Datawhale_大数据0期
【Task1】创建虚拟机+熟悉linux(2day)
- 创建三台虚拟机
- 在本机使用Xshell连接虚拟机
- CentOS7配置阿里云yum源和EPEL源
- 安装jdk
- 熟悉linux 常用命令
- 熟悉,shell 变量/循环/条件判断/函数等
shell小练习1:
编写函数,实现将1-100追加到output.txt中,其中若模10等于0,则再追加输出一次。即10,20…100在这个文件中会出现两次。
注意:
电脑系统需要64位(4g
文章目录
- 【Task1】创建虚拟机+熟悉linux(2day)
- vmware 安装
- 安装镜像
- 连接secureCRT
- 安装slave
- 设置共享文件夹
- 安装java
- CentOS7配置阿里云yum源和EPEL源
- 熟悉linux 常用命令
- 熟悉,shell 变量/循环/条件判断/函数等
- 【Task 2】搭建Hadoop集群(3day)
- 安装hadoop 2.0
- 关闭可能阻碍的网络传输
- 建立ssh互信
- 验证Hadoop集群启动(1.0)
- 验证Hadoop集群启动(2.0)
- vim 配置
- hosts
- 阅读Google三大论文,并总结
- Hadoop的作用(解决了什么问题)/运行模式/基础组件及架构
- 学会阅读HDFS源码,
- Hadoop中各个组件的通信方式,RPC/Http等
- WordCount(分布式/单机运行模式)
- Hadoop2.0 操作mapreduce
- 理解MapReduce的执行过程
- Yarn在Hadoop中的作用
- 【Task 3】HDFS常用命令/API+上传下载过程
- 认识HDFS
- 熟悉hdfs常用命令
- Python操作HDFS的其他API
- Hadoop2.x的版本中,文件块的默认大小是128M
- HDFS 各进程的作用
- NameNode是如何组织文件中的元信息的,edits log与fsImage的区别?使用hdfs oiv命令观察HDFS上的文件的metadata
- HDFS文件上传下载过程,源码阅读与整理。
- 【Task4】MapReduce+MapReduce执行过程
- MR原理
- 使用Hadoop Streaming -python写出WordCount
- 使用mr计算movielen中每个用户的平均评分。
- 使用mr实现merge功能。根据item,merge movielen中的 u.data u.item
- 使用mr实现去重任务。
- 使用mr实现排序。
- 使用mapreduce实现倒排索引。
- 使用mapreduce计算Jaccard相似度
- 使用mapreduce实现PageRank
- 【Task5】Spark常用API
- spark集群搭建
- 安装scala
- 安装spark
- 启动spark
- yarn-client
- scala
- sbt
- 初步认识Spark
- 理解spark的RDD
- 使用shell方式操作Spark,熟悉RDD的基本操作
- spark RDD的常用操作
- Learning Spark——使用spark-shell运行Word Count
- 使用jupyter连接集群的pyspark
- 理解Spark的shuffle过程
- 学会使用SparkStreaming
- 4.使用spark-Streaming进行流式wordcount计算
- 说一说take,collect,first的区别,为什么不建议使用collect?
- 向集群提交Spark程序
- 使用spark计算《The man of property》
- 1.在集群上 面运行
- 计算出movielen数据集中,平均评分最高的五个电影。
- 计算出movielen中,每个用户最喜欢的前5部电影
- 学会阅读Spark源码,整理Spark任务submit过程
- 【Task6】Hive原理及其使用
- 安装MySQL、Hive
- 【Task7】实践
- 计算每个content的CTR。
- 【选做】 使用Spark实现ALS矩阵分解算法 movielen
- 使用Spark分析Amazon DataSet(实现 Spark LR、Spark TFIDF)
- Spark LR
- Spark TFIDF
- END参考
vmware 安装
安装步骤
https://blog.csdn.net/qq_40950957/article/details/80467513
一直下一步即可
软件下载地址
http://www.pansoso.com/a/1144532/
安装镜像
# 镜像拷贝到D:\VM ==>命名CentOS_6.5_yam-m,CentOS_6.5_yam-s1,CentOS_6.5_yam-s2
# 主页-->打开虚拟机-->CentOS 64 位.vmx-->复制虚拟机-->右键重命名为yam-m-点击查看(立即适应客户机)
# 配置nat
-右击右下角小电脑里的设置-->网络适配器-nat模式
-左上角编辑-->虚拟网络编辑器-->右下角的更改设置-->移除网络-->选择nat模式-->选择vmnet8
-先桥接模式初始化-->再改为nat
[badou@localhost media]$ ifconfig
eth0 Link encap:Ethernet HWaddr 00:0C:29:00:AD:A0
inet6 addr: fe80::20c:29ff:fe00:ada0/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 # 当前没有分配ip
-[badou@localhost media]$ cd /etc/sysconfig/network-scripts/
切换为root 用户
[root@localhost network-scripts]# vim ifcfg-eth0
DEVICE="eth0"
BOOTPROTO="static" # 改为static
HWADDR="00:0C:29:00:AD:A0" # 删除
IPV6INIT="yes" # 删除
TYPE="Ethernet"
IPADDR=192.168.28.100
NETMASK=255.255.255.0
GATEWAY=192.168.28.2
DNS1=202.106.0.20
ctrl + shift + t 新建终端
[badou@localhost network-scripts]$ su
Password:
[root@localhost network-scripts]# /etc/init.d/network restart
Shutting down interface eth0: Device state: 3 (disconnected)
[ OK ]
Shutting down loopback interface: [ OK ]
Bringing up loopback interface: [ OK ]
Bringing up interface eth0: Active connection state: activating
Active connection path: /org/freedesktop/NetworkManager/ActiveConnection/15
state: activated
Connection activated
[ OK ]
[root@localhost network-scripts]#
[root@localhost network-scripts]# ifconfig
eth0 Link encap:Ethernet HWaddr 00:0C:29:00:AD:A0
# ip 地址与我们设置的一样
inet addr:192.168.28.100 Bcast:192.168.28.255 Mask:255.255.255.0
# 无法联网
https://blog.csdn.net/lan_xi/article/details/80826049
3、rm -f /etc/udev/rules.d/70-persistent-net.rules 删除该文件(或者重命名):cat /etc/udev/rules.d/70-persistent-net.rules
4、reboot重启服务器
5、service network restart重启网络服务
http://www.cnblogs.com/pizitai/p/6519941.html # 80端口未开
https://blog.csdn.net/u012914436/article/details/87901343 # 虚拟机未开启网络服务
https://blog.csdn.net/u012914436/article/details/88306127 # Linux永久关闭防火墙
连接secureCRT
安装secureCRT及破解
https://www.cnblogs.com/qingtingzhe/articles/5008902.html
新建连接
hostname 192.168.28.100
username badou
connet
password:111111
connect&save
[badou@bogon ~]$ ls
Desktop Documents Downloads Music Pictures Public Templates Videos
[badou@bogon ~]$ ifconfig
eth0 Link encap:Ethernet HWaddr 00:0C:29:0E:D3:07
inet addr:192.168.28.100 Bcast:192.168.28.255 Mask:255.255.255.0
inet6 addr: fe80::20c:29ff:fe0e:d307/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:17595 errors:0 dropped:0 overruns:0 frame:0
TX packets:3882 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:10516227 (10.0 MiB) TX bytes:221934 (216.7 KiB)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:10 errors:0 dropped:0 overruns:0 frame:0
TX packets:10 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:582 (582.0 b) TX bytes:582 (582.0 b)
[badou@bogon ~]$
[badou@bogon ~]$ pwd
/home/badou
[badou@bogon ~]$
[badou@bogon ~]$ curl www.baidu.com
# 出现乱码
点击上面的IP 右键--->session options(设置终端环境)
Terminal-->Emulation-->在右边选择linux-->scrollback buffer 128000
Appearance -->current color scheme(traditional)-->character encoding (utf-8)
-->font(yahei consolas hybrid) 四号
-->cursor(光标)--usecolor打勾--点color选择绿色
--> ansi color 深蓝改为把颜色调浅(上面一个淡蓝即可)
[badou@bogon ~]$ curl www.baidu.com # 正常显示
安装slave
挂起master
复制两份master,分别命名为CentOS_6.5_yam-s1,CentOS_6.5_yam-s2
复制完后校验资料包是否一样大
vmware 打开另两台slave
# 为使slave 能正常上网,先修改其IP
[root@bogon Desktop]# cd /etc/sysconfig/network-scripts/
[root@bogon network-scripts]# vim ifcfg-eth0
DEVICE="eth0"
IPV6INIT="yes"
NM_CONTROLLED="yes"
ONBOOT="yes"
TYPE="Ethernet"
IPADDR=192.168.28.101 # IP:101
NETMASK=255.255.255.0
GATEWAY=192.168.28.2
DNS1=202.106.0.20
# 重启网卡
[root@bogon network-scripts]# /etc/init.d/network restart
Shutting down interface eth0: [ OK ]
Shutting down loopback interface: [ OK ]
Bringing up loopback interface: [ OK ]
Bringing up interface eth0: Determining if ip address 192.168.28.101 is already in use for device eth0...
[ OK ]
[root@bogon network-scripts]#
# 因为完全拷贝,网卡一样,故mac 地址也一样,先需要卸载网卡
点击右小角小电脑,--网络适配器移除,再添加
# 若ifconfig出现找不到mac 或重启网卡出现failed 可
rm -f /etc/udev/rules.d/70-persistent-net.rules
reboot重启服务器
https://blog.csdn.net/lan_xi/article/details/80826049
# [badou@bogon Desktop]$ curl www.baidu.com # 若curl 不通可先ping下,若能ping 通,可能网络慢,再curl下
# 连接secureCRT
拷贝master的secureCRT 并修改host
设置共享文件夹
在master 节点上点右键设置--选项--共享文件夹--总是启用--添加--下一步--浏览--选择D:\py1805\badou\share_folder--下一步完成确定
安装java
[root@bogon src]# pwd
/usr/local/src
# 解压
[root@bogon bin]# tar xvzf jdk1.7.0_45.tgz
# 启动java
[root@bogon jdk1.7.0_45]# ./java
# 查看java 版本
[root@bogon bin]# ./java -version
java version "1.7.0_45"
Java(TM) SE Runtime Environment (build 1.7.0_45-b18)
Java HotSpot(TM) 64-Bit Server VM (build 24.45-b08, mixed mode)
[root@bogon bin]#
# 添加java到环境变量
[root@bogon bin]# vim ~/.bashrc
export JAVA_HOME=/usr/local/src/jdk1.7.0_45
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin
# 添加hadoop 路径
export PATH=${JAVA_HOME}/bin:$PATH
export PATH=PATH=$PATH:$HOME/bin:/usr/local/src/hadoop-2.6.1/bin
# 生效环境变量
[root@bogon bin]# source ~/.bashrc
# 在其他目录启动java,是否可启动,若启动则环境变量ok
[root@bogon src]# java
# 拷贝到slave
# -r 递归复制整个目录。 -p:保留原文件的修改时间,访问时间和访问权限。
[root@bogon src]# scp -rp jdk1.7.0_45 192.168.28.101:/usr/local/src
[root@bogon src]# scp -rp jdk1.7.0_45 192.168.28.102:/usr/local/src
# 把bashec里java 的环境变量也拷贝到slvae
[root@bogon src]# cat ~/.bashrc
# .bashrc
# User specific aliases and functions
alias rm='rm -i'
alias cp='cp -i'
alias mv='mv -i'
# Source global definitions
if [ -f /etc/bashrc ]; then
. /etc/bashrc
fi
# 拷贝此三行
export JAVA_HOME=/usr/local/src/jdk1.7.0_45
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin
[root@bogon src]#
# slave1
[root@bogon jdk1.7.0_45]# vim ~/.bashrc
[root@bogon jdk1.7.0_45]# source ~/.bashrc
[root@bogon jdk1.7.0_45]# java
# slave2
[root@bogon jdk1.7.0_45]# vim ~/.bashrc
[root@bogon jdk1.7.0_45]# source ~/.bashrc
[root@bogon jdk1.7.0_45]# java
CentOS7配置阿里云yum源和EPEL源
https://www.cnblogs.com/jimboi/p/8437788.html
熟悉linux 常用命令
ls # 列出当前目录下的文件
cd A # 切换到目录A
cd … 上一层目录
mv A B # 移动文件A到B目录下
tar -zxvf *.tar.gz # 解压压缩包
mkdir # 创建目录
https://www.jianshu.com/p/da6db3f56fad
熟悉,shell 变量/循环/条件判断/函数等
[root@master20 bigdata]# pwd
/home/badou/datawhale/bigdata
vim test_func.sh
#! /bin/bash
echo "测试写入output.txt文件"
for((i=1;i<=100;i++));
do
echo $i >> output.txt
b=$(( $i % 10 ))
if [ $b = 0 ];then
echo $i >> output.txt
fi
done
[root@master20 bigdata]# /bin/sh test_func.sh
[root@master20 bigdata]# ls
output.txt test_func.sh
[root@master20 bigdata]# cat output.txt
1
2
3
4
5
6
7
8
9
10
10
...
96
97
98
99
100
100
【Task 2】搭建Hadoop集群(3day)
- 搭建HA的Hadoop集群并验证,3节点(1主2从),理解HA/Federation,并截图记录搭建过程
- 阅读Google三大论文,并总结
- Hadoop的作用(解决了什么问题)/运行模式/基础组件及架构
- 学会阅读HDFS源码,并自己阅读一段HDFS的源码(推荐HDFS上传/下载过程)【可选】
- Hadoop中各个组件的通信方式,RPC/Http等
- 学会写WordCount(Java/Python-Hadoop Streaming),理解分布式/单机运行模式的区别
- 理解MapReduce的执行过程
- Yarn在Hadoop中的作用
- 参考资料:Google三大论文
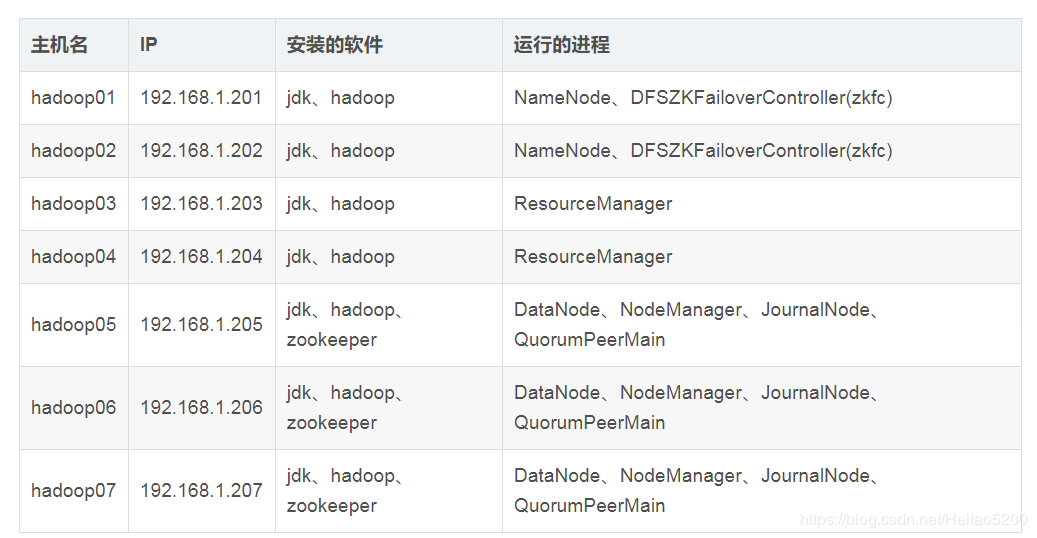
集群规划1-省机器:
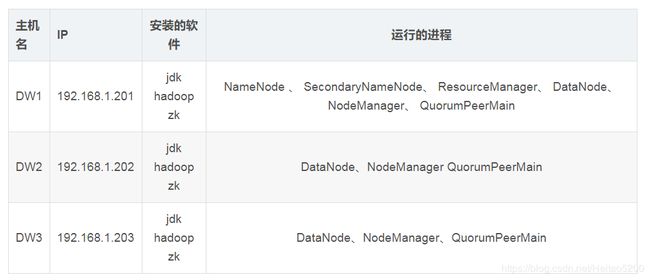
集群规划2-清晰:
【截止时间】任务时间是3天(最终以石墨文档的记录为准)1)2019.7.28 周日 22:00 前提交博客/Github链接(描述:任务、遇到的问题、实现代码和参考资料)2)2019.7.29 中午12:00 前点评完毕 **【考核方式】**1)链接发到群里同时@点评人 + 在群里对下一号学员进行点评2)并在下面贴上自己链接、对他人的点评
【学员打卡】 参考作业分享http://t.cn/EUBStT7xxx点评优点:xxx号排版简单明了缺点:如果能将模型结果贴出来,做一些简单的分析就更完美了。疑问:roc_auc_score的第二个参数能传y_predict吗?-----------------点评也是一门学问,认真对待每一次队友给你点评的机会,加油!!!
