第一步:如果读者使用过maven,可以很轻松的使用maven引入即可。
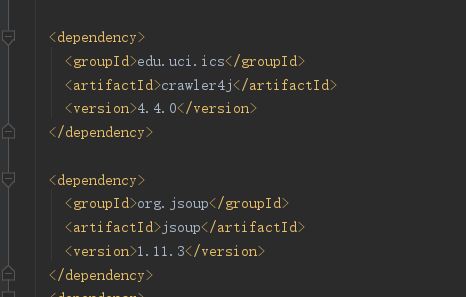
如果你没有用过maven那么,你需要把源码打成jar包,然后引入jar包,使用即可。
第二步:创建一个crawler类继承WebCrawler ,并重写两个方法,如下:
public class MyCrawler2 extends WebCrawler {
@Override
public boolean shouldVisit(Page referringPage, WebURL url) {
//这个方法的作用是过滤不想访问的url
//return false时 url被过滤掉不会被爬取
return super.shouldVisit(referringPage, url);
}
@Override
public void visit(Page page) {
//这个方法的作用是当shouldVisit方法返回true时,调用该方法,获取网页内容,已被封装到Page对象中
super.visit(page);
}
}
第三步:创建一个controller类(实际任意类都行),创建main方法,根据官方文档,只需修改线程数量和url就行了。该url可以被称为种子,只要传入一个url,crawler4j就会根据url中的内容获取页面中所有的url然后再次爬取,周而复始,但重复的网址不会重复爬取,不会出现死循环。
public class Controller {
public static void main(String[] args) throws Exception {
String crawlStorageFolder = "/data/crawl/root";//文件存储位置
int numberOfCrawlers = 7;//线程数量
CrawlConfig config = new CrawlConfig();
config.setCrawlStorageFolder(crawlStorageFolder);//配置对象设置
PageFetcher pageFetcher = new PageFetcher(config);
RobotstxtConfig robotstxtConfig = new RobotstxtConfig();
RobotstxtServer robotstxtServer = new RobotstxtServer(robotstxtConfig, pageFetcher);
CrawlController controller = new CrawlController(config, pageFetcher, robotstxtServer);//创建
controller.addSeed("http://www.ics.uci.edu/~lopes/");//传入的url
controller.start(MyCrawler.class, numberOfCrawlers);//开始执行爬虫
}
}
启动main方法就可以完成网页的爬取了。
下面写一个实例,爬取欧洲黄页的企业信息
1.控制器
public class CrawlerController {
public static void main(String[] args) throws Exception {
String crawkStirageFolder = "E:/CRAWLER/jd/test1";//定义爬虫数据存储位置
int numberOfCrawlers=1;//定义1个爬虫,也就是1个线程,爬虫数量不可以超出cpu的线程
CrawlConfig config=new CrawlConfig();//定义爬虫配置
config.setCrawlStorageFolder(crawkStirageFolder);
/*
实例化爬虫控制器
*/
PageFetcher pageFetcher=new PageFetcher(config);//实例化页面获取器
RobotstxtConfig robotstxtConfig=new RobotstxtConfig();//实例化爬虫机器人配置
// 实例化爬虫机器人对目标服务器的配置,每个网站都有一个robots.txt文件
// 规定了该网站哪些页面可以爬,哪些页面禁止爬,该类是对robots.txt规范的实现
RobotstxtServer robotstxtServer=new RobotstxtServer(robotstxtConfig,pageFetcher);
//实例化爬虫控制器
CrawlController controller=new CrawlController(config,pageFetcher,robotstxtServer);
controller.addSeed("https://www.europages.cn/qiyeminglu.html");//传入种子 要爬的网站
controller.start(MyCrawler2.class,numberOfCrawlers);//开始执行爬虫
}
}2.爬虫类,这里的两个实现方法尤为重要,控制器只是一个访问的入口,具体访问规则和访问结果的获取都是在这两个方法中实现。
查看欧洲黄页关html规则,发现目录都在
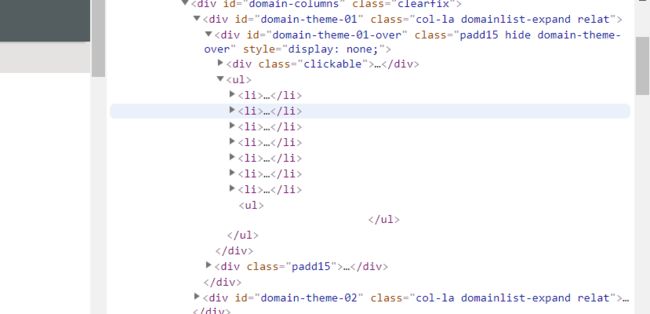
继续展开
public class MyCrawler2 extends WebCrawler {
//自定义过滤规则
private final static Pattern FILTERS=Pattern.compile(".*(\\.(css|js|gif|jpg|png|mp3|mp4|zip|gz))$");
@Override
public boolean shouldVisit(Page referringPage, WebURL url){
/* return super.shouldVisit(referringPage,url);*/
String href = url.getURL().toLowerCase();//爬取的网址 转小写
//这里定义过滤的网址,我的需求是只爬取一级菜单
boolean b =!FILTERS.matcher(href).matches()&&href.startsWith("https://www.europages.cn/qiyeminglu.html");
return b;
}
@Override
public void visit(Page page){
/*super.visit(page);*/
String url = page.getWebURL().getURL();
System.out.println(url);
//判断page是否为真正的网页
if (page.getParseData() instanceof HtmlParseData) {
HtmlParseData htmlParseData = (HtmlParseData) page.getParseData();
String html = htmlParseData.getHtml();//页面html内容
Document doc= Jsoup.parse(html);//将html解析成一个Document类
//使用选择器的时候需要了解网页中的html规则,自己去网页中F12一下,
Elements content=doc.getElementsByClass("title test_actvLink");
if (content.size()==0){
return;
}
//Elements elements = doc.select(".gl-item");
int num=0;
for (Element element: content) {
String text=element.text();
String weburl=element.attr("href");
System.out.println(text);
System.out.println(weburl);
num++;
}
System.out.println("分类总算为"+num);
}
}
}看一下运行结果,我选择输出一级分类名,和对应网址
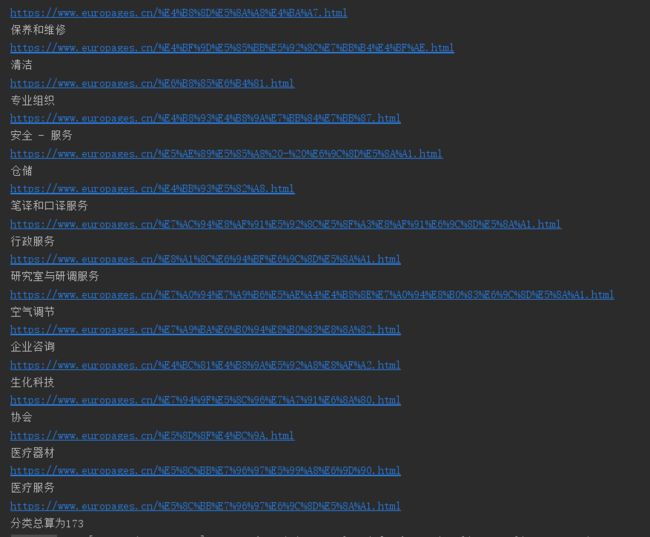
这个文章写的相对粗糙,周末有空在好好整理一下吧
推荐博文 https://blog.csdn.net/qq_34337272/article/details/78815547