Why Memory Barriers中文翻译(下)
转载自:http://www.wowotech.net/kernel_synchronization/why-memory-barrier-2.html
在上一篇why memory barriers文档中,由于各种原因,有几个章节没有翻译。其实所谓的各种原因总结出一句话就是还没有明白那些章节所要表达的内容。当然,对于一个真正的热爱钻研的linuxer,不理解的那些章节始终都是一块心病。终于,在一个月黑风高的夜晚,我发了一封邮件给perfbook的作者Paul,请其指点一二。果然是水平越高越平易近人,很快,大神回复了,给出了一些他的意见,大意就是不必纠结于具体的细节,始终focus在几个基本的规则上就OK了。受此鼓舞,我还是坚持把剩余章节翻译出来,于是形成了本文。
注:有些特定CPU architecture章节实在是无心翻译,暂时TODO吧。

七、Example Memory-Barrier Sequences
This section presents some seductive but subtly broken uses of memory barriers. Although many of them will work most of the time, and some will work all the time on some specific CPUs, these uses must be avoided if the goal is to produce code that works reliably on all CPUs. To help us better see the subtle breakage, we first need to focus on an ordering-hostile architecture.
这一小节我们会分析几个有意思的memory barrier的例子。尽管这些代码大部分时间都可以正常工作,并且其中有些在某些特定平台的CPU上可以一直正常工作,但是,如果我们的目标是星辰大海(平台无关代码,即在所有的CPU上都可以正确运行),那么还是有必要看看这些微妙的错误是如何发生的。我们先来看看ordering-hostile architecture这个概念。
1、Ordering-Hostile Architecture
A number of ordering-hostile computer systems have been produced over the decades, but the nature of the hostility has always been extremely subtle, and understanding it has required detailed knowledge of the specific hardware. Rather than picking on a specific hardware vendor, and as a presumably attractive alternative to dragging the reader through detailed technical specifications, let us instead design a mythical but maximally memory-ordering-hostile
computer architecture.
在过去的数十年里,许多ordering-hostile的计算系统被生产出来,对于这类计算机系统,memory order非常精妙,需要大量的硬件知识才能理解它。与其选择一个特定的硬件平台,把读者带入特定的一些技术细节,不如做点看起来更有意思的事情:我们自己设计一个对memory order约束最弱的CPU architecture。
This hardware must obey the following ordering constraints [McK05a, McK05b]:
- Each CPU will always perceive its own memory accesses as occurring in program order.
- CPUs will reorder a given operation with a store only if the two operations are referencing different locations.
- All of a given CPU’s loads preceding a read memory barrier (smp_rmb()) will be perceived by all CPUs to precede any loads following that read memory barrier.
- All of a given CPU’s stores preceding a write memory barrier (smp_wmb()) will be perceived by all CPUs to precede any stores following that write memory barrier.
- All of a given CPU’s accesses (loads and stores) preceding a full memory barrier (smp_mb()) will be perceived by all CPUs to precede any accesses following that memory barrier.
这种硬件必须服从下面的规则:
(1) 对于每个CPU而言,从它自己的角度看,其内存访问的顺序总是符合program order的。
(2) 如果CPU要对一个指定的操作(load或者store)和另外的一个store操作进行重排的话,那么一定要符合指定的条件:即这两个操作的memory地址是不能有重叠区域的。
(3) 如果program order是先load A然后load B,这样的操作在CPU 0上执行的时候,从其自己来看memory系统的变化,当然是load A,然后load B(请参考前面的第一条规则)。但是,系统中的其他其他CPU如何看待CPU 0的操作呢(想像所有的CPU都是趴在总线上的观察者,不断的观察memory的变化)?根据前面文章描述的知识,可以肯定的是load A和load B的顺序是无法保证的。如果增加了个read memory barrier,那结果可就不一样了。假设CPU 0执行的是load A,然后read memory barrier,最后load B,那么总线上的所有CPU,包括CPU 0自己,看到的内存操作顺序都是load A,然后load B。
(4) 如果系统中所有的CPU都是潜伏在总线上的观察者,不断的观察memory的变化。那么任意一个给定的系统中的CPU在执行store代码的时候,都可以被系统中的所有CPU感知(包括它自己)。如果给定CPU执行的代码被write memory barrier分成两段:wmb之前的store操作,wmb之后的store操作,那么系统中所有的CPU的观察结果都是一样的,wmb之前的store操作先执行完毕,wmb之后的store操作随后被执行。
(5) 某一个CPU执行的全功能内存屏障指令之前的memory access的操作(load or store),必定先被系统中所有的CPU感知到,之后系统中的所有CPU才看到全功能内存屏障指令之后的memory access的操作(load or store)的执行结果。
Imagine a large non-uniform cache architecture (NUCA) system that, in order to provide fair allocation of interconnect bandwidth to CPUs in a given node, provided per-CPU queues in each node’s interconnect interface, as shown in Figure C.8. Although a given CPU’s accesses are ordered as specified by memory barriers executed by that CPU, however, the relative order of a given pair of CPUs’ accesses could be severely reordered, as we will see.
一个示例性的Ordering-Hostile Architecture如下图所示:

这个系统被称为non-uniform cache architecture (NUCA) 的系统,为了公平的分配Interconnect到各个CPU之间的带宽,我们在Node和interconnect器件之间的接口设计了per cpu的Message queue。尽管,一个指定CPU的内存访问可以通过memory barrier对访问顺序进行约定,但是,一对CPU上的内存访问可以被完全打乱重排,下面我们会详细描述。
2、Example 1
Table C.2 shows three code fragments, executed concurrently by CPUs 0, 1, and 2. Each of “a”, “b”, and “c” are initially zero.
下表列出了CPU 0、CPU 1和CPU 2各自执行的代码片段,a,b,c变量的初始值都是0。
| CPU 0 | CPU 1 | CPU 2 |
| a = 1;
|
|
z = c; |
Suppose CPU 0 recently experienced many cache misses, so that its message queue is full, but that CPU 1 has been running exclusively within the cache, so that its message queue is empty. Then CPU 0’s assignment to “a” and “b” will appear in Node 0’s cache immediately (and thus be visible to CPU 1), but will be blocked behind CPU 0’s prior traffic. In contrast, CPU 1’s assignment to “c” will sail through CPU 1’s previously empty queue. Therefore, CPU 2 might well see CPU 1’s assignment to “c” before it sees CPU 0’s assignment to “a”, causing the assertion to fire, despite the memory barriers.
