2019/11/19 Caesar
前言
有这么一句话在业界广泛流传:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。那特征工程到底是什么呢?顾名思义,其本质是一项工程活动,目的是最大限度地从原始数据中提取特征以供算法和模型使用。通过特征提取,我们能得到未经处理的特征,需要通过数据预处理手段来解决。
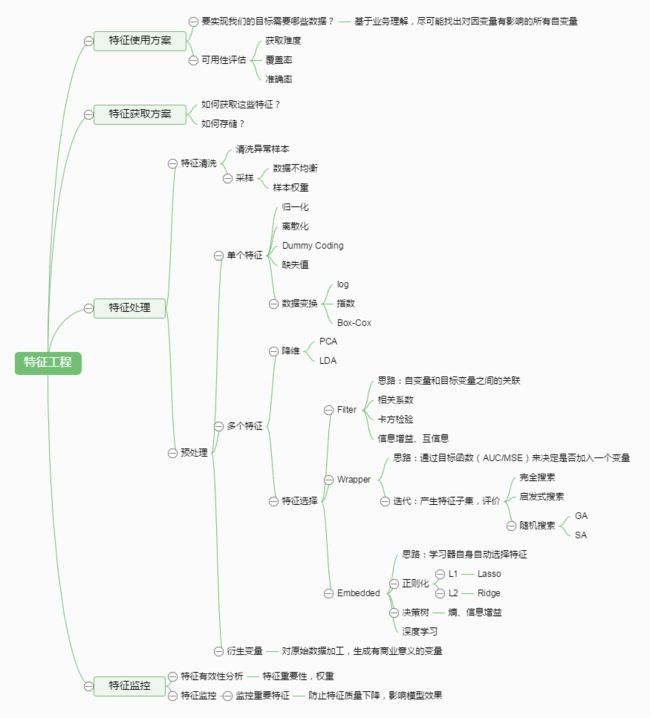
1. 特征工程
特征处理是特征工程的核心部分,sklearn提供了较为完整的特征处理方法,包括数据预处理,特征选择,降维等。首次接触到sklearn,通常会被其丰富且方便的算法模型库吸引,但是这里介绍的特征处理库也十分强大!通过总结和归纳,人们认为特征工程包括以下方面:
本文中使用sklearn中的IRIS(鸢尾花)数据集来对特征处理功能进行说明。IRIS数据集由Fisher在1936年整理,包含4个特征(Sepal.Length(花萼长度)、Sepal.Width(花萼宽度)、Petal.Length(花瓣长度)、Petal.Width(花瓣宽度)),特征值都为正浮点数,单位为厘米。目标值为鸢尾花的分类(Iris Setosa(山鸢尾)、Iris Versicolour(杂色鸢尾),Iris Virginica(维吉尼亚鸢尾))。导入IRIS数据集的代码如下:
from sklearn.datasets import load_iris
#导入IRIS数据集
iris = load_iris()
#特征矩阵
iris.data
#目标向量
iris.target
2. 数据预处理
2.1 无量纲化
无量纲化使不同规格的数据转换到同一规格。常见的无量纲化方法有标准化和区间缩放法。标准化的前提是特征值服从正态分布,标准化后,其转换成标准正态分布。区间缩放法利用了边界值信息,将特征的取值区间缩放到某个特点的范围,例如[0, 1]等。
2.1.1 标准化
标准化需要计算特征的均值和标准差,公式表达为:
使用preproccessing库的StandardScaler类对数据进行标准化的代码如下:
from sklearn.preprocessing import MinMaxScaler #区间缩放,返回值为缩放到[0, 1]区间的数据MinMaxScaler().fit_transform(iris.data)
2.1.3 标准化与正则化的区别
简单来说,标准化是依照特征矩阵的列处理数据,其通过求z-score的方法,将样本的特征值转换到同一量纲下。正则化是依照特征矩阵的行处理数据,其目的在于样本向量在点乘运算或其他核函数计算相似性时,拥有统一的标准,也就是说都转化为“单位向量”。规则为l2的归一化公式如下:
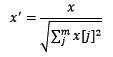
正则化的过程是将每个样本缩放到单位范数(每个样本的范数为1),如果后面要使用如二次型(点积)或者其它核方法计算两个样本之间的相似性这个方法会很有用。
Normalization主要思想是对每个样本计算其p-范数,然后对该样本中每个元素除以该范数,这样处理的结果是使得每个处理后样本的p-范数(l1-norm,l2-norm)等于1。
p-范数的计算公式:||X||p=(|x1| p+|x2|p+...+|xn| p)1/p
该方法主要应用于文本分类和聚类中。例如,对于两个TF-IDF向量的l2-norm进行点积,就可以得到这两个向量的余弦相似性。
使用preproccessing库的Normalizer类对数据进行归一化的代码如下:
>>> X = [[ 1., -1., 2.],
... [ 2., 0., 0.],
... [ 0., 1., -1.]]
