WRITE
对应 00000100,可以往通道中写入数据
SelectionKey.OP_CONNECT
对应 00001000,成功建立 TCP 连接
SelectionKey.OP_ACCEPT
对应 00010000,接受 TCP 连接
我们可以同时监听一个 Channel 中的发生的多个事件,比如我们要监听 ACCEPT 和 READ 事件,那么指定参数为二进制的 00010001 即十进制数值 17 即可。
注册方法返回值是 SelectionKey 实例,它包含了 Channel 和 Selector 信息,也包括了一个叫做 Interest Set 的信息,即我们设置的我们感兴趣的正在监听的事件集合。
3.调用 select() 方法获取通道信息。用于判断是否有我们感兴趣的事件已经发生了。
select()
调用此方法,会将上次 select 之后的准备好的 channel 对应的 SelectionKey 复制到 selected set 中。如果没有任何通道准备好,这个方法会阻塞,直到至少有一个通道准备好。
selectNow()
功能和 select 一样,区别在于如果没有准备好的通道,那么此方法会立即返回 0。
select(long timeout)
看了前面两个,这个应该很好理解了,如果没有通道准备好,此方法会等待一会
wakeup()
这个方法是用来唤醒等待在 select() 和 select(timeout) 上的线程的。如果 wakeup() 先被调用,此时没有线程在 select 上阻塞,那么之后的一个 select() 或 select(timeout) 会立即返回,而不会阻塞,当然,它只会作用一次。
AIO:
More New IO,或称 NIO.2,随 JDK 1.7 发布,包括了引入异步 IO 接口和 Paths 等文件访问接口。异步这个词,我想对于绝大多数开发者来说都很熟悉,很多场景下我们都会使用异步。通常,我们会有一个线程池用于执行异步任务,提交任务的线程将任务提交到线程池就可以立马返回,不必等到任务真正完成。如果想要知道任务的执行结果,通常是通过传递一个回调函数的方式,任务结束后去调用这个函数。同样的原理,Java 中的异步 IO 也是一样的,都是由一个线程池来负责执行任务,然后使用回调或自己去查询结果。大部分开发者都知道为什么要这么设计了,这里再啰嗦一下。异步 IO 主要是为了控制线程数量,减少过多的线程带来的内存消耗和 CPU 在线程调度上的开销。
Unix/Linux 等系统中: JDK 使用了并发包中的线程池来管理任务,具体可以查看 AsynchronousChannelGroup 的源码。
**Windows 操作系统中:**提供了一个叫做 I/O Completion Ports 的方案,通常简称为 IOCP,操作系统负责管理线程池,其性能非常优异,所以在 Windows 中 JDK 直接采用了 IOCP 的支持,使用系统支持,把更多的操作信息暴露给操作系统,也使得操作系统能够对我们的 IO 进行一定程度的优化。
在 Linux 中其实也是有异步 IO 系统实现的,但是限制比较多,性能也一般,所以 JDK 采用了自建线程池的方式。
总共有三个类:,分别是 AsynchronousSocketChannel,AsynchronousServerSocketChannel 和 AsynchronousFileChannel,只不过是在之前的 FileChannel、SocketChannel ServerSocketChannel 的类名上加了个前缀 Asynchronous。
Java 异步 IO 提供了两种使用方式,分别是返回 Future 实例和使用回调函数。
==========================================================================
1、返回 Future 实例
返回 java.util.concurrent.Future 实例的方式我们应该很熟悉,JDK 线程池就是这么使用的。Future 接口的几个方法语义在这里也是通用的,这里先做简单介绍。
future.isDone();
判断操作是否已经完成,包括了正常完成、异常抛出、取消
future.cancel(true);
取消操作,方式是中断。参数 true 说的是,即使这个任务正在执行,也会进行中断。
future.isCancelled();
是否被取消,只有在任务正常结束之前被取消,这个方法才会返回 true
future.get();
这是我们的老朋友,获取执行结果,阻塞。
future.get(10, TimeUnit.SECONDS);
如果上面的 get() 方法的阻塞你不满意,那就设置个超时时间。
===========================================================================
2、提供 CompletionHandler 回调函数
package java.nio.channels;
public interface CompletionHandler<V,A> {
void completed(V result, A attachment);//注意,参数上有个 attachment,虽然不常用,我们可以在各个支持的方法中传递这个参数值
void failed(Throwable exc, A attachment);
}
AsynchronousServerSocketChannel listener = AsynchronousServerSocketChannel.open().bind(null);
// accept 方法的第一个参数可以传递 attachment
listener.accept(attachment, new CompletionHandler<AsynchronousSocketChannel, Object>() {
public void completed(
AsynchronousSocketChannel client, Object attachment) {
//
}
public void failed(Throwable exc, Object attachment) {
//
}
});
AsynchronousFileChannel:
实例化:
AsynchronousFileChannel channel = AsynchronousFileChannel.open(Paths.get("/Users/hongjie/test.txt"));
一旦实例化完成,我们就可以着手准备将数据读入到 Buffer 中:
ByteBuffer buffer = ByteBuffer.allocate(1024);
Future<Integer> result = channel.read(buffer, 0);
异步文件通道的读操作和写操作都需要提供一个文件的开始位置,文件开始位置为 0
除了使用返回 Future 实例的方式,也可以采用回调函数进行操作,接口如下:
public abstract void read(ByteBuffer dst,
long position,
A attachment,
CompletionHandler handler);
写操作的两个版本的接口:
public abstract Future<Integer> write(ByteBuffer src, long position);
public abstract <A> void write(ByteBuffer src,
long position,
A attachment,
CompletionHandler<Integer,? super A> handler);
我们可以看到,AIO 的读写主要也还是与 Buffer 打交道,这个与 NIO 是一脉相承的。
另外,还提供了用于将内存中的数据刷入到磁盘的方法:
//
public abstract void force(boolean metaData) throws IOException;