我们假设CPU 0最近经历了太多cache miss,以至于它的message queue满了。CPU 1比较幸运,它操作的内存变量在cacheline中都是exclusive状态,不需要发送和node 1进行交互的message,因此它的message queue是空的。对于CPU0而言,a和b的赋值都很快体现在了NODE 0的cache中(CPU1也是可见的),不过node 1不知道,因为message都阻塞在了cpu 0的message queue中。与之相反的是CPU1,其对c的赋值可以通过message queue通知到node1。这样导致的效果就是,从cpu2的角度看,它先观察到了CPU1上的c=1赋值,然后才看到CPU0上的对a变量的赋值,这也导致了尽管使用了memory barrier,CPU2上仍然遭遇了assert fail。之所以会fail,主要是在cpu2上发生了当z等于1的时候,却发现x等于0。
Therefore, portable code cannot rely on this assertion not firing, as both the compiler and the CPU can reorder the code so as to trip the assertion.
因此,可移植代码不能依赖assert总是succeed,编译器和CPU都会重排代码,导致assertion trigger。
3、 Example 2
Table C.3 shows three code fragments, executed concurrently by CPUs 0, 1, and 2. Both “a” and “b” are initially zero.
下表列出了CPU 0、CPU 1和CPU 2各自执行的代码片段,a,b变量的初始值都是0。
| CPU 0 | CPU 1 | CPU 2 |
| a = 1; |
while (a == 0); smp_mb(); |
y = b; |
Again, suppose CPU 0 recently experienced many cache misses, so that its message queue is full, but that CPU 1 has been running exclusively within the cache, so that its message queue is empty. Then CPU 0’s assignment to “a” will appear in Node 0’s cache immediately (and thus be visible to CPU 1), but will be blocked behind CPU 0’s prior traffic. In contrast, CPU 1’s assignment to “b” will sail through CPU 1’s previously empty queue. Therefore, CPU 2 might well see CPU 1’s assignment to “b” before it sees CPU 0’s assignment to “a”, causing the assertion to fire, despite the memory barriers.
我们再次假设CPU0最近遇到太多cache miss,以至于它的message queue满了,而cpu1由于操作的变量cacheline都是exclusive状态,因此它的message queue是空的。同样的,CPU0上的对a的赋值会立刻被同在一个node中的CPU1观察到,但是,由于CPU0之前的一些协议交互塞满了其message queue,因此,对于node 0之外的CPUs则看不到CPU0对a的赋值。相反,CPU1的对b的赋值,由于其message queue是空的,因此,轻舟已过万重山,顺利到达其他node。对于CPU2而言,当执行assert的代码的时候,有可能执行的结果是y等于1并且x等于0,从而导致assertion fail。
In theory, portable code should not rely on this example code fragment, however, as before, in practice it actually does work on most mainstream computer systems.
理论上,上面的代码不是可移植代码,虽然在大部分的计算机系统上都能正常运行。
4、Example 3
Table C.4 shows three code fragments, executed concurrently by CPUs 0, 1, and 2. All variables are initially zero.
下表列出了CPU 0、CPU 1和CPU 2各自执行的代码片段,所有的变量的初始值都是0。

Note that neither CPU 1 nor CPU 2 can proceed to line 5 until they see CPU 0’s assignment to “b” on line 3. Once CPU 1 and 2 have executed their memory barriers on line 4, they are both guaranteed to see all assignments by CPU 0 preceding its memory barrier on line 2. Similarly, CPU 0’s memory barrier on line 8 pairs with those of CPUs 1 and 2 on line 4, so that CPU 0 will not execute the assignment to “e” on line 9 until after its assignment to “a” is visible to both of the other CPUs. Therefore, CPU 2’s assertion on line 9 is guaranteed not to fire.
无论是CPU1还是CPU2,它们都不能越过smp_mb,直到观察到CPU0上的对b的赋值(在line3)。一旦CPU1和CPU2执行了smp_mb这条指令(line 4),这两个CPU都可以保证观察到CPU0上smb_wmb(line 2)之前的指令的执行结果。同样的,CPU0上在第8行的smp_mb(),和CPU1以及CPU2上的smp_mb(line 4)组成一对,可以保证CPU0不会执行e的赋值(line 9),直到其对a的赋值(line1)被CPU1和CPU2观察到。因此CPU2上assert不会fail。
八、 Memory-Barrier Instructions For Specific CPUs
Each CPU has its own peculiar memory-barrier instructions, which can make portability a challenge, as indicated by Table C.5. In fact, many software environments, including pthreads and Java, simply prohibit direct use of memory barriers, restricting the programmer to mutual-exclusion primitives that incorporate them to the extent that they are required. In the table, the first four columns indicate whether a given CPU allows the four possible combinations of loads and stores to be reordered. The next two columns indicate whether a given CPU allows loads and stores to be reordered with atomic instructions.
The seventh column, data-dependent reads reordered, requires some explanation, which is undertaken in the following section covering Alpha CPUs. The short version is that Alpha requires memory barriers for readers as well as updaters of linked data structures. Yes, this does mean that Alpha can in effect fetch the data pointed to before it fetches the pointer itself, strange but true. Please see: http://www.openvms.compaq.com/wizard/wiz_2637.html if you think that I am just making this up. The benefit of this extremely weak memory model is that Alpha can use simpler cache hardware, which in turn permitted higher clock frequency in Alpha’s heyday.
The last column indicates whether a given CPU has a incoherent instruction cache and pipeline. Such CPUs require special instructions be executed for self-modifying code.
Parenthesized CPU names indicate modes that are architecturally allowed, but rarely used in practice.