>>> normalizer = preprocessing.Normalizer().fit(X) # fit does nothing
>>> normalizer
Normalizer(copy=True, norm=‘l2‘)
>>>
>>> normalizer.transform(X)
array([[ 0.40..., -0.40..., 0.81...],
[ 1. ..., 0. ..., 0. ...],
[ 0. ..., 0.70..., -0.70...]])
2.2 对定量特征二值化
定量特征二值化的核心在于设定一个阈值,大于阈值的赋值为1,小于等于阈值的赋值为0,公式表达如下:
使用preproccessing库的Binarizer类对数据进行二值化的代码如下:
from sklearn.preprocessing import Binarizer
#二值化,阈值设置为3,返回值为二值化后的数据
Binarizer(threshold=3).fit_transform(iris.data)
2.3 对定性特征哑编码
由于IRIS数据集的特征皆为定量特征,故使用其目标值进行哑编码(实际上是不需要的)。使用preproccessing库的OneHotEncoder类对数据进行哑编码的代码如下:
from sklearn.preprocessing import OneHotEncoder
#哑编码,对IRIS数据集的目标值,返回值为哑编码后的数据
OneHotEncoder().fit_transform(iris.target.reshape((-1,1)))
2.4 缺失值计算
由于IRIS数据集没有缺失值,故对数据集新增一个样本,4个特征均赋值为NaN,表示数据缺失。使用preproccessing库的Imputer类对数据进行缺失值计算的代码如下:
在sklearn的preprocessing包中包含了对数据集中缺失值的处理,主要是应用Imputer类进行处理。
首先需要说明的是,numpy的数组中可以使用np.nan/np.NaN(Not A Number)来代替缺失值,对于数组中是否存在nan可以使用np.isnan()来判定。
使用type(np.nan)或者type(np.NaN)可以发现改值其实属于float类型,代码如下:
>>> type(np.NaN)
>>> type(np.nan)
>>> np.NaN
nan
>>> np.nan
nan
因此,如果要进行处理的数据集中包含缺失值一般步骤如下:
1、使用字符串'nan'来代替数据集中的缺失值;
2、将该数据集转换为浮点型便可以得到包含np.nan的数据集;
3、使用sklearn.preprocessing.Imputer类来处理使用np.nan对缺失值进行编码过的数据集。
代码如下:
>>> from sklearn.preprocessing import Imputer
>>> imp = Imputer(missing_values='NaN', strategy='mean', axis=0)
>>> X=np.array([[1, 2], [np.nan, 3], [7, 6]])
>>> Y=[[np.nan, 2], [6, np.nan], [7, 6]]
>>> imp.fit(X)
Imputer(axis=0, copy=True, missing_values='NaN', strategy='mean', verbose=0)
>>> imp.transform(Y)
array([[ 4. , 2. ],
[ 6. , 3.66666667],
[ 7. , 6. ]])
上述代码使用数组X去“训练”一个Imputer类,然后用该类的对象去处理数组Y中的缺失值,缺失值的处理方式是使用X中的均值(axis=0表示按列进行)代替Y中的缺失值。当然也可以使用imp对象来对X数组本身进行处理。
通常,我们的数据都保存在文件中,也不一定都是Numpy数组生成的,因此缺失值可能不一定是使用nan来编码的,对于这种情况可以参考以下代码:
>>> line='1,?'
>>> line=line.replace(',?',',nan')
>>> line
'1,nan'
>>> Z=line.split(',')
>>> Z
['1', 'nan']
>>> Z=np.array(Z,dtype=float)
>>> Z
array([ 1., nan])
>>> imp.transform(Z)
array([[ 1. , 3.66666667]])