安装hadoop 2.0
[root@bogon src]# pwd
/usr/local/src
[root@bogon src]# tar xvzf hadoop-2.6.1.tar.gz
[root@bogon src]# cd hadoop-2.6.1
[root@bogon hadoop-2.6.1]# ls
bin include libexec NOTICE.txt sbin
etc lib LICENSE.txt README.txt share
#_0 存放Hadoop临时目录
## 1.0
[root@master hadoop-1.2.1]# pwd
/usr/local/src/hadoop-1.2.1
[root@master hadoop-1.2.1]# mkdir tmp
## 2.0 (创建tmp 与dfs/name,dfs/data 目录, tmp 与dfs 是同级目录)
### tmp
[root@master20 hadoop-2.6.1]# pwd
/usr/local/src/hadoop-2.6.1
[root@bogon hadoop-2.6.1]# mkdir tmp
### dfs
[root@master20 hadoop-2.6.1]# pwd
/usr/local/src/hadoop-2.6.1
[root@master20 hadoop-2.6.1]# mkdir -p dfs/name
[root@master20 hadoop-2.6.1]# mkdir -p dfs/data
###hadoop 2.0 没conf 目录
# cd conf/
#_1 maste (1.0有, 2.0 无)
[root@master conf]# pwd
/usr/local/src/hadoop-1.2.1/conf
## 1.0
[root@master conf]# vim masters
1 master ## 将localhost 改为master(2.0 无)
#_2 slaves (都有, 但路径不同)
## 1.0
[root@master conf]# pwd
/usr/local/src/hadoop-1.2.1/conf
[root@master conf]# vim slaves
1 slave1
2 slave2
## 2.0
[root@bogon hadoop]# pwd
/usr/local/src/hadoop-2.6.1/etc/hadoop
[root@bogon hadoop]# vim slaves
slave21
slave22
#_3 core-site.xmls (配置临时文件,datanode: 都有, 路径不同)
## 1.0
[root@master conf]# pwd
/usr/local/src/hadoop-1.2.1/conf
6 <configuration>
7 <property>
8 <name>hadoop.tmp.dir</name>
9 <value>/usr/local/src/hadoop-1.2.1/tmp</value>
10 </property>
11 <property>
12 <name>fs.default.name</name>
13 <value>hdfs://192.168.28.10:9000</value>-------
14 </property>
15 <property>
16 <name>fs.trash.interval</name>
17 <value>1440</value>-------
18 </property>
19 </configuration>
## 2.0
[root@bogon hadoop-2.6.1]# cd /usr/local/src/hadoop-2.6.1/etc/hadoop/
[root@bogon hadoop]# vim core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/src/hadoop-2.6.1/tmp</value>
</property>
<property>
<name>fs.defaultFS</name> # 默认hdfs路径比fs.default.name好一些
<value>hdfs://master20:9000</value> # 临时目录
</property>
</configuration>
#_4 mapred-site.xml (配置jobtracker: 1.0有, 2.0模板拷贝)
## 1.0
[root@master conf]# pwd
/usr/local/src/hadoop-1.2.1/conf
[root@master conf]# vim mapred-site.xml
1 <?xml version="1.0"?>
2 <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
3
4 <!-- Put site-specific property overrides in this file. -->
5
6 <configuration>
7 <property>
8 <name>mapred.job.tracker</name>
9 <value>http://192.168.28.10:9001</value>
10 </property>
11 </configuration>
## 2.0
[root@master20 hadoop]# pwd
/usr/local/src/hadoop-2.6.1/etc/hadoop
[root@master20 hadoop]# cp mapred-site.xml.template mapred-site.xml
[root@master20 hadoop]# vim mapred-site.xml
19 <configuration>
20 <property>
21 <name>mapreduce.framework.name</name>
22 <value>yarn</value>
23 </property>
24 </configuration>
#_5 hdfs-site.xml (数据在hdfs中配置副本数 :有,但路径不同)
## 1.0
[root@master conf]# vim hdfs-site.xml
1 <?xml version="1.0"?>
2 <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
3
4 <!-- Put site-specific property overrides in this file. -->
5
6 <configuration>
7 <property>
8 <name>dfs.replication</name>
9 <value>3</value>-------
10 </property>
11 <property>
12 <name>dfs.datanode.max.xcievers</name>
13 <value>4096</value>-------
14 </property>
15 </configuration>
## 2.0
[root@bogon hadoop]# pwd
/usr/local/src/hadoop-2.6.1/etc/hadoop
[root@bogon hadoop]# vim hdfs-site.xml
19 <configuration>
20 <property>
21 <name>dfs.namenode.secondary.http-address</name> # 做备份,进程,端口号
22 <value>master20:9001</value>
23 </property>
24 <property>
25 <name>dfs.namenode.name.dir</name> # 存一些镜像
26 <value>file:/usr/local/src/hadoop-2.6.1/dfs/name</value>
27 </property>
28 <property>
29 <name>dfs.datanode.data.dir</name>
30 <value>file:/usr/local/src/hadoop-2.6.1/dfs/data</value>
31 </property>
32 <property>
33 <name>dfs.replication</name>
34 <value>3</value> # 副本数3个
35 </property>
36 </configuration>
netstat -natup | grep 9001
#_6 Hadoop-env.sh (在最后添加java_home 都有, 但路径不同)
## 1.0
[root@master conf]# pwd
/usr/local/src/hadoop-1.2.1/conf
[root@master conf]# vim hadoop-env.sh
57 # export HADOOP_NICENESS=10
58 export JAVA_HOME=/usr/local/src/jdk1.6.0_45
## 2.0
25 export JAVA_HOME=/usr/local/src/jdk1.7.0_45
# 查看修改过的文件
[root@bogon hadoop]# ls -rlt
#_7 hostsname (本地网络配置: 都有, 一样)
## 1.0
[root@master conf]# vim /etc/hosts
1 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomai
n4
2 ::1 localhost localhost.localdomain localhost6 localhost6.localdomai
n6
3 192.168.28.10 master
4 192.168.28.11 slave1
5 192.168.28.12 slave2
## 2.0
[root@bogon etc]# vim /etc/hosts
192.168.28.100 master20
192.168.28.101 slave21
192.168.28.102 slave22
# hostname 使别名临时生效
[root@master conf]# hostname master(master20)
master
[root@master conf]# hostname (1.0)
master
[root@bogon /]# hostname (2.0)
master20
#_8 hostname 别名永久生效
## 1.0
[root@master conf]# vim /etc/sysconfig/network
1 NETWORKING=yes
2 HOSTNAME=master
## 2.0
[root@bogon /]# vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=master20
#_9 yarn-en.sh (1.0无,2.0 有)
## 1.0 无
## 2.0 有
[root@master20 hadoop]# pwd
/usr/local/src/hadoop-2.6.1/etc/hadoop
[root@master20 hadoop]# vim yarn-env.sh
23 export JAVA_HOME=/usr/local/src/jdk1.7.0_45
#_10 yarn-site.xml (1.0无, 2.0 有)
yarn-site.xml 45,1 Bot
[root@master20 hadoop]# pwd
/usr/local/src/hadoop-2.6.1/etc/hadoop
[root@master20 hadoop]# vim yarn-site.xml
1 <?xml version="1.0"?>
2 <!--
3 Licensed under the Apache License, Version 2.0 (the "License");
4 you may not use this file except in compliance with the License.
5 You may obtain a copy of the License at
6
7 http://www.apache.org/licenses/LICENSE-2.0
8
9 Unless required by applicable law or agreed to in writing, software
10 distributed under the License is distributed on an "AS IS" BASIS,
11 WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 See the License for the specific language governing permissions and
13 limitations under the License. See accompanying LICENSE file.
14 -->
15 <configuration>
16 <property>
17 <name>yarn.nodemanager.aux-services</name>
18 <value>mapreduce_shuffle</value>
19 </property>
20 <property>
21 <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
21 <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
22 <value>org.apache.hadoop.mapred.ShuffleHandler</value>
23 </property>
24 <property>
25 <name>yarn.resourcemanager.address</name>
26 <value>master20:8032</value>
27 </property>
28 <property>
29 <name>yarn.resourcemanager.scheduler.address</name>
30 <value>master20:8030</value>
31 </property>
32 <property>
33 <name>yarn.resourcemanager.resource-tracker.address</name>
34 <value>master20:8035</value>
35 </property>
36 <property>
37 <name>yarn.resourcemanager.admin.address</name>
38 <value>master20:8033</value>
39 </property>
40 <property>
41 <name>yarn.resourcemanager.webapp.address</name>
42 <value>master20:8088</value>
43 </property>
44 <!-- Site specific YARN configuration properties -->
45
46 </configuration>
yarn-site.xml 45,1
# 将hadoop 复制到slave 里
[root@bogon src]# pwd
/usr/local/src
[root@bogon src]# scp -rp hadoop-2.6.1 192.168.28.101:/usr/local/src
[root@bogon src]# scp -rp hadoop-2.6.1 192.168.28.102:/usr/local/src
# 将slave 里的hosts(slave1与slave2,相同)
[root@bogon hadoop]# vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.28.100 master20
192.168.28.101 slave21
192.168.28.102 slave22
#slave21
[root@bogon hadoop]# vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=slave21
[root@bogon hadoop]# hostname slave21
[root@bogon hadoop]# hostname
slave21
# slave22
[root@bogon hadoop]# vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=slave22
[root@bogon hadoop]# hostname slave22
[root@bogon hadoop]# hostname
slave22
关闭可能阻碍的网络传输
# 关闭防火墙(https://blog.csdn.net/qq_37928350/article/details/78830896)
## 临时关闭(每台都要执行)
[root@bogon src]# service iptables stop
## 永久关闭
[root@bogon hadoop]# chkconfig iptables off
## 查看防火墙状态
[root@bogon src]# service iptables status
iptables: Firewall is not running.
## 查看网络传输
[root@bogon src]# iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
[root@bogon src]#
# 影响网络传输,除了iptables 还有setenforce
[root@bogon src]# setenforce 0
[root@bogon hadoop]# getenforce
Permissive # 处于关闭状态
建立ssh互信
每台机器均需
[root@bogon src]# ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
bb:71:8e:96:2c:83:ba:47:08:64:4f:b9:aa:71:b1:54 root@master20
The key's randomart image is:
+--[ RSA 2048]----+
| . |
| o oE |
|o o.. |
|. oo |
| o.+ S |
|..+ . . |
|.o . . .o.. |
|. o o +* |
| o+ +o . |
+-----------------+
[root@bogon src]#
[root@bogon src]# cd ~/.ssh
[root@bogon .ssh]# ls
id_rsa(私钥) id_rsa.pub(公钥) known_hosts
# 将公钥复制到authoorized_keys(授权钥匙)中
[root@bogon .ssh]# cat id_rsa.pub > authorized_keys
# 查看是否一致
[root@bogon .ssh]# cat id_rsa.pub
ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAzuPAe5B8EWywn8veH8/FZ/UZXhdJmdQiRJeCD8LsUPvpjE7al5V9orKU9WI6Ysh1JbZbclFsN28Hiqww2lxn6NUBEUGgFmX+8xGlfuwjuJ2JXk/b8tUufA+A3yorhMyUgjtv7orNq5liwvDff7DP4AXO7OzITaqwzRKqHn5u7gMj21ZAXrNBvPQAaQ9YZO3KUTJsl9RrFCEMtzs5ZDK7jBgeuhVFLnBb84dHBzEoQeUdYtDrjVaSSn1OvphdRyC0kM/7aBxO6waRCbPZakVcLuzLG8mANccRggAI/qXeAsWgX+DrcB2eVw0ybVdAXVIufmTGb2AdpJF2qfcPI/D8aw== root@master20
[root@bogon .ssh]# cat authorized_keys
ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAzuPAe5B8EWywn8veH8/FZ/UZXhdJmdQiRJeCD8LsUPvpjE7al5V9orKU9WI6Ysh1JbZbclFsN28Hiqww2lxn6NUBEUGgFmX+8xGlfuwjuJ2JXk/b8tUufA+A3yorhMyUgjtv7orNq5liwvDff7DP4AXO7OzITaqwzRKqHn5u7gMj21ZAXrNBvPQAaQ9YZO3KUTJsl9RrFCEMtzs5ZDK7jBgeuhVFLnBb84dHBzEoQeUdYtDrjVaSSn1OvphdRyC0kM/7aBxO6waRCbPZakVcLuzLG8mANccRggAI/qXeAsWgX+DrcB2eVw0ybVdAXVIufmTGb2AdpJF2qfcPI/D8aw== root@master20
[root@bogon .ssh]#
# 将salve的authorized_keys 都拷贝到master上
[root@bogon .ssh]# vim authorized_keys
ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAzuPAe5B8EWywn8veH8/FZ/UZXhdJmdQiRJeCD8LsUPvp
jE7al5V9orKU9WI6Ysh1JbZbclFsN28Hiqww2lxn6NUBEUGgFmX+8xGlfuwjuJ2JXk/b8tUufA+A3yor
hMyUgjtv7orNq5liwvDff7DP4AXO7OzITaqwzRKqHn5u7gMj21ZAXrNBvPQAaQ9YZO3KUTJsl9RrFCEM
tzs5ZDK7jBgeuhVFLnBb84dHBzEoQeUdYtDrjVaSSn1OvphdRyC0kM/7aBxO6waRCbPZakVcLuzLG8mA
NccRggAI/qXeAsWgX+DrcB2eVw0ybVdAXVIufmTGb2AdpJF2qfcPI/D8aw== root@master20
ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAvNLw9m3Giwt/7QeRMUbAYAQi64jDSJZt04g6gjwsibmZ
3Z9jkAoLmq+HZiW8OmNy0HdD6or9vhl1eVwnNKeyjplyhPdCITRxIqcfTt8hKzFJ8XK/9QybbmHoiBnC
75H2iCvjwy5QkIqT1cnRGP9ZrTTw2fA2U4CSuU3GMqtSzAtkqZ6v/lBZBtKf5pqQsaOtXvQJcKhArp/A
jCFp7XSpaoJX0IiseB5NxrNrdSMyMEFjT2PhZ0+rdqCc01OXmPqcd/6Ho3cMdDF8CoO6sg1e0tVPkdSp
ajjeOQvGE8VLzfr2um35tjGhBKU4zhBTPPqrrC5iZt594Z4CEVSaYFY43w== root@slave21
ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEA516JVW7RQCKN0+deXlAHJiqplUjhKWCTRGQ/v6d5WTvs
HOttOwxq+k2PXlDsfycPRu5w/ngZf/T7ow2+WUN3b7ttbfiYqKee2R29h3r7BkTOA7fD2NTjCn2E9tQm
l0v3d2S6ffDmUYs8HF7wUzZrb5az+CktHNsImi7n1QzQwKsG9YMqfJgmWA+cvLRwHxTM2E8XqqLGGtgP
eil76l95kkh5HdcgpierdJpwfmWSKV+ghNgoQ0zjL0rI4w652APC8zIffWVsjm6ANZ7+WVbMgVr7/fIF
LNHKD2WovrAqEkM4oQIkzIifpFj50fkn4WDj9J7J1u8lBgZ+NmqOAWMi0w== root@slave22
# 将master 上的authorized 拷贝到其他salve上
[root@bogon .ssh]# scp -rp authorized_keys slave21:~/.ssh/
The authenticity of host 'slave21 (192.168.28.101)' can't be established.
RSA key fingerprint is c1:57:34:f1:fb:9c:c6:40:c4:6e:68:76:b6:5b:92:90.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'slave21' (RSA) to the list of known hosts.
root@slave21's password:
authorized_keys 100% 1183 1.2KB/s 00:00
[root@bogon .ssh]# scp -rp authorized_keys slave22:~/.ssh/
The authenticity of host 'slave22 (192.168.28.102)' can't be established.
RSA key fingerprint is c1:57:34:f1:fb:9c:c6:40:c4:6e:68:76:b6:5b:92:90.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'slave22' (RSA) to the list of known hosts.
root@slave22's password:
authorized_keys 100% 1183 1.2KB/s 00:00
[root@bogon .ssh]#
# 检查slave是否拷贝ok
[root@bogon .ssh]# cat authorized_keys
# 验证是否可以免密访问
[root@bogon .ssh]# ssh slave21
The authenticity of host 'slave21 (192.168.28.101)' can't be established.
RSA key fingerprint is c1:57:34:f1:fb:9c:c6:40:c4:6e:68:76:b6:5b:92:90.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'slave21,192.168.28.101' (RSA) to the list of known hosts.
[root@bogon .ssh]# ssh master20
The authenticity of host 'master20 (192.168.28.100)' can't be established.
RSA key fingerprint is c1:57:34:f1:fb:9c:c6:40:c4:6e:68:76:b6:5b:92:90.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'master20,192.168.28.100' (RSA) to the list of known hosts.