每种CPU都有自己特有的memory barrier指令,这也导致了想要写可移植代码比较困难。具体的信息可以参考下面的表格:
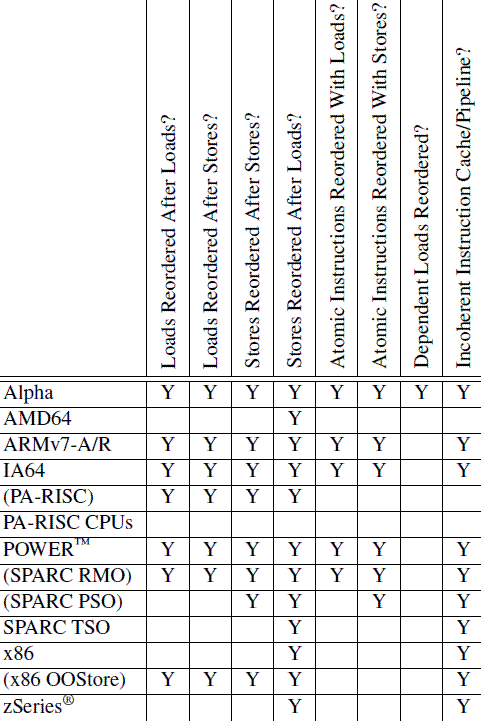
实际上,很多的软件环境,例如pthread、Java简单而粗暴的禁止了对memory barrier的直接使用,当然,对于有需要的场景,程序员也不能直接使用memory barrier,而是使用互斥原语,而互斥原语实际上是隐含了对memory barrier的使用。上面的表格描述了各种CPU对memory reorder行为的支持情况,第一列是CPU信息,后面的列是各种reorder的case,包括:
(1)load和store的4种组合。memory 访问指令就只有2种(对于RISC而言),load和store,运用简单的排列组合知识就可以知道有4种组合情况,load after store,load after load, store after load和store after store。
(2)内存访问是否可以和原子操作进行reorder。这类case有两种,一是是否允许store操作和原子操作进行reorder,另外一个是是否允许load操作和原子操作进行reorder。
(3)是否对有数据依赖关系的读操作进行重排。这个在绝大多数的CPU上都不支持,除了Alpha处理器。首先我们先解释一下什么是“data-dependent read”,请看下表:
| CPU 0 | CPU 1 |
| 给一个结构体S的各个成员赋值 将指针变量ps的值设定为结构体S的地址 |
load ps load S结构体的值 |
对于CPU1而言,读取指针变量ps的值和读取S结构体的值是两个有依赖关系的load操作,如果不load ps,其实是无法获取S结构体的值的,这也就是传说中的“data-dependent read”。对于CPU 0上的写入操作,两个操作是向不同的memory地址中写入数据,因此没有依赖性。
为了合理约定memory order,我们需要添加一些memory barrier的代码:
| CPU 0 | CPU 1 |
| 给一个结构体S的各个成员赋值 write memory barrier 将指针变量ps的值设定为结构体S的地址 |
load ps read memory barrier load S结构体的值 |
CPU1上的load ps操作要么看到旧指针,要么看到新指针。如果看到新的指针说明CPU0上的write memory barrier之后的赋值操作已经完成,在这样的条件下,CPU1上的rmb之后的load操作必然看到CPU0上wmb之前对结构体S成员赋的新值。由于数据的依赖性,对于大部分的CPU而言,去掉读一侧CPU1上的rmb也是没有问题的(使用单侧的memory barrier),CPU的硬件保证了读侧的load顺序。不幸的是对于Alpha而言,必须使用成对的memory barrier,即读的一侧需要使用阻止read depends类型的memory barrier。如果你觉得我在鬼扯,请去http://www.openvms.compaq.com/wizard/wiz_2637.html 下载Alpha的手册来仔细阅读。之所以采用了这么弱的memory model是为了在Alpha上使用更简单的cache硬件,而更简单的硬件使得Alpha可以采用更高的主频,从而让计算机跑的更快。
(4)最后一列是说明该CPU是否支持独立的icache和pipeline(这里的独立是相对于data cache而言,原文是incoherent,这里可能理解有误)。这种CPU需要为self-modifying的代码提供特殊的memory barrier指令
被括号围起来的CPU ARCH说明CPU虽然支持该mode,不过在实际中很少使用。
The common “just say no” approach to memory barriers can be eminently reasonable where it applies, but there are environments, such as the Linux kernel, where direct use of memory barriers is required. Therefore, Linux provides a carefully chosen least-common-denominator set of memory-barrier primitives, which are as follows:
在某些场合下,对memory barrier说“不”也是非常合理的,毕竟这个东东理解起来还是比较困难的,但是,有些场合,例如linux kernel中,有直接使用memory barrier的需求,就不能just say no了。对于linux kernel而言,它需要支持多种CPU体系结构的memory barrier的操作。虽然各自CPU arch有自己的memory barrier的设计,但是所有的CPU arch可以找到一个最小的集合,在这个集合中,每一个memory barrier的操作都可以被各个CPU arch所支持,它们是:
(1) smp_mb(): “memory barrier” that orders both loads and stores. This means that loads and stores preceding the memory barrier will be committed to memory before any loads and stores following the memory barrier.对load和store都有效的全功能memory barrier,执行了该memory barrier指令的CPU可以保证smp_mb之前的load和store操作将先于该指令之后的load或者store操作被提交到存储系统。
(2) smp_rmb(): “read memory barrier” that orders only loads.只规定load操作的memory barrier。
(3) smp_wmb(): “write memory barrier” that orders only stores.只规定store操作的memory barrier。
(4) smp_read_barrier_depends() that forces subsequent operations that depend on prior operations to be ordered. This primitive is a no-op on all platforms except Alpha. 如果前后两个memory access有依赖关系(例如前一个的操作是取后一个要操作memory的地址),那么smp_read_barrier_depends()这个memory barrier原语可以用来规定这两个有依赖关系的内存操作顺序。当然,除了Alpha,在其他的CPU上,该原语都是空。
(5) mmiowb() that forces ordering on MMIO writes that are guarded by global spinlocks. This primitive is a no-op on all platforms on which the memory barriers in spinlocks already enforce MMIO ordering. The platforms with a
non-no-op mmiowb() definition include some (but not all) IA64, FRV, MIPS, and SH systems. This primitive is relatively new, so relatively few drivers take advantage of it. mmiowb主要用于约束被spin lock保护的MMIO write操作顺序。当然,有些CPU architecture平台中,spinlock中的memory barrier操作已经保证了MMI的写入顺序,那么这个宏是空的。mmiowb是空的CPU architecture包括(但不限于)IA64, FRV, MIPS, and SH。这个原语比较新,因此在比较新的driver会使用它。
The smp_mb(), smp_rmb(), and smp_wmb() primitives also force the compiler to eschew any optimizations that would have the effect of reordering memory optimizations across the barriers. The smp_read_barrier_depends() primitive has a similar effect, but only on Alpha CPUs. See Section 14.2 for more information on use of these primitives.These primitives generate code only in SMP kernels, however, each also has a UP version (mb(), rmb(), wmb(), and read_barrier_depends(), respectively) that generate a memory barrier even in UP kernels. The smp_ versions should be used in most cases. However, these latter primitives are useful when writing drivers, because MMIO accesses must remain ordered even in UP kernels. In absence of memory-barrier instructions, both CPUs and compilers would happily rearrange these accesses, which at best would make the device act strangely, and could crash your kernel or, in some cases, even damage your hardware.