因为我们对文件的写操作,操作系统并不会直接针对文件操作,系统会缓存,然后周期性地刷入到磁盘。如果希望将数据及时写入到磁盘中,以免断电引发部分数据丢失,可以调用此方法。参数如果设置为 true,意味着同时也将文件属性信息更新到磁盘。
还提供了对文件的锁定功能,我们可以锁定文件的部分数据,这样可以进行排他性的操作。
public abstract Future lock(long position, long size, boolean shared);
// position 是要锁定内容的开始位置,size 指示了要锁定的区域大小,shared 指示需要的是共享锁还是排他锁
当然,也可以使用回调函数的版本:
public abstract <A> void lock(long position,
long size,
boolean shared,
A attachment,
CompletionHandler<FileLock,? super A> handler);
文件锁定功能上还提供了 tryLock 方法,此方法会快速返回结果:
public abstract FileLock tryLock(long position, long size, boolean shared)
throws IOException;
// 这个方法很简单,就是尝试去获取锁,如果该区域已被其他线程或其他应用锁住,那么立刻返回 null,否则返回 FileLock 对象。
AsynchronousServerSocketChannel:
package com.javadoop.aio;
import java.io.IOException;
import java.net.InetSocketAddress;
import java.net.SocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.AsynchronousServerSocketChannel;
import java.nio.channels.AsynchronousSocketChannel;
import java.nio.channels.CompletionHandler;
public class Server {
public static void main(String[] args) throws IOException {
// 实例化,并监听端口
AsynchronousServerSocketChannel server =
AsynchronousServerSocketChannel.open().bind(new InetSocketAddress(8080));
// 自己定义一个 Attachment 类,用于传递一些信息
Attachment att = new Attachment();
att.setServer(server);
server.accept(att, new CompletionHandler<AsynchronousSocketChannel, Attachment>() {
@Override
public void completed(AsynchronousSocketChannel client, Attachment att) {
try {
SocketAddress clientAddr = client.getRemoteAddress();
System.out.println("收到新的连接:" + clientAddr);
// 收到新的连接后,server 应该重新调用 accept 方法等待新的连接进来
att.getServer().accept(att, this);
Attachment newAtt = new Attachment();
newAtt.setServer(server);
newAtt.setClient(client);
newAtt.setReadMode(true);
newAtt.setBuffer(ByteBuffer.allocate(2048));
// 这里也可以继续使用匿名实现类,不过代码不好看,所以这里专门定义一个类
client.read(newAtt.getBuffer(), newAtt, new ChannelHandler());
} catch (IOException ex) {
ex.printStackTrace();
}
}
@Override
public void failed(Throwable t, Attachment att) {
System.out.println("accept failed");
}
});
// 为了防止 main 线程退出
try {
Thread.currentThread().join();
} catch (InterruptedException e) {
}
}
}
ChannelHandler 类:
package com.javadoop.aio;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.channels.CompletionHandler;
import java.nio.charset.Charset;
public class ChannelHandler implements CompletionHandler<Integer, Attachment> {
@Override
public void completed(Integer result, Attachment att) {
if (att.isReadMode()) {
// 读取来自客户端的数据
ByteBuffer buffer = att.getBuffer();
buffer.flip();
byte bytes[] = new byte[buffer.limit()];
buffer.get(bytes);
String msg = new String(buffer.array()).toString().trim();
System.out.println("收到来自客户端的数据: " + msg);
// 响应客户端请求,返回数据
buffer.clear();
buffer.put("Response from server!".getBytes(Charset.forName("UTF-8")));
att.setReadMode(false);
buffer.flip();
// 写数据到客户端也是异步
att.getClient().write(buffer, att, this);
} else {
// 到这里,说明往客户端写数据也结束了,有以下两种选择:
// 1. 继续等待客户端发送新的数据过来
// att.setReadMode(true);
// att.getBuffer().clear();
// att.getClient().read(att.getBuffer(), att, this);
// 2. 既然服务端已经返回数据给客户端,断开这次的连接
try {
att.getClient().close();
} catch (IOException e) {
}
}
}
@Override
public void failed(Throwable t, Attachment att) {
System.out.println("连接断开");
}
}
自定义的 Attachment 类:
public class Attachment {
private AsynchronousServerSocketChannel server;
private AsynchronousSocketChannel client;
private boolean isReadMode;
private ByteBuffer buffer;
// getter & setter
}
AsynchronousSocketChannel:
配合之前介绍的 Server 进行测试使用了。
package com.javadoop.aio;