验证Hadoop集群启动(1.0)
[root@bogon .ssh]# cd /usr/local/src
[root@master hadoop-1.2.1]# cd bin/
[root@master bin]# # ./Hadoop/namenode -format
[root@master bin]# ./start-all.sh
# master
[root@master bin]# jps
60533 DataNode
13446 logviewer
13445 core
2382 NameNode # ok
19446 HQuorumPeer
2535 SecondaryNameNode # ok
2620 JobTracker # ok
76757 HMaster
86471 Jps
35930 ThriftServer
[root@master bin]#
# slave
[root@slavel bin]# jps
60533 DataNode
13446 RadkTracker
13445 jps
# 展示hdfs 文件
[root@master bin]# ./hadoop fs -ls /
Found 16 items
-rw-r--r-- 3 root supergroup 632207 2019-03-06 04:57 /The_Man_of_Property.txt
-rw-r--r-- 3 root supergroup 404 2019-03-06 23:33 /b.txt
drwxr-xr-x - root supergroup 0 2019-03-19 23:54 /hbase
drwxr-xr-x - root supergroup 0 2019-03-19 05:28 /hive_data
-rw-r--r-- 3 root supergroup 8711 2019-03-17 23:17 /input.data
-rw-r--r-- 3 root supergroup 12224421 2019-03-07 03:44 /ip.lib.txt
drwxr-xr-x - root supergroup 0 2019-03-17 23:53 /output
drwxr-xr-x - root supergroup 0 2019-03-18 00:36 /output_hbase
drwxr-xr-x - root supergroup 0 2019-03-07 03:45 /output_ip_lib
drwxr-xr-x - root supergroup 0 2019-03-07 00:27 /output_sort
-rw-r--r-- 3 root supergroup 3541 2019-03-07 03:45 /query_cookie_ip.txt.small
drwxr-xr-x - root supergroup 0 2019-03-07 05:45 /test_dir
drwxr-xr-x - root supergroup 0 2019-03-19 00:04 /tmp
drwxr-xr-x - root supergroup 0 2019-03-19 00:03 /user
drwxr-xr-x - root supergroup 0 2019-03-06 04:55 /usr
-rw-r--r-- 3 root supergroup 166 2019-03-20 05:24 /w.tar.gz
[root@master bin]#
# 上传文件
[root@master bin]# ./hadoop fs - put /erc/passwd
# 读文件
[root@master bin]# ./hadoop fs - cat /passwd /
验证Hadoop集群启动(2.0)
[root@master20 hadoop-2.6.1]# pwd
/usr/local/src/hadoop-2.6.1
[root@master20 hadoop-2.6.1]# ./bin/hadoop namenode -format
[root@master20 sbin]# pwd
/usr/local/src/hadoop-2.6.1/sbin
# 下面这两个可用([root@master20 sbin]# ls start-all.sh 代替)
./sbin/start-dfs.sh
./sbin/start-yarn.sh
[root@master20 sbin]# ls start-all.sh
start-all.sh
# 主
[root@master20 sbin]# ./start-all.sh
[root@master20 sbin]# jps
6011 SecondaryNameNode # ok
5842 NameNode # ok
6405 Jps
6157 ResourceManager # ok
[root@master20 sbin]#
# 从
[root@slave21 hadoop]# jps
5900 DataNode # ok
5998 NodeManager # ok
6123 Jps
[root@slave21 hadoop]#
# 在浏览器打开输入master20:8088 hadoop 2.0 启动页面
http://master20:8088
# 操作同hadoop 1.0
hadoop fs -ls /
# 警告
19/03/23 01:24:46 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
原因:版本不兼容,无影响
解决:[root@master20 native]# pwd
/usr/local/src/hadoop-2.6.1/lib/native
将hadoop-native-64-2.6.0.tar解压在此目录下
[root@master20 native]# tar xvf hadoop-native-64-2.6.0.tar
[root@master20 lib]# scp -rp native/ slave21:/usr/local/src/hadoop-2.6.1/lib
[root@master20 lib]# scp -rp native/ slave22:/usr/local/src/hadoop-2.6.1/lib
# 若还出现警告,则在此处添加环境变量
[root@slave22 hadoop]# vim /usr/local/src/hadoop-2.6.1/etc/hadoop/hadoop-env.sh
98 export HADOOP_IDENT_STRING=$USER
99
100 export HADOOP_OPTS="-Djava.library.path=$HADOOP_PREFIX/lib:$HADOOP_PREFIX/lib/native" # 添加此列
vim 配置
[root@master20 /]# cd /root
[root@master20 ~]# pwd
/root
[root@master20 ~]# # tar xvzf vim.tgz
[root@master20 ~]# ls -a
. .bash_logout install.log .vim
.. .bash_profile install.log.syslog .viminfo
anaconda-ks.cfg .bashrc .ssh .vimrc
.bash_history .cshrc .tcshrc vim.tgz
# 改为utf-8
[root@master ~]# vim .vimrc
12 set fileencodings=utf-8,ucs-bom.cp936 " the file's encode mode guess list
13 set fenc=utf-8
14 set tenc=utf-8
15 set enc=utf-8
[root@master20 src]# scp -rp /root/.vimrc slave21:/root/.vimrc
[root@master20 src]# scp -rp /root/.vimrc slave22:/root/.vimrc
hosts
修改hosts 可在windows下访问,提示无权限可先拷贝到桌面,再替换
C:\Windows\System32\drivers\etc
127.0.0.1 localthost
127.0.0.1 www.chentan.com
127.0.0.1 chentan.com
0.0.0.0 www.xmind.net
219.76.4.4 github-cloud.s3.amazonaws.com
192.168.28.10 master
192.168.28.11 slave1
192.168.28.12 slave2
192.168.28.100 master20
192.168.28.101 slave21
192.168.28.102 slave22
阅读Google三大论文,并总结
Google的三驾马车:Google FS、MapReduce、BigTable 奠定了风靡全球的大数据算法的基础!
一,GFS—-2003
这是一个可扩展的分布式文件系统,用于大型的、分布式的、对大量数据进行访问的应用。
它运行于廉价的普通硬件上,提供容错功能.
MapReduce 和 BigTable都是以GFS为基础。
三大基础核心技术构建出了完整的分布式运算架构。
二,MapReduce—-2004
论文描述了大数据的分布式计算方式,主要思想是
将任务分解然后在多台处理能力较弱的计算节点中同时处理,
然后将结果合并从而完成大数据处理。
Mapreduce由Map和reduce组成,来自于Lisp,
Map是影射,把指令分发到多个worker上去,
reduce是规约,把Map的worker计算出来的结果合并。
Mapreduce使用GFS存储数据。
三,BigTable—-2006
BigTable 是建立在 GFS 和 MapReduce 之上的。
每个Table都是一个多维的稀疏图为了管理巨大的Table,
把Table根据行分割,这些分割后的数据统称为:Tablets。
每个Tablets大概有 100-200 MB,每个机器存储100个左右的 Tablets。
底层的架构是:GFS。
由于GFS是一种分布式的文件系统,采用Tablets的机制后,可以获得很好的负载均衡。
比如:可以把经常响应的表移动到其他空闲机器上,然后快速重建。
Hadoop的作用(解决了什么问题)/运行模式/基础组件及架构
一 Hadoop是什么
开源的 分布式存储 + 分布式计算平台
二 Hadoop组成
包括两个核心组件
HDFS:分布式文件系统,存储海量的数据。
MapReduce:并行处理框架,实现任务分解和调度。
三 Hadoop可以用来做什么
搭建大型数据仓库,PB级数据的存储、处理、分析、统计等业务
https://blog.csdn.net/chengqiuming/article/details/78602185
https://blog.csdn.net/Z_Date/article/details/84330289
学会阅读HDFS源码,
并自己阅读一段HDFS的源码(推荐HDFS上传/下载过程)【可选】
https://blog.csdn.net/zdy0_2004/article/details/70307588
Hadoop中各个组件的通信方式,RPC/Http等
https://blog.csdn.net/ty4315/article/details/51928284
Hadoop笔记三之Hdfs体系架构及各节点之间的Rpc通信
https://blog.csdn.net/xhh198781/article/details/7280084
Hadoop中的RPC实现——服务器端通信组件
https://blog.csdn.net/xhh198781/article/details/7268298
Hadoop中的RPC实现——客户端通信组件
WordCount(分布式/单机运行模式)
(Java/Python-Hadoop Streaming),理解分布式/单机运行模式的区别
分布式/单机运行模式
单机模式(独立模式)(Local或Standalone Mode)
- 默认情况下,Hadoop即处于该模式,用于开发和调式。
- 不对配置文件进行修改。
- 使用本地文件系统,而不是分布式文件系统。
- Hadoop不会启动NameNode、DataNode、JobTracker、TaskTracker等守护进程,Map()和Reduce()任务作为同一个进程的不同部分来执行的。
- 用于对MapReduce程序的逻辑进行调试,确保程序的正确。
伪分布式模式(Pseudo-Distrubuted Mode)
- Hadoop的守护进程运行在本机机器,模拟一个小规模的集群。
- 在一台主机模拟多主机。
- Hadoop启动NameNode、DataNode、JobTracker、TaskTracker这些守护进程都在同一台机器上运行,是相互独立的Java进程。
- 在这种模式下,Hadoop使用的是分布式文件系统,各个作业也是由JobTraker服务,来管理的独立进程。在单机模式之上增加了代码调试功能,允许检查内存使用情况,HDFS输入输出,以及其他的守护进程交互。类似于完全分布式模式,因此,这种模式常用来开发测试Hadoop程序的执行是否正确。
- 修改3个配置文件:core-site.xml(Hadoop集群的特性,作用于全部进程及客户端)、hdfs-site.xml(配置HDFS集群的工作属性)、mapred-site.xml(配置MapReduce集群的属性)
- 格式化文件系统
全分布式集群模式(Full-Distributed Mode)
- Hadoop的守护进程运行在一个集群上。
- Hadoop的守护进程运行在由多台主机搭建的集群上,是真正的生产环境。
- 在所有的主机上安装JDK和Hadoop,组成相互连通的网络。
- 在主机间设置SSH免密码登录,把各从节点生成的公钥添加到主节点的信任列表。
- 修改3个配置文件:core-site.xml、hdfs-site.xml、mapred-site.xml,指定NameNode和JobTraker的位置和端口,设置文件的副本等参数。
- 格式化文件系统
注意:所谓分布式要启动守护进程,即:使用分布式hadoop时,要先启动一些准备程序进程,然后才能使用比如 start-dfs.sh,start-yarn.sh。而本地模式不需要启动这些守护进程
https://blog.csdn.net/qiulinsama/article/details/86216394
Hadoop2.0 操作mapreduce
mapreduce_python_hadoop
[root@master20 mapreduce_wordcount_python]# pwd
/home/badou/badou2/python_mr/mapreduce_wordcount_python
# 相较于hadoop1.0其余无需修改,只要修改run.sh里的hadoop 与Hadoop-streaming路径
[root@master20 mapreduce_wordcount_python]# vim run.sh
1
2 HADOOP_CMD="/usr/local/src/hadoop-2.6.1/bin/hadoop" # 2.0修改此处
3 STREAM_JAR_PATH="/usr/local/src/hadoop-2.6.1/share/hadoop/tools/lib/hadoo
p-streaming-2.6.1.jar" # 2.0修改此处
4
5 INPUT_FILE_PATH_1="/The_Man_of_Property.txt"
6 OUTPUT_PATH="/output"
7
8 $HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH
9
10 # Step 1.
11 $HADOOP_CMD jar $STREAM_JAR_PATH \
12 ^I^I-input $INPUT_FILE_PATH_1 \
13 ^I^I-output $OUTPUT_PATH \
14 ^I^I-mapper "python map.py" \
15 ^I^I-reducer "python red.py" \
16 ^I^I-file ./map.py \
17 ^I^I-file ./red.py
run.sh 17,1-4 Bot
[root@master20 mapreduce_wordcount_python]# vim map.py
1 #!/usr/local/bin/python
2
3 import sys
4
5 for line in sys.stdin:
6 ^Iss = line.strip().split(' ')
7 ^Ifor s in ss:
8 ^I^Iif s.strip() != "":
9 ^I^I^Iprint "%s\t%s" % (s, 1)
10
11
12
~
~
~
~
~
map.py 5,1 All
"map.py" 12L, 156C
[root@master20 mapreduce_wordcount_python]# vim red.py
1 #!/usr/local/bin/python
2
3 import sys
4
5 current_word = None
6 count_pool = []
7 sum = 0
8
9 for line in sys.stdin:
10 ^Iword, val = line.strip().split('\t')
11
12 ^Iif current_word == None:
13 ^I^Icurrent_word = word
14
15 ^Iif current_word != word:
16 ^I^Ifor count in count_pool:
17 ^I^I^Isum += count
18 ^I^Iprint "%s\t%s" % (current_word, sum)
19 ^I^Icurrent_word = word
20 ^I^Icount_pool = []
21 ^I^Isum = 0
22
23 ^Icount_pool.append(int(val))
24
25 for count in count_pool:
26 ^Isum += count
27 print "%s\t%s" % (current_word, str(sum))
28
red.py 28,0-1 Bot
"red.py" 28L, 464C
[root@master20 mapreduce_wordcount_python]# cat The_Man_of_Property.txt | head
Preface
“The Forsyte Saga” was the title originally destined for that part of it which is called “The Man of Property”; and to adopt it for the collected chronicles of the Forsyte family has indulged the Forsytean tenacity that is in all of us. ...
9 One has noticed that readers, as they wade on through the salt waters of
the Saga, are inclined more and more to pity Soames, and to think that
in doing so they are in revolt against the mood of his creator. Far from
it! He, too, pities Soames, the tragedy of whose life is the very simpl
e, uncontrollable tragedy of being unlovable, without quite a thick enou
gh skin to be thoroughly unconscious of the fact. Not even Fleur loves S
oames as he feels he ought to be loved. But in pitying Soames, readers i
ncline, perhaps, to animus against Irene: After all, they think, he wasn
’t a bad fellow, it wasn’t his fault; she ought to have forgiven him, an
d so on!
The_Man_of_Property.txt 1,1 Top
"The_Man_of_Property.txt" [dos] 2866L, 632207C
[root@master20 mapreduce_wordcount_python]# hadoop fs -put The_Man_of_Property.txt /
[root@master20 mapreduce_wordcount_python]# bash run.sh
# 从节点 salve21 salve22
[root@slave21 hadoop-2.6.1]# jps
8710 Jps
5900 DataNode
5998 NodeManager
8676 YarnChild
8673 YarnChild
[root@slave22 hadoop-2.6.1]# jps
6136 DataNode
9829 Jps
9746 MRAppMaster
6234 NodeManager
[root@master20 mapreduce_wordcount_python]# hadoop fs -ls /output
[root@master20 mapreduce_wordcount_python]# hadoop fs -text /output/part-00000 | head
(Baynes 1
(Dartie 1
(Dartie’s 1
(Down-by-the-starn) 2
(Down-by-the-starn), 1
(He 1
(I 1
(James) 1
(L500) 1
(Louisa 1
text: Unable to write to output stream.