smp_mb(), smp_rmb(), 和 smp_wmb() 原语除了指导CPU的工作(规定cpu提交到到存储系统的操作顺序),它们对编译器也有作用(linux中的优化屏障barrier()),这些原语阻止了编译器为了优化而重排内存访问顺序。smp_read_barrier_depends有同样的效果,但是仅仅适用在Alpha处理器上。想要知道更多的关于这些原语使用的知识,请参考14.2章节。上面的这些smp_xxx的原语主要用在SMP的场合,在SMP的场景下会生成具体的memory barrier指令代码,在UP场合下,它们不会生成代码(仅仅是一个优化屏障而已)。smp_xxx的原语有对应的UP版本的memory barrier原语(mb(), rmb(), wmb(), 和read_barrier_depends()),这些UP版本的原语无论是SMP还是UP场合,都会生成具体的memory barrier指令代码。虽然大部分场景都是使用smp_xxx版本的memory barrier原语,但是,对于驱动工程师,由于需要规定MMIO的顺序(不仅适用SMP,也适用UP),因此,UP版本的memory barrier原语也经常使用。如果缺少了这些memory barrier原语,那么CPU和编译器都可以愉快的按照其自己的想法来对memory access顺序进行重排,而这样的行为轻则让设备行为异常,或者内核crash,重则造成硬件的损伤。
So most kernel programmers need not worry about the memory-barrier peculiarities of each and every CPU, as long as they stick to these interfaces. If you are working deep in a given CPU’s architecture-specific code, of course, all bets are off.
Furthermore, all of Linux’s locking primitives (spinlocks, reader-writer locks, semaphores, RCU, ...) include any needed barrier primitives. So if you are working with code that uses these primitives, you don’t even need to worry about Linux’s memory-ordering primitives.
因此,只要熟悉了linux kernel提供的architecture无关的memory barrier接口API(原语),那么大部分的内核开发者并不需要担心特定CPU上的memory barrier操作。当然,如果的你就是撰写特定CPU上的代码,上面的话不作数。
生活多么美好,开发kernel而不需要深入特定CPU的细节,稍等,还有令你心情更加愉悦的事情。其实内核中的所有的互斥原语(spinlocks, reader-writer locks, semaphores, RCU, ...)也都隐含了它们需要的memory barrier原语,因此,如果你的工作是直接使用这些互斥原语,那么你也根本不需要“鸟”那些linux提供的memroy barrier原语。
That said, deep knowledge of each CPU’s memory-consistency model can be very helpful when debugging, to say nothing of when writing architecture-specific code or synchronization primitives.
Besides, they say that a little knowledge is a very dangerous thing. Just imagine the damage you could do with a lot of knowledge! For those who wish to understand more about individual CPUs’ memory consistency models, the next sections describes those of the most popular and prominent CPUs. Although nothing can replace actually reading a given CPU’s documentation, these sections give a good overview.
行文至此,你肯定忍不住提出疑问:那为何我们还要专门描写一个特定CPU上memory barrier的章节呢?生活固然美好,但是,深入掌握每一个CPU的内存一致性模型对调试内核代码的时候帮助很大。当然,如果你是需要些特定CPU的代码或者同步原语,那更不必说了,该cpu的memory order和memory barrier的相关知识必须拿下。
除此之外,一知半解(掌握一点memory barrier的知识)是一个很危险的事情,想象一下,如果你掌握了大量的memory barrier知识所带来的破坏力(作者这里要表达什么我也搞不清楚,如果有理解的帮忙提点一下)。虽然有些工程师使用linux提供的原语快乐的工作着,但是,总是有些工程师期望能够理解更多关于各种CPU上的memory order和memory barrier相关的知识,我们下面的小节就是为你们准备的。下面的小节将描述各种主流CPU的memory barrier指令。需要注意的是:我们这里是概述,如果想要了解更多,可以下载具体CPU的文档来仔细研读。
1、 Alpha
It may seem strange to say much of anything about a CPU whose end of life has been announced, but Alpha is interesting because, with the weakest memory ordering model, it reorders memory operations the most aggressively. It therefore has defined the Linuxkernel memory-ordering primitives, which must work on all CPUs, including Alpha. Understanding Alpha is therefore surprisingly important to the Linux kernel hacker.
看起来现在讨论一个已经宣布死亡的CPU是有点奇怪,不过Alpha是一个非常有意思的产品,因为这款CPU有着世界上最弱的内存访问顺序模型。为了性能,Alpha处理器不择手段,丧心病狂的对内存操作进行重排。由于linux内核必须在包括Alpha在内的各种处理器上工作,因此linux下的memory barrier的原语其实是根据这款CPU而定义的。因此,对于那些内核狂热分子,理解Alpha是有非常重要的意义的。
The difference between Alpha and the other CPUs is illustrated by the code shown in Figure C.9. This smp_wmb() on line 9 of this figure guarantees that the element initialization in lines 6-8 is executed before the element is added to the list on line 10, so that the lock-free search will work correctly. That is, it makes this guarantee on all CPUs except Alpha.
Alpha has extremely weak memory ordering such that the code on line 20 of Figure C.9 could see the old garbage values that were present before the initialization on lines 6-8.