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.AsynchronousSocketChannel;
import java.nio.charset.Charset;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class Client {
public static void main(String[] args) throws Exception {
AsynchronousSocketChannel client = AsynchronousSocketChannel.open();
// 来个 Future 形式的
Future<?> future = client.connect(new InetSocketAddress(8080));
// 阻塞一下,等待连接成功
future.get();
Attachment att = new Attachment();
att.setClient(client);
att.setReadMode(false);
att.setBuffer(ByteBuffer.allocate(2048));
byte[] data = "I am obot!".getBytes();
att.getBuffer().put(data);
att.getBuffer().flip();
// 异步发送数据到服务端
client.write(att.getBuffer(), att, new ClientChannelHandler());
// 这里休息一下再退出,给出足够的时间处理数据
Thread.sleep(2000);
}
}
ClientChannelHandler 类:
package com.javadoop.aio;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.channels.CompletionHandler;
import java.nio.charset.Charset;
public class ClientChannelHandler implements CompletionHandler<Integer, Attachment> {
@Override
public void completed(Integer result, Attachment att) {
ByteBuffer buffer = att.getBuffer();
if (att.isReadMode()) {
// 读取来自服务端的数据
buffer.flip();
byte[] bytes = new byte[buffer.limit()];
buffer.get(bytes);
String msg = new String(bytes, Charset.forName("UTF-8"));
System.out.println("收到来自服务端的响应数据: " + msg);
// 接下来,有以下两种选择:
// 1. 向服务端发送新的数据
// att.setReadMode(false);
// buffer.clear();
// String newMsg = "new message from client";
// byte[] data = newMsg.getBytes(Charset.forName("UTF-8"));
// buffer.put(data);
// buffer.flip();
// att.getClient().write(buffer, att, this);
// 2. 关闭连接
try {
att.getClient().close();
} catch (IOException e) {
}
} else {
// 写操作完成后,会进到这里
att.setReadMode(true);
buffer.clear();
att.getClient().read(buffer, att, this);
}
}
@Override
public void failed(Throwable t, Attachment att) {
System.out.println("服务器无响应");
}
}
AsynchronousChannelGroup :
为了知识的完整性,有必要对 group 进行介绍,其实也就是介绍 AsynchronousChannelGroup 这个类。之前我们说过,异步 IO 一定存在一个线程池,这个线程池负责接收任务、处理 IO 事件、回调等。这个线程池就在 group 内部,group 一旦关闭,那么相应的线程池就会关闭。AsynchronousServerSocketChannels 和 AsynchronousSocketChannels 是属于 group 的,当我们调用 AsynchronousServerSocketChannel 或 AsynchronousSocketChannel 的 open() 方法的时候,相应的 channel 就属于默认的 group,这个 group 由 JVM 自动构造并管理。
如果我们想要配置这个默认的 group,可以在 JVM 启动参数中指定以下系统变量:
java.nio.channels.DefaultThreadPool.threadFactory
此系统变量用于设置 ThreadFactory,它应该是 java.util.concurrent.ThreadFactory 实现类的全限定类名。一旦我们指定了这个 ThreadFactory 以后,group 中的线程就会使用该类产生。
java.nio.channels.DefaultThreadPool.initialSize
此系统变量也很好理解,用于设置线程池的初始大小。
可能你会想要使用自己定义的 group,这样可以对其中的线程进行更多的控制,使用以下几个方法即可:
AsynchronousChannelGroup.withCachedThreadPool(ExecutorService executor, int initialSize)
AsynchronousChannelGroup.withFixedThreadPool(int nThreads, ThreadFactory threadFactory)
AsynchronousChannelGroup.withThreadPool(ExecutorService executor)
熟悉线程池的读者对这些方法应该很好理解,它们都是 AsynchronousChannelGroup 中的静态方法。
至于 group 的使用就很简单了,代码一看就懂:
AsynchronousChannelGroup group = AsynchronousChannelGroup
.withFixedThreadPool(10, Executors.defaultThreadFactory());
AsynchronousServerSocketChannel server = AsynchronousServerSocketChannel.open(group);
AsynchronousSocketChannel client = AsynchronousSocketChannel.open(group);
AsynchronousFileChannels 不属于 group。但是它们也是关联到一个线程池的,如果不指定,会使用系统默认的线程池,如果想要使用指定的线程池,可以在实例化的时候使用以下方法:
public static AsynchronousFileChannel open(Path file,
Set<? extends OpenOption> options,
ExecutorService executor,
FileAttribute<?>... attrs) {
...
}
到这里,异步 IO 就算介绍完成了。
用了一天半时间来回顾之前学过的,但是感觉还是有很多点似懂非懂。脑袋晕晕乎乎的,不过相比上次学习还是有了更多收货,希望下次再来学习这部分内容时可以更加透彻