[root@master20 mapreduce_wordcount_python]#
# 在浏览器输入打开监控页面:
http://master20:8088
点击logs-->stderr(错误日志),stdout(正确结果),syslog(打印日志)
mapredu_scala_spark
理解MapReduce的执行过程
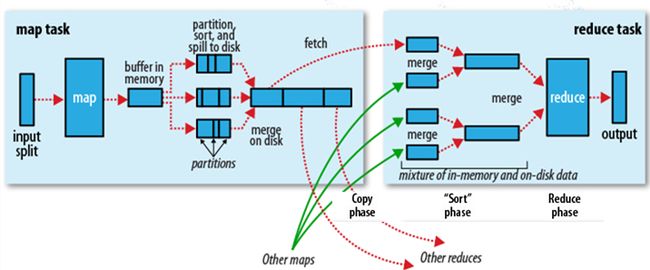
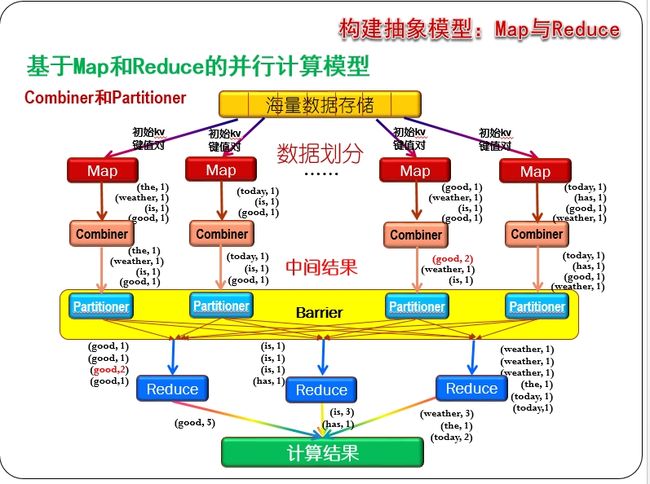
https://blog.csdn.net/xiaokang06/article/details/65635269
图解mapreduce原理和执行过程
https://www.iteblog.com/archives/1119.html
MapReduce:详细介绍Shuffle的执行过程
Yarn在Hadoop中的作用
一:对yarn的理解
1.关于yarn的组成
大约分成主要的四个。
Resourcemanager,Nodemanager,Applicationmaster,container
2.Resourcemanager(RM)的理解
RM是全局资源管理器,负责整个系统的资源管理和分配。
主要由两个组件组成:调度器和应用程序管理器(ASM)
调度器:根据容量,队列等限制条件,将系统中的资源分配给各个正在运行的应用程序,不负责具体应用程序的相关工作,比如监控或跟踪状态
应用程序管理器:负责管理整个系统中所有应用程序
3.Applicationmaster(AM)
用户提交的每个应用程序均包含一个AM
AM的主要功能:
(1)与RM调度器协商以获取资源(用Container表示)
(2)将得到的任务进一步分配给内部的任务
(3)与NM通信以自动/停止任务
(4)监控所有任务运行状态,并在任务运行失败时重新为任务申请资源以重启任务
当前YARN自带了两个AM实现:
一个用于演示AM编写方法的实例程序distributedshell
一个用于Mapreduce程序—MRAppMaster
其他的计算框架对应的AM正在开发中,比如Spark等
4.Nodemanager
NM是每个节点上的资源和任务管理器
(1)定时向RM汇报本节点上的资源使用情况和各个Container的运行状态
(2)接收并处理来自AM的Container启动/停止等各种要求
5.container
Container是YARN中的资源抽象,它封装了某个节点上的多维度资源
YARN会为每个任务分配一个Container,且该任务只能使用该Container中描述的资源
我们看到JobTracker的功能被分散到各个进程中包括ResourceManager和NodeManager:
比如监控功能,分给了NodeManager,和Application Master。
ResourceManager里面又分为了两个组件:调度器及应用程序管理器。
也就是说Yarn重构后,JobTracker的功能,被分散到了各个进程中。同时由于这些进程可以被单独部署所以这样就大大减轻了单点故障,及压力。
同时我们还看到Yarn使用了Container,而hadoop1.x中使用了slot。slot存在的缺点比如只能map或则reduce用。Container则不存在这个问题。这也是Yarn的进步。
http://www.aboutyun.com/forum.php?mod=viewthread&tid=20891
Hadoop2.x 让你真正明白yarn
https://www.cnblogs.com/juncaoit/p/6737308.html
014 再次整理关于hadoop中yarn的原理及运行
【Task 3】HDFS常用命令/API+上传下载过程
- 认识HDFS
- HDFS是用来解决什么问题的
- HDFS设计与架构
- 熟悉hdfs常用命令
- Python操作HDFS的其他API
- 观察上传后的文件,上传大于128M的文件与小于128M的文件有何区别?
- 启动HDFS后,会分别启动NameNode/DataNode/SecondaryNameNode,这些进程的的作用分别是什么?
- NameNode是如何组织文件中的元信息的,edits log与fsImage的区别?使用hdfs oiv命令观察HDFS上的文件的metadata
- HDFS文件上传下载过程,源码阅读与整理。
参考: https://segmentfault.com/a/1190000002672666
参考资料:Python3调用Hadoop的API
认识HDFS
- HDFS是用来解决什么问题的
单机文件系统的限制:
早期计算机中的文件是由单机的操作系统来进行管理的,单机中的文件管理存在以下不足:
①存储容量的限制。
②读写性能的限制。
③容灾能力不足。
当文件特别大的时候,上面三个问题凸显。
行业现状:
①数据格式多样化。各业务系统数据库中的结构化数据;日志文件等半结构化数据;视频、图片等非结构化数据。传统的数据库已经满足不了我们的存储需求。
②每天各种类型的数据以GB、TB的速度增长。单机的文件系统已管理不了如此大的数据量。
HDFS就是为了解决上面这些问题而生的:
HDFS是一种允许文件通过网络在多台机器上分享的文件系统。
②HDFS将一个大文件分割成多个数据块,将这些数据块分散存储在多台机器上。
③虽然HDFS会将文件分割成多个数据块,但在程序和用户看来就跟操作本地磁盘中的文件一样。
④针对一个文件,可以并发读取它的数据块,增加了读取的性能。
⑤HDFS存储的容量具有巨大的扩展性。
⑥HDFS可以保证系统中的某些节点脱机时整个系统仍然能持续运行,并保证数据不丢失。
为什么不使用配有大量硬盘的单台机器来存储文件?
①随着计算机硬件技术的发展,单台机器硬盘存储容量不断提升,但硬盘数据读取速度却提升缓慢。
②硬盘寻址速度的提升远远不如网络传输速度的提升。如果数据的访问包含大量的硬盘寻址,那么读取大量数据就会花费更长的时间。
- HDFS设计与架构
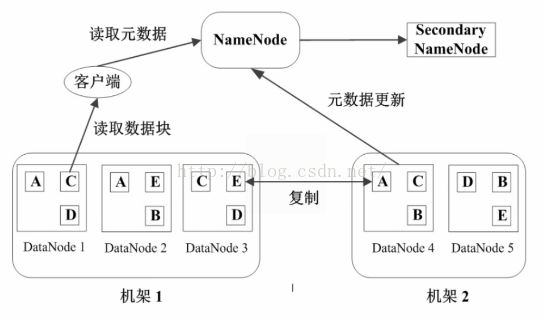
想要看懂这张图,我们先得了解这几个基本概念:
块(block):我们可以看到图中有 “读取数据块” 的字样,那么数据块是什么呢?块在文件系统里面通常是指固定大小的逻辑单元,HDFS的文件就是被分成块进行存储,每个HDFS块的默认大小是64MB。我们做文件的备份和查找也都是以块为单元进行的,那么这么做的好处是什么?
NameNode:管理节点,存放元数据,元数据又包括两个部分:1.文件与数据块的映射表,2.数据块与数据节点的映射表。这里也就可以解释为什么HDFS不适合存储小文件了,因为不管是存大文件或是小文件都是需要在NameNode里写入元数据,显然存小文件是不划算的。
DataNode:HDFS的工作节点,存放数据块。
HDFS为了保证对硬件上的容错,对任何一个数据块都是默认存三份,因为任何一个节点都可能发生故障,为了保证数据不被丢失,数据块就有多分冗余。
在上图中,A,B,C,D都是64MB的数据块,而且默认都有三份,其中两份在同一机架上,在另一个机架上也有一份。这样即使一个节点挂了,还可以在同一机架的另一个节点上找到相同数据块。即使整个机架挂了,也可以在另一个机架上找到。
我们可以举个例子来理解整个过程:NameNode 相当于一个仓库管理员,他需要维护自己的一个账本,而 DataNode 相当于一个仓库,在仓库里面存放数据,客户端相当于送货人或者提货人。当我们要存数据(货物)的时候,送货人想将货物放到仓库里,首先要跟仓库管理员打交道,即发送一个请求,仓库管理员先查看账本(包含各个仓库的信息),看看哪些仓库可以用之类的,然后告诉送货员你把货物送到某个仓库里面去。
心跳检测
每个DataNode定期向NameNode发送心跳消息,来汇报自己的状况:是否还处于Active状态,网络是否断开之类的。
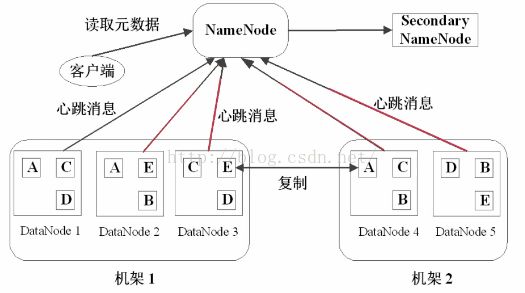
Secondary NameNode
二级 NameNode ,定期同步元数据映像文件和修改日志,当 NameNode 发生故障时,Secondary NameNode可用来恢复文件系统。为了防止 NameNode 发生故障时,元数据丢失。大部分情况下,当NameNode 正常工作时,Secondary NameNode 只做备份工作,而不接受请求。
切记:Secondary NameNode 不是 NameNode 的热备进程,也就是说它是无法直接替代 NameNode 进行工作的。
https://blog.csdn.net/gangchengzhong/article/details/71403321
https://blog.csdn.net/gangchengzhong/article/details/72899563
官方HDFS架构设计原理说明(上/下)
https://segmentfault.com/a/1190000019831598?utm_source=tag-newest
浅析HDFS架构和设计
熟悉hdfs常用命令
https://segmentfault.com/a/1190000002672666
hadoop HDFS常用文件操作命令
命令基本格式:
hadoop fs -cmd < args >
1.ls
-->hadoop fs -ls / 列出hdfs文件系统根目录下的目录和文件
-->hadoop fs -ls -R / 列出hdfs文件系统所有的目录和文件
2.put
-->hadoop fs -put < local file > < hdfs file >
hdfs file的父目录一定要存在,否则命令不会执行
-->hadoop fs -put < local file or dir >...< hdfs dir >
hdfs dir 一定要存在,否则命令不会执行
-->hadoop fs -put - < hdsf file>
从键盘读取输入到hdfs file中,按Ctrl+D结束输入,hdfs file不能存在,否则命令不会执行
4.rm
-->hadoop fs -rm < hdfs file > ...
-->hadoop fs -rm -r < hdfs dir>...
每次可以删除多个文件或目录
5.mkdir
-->hadoop fs -mkdir < hdfs path>
只能一级一级的建目录,父目录不存在的话使用这个命令会报错
-->hadoop fs -mkdir -p < hdfs path>
所创建的目录如果父目录不存在就创建该父目录
11.text
-->hadoop fs -text < hdsf file>
将文本文件或某些格式的非文本文件通过文本格式输出
Python操作HDFS的其他API
python3调用HDFS集群API
Hadoop安装好了;(虽说是伪分布式的,如果要做分布式做好ssh免密码登录,把配置文件分发出去就好了)
但是我在网上看到python的pyhdfs模块可以调用HDFS集群的API进行上传、下载、查找....文件...于是储备下来了,也许可以用作后期 Hadoop自动化项目;
注意:在使用pyhdfs模块之前一定要确保Hadoop的配置文件都监听在外网端口并修改host文件。
192.168.226.142 localhost
[root@master20 hadoop-2.6.1]# vim /etc/hosts
1 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdo
main4
2 ::1 localhost localhost.localdomain localhost6 localhost6.localdo
main6
3
4 192.168.28.100 master20
5 192.168.28.101 slave21
6 192.168.28.102 slave22
#windows hosts文件的路径 C:\WINDOWS\system32\drivers\etc\host
#Linux /etc/host
#1 使用yum安装pip
1018 python get-pip.py
1019 yum -y install epel-release
1020 yum -y install python-pip
1021 yum clean all
https://www.cnblogs.com/ermao0423/p/9596617.html
##若错误: _blocking_errnos = {errno.EAGAIN, errno.EWOULDBLOCK} pip
python2.6 get-pip.py 报错下面的错误
_blocking_errnos = {errno.EAGAIN, errno.EWOULDBLOCK} pip
解决方案(我用的这种):
### 1, 从官方github获取具体版本的pip
wget https://raw.githubusercontent.com/pypa/get-pip/master/2.6/get-pip.py
### 2,运行刚才获取的pip文件
python2.6 get-pip.py
https://www.cnblogs.com/huanhang/p/11243237.html
#2 安装python3
1).下载安装包
1005 wget https://www.Python.org/ftp/python/3.6.3/Python-3.6.3.tgz
# 解压
1006 tar zxvf Python-3.6.3.tgz
# 移动
1008 mv Python-3.6.3 /usr/local/src/Python-3.6.3
2).二进制文件安装
1.. 进入Python文件夹创建存放目录
1010 cd /usr/local/src
1012 mkdir /usr/local/src/python3.6.3
2.. 配置python安装位置,运行脚本configure
config是一个shell脚本,根据平台的特性生成Makefile文件,为下一步的编译做准备。
可以通过在 configure 后加上参数来对安装进行控制,比如下面就是指定安装目录/usr/local/python3。
如果没有用这个选项,安装过程结束后,该软件所需的软件被复制到不同的系统目录下,比较混乱。
1015 cd /usr/local/src/Python-3.6.3
1016 ./configure --enable-optimizations --prefix=/usr/local/src/python373
可以通过 ./configure --help 查看详细的说明帮助。
3). make编译
1017 make
4).make install安装
1018 make install
...
Looking in links: /tmp/tmpfxdljd7f
Collecting setuptools
Collecting pip
Installing collected packages: setuptools, pip
Successfully installed pip-19.0.3 setuptools-40.8.0 # 安装成功
#删除一些临时文件(删除源代码(C\C++ code)生成的执行文件和所有的中间目标文件)
[root@master20 Python-3.7.3]# make clean
# 要清除所有生成的文件。
[root@master20 Python-3.7.3]# make distclean
5).编译过程中有出现”zipimport.ZipImportError: can’t decompress data; zlib not available”错误提示,是由于缺少包导致的,解决方法是安装需要的包:
yum install zlib zlib-devel -y
然后从config开始重新安装
6).设置系统默认版本
# 备份原有python命令执行文件
1029 mv /usr/bin/python /usr/bin/pythonbak
# 创建新连接
1030 ln -s /usr/local/src/python3.6.3/bin/python3.6 /usr/bin/python
# 查看python3与pip3的安装路径
[root@master20 bin]# find / -name python
/usr/local/src/Python-3.6.3/python
[root@master20 bin]# find / -name pip3.6
/usr/local/src/python3.6.3/bin/pip3.6
# 备份原有pip命令执行文件
1067 mv /usr/bin/pip /usr/bin/pip.bak
# 创建新连接
1085 ln -s /usr/local/src/python3.6.3/bin/pip3.6 /usr/bin/pip
# 查看python 版本
python -V
Python 3.6.3
pip -V
[root@master20 bin]# pip -V
pip 9.0.1 from /usr/local/src/python3.6.3/lib/python3.6/site-packages (python 3.6)
https://www.cnblogs.com/huanhang/p/11243237.html
https://blog.csdn.net/u011514201/article/details/78425394
https://www.cnblogs.com/wx-mm/p/11051995.html
#3 python3调用HDFS集群API
# 安装pyhdfs
[root@master20 hadoop-2.6.1]# pip install pyhdfs -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
##证书 --trusted-host pypi.douban.com
# 若提示更新pip
[root@master20 hadoop-2.6.1]# pip install --upgrade pip
# python 操作hdfs
https://www.cnblogs.com/sss4/p/10443497.html
Python3调用Hadoop的API
https://blog.csdn.net/weixin_38070561/article/details/81289601
使用python中的pyhdfs连接HDFS进行操作——pyhdfs使用指导(附代码及运行结果)
https://blog.csdn.net/vickyrocker1/article/details/48178883
Hadoop2.6.0使用Python操作HDFS的解决方案
https://blog.csdn.net/qq_29979341/article/details/77096520
python对Hadoop的hdfs的操作——-pyhdfs或python调用shell文件
#连接
import pyhdfs
fs = pyhdfs.HdfsClient('192.168.***.**:50070')
# 操作
import pyhdfs
class PackageHdfs():
def __init__(self):
self.fs = pyhdfs.HdfsClient('192.168.200.19:50070')
# 删除
def delFile(self,path):
fs = self.fs
fs.delete(path)
# 上传文件
def upload(self, fileName, tmpFile):
fs = self.fs
fs.copy_from_local(fileName, tmpFile)
# 新建目录
def makdir(self, filePath):
fs = self.fs
if not fs.exists(filePath):
#os.system('hadoop fs -mkdir '+filePath)
fs.mkdirs(filePath)
return 'mkdir'
return 'exits'
# 重命名
def rename(self, srcPath, dstPath):
fs = self.fs
if not fs.exists(srcPath):
return
fs.rename(srcPath, dstPath)
# 方便调试python,彩色显示python,tab 补全
https://blog.csdn.net/qq_39362996/article/details/82892671
https://www.cnblogs.com/hanggegege/p/6071570.html
IPython介绍
https://blog.csdn.net/xiaoxianerqq/article/details/79424051
如何将ipython的历史记录导出到.py文件中?
https://blog.csdn.net/joy_yue_/article/details/82912706
ipython快捷键操作及常用命令
[root@master20 badou]# yum install ipython
[root@master20 badou]# ipython
/usr/local/src/python3.6.3/lib/python3.6/site-packages/IPython/frontend.py:21: ShimWarning: The top-level `frontend` package has been deprecated since IPython 1.0. All its subpackages have been moved to the top `IPython` level.