Alpha和其他处理器的不同之处可以通过下面的代码描述:
1 struct el *insert(long key, long data)
2 {
3 struct el *p;
4 p = kmalloc(sizeof(*p), GFP_ATOMIC);
5 spin_lock(&mutex);
6 p->next = head.next;
7 p->key = key;
8 p->data = data;
9 smp_wmb();
10 head.next = p;
11 spin_unlock(&mutex);
12 }
13
14 struct el *search(long key)
15 {
16 struct el *p;
17 p = head.next;
18 while (p != &head) {
19 /* BUG ON ALPHA!!! */
20 if (p->key == key) {
21 return (p);
22 }
23 p = p->next;
24 };
25 return (NULL);
26 }
在上面的代码片段中,第9行的smp_wmb可以保证6~8行的结构体成员初始化代码先执行,之后才执行第10行的代码,也就是讲结构体加入链表的代码。只有这样,才能保证没有使用lock的链表搜索操作的正确性。上面的代码在任何的处理器上都可以正确运行,除了Alpha。
Alpha处理器有着非常非常弱的内存访问顺序模型,这使得上面第20行代码的通过指针load key成员的操作可以看到旧的垃圾数据而不是6~8行的初始化的新值。
Figure C.10 shows how this can happen on an aggressively parallel machine with partitioned caches, so that alternating caches lines are processed by the different partitions of the caches. Assume that the list header head will be processed by cache bank 0, and that the new element will be processed by cache bank 1. On Alpha, the smp_wmb() will guarantee that the cache invalidates performed by lines 6-8 of Figure C.9 will reach the interconnect before that of line 10 does, but makes absolutely no guarantee about the order in which the new values will reach the reading CPU’s core. For example, it is possible that the reading CPU’s cache bank 1 is very busy, but cache bank 0 is idle. This could result in the cache invalidates for the new element being delayed, so that the reading CPU gets the new value for the pointer, but sees the old cached values for the new element. See the Web site called out earlier for more information, or, again, if you think that I am just making all this up.
怎么会这样呢?我们通过下面这幅图片向您展示这个问题是如何发生的:

上图展示的是一个使用分区cache的并行计算系统,这种系统的cache分成两个bank,不同的cache bank处理不同的cacheline。例如A cache line被bank 0处理,那么A+1的cache line会被bank 1处理。假设链表头head由cache bank 0来处理,而具体结构体的成员数据由bank 1来处理。在Alpha处理器上,smp_wmb() 可以确保上面6~8行的结构体成员初始化代码产生的invalidate message要早于第10行程序产生的invalidate message到达互连器件,但是,对于发起读操作那一侧的CPU core而言,并不能保证这些新值可以到达reading CPU core。例如说有可能发起读操作那一侧的CPU 的cache bank 1非常忙,但是bank0比较闲,这也就导致了结构体成员的invalidate message被推迟了,在这种情况下,CPU读到了新的指针数值,但是却看到了旧的数据。再强调一次,如果你觉得我在鬼扯,请去网上下载Alpha的手册来仔细阅读。
One could place an smp_rmb() primitive between the pointer fetch and dereference. However, this imposes unneeded overhead on systems (such as i386, IA64, PPC, and SPARC) that respect data dependencies on the read side. A smp_read_barrier_depends() primitive has been added to the Linux 2.6 kernel to eliminate overhead on these systems. This primitive may be used as shown on line 19 of Figure C.11.
当然,你也可以在获取结构体指针代码和通过指针访问结构体成员代码之间插入一个smp_rmb原语,但是,对于某些系统(例如i386、IA64、PPC和SPARC)而言,会带来不必要的开销。因为,在这些系统中,两个有依赖关系的load操作是可以保证访问顺序的,即便没有smp_rmb原语,cpu也不会大量其memory access的顺序。为了解决这个问题,从2.6的内核开始,新增一个smp_read_barrier_depends()的原语,具体代码如下:
1 struct el *insert(long key, long data)
2 {
3 struct el *p;
4 p = kmalloc(sizeof(*p), GFP_ATOMIC);
5 spin_lock(&mutex);
6 p->next = head.next;
7 p->key = key;
8 p->data = data;
9 smp_wmb();
10 head.next = p;
11 spin_unlock(&mutex);
12 }
13
14 struct el *search(long key)
15 {
16 struct el *p;
17 p = head.next;
18 while (p != &head) {
19 smp_read_barrier_depends();
20 if (p->key == key) {
21 return (p);
22 }
23 p = p->next;
24 };
25 return (NULL);
26 }
对于大部分CPU而言,smp_read_barrier_depends()是空操作,因此不会影响性能,在Alpha上,smp_read_barrier_depends()又可以保证有依赖关系的load的操作顺序,因此保证了程序逻辑上的正确性。
It is also possible to implement a software barrier that could be used in place of smp_wmb(), which would force all reading CPUs to see the writing CPU’s writes in order. However, this approach was deemed by the Linux community to impose excessive overhead on extremely weakly ordered CPUs such as Alpha. This software barrier could be implemented by sending inter-processor interrupts (IPIs) to all other CPUs. Upon receipt of such an IPI, a CPU would execute a memory-barrier instruction, implementing a memory-barrier shootdown. Additional logic is required to avoid deadlocks. Of course, CPUs that respect data dependencies would define such a barrier to simply be smp_wmb(). Perhaps this decision should be revisited in the future as Alpha fades off into the sunset.
The Linux memory-barrier primitives took their names from the Alpha instructions, so smp_mb() is mb, smp_rmb() is rmb, and smp_wmb() is wmb. Alpha is the only CPU where smp_read_barrier_depends() is an smp_mb() rather than
a no-op.