"All its subpackages have been moved to the top `IPython` level.", ShimWarning)
/usr/local/src/python3.6.3/lib/python3.6/site-packages/IPython/core/history.py:226: UserWarning: IPython History requires SQLite, your history will not be saved
warn("IPython History requires SQLite, your history will not be saved")
Python 3.6.3 (default, Jul 31 2019, 15:58:31)
Type 'copyright', 'credits' or 'license' for more information
IPython 7.7.0 -- An enhanced Interactive Python. Type '?' for help.
In [27]: import pyhdfs
In [28]: fs = pyhdfs.HdfsClient(hosts='master20,50070',user_name='root')
# 非root 用户报权限错误
hadoop 创建用户及hdfs权限,hdfs操作等常用shell命令
https://blog.csdn.net/swuteresa/article/details/13767169
https://blog.csdn.net/kicilove/article/details/79880458s
在hdfs中创建文件夹,出现权限问题
In [29]: fs.get_home_directory()
Out[29]: '/user/root'
In [30]: fs.get_active_namenode()
Out[30]: 'master20:50070'
In [33]: def makir(filePath):
...: if not fs.exists(filePath):
...: fs.mkdirs(filePath)
...: return '创建成功'
...: return '已存在'
...:
# 按两次enter,另起一行
In [34]: makir('/mxj/mxj001')
Out[34]: '创建成功'
Hadoop2.x的版本中,文件块的默认大小是128M
在Hadoop2.x的版本中,文件块的默认大小是128M,老版本中默认是64M;
观察上传后的文件,上传大于128M的文件与小于128M的文件有何区别?
大于128MB会被分为两个block存储,小于128MB未1个block存储
寻址时间:HDFS中找到目标文件块(block)所需要的时间。
原理:
文件块越大,寻址时间越短,但磁盘传输时间越长;
文件块越小,寻址时间越长,但磁盘传输时间越短。
一、为什么HDFS中块(block)不能设置太大,也不能设置太小?
1. 如果块设置过大,
一方面,从磁盘传输数据的时间会明显大于寻址时间,导致程序在处理这块数据时,变得非常慢;
另一方面,mapreduce中的map任务通常一次只处理一个块中的数据,如果块过大运行速度也会很慢。
2. 如果块设置过小,
一方面存放大量小文件会占用NameNode中大量内存来存储元数据,而NameNode的内存是有限的,不可取;
另一方面文件块过小,寻址时间增大,导致程序一直在找block的开始位置。
因而,块适当设置大一些,减少寻址时间,那么传输一个由多个块组成的文件的时间主要取决于磁盘的传输速率。
二、 HDFS中块(block)的大小为什么设置为128M?
1. HDFS中平均寻址时间大概为10ms;
2. 经过前人的大量测试发现,寻址时间为传输时间的1%时,为最佳状态;
所以最佳传输时间为10ms/0.01=1000ms=1s
3. 目前磁盘的传输速率普遍为100MB/s;
计算出最佳block大小:100MB/s x 1s = 100MB
所以我们设定block大小为128MB。
ps:实际在工业生产中,磁盘传输速率为200MB/s时,一般设定block大小为256MB
磁盘传输速率为400MB/s时,一般设定block大小为512MB
https://blog.csdn.net/wx1528159409/article/details/84260023
一篇讲懂为什么HDFS文件块(block)大小设为128M
https://blog.csdn.net/qq_35688140/article/details/86495857
关于hdfs分片和分块
HDFS 各进程的作用
启动HDFS后,会分别启动NameNode/DataNode/SecondaryNameNode,这些进程的的作用分别是什么?
NameNode:名称节点,
主要是用来保存HDFS的元数据信息,比如命名空间信息,块信息等。
当它运行的时候,这些信息是存在内存中的。但是这些信息也可以持久化到磁盘上。
DataNode:数据节点,
Datanode是文件系统的工作节点,他们根据客户端或者是namenode的调度存储和检索数据,
并且定期向namenode发送他们所存储的块(block)的列表。
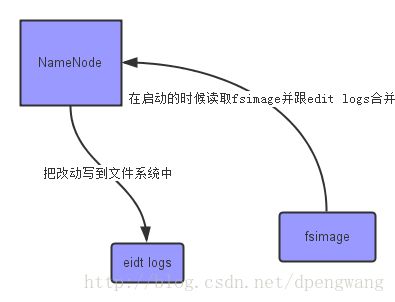
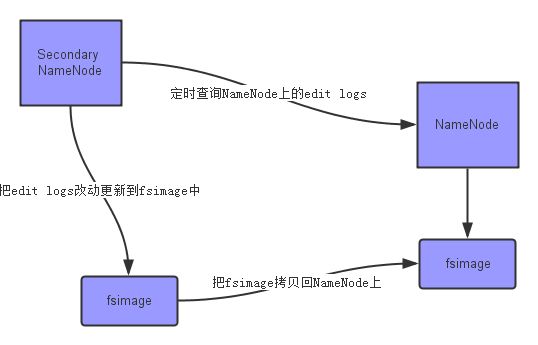
Secondary NameNode 第二名称节点
SecondaryNameNode它的职责是合并NameNode的edit logs到fsimage文件中。
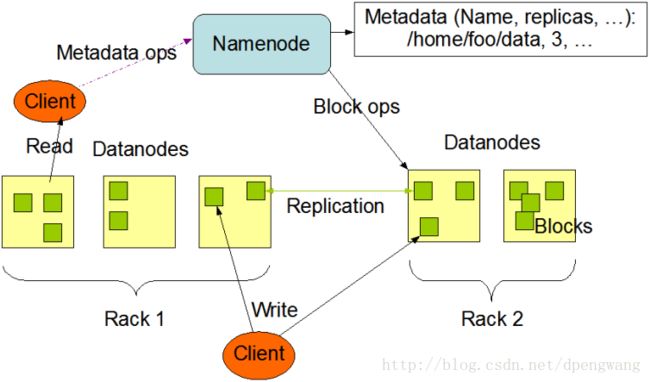
https://blog.csdn.net/dpengwang/article/details/79060052
Hadoop中的Namenode、Datanode和Secondary Namenode
https://blog.csdn.net/lvtula/article/details/82354989
hdfs的namenode、datanode和secondarynamenode
NameNode是如何组织文件中的元信息的,edits log与fsImage的区别?使用hdfs oiv命令观察HDFS上的文件的metadata
NameNode是如何组织文件中的元信息的
NameNode职责:
负责客户端请求的响应
元数据的管理(查询,修改)
元数据管理
namenode对元数据的管理采用了三种存储形式:
a.内存元数据(NameSystem)
b.磁盘元数据镜像文件
c.数据操作日志文件(可以通过日志运算出元数据)
2.1 元数据存储机制:
A.内存中有一份完整的元数据(内存 meta data)
B.磁盘有一个"准完整"的元数据镜像(fsimage),文件(在namenode的工作目录中)
c.用于衔接内存metadata和持久化元数据镜像fsimage之间的操作日志(edit文件)
注:当客户端对hdfs中的文件进行新增或者修改操作时,操作记录首先被记入edits日志文件中,
当客户端操作成功之后,相应的元数据会更新到内存meta.data中
---------------------
作者:汤愈韬
来源:CSDN
原文:https://blog.csdn.net/qq_38200548/article/details/83108422
版权声明:本文为博主原创文章,转载请附上博文链接!
Hadoop Namenode元数据文件 Fsimage、editlog、seen_txid说明
Hadoop NameNode元数据的$dfs.namenode.name.dir/current/文件夹有几个文件:
current/
2|-- VERSION
3|-- edits_*
4|-- fsimage_0000000000008547077
5|-- fsimage_0000000000008547077.md5
6|-- seen_txid
---------------------
作者:levy_cui
来源:CSDN
原文:https://blog.csdn.net/levy_cui/article/details/60144621
版权声明:本文为博主原创文章,转载请附上博文链接!
edits log与fsImage的区别?
Editslog :保存了所有对hdfs中文件的操作信息
FsImage:是内存元数据在本地磁盘的映射,用于维护管理文件系统树,即元数据(metadata)
第一步:将hdfs更新记录写入一个新的文件--edit.new
第二步:将fsimage和editlog通过http协议发送至secondary namenode
第三步:将fsimage与editlog合并,生成一个新的文件--fsimage.ckpt。
这步之所以在secondary namenode中进行,是因为比较耗时,
如果在namenode进行,或导致整个系统卡顿。
第四步:将生成的fsimage.ckpt通过http协议发送至namenode。
第五步:重命名fsimage.ckpt为fsimage,edits.new为edit。
https://my.oschina.net/u/4009325/blog/2396163
fsimage 和 editlog 的解释和原理 原
https://blog.csdn.net/a602519773/article/details/80367582
hadoop中FsImage与Editslog合并解析
使用hdfs oiv命令观察HDFS上的文件的metadata
命令hdfs oiv用于将fsimage,edits文件转换成其他格式的,如文本文件、XML文件。
> HDFS查看fsimage,edits
命令说明
> 必要参数
-i,–inputFile <arg> 输入FSImage文件.
-o,–outputFile <arg> 输出转换后的文件,如果存在,则会覆盖
> 可选参数:
-p,–processor <arg> 将FSImage文件转换成哪种格式: (Ls|XML|FileDistribution).默认为Ls.
-h,–help 显示帮助信息
hdfs oiv -i fsimage_0000000000016975189 -o 123.xml
hdfs oiv -i /var/lib/hadoop-yarn/test00001/data/fsimage_0000000000016975189 -o fsimage.txt
---------------------
作者:甜橙味芬达
来源:CSDN
原文:https://blog.csdn.net/weixin_42404341/article/details/83787356
版权声明:本文为博主原创文章,转载请附上博文链接!
[root@master20 name]# pwd
/usr/local/src/hadoop-2.6.1/dfs/name
[root@master20 name]# tree current/
current/
├── edits_0000000000000000001-0000000000000000002
├── edits_0000000000000000003-0000000000000000004
├── edits_0000000000000000005-0000000000000000012
├── edits_0000000000000000013-0000000000000000014
├── edits_0000000000000000015-0000000000000000016
├── edits_0000000000000000017-0000000000000000028
├── edits_0000000000000000029-0000000000000000646
├── edits_0000000000000002721-0000000000000002721
├── edits_0000000000000002722-0000000000000002722
├── edits_0000000000000002723-0000000000000002724
├── edits_inprogress_0000000000000002725
├── fsimage_0000000000000002720
├── fsimage_0000000000000002720.md5
├── fsimage_0000000000000002724
├── fsimage_0000000000000002724.md5
├── seen_txid
└── VERSION
[root@master20 name]# cd current/
[root@master20 name]# hdfs oiv -i fsimage_0000000000000002724 -o tmp123.xml
{"RemoteException":{"exception":"FileNotFoundException","javaClassName":"java.io.FileNotFoundException","message":"Path: / should start with \"/webhdfs/v1/\""}}
https://blog.csdn.net/levy_cui/article/details/60144621
Hadoop Namenode元数据文件 Fsimage、editlog、seen_txid说明
HDFS文件上传下载过程,源码阅读与整理。
并自己阅读一段HDFS的源码(推荐HDFS上传/下载过程)【可选】
https://blog.csdn.net/zdy0_2004/article/details/70307588
【Task4】MapReduce+MapReduce执行过程
-
MR原理
-
使用Hadoop Streaming -python写出WordCount
-
使用mr计算movielen中每个用户的平均评分。
-
使用mr实现merge功能。根据item,merge movielen中的 u.data u.item
-
使用mr实现去重任务。
-
使用mr实现排序。
-
使用mapreduce实现倒排索引。
-
使用mapreduce计算Jaccard相似度。
-
使用mapreduce实现PageRank。
参考: https://segmentfault.com/a/1190000002672666
参考资料:Python3调用Hadoop的API
【截止时间】任务时间是3天(最终以石墨文档的记录为准)
1)2019.8.2 周五 22:00 前提交博客/Github链接(描述:任务、遇到的问题、实现代码和参考资料)
2)2019.8.3中午12:00 前点评完毕
**【考核方式】**1)链接发到群里同时@点评人 + 在群里对下一号学员进行点评2)并在下面贴上自己链接、对他人的点评
【学员打卡】
MR原理
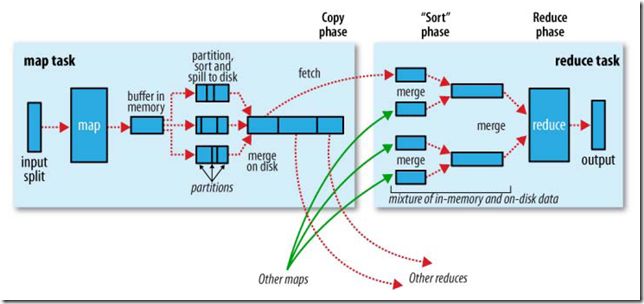
3.4.1、Map的过程
MapRunnable从input split中读取一个个的record,然后依次调用Mapper的map函数,将结果输出。
map的输出并不是直接写入硬盘,而是将其写入缓存memory buffer。
当buffer中数据的到达一定的大小,一个背景线程将数据开始写入硬盘。
在写入硬盘之前,内存中的数据通过partitioner分成多个partition。
在同一个partition中,背景线程会将数据按照key在内存中排序。
每次从内存向硬盘flush数据,都生成一个新的spill文件。
当此task结束之前,所有的spill文件被合并为一个整的被partition的而且排好序的文件。
reducer可以通过http协议请求map的输出文件,tracker.http.threads可以设置http服务线程数。
3.4.2、Reduce的过程
当map task结束后,其通知TaskTracker,TaskTracker通知JobTracker。
对于一个job,JobTracker知道TaskTracer和map输出的对应关系。
reducer中一个线程周期性的向JobTracker请求map输出的位置,直到其取得了所有的map输出。
reduce task需要其对应的partition的所有的map输出。
reduce task中的copy过程即当每个map task结束的时候就开始拷贝输出,因为不同的map task完成时间不同。
reduce task中有多个copy线程,可以并行拷贝map输出。
当很多map输出拷贝到reduce task后,一个背景线程将其合并为一个大的排好序的文件。
当所有的map输出都拷贝到reduce task后,进入sort过程,将所有的map输出合并为大的排好序的文件。
最后进入reduce过程,调用reducer的reduce函数,处理排好序的输出的每个key,最后的结果写入HDFS。
作者:首席撩妹指导官
来源:CSDN
原文:https://blog.csdn.net/qq_36864672/article/details/78561375
版权声明:本文为博主原创文章,转载请附上博文链接!
https://blog.csdn.net/qq_31975963/article/details/84995460
MR的原理和运行流程
https://blog.csdn.net/qq_36864672/article/details/78561375
MR 运行原理
使用Hadoop Streaming -python写出WordCount
Hadoop2.0 操作mapreduce ctrl+点击跳转
[Hadoop2.0 操作mapreduce](#Hadoop2.0 操作mapreduce) ctrl+点击
[root@master20 mapreduce_wordcount_python]# pwd
/home/badou/badou2/python_mr/mapreduce_wordcount_python
# 相较于hadoop1.0其余无需修改,只要修改run.sh里的hadoop 与Hadoop-streaming路径
[root@master20 mapreduce_wordcount_python]# vim run.sh
1
2 HADOOP_CMD="/usr/local/src/hadoop-2.6.1/bin/hadoop" # 2.0修改此处
3 STREAM_JAR_PATH="/usr/local/src/hadoop-2.6.1/share/hadoop/tools/lib/hadoo
p-streaming-2.6.1.jar" # 2.0修改此处
4
5 INPUT_FILE_PATH_1="/The_Man_of_Property.txt"
6 OUTPUT_PATH="/output"
7
8 $HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH
9
10 # Step 1.
11 $HADOOP_CMD jar $STREAM_JAR_PATH \
12 ^I^I-input $INPUT_FILE_PATH_1 \
13 ^I^I-output $OUTPUT_PATH \
14 ^I^I-mapper "python map.py" \
15 ^I^I-reducer "python red.py" \
16 ^I^I-file ./map.py \
17 ^I^I-file ./red.py
run.sh 17,1-4 Bot
[root@master20 mapreduce_wordcount_python]# vim map.py
1 #!/usr/local/bin/python
2
3 import sys
4
5 for line in sys.stdin:
6 ^Iss = line.strip().split(' ')
7 ^Ifor s in ss:
8 ^I^Iif s.strip() != "":
9 ^I^I^Iprint "%s\t%s" % (s, 1)
10
11
12
~
~
~
~
~
map.py 5,1 All
"map.py" 12L, 156C
[root@master20 mapreduce_wordcount_python]# vim red.py
1 #!/usr/local/bin/python
2
3 import sys
4
5 current_word = None
6 count_pool = []
7 sum = 0
8
9 for line in sys.stdin:
10 ^Iword, val = line.strip().split('\t')
11
12 ^Iif current_word == None:
13 ^I^Icurrent_word = word
14
15 ^Iif current_word != word:
16 ^I^Ifor count in count_pool:
17 ^I^I^Isum += count
18 ^I^Iprint "%s\t%s" % (current_word, sum)
19 ^I^Icurrent_word = word
20 ^I^Icount_pool = []
21 ^I^Isum = 0
22
23 ^Icount_pool.append(int(val))
24
25 for count in count_pool:
26 ^Isum += count
27 print "%s\t%s" % (current_word, str(sum))
28
red.py 28,0-1 Bot
"red.py" 28L, 464C
[root@master20 mapreduce_wordcount_python]# cat The_Man_of_Property.txt | head
Preface
“The Forsyte Saga” was the title originally destined for that part of it which is called “The Man of Property”; and to adopt it for the collected chronicles of the Forsyte family has indulged the Forsytean tenacity that is in all of us. ...
9 One has noticed that readers, as they wade on through the salt waters of
the Saga, are inclined more and more to pity Soames, and to think that
in doing so they are in revolt against the mood of his creator. Far from
it! He, too, pities Soames, the tragedy of whose life is the very simpl
e, uncontrollable tragedy of being unlovable, without quite a thick enou
gh skin to be thoroughly unconscious of the fact. Not even Fleur loves S
oames as he feels he ought to be loved. But in pitying Soames, readers i
ncline, perhaps, to animus against Irene: After all, they think, he wasn
’t a bad fellow, it wasn’t his fault; she ought to have forgiven him, an
d so on!
The_Man_of_Property.txt 1,1 Top
"The_Man_of_Property.txt" [dos] 2866L, 632207C
[root@master20 mapreduce_wordcount_python]# hadoop fs -put The_Man_of_Property.txt /
[root@master20 mapreduce_wordcount_python]# bash run.sh
# 从节点 salve21 salve22
[root@slave21 hadoop-2.6.1]# jps
8710 Jps
5900 DataNode
5998 NodeManager
8676 YarnChild
8673 YarnChild
[root@slave22 hadoop-2.6.1]# jps
6136 DataNode
9829 Jps
9746 MRAppMaster
6234 NodeManager
[root@master20 mapreduce_wordcount_python]# hadoop fs -ls /output
[root@master20 mapreduce_wordcount_python]# hadoop fs -text /output/part-00000 | head
(Baynes 1
(Dartie 1
(Dartie’s 1
(Down-by-the-starn) 2
(Down-by-the-starn), 1
(He 1
(I 1
(James) 1
(L500) 1
(Louisa 1
text: Unable to write to output stream.
[root@master20 mapreduce_wordcount_python]#
# 在浏览器输入打开监控页面:
http://master20:8088
点击logs-->stderr(错误日志),stdout(正确结果),syslog(打印日志)
使用mr计算movielen中每个用户的平均评分。
[root@master20 ml-100k]# pwd
/mnt/hgfs/share_folder/datawhale_bigdata/ml-100k
1. 首先是用户信息:
[root@master20 ml-100k]# head u.user
1|24|M|technician|85711
2|53|F|other|94043
3|23|M|writer|32067
4|24|M|technician|43537
5|33|F|other|15213
6|42|M|executive|98101
7|57|M|administrator|91344
8|36|M|administrator|05201
9|29|M|student|01002
10|53|M|lawyer|90703
其中各列数据分别为:
用户id | 用户年龄 | 用户性别 | 用户职业 | 用户邮政编码
[root@master20 ml-100k]#
2. 然后是影片信息:
[root@master20 ml-100k]# head u.item
1|Toy Story (1995)|01-Jan-1995||http://us.imdb.com/M/title-exact?Toy%20Story%20(1995)|0|0|0|1|1|1|0|0|0|0|0|0|0|0|0|0|0|0|0
2|GoldenEye (1995)|01-Jan-1995||http://us.imdb.com/M/title-exact?GoldenEye%20(1995)|0|1|1|0|0|0|0|0|0|0|0|0|0|0|0|0|1|0|0
3|Four Rooms (1995)|01-Jan-1995||http://us.imdb.com/M/title-exact?Four%20Rooms%20(1995)|0|0|0|0|0|0|0|0|0|0|0|0|0|0|0|0|1|0|0
4|Get Shorty (1995)|01-Jan-1995||http://us.imdb.com/M/title-exact?Get%20Shorty%20(1995)|0|1|0|0|0|1|0|0|1|0|0|0|0|0|0|0|0|0|0
5|Copycat (1995)|01-Jan-1995||http://us.imdb.com/M/title-exact?Copycat%20(1995)|0|0|0|0|0|0|1|0|1|0|0|0|0|0|0|0|1|0|0
6|Shanghai Triad (Yao a yao yao dao waipo qiao) (1995)|01-Jan-1995||http://us.imdb.com/Title?Yao+a+yao+yao+dao+waipo+qiao+(1995)|0|0|0|0|0|0|0|0|1|0|0|0|0|0|0|0|0|0|0
7|Twelve Monkeys (1995)|01-Jan-1995||http://us.imdb.com/M/title-exact?Twelve%20Monkeys%20(1995)|0|0|0|0|0|0|0|0|1|0|0|0|0|0|0|1|0|0|0
8|Babe (1995)|01-Jan-1995||http://us.imdb.com/M/title-exact?Babe%20(1995)|0|0|0|0|1|1|0|0|1|0|0|0|0|0|0|0|0|0|0
9|Dead Man Walking (1995)|01-Jan-1995||http://us.imdb.com/M/title-exact?Dead%20Man%20Walking%20(1995)|0|0|0|0|0|0|0|0|1|0|0|0|0|0|0|0|0|0|0
10|Richard III (1995)|22-Jan-1996||http://us.imdb.com/M/title-exact?Richard%20III%20(1995)|0|0|0|0|0|0|0|0|1|0|0|0|0|0|0|0|0|1|0
[root@master20 ml-100k]#
其中前几列数据分别为:
影片id | 影片名 | 影片发行日期 | 影片链接 | (后面几列先不去管)
3. 最后是评分数据:
[root@master20 ml-100k]# head u.data
196 242 3 881250949
186 302 3 891717742
22 377 1 878887116
244 51 2 880606923
166 346 1 886397596
298 474 4 884182806
115 265 2 881171488
253 465 5 891628467
305 451 3 886324817
6 86 3 883603013
[root@master20 ml-100k]#
其中各列数据分别为:
用户id | 影片id | 评分值 | 时间戳(timestamp格式)
下载地址为:http://files.grouplens.org/datasets/movielens/,有好几种版本,对应不同数据量,可任君选用。
本文下载数据量最小的100k版本,对该数据集进行探索:
# 查看数据信息
[root@master20 mr_ml-100K]# head u.data
196 242 3 881250949
186 302 3 891717742
22 377 1 878887116
244 51 2 880606923
166 346 1 886397596
298 474 4 884182806
115 265 2 881171488
253 465 5 891628467
305 451 3 886324817
6 86 3 883603013
其中各列数据分别为:
用户id | 影片id | 评分值 | 时间戳(timestamp格式)
# 数据量较大,先选两行测试
1043 head -2 u.data > 1.data
[root@master20 mr_ml-100K]# cat 1.data
196 242 3 881250949
186 302 3 891717742
[root@master20 datawhale_bigdata]# mkdir mr_ml-100K
[root@master20 mr_ml-100K]# pwd
/mnt/hgfs/share_folder/datawhale_bigdata/mr_ml-100K
[root@master20 mr_ml-100K]# touch map.py
[root@master20 mr_ml-100K]# vim map.py
import sys
for line in sys.stdin:
# print (line.strip())
ss = line.strip().split(' ')
#print(ss)
for s in ss:
print('\t'.join([s.strip().split('\t')[0], s.strip().split('\t')[2],'1']))
# map 阶段输出k,v (用户id | 评分值) 先本地测试,测试成功后再往集群提交
[root@master20 mr_ml-100K]# cat 1.data | python map.py
['196\t242\t3\t881250949']
196 3
['186\t302\t3\t891717742']
186 3
# red 阶段根据用户聚合K , 统计求和,求平均值
[root@master20 mr_ml-100K]# vim red.py
import sys
cur_word = None
sum = 0
nu = 0
for line in sys.stdin:
word, cnt, num = line.strip().split('\t')
#print(word,cnt, num)
if cur_word == None:
cur_word = word
if cur_word != word:
print('\t'.join([cur_word, str(avg)]))
cur_word = word
sum = 0
nu = 0
sum += int(cnt)
nu += int(num)
avg = sum/nu
print('\t'.join([cur_word, str(avg)]))
# 本地测试
[root@master20 mr_ml-100K]# cat 1.txt | python map.py | sort -k 1 | python red.py
[root@master20 mr_ml-100K]# vim run.sh
HADOOP_CMD="/usr/local/src/hadoop-2.6.1/bin/hadoop"
STREAM_JAR_PATH="/usr/local/src/hadoop-2.6.1/share/hadoop/tools/lib/hadoop-streaming-2.6.1.jar"
INPUT_FILE_PATH_1="/1.data" # 本地测试成功后改为u.data(原文件名)
OUTPUT_PATH="/output/datawhale_mr_ml-100K"
$HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH
# Step 1.
$HADOOP_CMD jar $STREAM_JAR_PATH \
-input $INPUT_FILE_PATH_1 \
-output $OUTPUT_PATH \
-mapper "python map.py" \
-reducer "python red.py" \
-file ./map.py \
-file ./red.py
# 提交文件
[root@master20 mr_ml-100K]# hadoop fs -put 1.data /
[root@master20 mr_ml-100K]# hadoop fs -put u.data /
[root@master20 mr_ml-100K]# hadoop fs -ls /
Found 16 items
-rw-r--r-- 3 root supergroup 40 2019-08-03 17:26 /1.data
-rw-r--r-- 3 root supergroup 1979173 2019-08-03 17:28 /u.data
[root@master20 mr_ml-100K]# bash run.sh
[root@master20 mr_ml-100K]#
[root@master20 mr_ml-100K]# hadoop fs -ls /output/datawhale_mr_ml-100K/part-00000
-rw-r--r-- 3 root supergroup 12 2019-08-03 17:29 /output/datawhale_mr_ml-100K/part-00000
[root@master20 mr_ml-100K]# hadoop fs -text /output/datawhale_mr_ml-100K/part-00000
186 3
196 3
[root@master20 mr_ml-100K]#
# 查看前10行
[root@master20 mr_ml-100K]# hadoop fs -text /output/datawhale_mr_ml-100K/part-00000 | head -10
1 3
10 4
100 3
101 2
102 2
103 3
104 2
105 3
106 3
107 3
text: Unable to write to output stream.
[root@master20 mr_ml-100K]#
# 查看后10行
[root@master20 mr_ml-100K]# hadoop fs -text /output/datawhale_mr_ml-100K/part-00000 | tail -10
94 3
940 3
941 4
942 4
943 3
95 3
96 4
97 4
98 3
99 3
[root@master20 mr_ml-100K]#
https://www.cppentry.com/bencandy.php?fid=115&id=191833
HDFS查看文件的前几行-后几行-行数
https://www.cnblogs.com/muchen/p/6881823.html
第一篇:使用Spark探索经典数据集MovieLens
使用mr实现merge功能。根据item,merge movielen中的 u.data u.item
[root@master20 mr_ml-100K]# head u.data
196 242 3 881250949
186 302 3 891717742
22 377 1 878887116
244 51 2 880606923
166 346 1 886397596
298 474 4 884182806
115 265 2 881171488
253 465 5 891628467
305 451 3 886324817
6 86 3 883603013
其中各列数据分别为:
用户id | 影片id | 评分值 | 时间戳(timestamp格式)
[root@master20 mr_ml-100K]# head u.item
head: cannot open `u.item' for reading: No such file or directory
[root@master20 mr_ml-100K]# head -5 u.item
1|Toy Story (1995)|01-Jan-1995||http://us.imdb.com/M/title-exact?Toy%20Story%20(1995)|0|0|0|1|1|1|0|0|0|0|0|0|0|0|0|0|0|0|0
2|GoldenEye (1995)|01-Jan-1995||http://us.imdb.com/M/title-exact?GoldenEye%20(1995)|0|1|1|0|0|0|0|0|0|0|0|0|0|0|0|0|1|0|0
3|Four Rooms (1995)|01-Jan-1995||http://us.imdb.com/M/title-exact?Four%20Rooms%20(1995)|0|0|0|0|0|0|0|0|0|0|0|0|0|0|0|0|1|0|0
4|Get Shorty (1995)|01-Jan-1995||http://us.imdb.com/M/title-exact?Get%20Shorty%20(1995)|0|1|0|0|0|1|0|0|1|0|0|0|0|0|0|0|0|0|0
5|Copycat (1995)|01-Jan-1995||http://us.imdb.com/M/title-exact?Copycat%20(1995)|0|0|0|0|0|0|1|0|1|0|0|0|0|0|0|0|1|0|0
[root@master20 mr_ml-100K]#
其中前几列数据分别为:
影片id | 影片名 | 影片发行日期 | 影片链接 | (后面几列先不去管)
[root@master20 mr_ml-100K]# head -2 u.item > 1.item
把影片id 改一下与1.data 中一样,便于测试
[root@master20 mr_ml-100K]# vim 1.item
242|Toy Story (1995)|01-Jan-1995||http://us.imdb.com/M/title-exact?Toy%20Story%20(1995)|0|0|0|1|1|1|0|0|0|0|0|0|0|0|0|0|0|0|0
302|GoldenEye (1995)|01-Jan-1995||http://us.imdb.com/M/title-exact?GoldenEye%20(1995)|0|1|1|0|0|0|0|0|0|0|0|0|0|0|0|0|1|0|0
[root@master20 mr_ml-100K]# cat 1.data
196 242 3 881250949
186 302 3 891717742
[root@master20 mr_ml-100K]# cat 1.item
242|Toy Story (1995)|01-Jan-1995||http://us.imdb.com/M/title-exact?Toy%20Story%20(1995)|0|0|0|1|1|1|0|0|0|0|0|0|0|0|0|0|0|0|0
302|GoldenEye (1995)|01-Jan-1995||http://us.imdb.com/M/title-exact?GoldenEye%20(1995)|0|1|1|0|0|0|0|0|0|0|0|0|0|0|0|0|1|0|0
[root@master20 mr_ml-100K]# hadoop fs -mkdir -p /ml-100k/input
[root@master20 mr_ml-100K]# hadoop fs -mkdir /ml-100k/output
[root@master20 mr_ml-100K]# hadoop fs -put 1.data /ml-100k/input/
[root@master20 mr_ml-100K]# hadoop fs -put 1.item /ml-100k/input/
[root@master20 mr_ml-100K]# bash run_mr_merge.sh
[root@master20 mr_ml-100K]# hadoop fs -ls /ml-100k/input
Found 4 items
-rw-r--r-- 3 root supergroup 40 2019-08-04 07:53 /ml-100k/input/1.data
-rw-r--r-- 3 root supergroup 250 2019-08-04 07:53 /ml-100k/input/1.item
-rw-r--r-- 3 root supergroup 1979173 2019-08-04 08:12 /ml-100k/input/u.data
-rw-r--r-- 3 root supergroup 236344 2019-08-04 08:12 /ml-100k/input/u.item
[root@master20 mr_ml-100K]#
[root@master20 mr_ml-100K]#
[root@master20 mr_ml-100K]# hadoop fs -text /ml-100k/output/part-00000
0 196 242 3 881250949
0 242|Toy Story (1995)|01-Jan-1995||http://us.imdb.com/M/title-exact?Toy%20Story%20(1995)|0|0|0|1|1|1|0|0|0|0|0|0|0|0|0|0|0|0|0
20 186 302 3 891717742
126 302|GoldenEye (1995)|01-Jan-1995||http://us.imdb.com/M/title-exact?GoldenEye%20(1995)|0|1|1|0|0|0|0|0|0|0|0|0|0|0|0|0|1|0|0
部分mrjob代码,参考其他同学的,感谢
使用mr实现去重任务。
from mrjob.job import MRJob
class DeRepetition(MRJob):
def mapper(self, _, line):
list_tab = line.strip().split('\t')
user_id = list_tab[0]
rating = list_tab[2]
yield user_id, rating
def reducer(self, user_id, rating):
yield user_id, set(rating)
if __name__ == '__main__':
DeRepetition.run()
运行脚本并查看结果
python de_rep.py -r local -o de_rep ./movielens/ml-100k/u.data
ls de_rep
part-00000 part-00002 part-00004 part-00006
part-00001 part-00003 part-00005 part-00007
head de_rep/part-00000
"1" ["2","3","1","4","5"]
"10" ["5","4","3"]
"100" ["2","3","1","4","5"]
"101" ["2","3","1","4","5"]
"102" ["1","2","4","3"]
"103" ["2","3","1","4","5"]
"104" ["2","3","1","4","5"]
"105" ["5","2","4","3"]
"106" ["5","2","4","3"]
"107" ["2","3","1","4","5"]
使用mr实现排序。
排序任务的具体情形是,在u.data文件中查看每个user都做出了哪些评级,并对去重过的评级进行排序
from mrjob.job import MRJob
import numpy as np
class Sort(MRJob):
def mapper(self, _, line):
list_tab = line.strip().split('\t')
user_id = list_tab[0]
rating = int(list_tab[2])
yield user_id, rating
def reducer(self, user_id, rating):
ratings = list(set(rating))
yield user_id, np.sort(ratings).tolist()
if __name__ == '__main__':
Sort.run()
python sort.py -r local -o sort ./movielens/ml-100k/u.data
ls sort
part-00000 part-00002 part-00004 part-00006
part-00001 part-00003 part-00005 part-00007
head sort/part-00000
"1" [1,2,3,4,5]
"10" [3,4,5]
"100" [1,2,3,4,5]
"101" [1,2,3,4,5]
"102" [1,2,3,4]
"103" [1,2,3,4,5]
"104" [1,2,3,4,5]
"105" [2,3,4,5]
"106" [2,3,4,5]
"107" [1,2,3,4,5]
使用mapreduce实现倒排索引。
倒排索引任务的具体情形是,在u.data文件中查看每个user都做出了哪些评级,并得到去重过的评级的倒排索引
from mrjob.job import MRJob
import numpy as np
class ReverseSort(MRJob):
def mapper(self, _, line):
list_tab = line.strip().split('\t')
user_id = list_tab[0]
rating = int(list_tab[2])
yield user_id, rating
def reducer(self, user_id, rating):
ratings = list(set(rating))
index_rev = np.argsort(ratings)[::-1]
yield user_id, index_rev.tolist()
if __name__ == '__main__':
ReverseSort.run()
python reverse_sort.py -r local -o reverse_sort ./movielens/ml-100k/u.data
head reverse_sort/part-00000
"1" [4,3,2,1,0]
"10" [2,1,0]
"100" [4,3,2,1,0]
"101" [4,3,2,1,0]
"102" [3,2,1,0]
"103" [4,3,2,1,0]
"104" [4,3,2,1,0]
"105" [3,2,1,0]
"106" [3,2,1,0]
"107" [4,3,2,1,0]
使用mapreduce计算Jaccard相似度
计算的具体情形是,对u.item里的影片类型进行Jaccard相似度计算,判断各个电影和电影1的相似度
from mrjob.job import MRJob
import numpy as np
from sklearn.metrics import jaccard_score
class Jaccard(MRJob):
def mapper(self, _, line):
list_tube = line.strip().split('|')
item_id = list_tube[0]
item_type = list_tube[5:]
yield item_id, item_type
def reducer(self, item_id, item_type):
ref_type = \
np.array([0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
item_type0 = item_type
for item_type in item_type0:
item_type = item_type
item_type = [int(num) for num in item_type]
if len(item_type) == len(ref_type):
score = jaccard_score(ref_type, np.array(item_type))
yield item_id, score
if __name__ == '__main__':
Jaccard.run()
python Jaccard.py -r local -o Jaccard ./movielens/ml-100k/u.item
head Jaccard/part-00000
"1" 1.0
"10" 0.0
"100" 0.0
"1000" 0.25
"1001" 0.3333333333
"1002" 0.3333333333
"1003" 0.5
"1004" 0.0
"1005" 0.0
"1006" 0.0
使用mapreduce实现PageRank
class PageRank(MRJob):
def mapper(self, _, line):
list_line = line.strip().split(' ')
node0 = list_line[0]
yield node0, 1
def reducer(self, node, recurrence):
n = 3
n_p = 4
alpha = 0.8
values = alpha * sum(recurrence)/n + (1 - alpha)/n_p
yield node, values
if __name__ == '__main__':
PageRank.run()
python pagerank.py -r local -o pagerank ./input_page.txt
head pagerank/part-00000
"A" 0.85
head pagerank/part-00001
"B" 0.5833333333
【Task5】Spark常用API
-
spark集群搭建
-
初步认识Spark (解决什么问题,为什么比Hadoop快,基本组件及架构Driver/)
-
理解spark的RDD
-
使用shell方式操作Spark,熟悉RDD的基本操作
-
使用jupyter连接集群的pyspark
-
理解Spark的shuffle过程
-
学会使用SparkStreaming
-
说一说take,collect,first的区别,为什么不建议使用collect?