增加一个smp_read_barrier_depends的原语带来了一定的复杂度,毕竟,arch无关的memory barrier接口多了一个。基本上这种接口的原则就是:如果一个接口可以解决问题的不要使用2个。当然,社区的人不是没有想过这个问题,他们也曾经提出一种software barrier方案可以不修改读CPU一侧的行为,同时保证了所有的读一侧的CPUs看到正确的写入侧的CPU的写入顺序。这个方案是这样的:
(1)对于其他CPU而言,software barrier就是smp_wmb
(2)对于Alpha而言,software barrier是送往其他CPU的IPI中断。收到该中断的CPU都执行一个memory barrier指令
不过由于这个方案对于类似Alpha这样采用比较弱内存顺序模型的CPU而言,开销太大,因此,linux社区否定了这个方案。不过,随着Alpha处理器的衰落,未来这个方案可以拿出来再讨论一下。
linux kernel中的memory barrier原语的命名来自Alpha处理器的memory barrier汇编指令,smp_mb()就是mb,smp_rmb()就是rmb,smp_wmb()就是wmb。Alpha处理器是唯一定义smp_read_barrier_depends() 原语是smp_mb() 的处理器,其他处理上,smp_read_barrier_depends() 原语没有任何操作。
2、AMD64
TODO
3、ARMV7-A/R
The ARM family of CPUs is extremely popular in embedded applications, particularly for power-constrained applications such as cellphones. There have nevertheless been multiprocessor implementations of ARM for more than five years. Its memory model is similar to that of Power (see Section C.7.6, but ARM uses a different set of memorybarrier instructions [ARM10]:
(1) DMB (data memory barrier) causes the specified type of operations to appear to have completed before any subsequent operations of the same type. The “type” of operations can be all operations or can be restricted to only writes (similar to the Alpha wmb and the POWER eieio instructions). In addition, ARM allows cache coherence to have one of three scopes: single processor, a subset of the processors (“inner”) and global (“outer”).
(2)DSB (data synchronization barrier) causes the specified type of operations to actually complete before any subsequent operations (of any type) are executed. The “type” of operations is the same as that of DMB. The DSB instruction was called DWB (drain write buffer or data write barrier, your choice) in early versions of the ARM architecture.
(3)ISB (instruction synchronization barrier) flushes the CPU pipeline, so that all instructions following the ISB are fetched only after the ISB completes. For example, if you are writing a self-modifying program (such as a JIT), you should execute an ISB after between generating the code and executing it.
ARM处理器广泛应用在嵌入式设备中,特别是对功耗要求比较高的应用场景,例如手机。然而,只是在最近5年才除了了支持多核架构的ARM CPU。ARM的内存模型类似Power处理器(参考本章第六小节),不过ARM使用了不同的memory barrier指令,具体如下:
(1)DMB (data memory barrier) 。DMB指令可以在指定的作用域内(也就是shareability domain啦),约束指定类型的内存操作顺序。更详细的表述是这样的,从指定的shareability domain内的所有观察者角度来看,CPU先完成内存屏障指令之前的特定类型的内存操作,然后再完成内存屏障指令之后的内存操作。DMB指令需要提供两个参数:一个shareability domain,另外一个是access type。具体的内存操作类型(access type)可能是:store或者store + load。如果只是约束store操作的DMB指令,其效果类似Alpha处理器的wmb,或者类似POWER处理器的eieio指令。shareability domain有三种:单处理器、一组处理器(inner)和全局(outer)。
(2)DSB(data synchronization barrier)。DSB和DMB不一样,DSB更“狠”一些,同时对CPU的性能杀伤力更大一些。DMB是“看起来”如何如何,DSB是真正的对指令执行的约束。也就是说,首先执行完毕DSB之前的指定的内存访问类型的指令,等待那些指定类型的内存访问指令执行完毕之后,对DSB之后的指定类型内存访问的指令才开始执行。具体DSB的参数和DMB类似,这里就不赘述了。顺便一提的是,在ARM早期版本中,DSB被称为DWB(全称是drain write buffer 或者 data write barrier都OK,随你选择)。不过DWB并不能完全反应其功能,因为这条指令需要同步cache、TLB、分支预测以及显式的load/store内存操作,由此可见,DSB是一个更合适的名字。
(3)ISB (instruction synchronization barrier)。就对CPU的性能杀伤力而言,如果说DSB是原子弹,那么ISB杀更大,是属于氢弹了。ISB会flush cpu pipeline(也就是将指令之前的所有stage的pipeline都设置为无效),这会导致ISB指令之后的指令会在ISB指令完成之后,重新开始取指,译码……,因此,整个CPU的流水线全部会重新来过。可以举一个具体的应用例子:如果你要写一个自修改的程序(该程序会修改自己的执行逻辑,例如JIT),那么你需要在代码生成和执行这些生成的代码之间插入一个ISB。
None of these instructions exactly match the semantics of Linux’s rmb() primitive, which must therefore be implemented as a full DMB. The DMB and DSB instructions have a recursive definition of accesses ordered before and after the barrier, which has an effect similar to that of POWER’s cumulativity.
这些指令并不能精准的命中linux kernel中的rmb()原语,因此,对于ARM处理器,其rmb世界上是用mb(即全功能memory barrier)来实现的。在约束内存访问顺序上,DMB和DSB指令有一个递进的效果(DSB强于DMB),其概念类似POWER处理器上的cumulativity。
ARM also implements control dependencies, so that if a conditional branch depends on a load, then any store executed after that conditional branch will be ordered after the load. However, loads following the conditional branch will not be guaranteed to be ordered unless there is an ISB instruction between the branch and the load. Consider the following example:
程序的执行流中难免会遇到控制依赖关系(control dependencies),例如:在A指令执行结果满足某些条件的情况下,才执行B指令。ARM是这样处理控制依赖关系的:如果条件调整指令依赖某个load操作,那么任何该条件跳转指令之后的store操作将会在load操作之后完成(也就是说,control dependencies其效果类似smp_mb)。需要注意的是,在条件跳转指令之后的load操作没有这个限制,我们可以参考下面的代码:
1 r1 = x;
2 if (r1 == 0)
3 nop();
4 y = 1;
5 r2 = z;
6 ISB();
7 r3 = z;
In this example, load-store control dependency ordering causes the load from x on line 1 to be ordered before the store to y on line 4. However, ARM does not respect load-load control dependencies, so that the load on line 1 might well happen after the load on line 5. On the other hand, the combination of the conditional branch on line 2 and the ISB instruction on line 6 ensures that the load on line 7 happens after the load on line 1. Note that inserting an additional ISB instruction somewhere between lines 3 and 4 would enforce ordering between lines 1 and 5.