-
向集群提交Spark程序
-
使用spark计算《The man of property》中共出现过多少不重复的单词,以及出现次数最多的10个单词。
-
计算出movielen数据集中,平均评分最高的五个电影。
-
计算出movielen中,每个用户最喜欢的前5部电影
-
学会阅读Spark源码,整理Spark任务submit过程
参考资料: 远程连接jupyter
【没有jblas库解决办法】 下载jblas包 :https://pan.baidu.com/s/1o8w6Wem
运行spark-shell时添加jar:spark-shell --jars [jblas path] /jblas-1.2.4.jar
【截止时间】任务时间是3天(最终以石墨文档的记录为准)1)2019.8.4 周日 22:00 前提交博客/Github链接(描述:任务、遇到的问题、实现代码和参考资料)2)2019.8.5中午12:00 前点评完毕
**【考核方式】**1)链接发到群里同时@点评人 + 在群里对下一号学员进行点评2)并在下面贴上自己链接、对他人的点评
【学员打卡】
spark集群搭建
jdk1.7已不适用,下面如有jdk1.7请换1.8
https://feitianbenyue.iteye.com/blog/2429045
centos jdk 1.7升级到1.8后显示还是1.7
https://blog.csdn.net/u012914436/article/details/88950607
安装scala
[root@master20 src]# pwd
/usr/local/src
[root@master20 src]# tar xvzf scala-2.11.4.tgz
[root@master20 src]# vim ~/.bashrc
23 export SCALA_HOME=/usr/local/src/scala-2.11.4 # scala
安装spark
http://archive.apache.org/dist/spark/spark-1.6.0/
# 启动hadoop
[root@master20 hadoop-2.6.1]# pwd
/usr/local/src/hadoop-2.6.1
[root@master20 hadoop-2.6.1]# ./sbin/start-all
# 查看进程
## 主
[root@master20 hadoop-2.6.1]# jps
6011 SecondaryNameNode # ok
5842 NameNode # ok
10937 Jps
6157 ResourceManager # ok
[root@master20 hadoop-2.6.1]#
# 从
[root@slave21 hadoop-2.6.1]# jps
5900 DataNode #ok
5998 NodeManager #ok
9190 Jps
[root@slave21 hadoop-2.6.1]#
#_01 conf
[root@master20 src]# pwd
/usr/local/src
[root@master20 src]# tar -xvzf spark-1.6.0-bin-hadoop2.6.tgz
[root@master20 src]# cd spark-1.6.0-bin-hadoop2.6
[root@master20 spark-1.6.0-bin-hadoop2.6]# cd conf
[root@master20 conf]# cp spark-env.sh.template spark-env.sh
[root@master20 conf]# vim spark-env.sh
55 export SCALA_HOME=/usr/local/src/scala-2.11.4
56 export JAVA_HOME=/usr/local/src/jdk1.7.0_45
57 export HADOOP_HOME=/usr/local/src/hadoop-2.6.1
58 export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
59 SPARK_MASTER_IP=master20 # 主的hostname
60 SPARK_LOCAL_DIRS=/usr/local/src/spark-1.6.0-bin-hadoop2.6
61 SPARK_DRIVER_MEMORY=1G # 实际生产中30-50G
#_02 slaves
[root@master20 conf]# ls
docker.properties.template metrics.properties.template spark-env.sh.template
fairscheduler.xml.template slaves.template
log4j.properties.template spark-defaults.conf.template
[root@master20 conf]# pwd
/usr/local/src/spark-1.6.0-bin-hadoop2.6/conf
[root@master20 conf]# cp slaves.template slaves
[root@master20 conf]# vim slaves
18 # A Spark Worker will be started on each of the machines listed below.
19 slave21
20 slave22
#_03 分发到从节点上(Scala,spark)
[root@master20 src]# scp -rp scala-2.11.4 slave21:/usr/local/src
[root@master20 src]# scp -rp scala-2.11.4 slave22:/usr/local/src
[root@master20 src]# scp -rp spark-1.6.0-bin-hadoop2.6 slave21:/usr/local/src
启动spark
/usr/local/src/spark-1.6.0-bin-hadoop2.6/sbin
[root@master20 sbin]# ./start-all.sh
#(因怕与hadoop启动冲突,故不在环境变量~/.bashrc添加spark路径)
# 主 master
[root@master20 sbin]# jps
12199 Jps
6011 SecondaryNameNode
5842 NameNode
12128 Master # ok
6157 ResourceManager
# 从 worker
[root@slave21 src]# jps
5900 DataNode
9858 Jps
5998 NodeManager
9808 Worker # ok
# 查看启动后的web 页面
http://master20:8080/
[root@master20 spark-1.6.0-bin-hadoop2.6]# pwd
/usr/local/src/spark-1.6.0-bin-hadoop2.6
# 本地模式启动
[root@master20 spark-1.6.0-bin-hadoop2.6]# ./bin/run-example SparkPi 10 --master local[2] # local[2] 本地启动两个进程
Pi is roughly 3.140368 # 出现此认为启动成功
19/03/24 22:42:57 INFO SparkUI: Stopped Spark web UI at http://192.168.28.100:4040
# 集群模式 Spark Standalone
[root@master20 spark-1.6.0-bin-hadoop2.6]# ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://master20:7077 lib/spark-examples-1.6.0-hadoop2.6.0.jar 100 ## lib...依赖的库 100 外部输入参数
Pi is roughly 3.1410928 # 启动成功
19/03/24 23:16:22 INFO SparkUI: Stopped Spark web UI at http://192.168.28.100:4040
# 集群模式 Spark on Yarn 集群上yarn-cluster 模式
[root@master20 spark-1.6.0-bin-hadoop2.6]# ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-cluster lib/spark-examples-1.6.0-hadoop2.6.0.jar 10
查看web 监控页面
master20:8088-->tracking Ui(history)-->logs-->stdout : Total file length is 22 bytes.-->Pi is roughly 3.13822 # 启动成功
yarn-client
[root@master20 spark-1.6.0-bin-hadoop2.6]# cd bin/
# python 开发spark
[root@master20 bin]# ./pyspark
>>> import sys
>>> a= [1, 2, 3, 4, 5]
>>> print a
[1, 2, 3, 4, 5]
>>>
# scala 语言 开发spark
[root@master20 bin]# ./spark-shell
scala>
scala
http://www.runoob.com/scala/scala-tutorial.html
# val final 变量 一旦定义不能再修改
# val 非final 变量,可修改
scala> val aaa = 123
aaa: Int = 123
scala> aaa = 234
:27: error: reassignment to val
aaa = 234
^
scala> var bbb = 123
bbb: Int = 123
scala> bbb = 234
bbb: Int = 234
scala>
# 多维数组 Array.ofDim[类型](维度1, 维度2, 维度3, ...)
scala> val muldimArr = Array.ofDim[Double](2,3)
muldimArr: Array[Array[Double]] = Array(Array(0.0, 0.0, 0.0), Array(0.0, 0.0, 0.0))
# 不规则数组
scala> val difLenMulArr = new Array[Array[Int]](3)
difLenMulArr: Array[Array[Int]] = Array(null, null, null)
scala> for (i <- 1 to difLenMulArr.length)
{
difLenMulArr(i-1) = new Array[Int](i)
}
scala> difLenMulArr
res3: Array[Array[Int]] = Array(Array(0), Array(0, 0), Array(0, 0, 0))
scala>
# 列表 List
scala> val oneTwo = List(1,2)
oneTwo: List[Int] = List(1, 2)
scala> val threeFour = List(3,4)
threeeFour: List[Int] = List(3, 4)
scala> val oneTwoThreeFour = oneTwo ::: threeFour
oneTwoThreeFour: List[Int] = List(1, 2, 3, 4)
##List 提供了":::" 方法实现叠加功能 (三个数组合并成一个)
scala> val twoThree = List(2,3)
twoThree: List[Int] = List(2, 3)
scala> val oneTwoThree = 1 :: twoThree
oneTwoThree: List[Int] = List(1, 2, 3)
scala> println(oneTwoThree)
List(1, 2, 3)
## List 提供了"::" 方法把一个新元素组合到已有List的最前端,然后返回结果List
# 元组(Tuple)
scala> val pair = (99, "Luftballons")
pair: (Int, String) = (99,Luftballons)
scala> println(pair._1) # 下划线+ 数字 访问元素 常用!!!
99
scala> println(pair._2)
Luftballons
scala>
# 集合(set)
## += 追加
scala> import scala.collection.immutable.Set
import scala.collection.immutable.Set
scala> var jetSet = Set("Boeing", "Airbus") // 这里定义的是不可变集
jetSet: scala.collection.immutable.Set[String] = Set(Boeing, Airbus)
scala> jetSet += "Lear" //因为是不可变集, 所以这里的 += 其实是重新赋值jetSet, 所以jetSet要声明成var 而不是val
## contains 子集
scala> println(jetSet.contains("Cessna"))
false
scala> println(jetSet.contains("Boeing"))
true
scala> println(jetSet.contains("Lear"))
true
scala> jetSet
res12: scala.collection.immutable.Set[String] = Set(Boeing, Airbus, Lear)
scala>
## ++(.++) 并集
scala> val site1 = Set("Runoob", "Google", "Baidu")
site1: scala.collection.immutable.Set[String] = Set(Runoob, Google, Baidu)
scala> val site2 = Set("Facebook", "Taobao")
site2: scala.collection.immutable.Set[String] = Set(Facebook, Taobao)
scala> var site = site1 ++ site2
site: scala.collection.immutable.Set[String] = Set(Taobao, Google, Facebook, Baidu, Runoob)
scala> site = site1.++(site2)
site: scala.collection.immutable.Set[String] = Set(Taobao, Google, Facebook, Baidu, Runoob)
scala>
## max,min 函数
scala> val num = Set(5,6,9,20,30,45)
num: scala.collection.immutable.Set[Int] = Set(5, 20, 6, 9, 45, 30)
scala> num.min
res14: Int = 5
scala> num.max
res16: Int = 45
scala>
## .&(intersect) 交集
scala> val num1 = Set(5,6,9,20,30,45)
num1: scala.collection.immutable.Set[Int] = Set(5, 20, 6, 9, 45, 30)
scala> val num2 = Set(50,60,9,20,35,55)
num2: scala.collection.immutable.Set[Int] = Set(20, 60, 9, 35, 50, 55)
scala> num1.&(num2)
res17: scala.collection.immutable.Set[Int] = Set(20, 9)
scala> num1.intersect(num2)
res18: scala.collection.immutable.Set[Int] = Set(20, 9)
scala>
# 映射(map)
# 对偶(名值对)
scala> import scala.collection.mutable.Map
import scala.collection.mutable.Map
scala> val treasureMap = Map[Int, String]() //定义一个可变的Map, 因为是可变的, 所以不需要对treasureMap 重新赋值,所以它是val
treasureMap: scala.collection.mutable.Map[Int,String] = Map()
## Map(Int -> String)
scala> treasureMap += (1 -> "Go to island.")
res20: treasureMap.type = Map(1 -> Go to island.)
scala> treasureMap += (2 -> "Find big x on ground.")
res21: treasureMap.type = Map(2 -> Find big x on ground., 1 -> Go to island.)
scala> treasureMap += (3 -> "Dig.")
res22: treasureMap.type = Map(2 -> Find big x on ground., 1 -> Go to island., 3 -> Dig.)
scala>
##
scala> treasureMap.contains((1))
res23: Boolean = true
scala> treasureMap(1)
res24: String = Go to island.