在这个例子中,load-store类型的控制依赖关系可以保证第四行的store y在第一行的load x之后执行。不过,ARM处理器对load-load类型的控制依赖关系并没有施加任何的内存访问顺序的保证,因此,第五行的load z操作可能先于第一行的load x执行。另一方面,结合第二行的条件跳转以及第六行的ISB指令,可以保证第七行的load z的操作在第一行的load x之后执行。请注意:在第三行和第四行之间插入额外的ISB可以确保第一行的load x和第五行load z之间的操作顺序。
4、IA64
IA64 offers a weak consistency model, so that in absence of explicit memory-barrier instructions, IA64 is within its rights to arbitrarily reorder memory references [Int02b]. IA64 has a memory-fence instruction named mf, but also has “half-memory fence” modifiers to loads, stores, and to some of its atomic instructions [Int02a]. The acq modifier prevents subsequent memory-reference instructions from being reordered before the acq, but permits prior memory-reference instructions to be reordered after the acq, as fancifully illustrated by Figure C.12. Similarly, the rel modifier prevents prior memory-reference instructions from being reordered after the rel, but allows subsequent memory-reference instructions to be reordered before the rel.
IA64提供了较弱的一致性模型,因此,在缺少memory barrier指令的情况下,IA64可以在许可范围内任意的重排内存的访问顺序。IA64提供了一条叫做mf的指令,此外还提供了支持half-memory fence功能的load、store以及一些原子操作。acq这个修饰符阻止了后面的内存访问指令越过acq修饰那条指令之前执行,不过,acq并不阻止前面的内存访问指令在acq修饰那条指令之后执行。具体可以参考下图:

LD, ACQ是一条隐含half-memory fence功能的load操作,该指令之前的内存操作可以delay至该指令之后执行,反之则不可以。类似的,还有一个rel的修饰符,也是提供了支持half-memory fence功能,不同的是rel是约束rel修饰的那条指令之前的内存访问操作不得越过该指令之后执行。
These half-memory fences are useful for critical sections, since it is safe to push operations into a critical section, but can be fatal to allow them to bleed out. However, as one of the only CPUs with this property, IA64 defines Linux’s semantics of memory ordering associated with lock acquisition and release.
half-memory fences应用在临界区上是非常合适的,将临界区的代码框在acq和rel定义的区域内,这样,临界区的代码的内存访问操作不会溢出。做为唯一一个支持这个属性的CPU(其实不是唯一的,ARMv8中也支持了,呵呵),IA64定义了linux中lock acquisition和release的在内存访问顺序上的语义。
The IA64 mf instruction is used for the smp_rmb(), smp_mb(), and smp_wmb() primitives in the Linux kernel. Oh, and despite rumors to the contrary, the “mf” mnemonic really does stand for “memory fence”.
对于IA64这个CPU architecture而言,linux中的smp_rmb(), smp_mb(), 和 smp_wmb() 这三个原语都是对应mf汇编指令。有些关于mf的谣言,不过实际上,mf就是memory fence的简写。
Finally, IA64 offers a global total order for “release” operations, including the “mf” instruction. This provides the notion of transitivity, where if a given code fragment sees a given access as having happened, any later code fragment will also see that earlier access as having happened. Assuming, that is, that all the code fragments involved correctly use memory barriers.
这段不是非常理解,TODO。
5、PA-RISC
Although the PA-RISC architecture permits full reordering of loads and stores, actual CPUs run fully ordered [Kan96]. This means that the Linux kernel’s memory-ordering primitives generate no code, however, they do use the gcc memory attribute to disable compiler optimizations that would reorder code across the memory barrier.
PA-RISC处理器保证了load和store的顺序,也就是说,实际上该CPU在执行程序的时候,内存访问是完全符合programmer order的,这也就是意味着在linux kernel的所有memory barrier的原语都是空的,没有任何代码。当然,必要的优化屏障还是需要的。
6、POWER / PowerPC
TODO
7、SPARC RMO, PSO, and TSO
TODO
8、x86
TODO
9、zSeries
TODO
九、Are Memory Barriers Forever?
There have been a number of recent systems that are significantly less aggressive about out-of-order execution in general and re-ordering memory references in particular. Will this trend continue to the point where memory barriers are a thing of the past?
The argument in favor would cite proposed massively multi-threaded hardware architectures, so that each thread would wait until memory was ready, with tens, hundreds, or even thousands of other threads making progress in the meantime. In such an architecture, there would be no need for memory barriers, because a given thread would simply wait for all outstanding operations to complete before proceeding to the next instruction. Because there would be potentially thousands of other threads, the CPU would be completely utilized, so no CPU time would be wasted.
在最近几个计算机系统上出现这样的现象:这些系统在out-of-order excution方面变得没有那么激进,特别是在对内存访问的重排方面。这些变化会不会导致memory barrier变成一个仅仅能从计算机历史找到的名词呢?
同意memory barrier退出历史舞台的那些人会认为目前硬件进入multi-threaded时代(注意这里的thread不是软件的thread),并且硬件线程数是越来越多,即便是一个线程上等待内存操作而暂停工作,但是系统中还有10个,几百个甚至上千其他的线程在继续前进。在这样的CPU架构下,根本没有memory barrier存在的必要了,因为对于任何一个线程,它都是等待该指令的操作完成之后,然后处理下一条指令。由于整个CPU系统存在数千个硬件线程可以使用,因此也没有浪费CPU的资源。
The argument against would cite the extremely limited number of applications capable of scaling up to a thousand threads, as well as increasingly severe realtime requirements, which are in the tens of microseconds for some applications. The realtimeresponse requirements are difficult enough to meet as is, and would be even more difficult to meet given the extremely low single-threaded throughput implied by the massive multi-threaded scenarios.
反对的人认为这将大大限制了应用程序的数目。同时,如果仅仅依靠硬件多线程,应用程序很难扩展到上千个线程(这里的线程是软件线程)。此外,也会大大增加实时响应时间,在有些应用中,甚至是几十个微妙的delay。实时系统响应时间的需求本来就很难满足,如果在multi-thread硬件情况下,single-thread的througput非常低,这时候响应时间更加难以符合实时系统的需要。
Another argument in favor would cite increasingly sophisticated latency-hiding hardware implementation techniques that might well allow the CPU to provide the illusion of fully sequentially consistent execution while still providing almost all of the performance advantages of out-of-order execution. A counter-argument would cite the increasingly severe power-efficiency requirements presented both by battery-operated devices and by environmental responsibility.
Who is right? We have no clue, so are preparing to live with either scenario.
还有另外的论点也是支持干掉memory barrier,这种观点认为虽然processor和memory的速度有差异,但是复杂度不断增加的latency-hiding硬件实现技术最终可以达成这样的效果:CPU可以提供一个完全顺序执行的假象,同时又不失乱序执行的性能优势。反对的声音认为这会增加功耗,不适合那些使用电池供电的设备,同时也不环保。
谁对谁错?我们也不知道,也许我们两种场景都会遇到。
十、Advice to Hardware Designers
There are any number of things that hardware designers can do to make the lives of software people difficult. Here is a list of a few such things that we have encountered in the past, presented here in the hope that it might help prevent future such problems:
硬件设计者如果设计思考不周,的确是有能力让软件工程师的生活变得异常的悲摧,做为一名软件工程师,在过去的工作中的确是遇到了一些这样的案例,我把它们罗列下来,希望能够防止其他硬件工程师犯同样的错误:
1. I/O devices that ignore cache coherence.
IO设备忽略了缓存一致性
This charming misfeature can result in DMAs from memory missing recent changes to the output buffer, or, just as bad, cause input buffers to be overwritten by the contents of CPU caches just after the DMA completes. To make your system work in face of such misbehavior, you must carefully flush the CPU caches of any location in any DMA buffer before presenting that buffer to the I/O device. Similarly, you need to flush the CPU caches of any location in any DMA buffer after DMA to that buffer completes. And even then, you need to be very careful to avoid pointer bugs, as even a misplaced read to an input buffer can result in corrupting the data input!
硬件工程师在设计I/O device的时候可能会build-in一个DMA控制器来辅助设备和memory之间的数据搬移。假设是从memory中搬移数据到设备上,假设硬件设计者不考虑cache coherence,那么DMA在搬运input memory的时候,将不能体现其最新的数据值(最新的在cache中)。在从设备搬移数据到memory中的时候会更糟糕,因为有可能会被CPU cache中的数据覆盖掉。在这种情况下,如果想让系统可以正常运作,你必须非常小心的操作DMA buffer,例如在DMA开始读取DMA buffer之前首先flush这段buffer的cache。即便如此,你仍然需要非常仔细,避免出现指针错误,因为即便是一个对DMA buffer错位的读操作都可以导致输入数据的破坏。
2. External busses that fail to transmit cache-coherence data.
外部总线无法发送cache-coherence数据
This is an even more painful variant of the above problem, but causes groups of devices—and even memory itself—to fail to respect cache coherence. It is my painful duty to inform you that as embedded systems move to multicore architectures, we will no doubt see a fair number of such problems arise. Hopefully these problems will clear up by the year 2015.
这是上一个问题的变种,而且更加令人痛苦。这个错误会导致一组设备,甚至是memory自己无法遵守cache coherence。因为痛苦的经历过,所以有责任告诉你,在从嵌入式系统转移的multicore体系结构的时候,毫无疑问,我们会遇到大量的这样的问题,希望这些问题能在2015年内解决掉。
3. Device interrupts that ignore cache coherence.
设备中断场景中忘记考虑cache coherence
This might sound innocent enough — after all, interrupts aren’t memory references, are they? But imagine a CPU with a split cache, one bank of which is extremely busy, therefore holding onto the last cacheline of the input buffer. If the corresponding I/O-complete interrupt reaches this CPU, then that CPU’s memory reference to the last cache line of the buffer could return old data, again resulting in data corruption, but in a form that will be invisible in a later crash dump. By the time the system gets around to dumping the offending input buffer, the DMA will most likely have completed.
这个错误听起来有些无辜,毕竟中断不是内存引用,不是吗?不过,设想一下,CPU使用了分bank的缓存机制,一个bank非常繁忙,因此,cpu无法将最新的数据写入cacheline。如果在这个时候,I/O完成的中断到达该CPU,然后该CPU会访问buffer中的数据,但是得到旧的值,从而导致data corruption,更可怕的是在随后的system crash的时候,你并不知道之前在interrupt handler中从buffer中copy数据发生了错误。当系统crash的时候再dump 恼人的输入的DMA buffer,DMA操作早已经完成了。
4. Inter-processor interrupts (IPIs) that ignore cache coherence.
IPI忘记考虑缓存一致性
This can be problematic if the IPI reaches its destination before all of the cache lines in the corresponding message buffer have been committed to memory.
正确的顺序应该是首先将对应message buffer中的cache line提交到内存,然后指定的CPU收到IPI中断,如果顺序反了就会存在问题。
5. Context switches that get ahead of cache coherence.
没有处理缓存一致性就进行了上下文切换
If memory accesses can complete too wildly out of order, then context switches can be quite harrowing. If the task flits from one CPU to another before all the memory accesses visible to the source CPU make it to the destination CPU, then the task could easily see the corresponding variables revert to prior values, which can fatally confuse most algorithms.
如果内存访问操作被严重的乱序执行,那么上下文切换会处理一些令人烦恼的问题。比如说一个task从一个CPU迁移到另外一个CPU上执行,虽然完成了切换,但是source CPU可见的内存操作在destination CPU上不可见,在这种情况下,执行程序很容易就看到这样的怪事:明明已经读到新值了,但是再次访问同样的内存,得到的确是旧值,这样内存顺序是任何算法都无法承受的。
6. Overly kind simulators and emulators.
模拟器和仿真器无法仿真真实的硬件环境
It is difficult to write simulators or emulators that force memory re-ordering, so software that runs just fine in these environments can get a nasty surprise when it first runs on the real hardware. Unfortunately, it is still the rule that the hardware is more devious than are the simulators and emulators, but we hope that this situation changes.
撰写支持乱序执行的模拟器和仿真器还是有些困难的,因此,如果软件可以正确的在仿真环境中运行正常,或许在真实硬件上运行的时候会遇到各种奇奇怪怪的问题。很遗憾,真实的硬件永远都是比模拟器和仿真器更加复杂,曲折,因此这个情况始终存在,希望后续会慢慢好转。
Again, we encourage hardware designers to avoid these practices!
再次强调,希望硬件设计者避免发生上述错误。