# 函数 def 函数名(参数列表):返回值类型 = {函数体}
scala> def max(x:Int, y:Int): Int = { //定义函数
| if (x > y) x
| else y
| }
max: (x: Int, y: Int)Int
scala> max (3, 7) // 调用函数
res25: Int = 7
# 扩展函数
scala> DRIVER_IDENTIFIER
LEGACY_DRIVER_IDENTIFIER Map
RDD_SCOPE_KEY RDD_SCOPE_NO_OVERRIDE_KEY
SPARK_JOB_DESCRIPTION SPARK_JOB_GROUP_ID
SPARK_JOB_INTERRUPT_ON_CANCEL Set
StringToColumn _sqlContext
abs acos
add_months approxCountDistinct
array array_contains
asc ascii
asin atan
atan2 avg
base64 bin
bitwiseNOT boolToBoolWritable
booleanWritableConverter broadcast
bytesToBytesWritable bytesWritableConverter
callUDF callUdf
cbrt ceil
classOf clearActiveContext
clone coalesce
col collect_list
collect_set column
concat concat_ws
conv corr
cos cosh
count countDistinct
crc32 cumeDist
cume_dist current_date
current_timestamp date_add
date_format date_sub
datediff dayofmonth
dayofyear decode
denseRank dense_rank
desc difLenMulArr
doubleRDDToDoubleRDDFunctions doubleToDoubleWritable
doubleWritableConverter encode
eq equals
exp explode
expm1 expr
factorial finalize
first floatToFloatWritable
floatWritableConverter floor
format_number format_string
from_unixtime from_utc_timestamp
getClass getOrCreate
get_json_object greatest
hashCode hex
hour hypot
initcap inputFileName
input_file_name instr
intRddToDataFrameHolder intToIntWritable
intWritableConverter isNaN
isTraceEnabled isnan
isnull jarOfClass
jarOfObject jetSet
json_tuple kurtosis
lag last
last_day lead
least length
levenshtein lit
localSeqToDataFrameHolder localSeqToDatasetHolder
locate log
log10 log1p
log2 logDebug
logError logInfo
logName logTrace
logWarning longRddToDataFrameHolder
longToLongWritable longWritableConverter
lower lpad
ltrim markPartiallyConstructed
max md5
mean min
minute monotonicallyIncreasingId
monotonically_increasing_id month
months_between nanvl
ne negate
newBooleanEncoder newByteEncoder
newDoubleEncoder newFloatEncoder
newIntEncoder newLongEncoder
newProductEncoder newShortEncoder
newStringEncoder next_day
not notify
notifyAll ntile
num num1
num2 numDriverCores
numericRDDToDoubleRDDFunctions oneTwo
oneTwoThree oneTwoThreeFour
pair percentRank
percent_rank pmod
pow quarter
rand randn
rank rddToAsyncRDDActions
rddToDataFrameHolder rddToDatasetHolder
rddToOrderedRDDFunctions rddToPairRDDFunctions
rddToSequenceFileRDDFunctions regexp_extract
regexp_replace repeat
res1 res10
res11 res12
res13 res14
res16 res17
res18 res2
res20 res21
res22 res23
res24 res3
res4 res6
res7 res8
res9 reverse
rint round
rowNumber row_number
rpad rtrim
sc second
setActiveContext sha1
sha2 shiftLeft
shiftRight shiftRightUnsigned
signum sin
sinh site
site1 site2
sitel size
skewness sort_array
soundex sparkPartitionId
spark_partition_id split
sql sqlContext
sqrt stddev
stddev_pop stddev_samp
stringRddToDataFrameHolder stringToText
stringWritableConverter struct
substring substring_index
sum sumDistinct
symbolToColumn synchronized
tan tanh
threeFour threeeFour
toDegrees toRadians
toString to_date
to_utc_timestamp translate
treasurMap treasureMap
trim trunc
twoThree udf
unbase64 unhex
unix_timestamp updatedConf
upper var_pop
var_samp variance
wait weekofyear
when writableWritableConverter
year
# 匿名函数
## (输入) => 输出
scala> var increase = (x : Int) => x+1
increase: Int => Int =
## foreach((输入) => 输出 )
scala> val someNumbers = List (-11, -10, -5, 0, 5, 10)
someNumbers: List[Int] = List(-11, -10, -5, 0, 5, 10)
scala> someNumbers.foreach((x:Int) => println(x))
-11
-10
-5
0
5
10
## filter (输入 => 输出条件)
scala> someNumbers.filter (x => x > 0)
res29: List[Int] = List(5, 10)
# 函数简化表达 filter(_ > 0) _ 代表参数
类似python map(lambda x:x.strip().replace('1', '2') ) # 把2替换成1,
相当于把map 上游的lambda x: 省略成 _ map(_.strip().replace('1','2'))
scala> someNumbers.filter(_ > 0)
res30: List[Int] = List(5, 10)
scala>
# 类和对象 class 声明, Scala 缺省定义未 public
scala> class ChecksumAccumulator{
| private var sum=0
| def add(b:Byte): Unit = sum +=b
| def checksum() : Int = ~(sum & 0xFF) + 1
| }
defined class ChecksumAccumulator
scala>
# 单例对象
scala> object ChecksumAccumulator {
private val cache = Map [String, Int] ()
def calculate(s:String) : Int =
if (cache.contains(s))
cache(s)
else {
val acc = new ChecksumAccumulator
for (c <- s)
acc.add(c.toByte)
val cs = acc.checksum()
cache += (s -> cs)
cs
}
}
defined module ChecksumAccumulator
warning: previously defined class ChecksumAccumulator is not a companion to object ChecksumAccumulator.
Companions must be defined together; you may wish to use :paste mode for this.
sbt
[root@master20 src]# pwd
/usr/local/src
[root@master20 src]# tar xvzf sbt-0.13.15.tgz
# 把此些命令放到bashrc里
[root@master20 sbt]# ls bin/
java9-rt-export.jar sbt sbt.bat sbt-launch.jar sbt-launch-lib.bash
[root@master20 sbt]# vim ~/.bashrc
12 fi
13
14 export JAVA_HOME=/usr/local/src/jdk1.7.0_45
15 export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib
16
17 export SCALA_HOME=/usr/local/src/scala-2.11.4
18 export HADOOP_HOME=/usr/local/src/hadoop-2.6.1
19 export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadooop
20
21 export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
22 export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
23
24 export SBT_HOME=/usr/local/src/sbt #ok
25
26 export PATH=$PATH:$JAVA_HOME/bin:$CALA_HOME/bin:$HADOOP_HOME/bin:$SBT_HOME/bin:$PATH
.bashrc [+] # ok 25,1 Bot
# 编写sbt脚本文件
[root@master20 sbt]# vim sbt
1 #!/bin/bash
2 SBT_OPTS="-Xms512M -Xmx1536M -Xss1M -XX:+CMSClassUnloadingEnabled -XX:MaxPermSize=256M"
3 java $SBT_OPTS -jar /usr/local/src/sbt/bin/sbt-launch.jar "$@"
# 修改sbt脚本文件权限
chmod u+x ./sbt
-- INSERT --
[root@master20 badou2]# pwd
/home/badou/badou2
[root@master20 badou2]# tar xvzf spark_test.tgz
[root@master20 badou2]# rm -rf spark_test.tgz
[root@master20 spark_test]# pwd
/home/badou/badou2/spark_test
[root@master20 spark_test]# mkdir -p spark_workstation/lib #
[root@master20 spark_test]# mkdir -p spark_workstation/project
# 源代码目录
[root@master20 spark_test]# mkdir -p spark_workstation/src
# 源代码编译后jar包存放的路径
[root@master20 spark_test]# mkdir -p spark_workstation/target
# 编写的scala代码
[root@master20 spark_test]# mkdir -p spark_workstation/src/main/scala
# 拷贝 (spark-assembly-1.6.0-hadoop2.6.0.jar)jar包到spark_workstation/lib lib库
[root@master20 sbt]# cd /usr/local/src/spark-1.6.0-bin-hadoop2.6/lib
[root@master20 lib]# ls
datanucleus-api-jdo-3.2.6.jar spark-1.6.0-yarn-shuffle.jar
datanucleus-core-3.2.10.jar spark-assembly-1.6.0-hadoop2.6.0.jar
datanucleus-rdbms-3.2.9.jar spark-examples-1.6.0-hadoop2.6.0.jar
# 工作开发的目录
[root@master20 spark_workstation]# pwd
/home/badou/badou2/spark_test/spark_workstation
[root@master20 spark_test]# tree ./
./
└── spark_workstation # scala 项目文件
├── build.sbt # 定义生成项目jar包的文件名
├── lib
├── project
├── src
│ └── main
│ └── scala # 编写的scala 代码
│ └── spark # spark 与下面的example 自己随便定义的
│ └── example
│ └── Test.scala
├── target # 生成的jar包
└── train_new.data
# 若下载慢,可添加阿里云
[root@master20 .sbt]# vim repositories
1 [repositories]
2 localmy-maven-repo: https://maven.aliyun.com/repository/public]
# 编译国内源
https://www.oschina.net/question/3028912_2205632?sort=default
https://www.cnblogs.com/codingexperience/p/5372617.html
[root@master20 spark_wordcount]# vim build.sbt
1 name := "WordCount" # 编译后的jar包文件名
2 version := "1.6.0"
3 scalaVersion := "2.11.4"
4 libraryDependencies ++= Seq(
5 "ch.qos.logback" % "logback-core" % "1.0.0",
6 "ch.qos.logback" % "logback-classic" % "1.0.0",
7 ...
8 )
9 libraryDependencies ++= Seq("org.scalatest" %% "scalatest" % "1.8" % "test")
# 代码实例
# 输入文件
[root@master20 spark_test]# hadoop fs -put train_new.data hdfs://master20:9000/
[root@master20 spark_test]# hadoop fs -text hdfs://master20:9000/train_new.data | head -10
19/03/31 18:05:38 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
用户 物品 对物品偏好的打分
1 100001 5
1 100002 3
1 100003 4
1 100004 3
1 100005 3
1 100007 4
1 100008 1
1 100009 5
1 1000011 2
1 1000013 5
[root@master20 example]# pwd
/home/badou/badou2/spark_test/spark_workstation/src/main/scala/spark/example
[root@master20 example]# vim Test.scala
1 package spark.example
2
3 import org.apache.spark._
4 import SparkContext._
5
6 object Test {
7 ----
8 def main(args: Array[String]){
9 --------
10 val conf = new SparkConf().setAppName("Test") # application 名字
11 --------
12 val sc = new SparkContex(conf) # 入口
13 val lines = sc.textFile(args(0)) # 输入 读取hdfs文件路径数据
14 val output_path = args(1).toString # 输出
15
16 /*
17 * Step 1.
18 * Obtain UI Matrix:
19 */
20 val ui_rdd = lines.filter{ x => # x 读入一行数据
21 val fields = x.split(" ") # "^I"以制表符分隔(ctrl + v + i)
22 fields(0).toString == "99" # 等于99的值留下,其余放弃
23 }.map { x =>
24 val fields = x.split(" ")
25 fields(0).toString + "\t" +fields(2).toString # 把第2列数据过滤掉,其余 拼接
26 }.saveAsTextFile(output_path) # 结果直接存在hdfs上
27 }
28 }
[root@master20 example]# cd /home/badou/badou2/spark_test/spark_workstation
[root@master20 spark_workstation]# pwd
/home/badou/badou2/spark_test/spark_workstation
[root@master20 spark_workstation]# sbt compile # 编译(只需要执行一次)
[root@master20 spark_workstation]# sbt package # 相当于对此目录下所有代码进行打成jar包
# 生成jar包
[root@master20 scala-2.11]# pwd
/home/badou/badou2/spark_test/spark_workstation/target/scala-2.11
[root@master20 scala-2.11]# ls
classes wordcount_2.11-1.6.0.jar #这个jar包包含了scala目录下的所欲功能
[root@master20 scala-2.11]# date
Mon Apr 1 17:18:41 CST 2019
[root@master20 scala-2.11]# ll wordcount_2.11-1.6.0.jar
-rw-r--r--. 1 root root 3832 Apr 1 17:15 wordcount_2.11-1.6.0.jar
[root@master20 scala-2.11]#
[root@master20 spark_workstation]# vim run_test.sh
1 #!/usr/bin/env bash
2
3 hadoop fs -rmr /spark_test_output
4
5 #/usr/local/src/spark-1.6.0-bin-hadoop2.6/bin/spark-submit --master spark://master:7077 \
6 /usr/local/src/spark-1.6.0-bin-hadoop2.6/bin/spark-submit --master yarn-cluster \
7 --num-executors 2 \
8 --executor-memory '512m' \
9 --executor-cores 1 \
# --class 要提交的代码案例spark.example是路径,Test是类,后面是jar包
10 --class spark.example.Test ./target/scala-2.11/wordcount_2.11-1.6.0.jar \
11 hdfs://master:9000/train_new.data \
12 hdfs://master20:9000/spark_test_output
13
[root@master20 spark_workstation]# ls
build.sbt lib project run_test.sh src target train_new.data
[root@master20 spark_workstation]# bash run_test.sh
# 输出
[root@master20 spark_workstation]# hadoop fs -ls hdfs://master20:9000/spark_test_output
[root@master20 spark_workstation]# hadoop fs -text hdfs://master20:9000/spark_test_output/part-00001 | head
19/04/01 21:28:58 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
99 4
99 5
99 3
99 3
99 5
99 4
99 5
99 2
99 2
99 5
# 实例2: WordCount
package spark.example
import org.apache.spark._
import SparkContext._
object WordCount {
def main(args: Array[String]) {
# 参数判断
if (args.length == 0) {
System.err.println("Usage: spark.example.WordCount )
System.exit(1)
}
val input_path = args(0).toString # 输入路径
val output_path = args(1).toString # 输出路径
val conf = new SparkConf().setAppName("WordCount") # 任务名字
# KryoSerializer序列化可加可不加
# conf配置
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
val sc = new SparkContext(conf)
val inputFile = sc.textFile(input_path) # 从hdfs读取文件,转化为rdd
# 读入数据按空格进行分割,分割成数组,即输入一句话,输出为单词,个数, 为1对多的关系,用flatMap
val countResult = inputFile.flatMap(line => line.split(" "))
.map(word => (word, 1)) # 接map,每个单词加1
.reduceByKey(_ + _) # 按key 聚合 _ + _ value 相加
.map(x => x._1 + "\t" + x._2) # ._1 定位,索引
.saveAsTextFile(output_path)
}
}
# vim run_wordcount.sh
[root@master20 spark_workstation]# vim run_wordcount.sh
1 #!/usr/bin/env bash
2
3 hadoop fs -rmr /spark_word_count_output
4 /usr/local/src/spark-1.6.0-bin-hadoop2.6/bin/spark-submit --master yarn-cluster \
5 --num-executors 2 \
6 --executor-memory '512m' \
7 --executor-cores 1 \
8 --class spark.example.WordCount ./target/scala-2.11/wordcount_2.11-1.6.0.jar \
9 hdfs://master20:9000/The_Man_of_Property.txt \
10 hdfs://master20:9000/spark_word_count_output
11
[root@master20 spark_workstation]# ls
1 build.sbt lib project run_test.sh run_wordcount.sh src target train_new.data
[root@master20 spark_workstation]# bash run_wordcount.sh
[root@master20 spark_workstation]# hadoop fs -ls hdfs://master20:9000/spark_word_count_output
Found 3 items
-rw-r--r-- 3 root supergroup 0 2019-04-03 16:36 hdfs://master20:9000/spark_word_count_output/_SUCCESS
-rw-r--r-- 3 root supergroup 90962 2019-04-03 16:36 hdfs://master20:9000/spark_word_count_output/part-00000
-rw-r--r-- 3 root supergroup 90572 2019-04-03 16:36 hdfs://master20:9000/spark_word_count_output/part-00001
[root@master20 spark_workstation]# hadoop fs -text hdfs://master20:9000/spark_word_count_output/part-00001 |head
one.” 1
‘fed 1
Let 3
softly. 3
George’s 6
averted. 1
tears. 1
instance, 7
taste 8
secure 3
text: Unable to write to output stream.
# 实例3:
[root@master20 example]# pwd
/home/badou/badou2/spark_test/spark_workstation/src/main/scala/spark/example
Last login: Tue Apr 2 10:52:44 2019 from 192.168.28.1
[root@master20 example]# ls
ALS.scala Test.scala WordCount.scala
[root@master20 example]# vim ALS.scala
1 package spark.example
2
3 import org.apache.spark.SparkConf
4 import org.apache.spark.SparkContext
5 import org.apache.spark.SparkContext._
6 import org.apache.spark.rdd._
7 import org.apache.spark.mllib.recommendation.{ALS, Rating, MatrixFactorizationModel}
8
9 object MovieLensALS {
10 def main(args: Array[String]) {
11
12 val conf = new SparkConf()
13 .setAppName("MovieLensALS")
14 .set("spark.executor.memory", "1g")
15
16 val sc = new SparkContext(conf)
17
18 val ratings=sc.textFile("/u1.test").map{
19 line=>val fields=line.split("\t") # \t 分割
20 (fields(3).toLong%10, Rating(fields(0)toInt, fields(1).toInt,fields # 把第四列数据追加到最前面
(2).toDouble))
21 }
22
23 val movies = sc.textFile("/u.item").map{
24 line=>val fields=line.split('|')
25 (fields(0).toInt,fields(1))
26 }
27
28 val numRatings = ratings.count # .count 是action ,之前所有的算子都开始处理,numRatings 数据的行数
29 val numUsers = ratings.map(_._2.user).distinct.count # 去重统计
30 val numMovies = ratings.map(_._2.product).distinct.count
31 println("Got " + numRatings + " ratings from "
32 + numUsers + " users on " + numMovies + " movies.")
33 }
34 }
35
36
37
# u1.test
[root@master20 spark_workstation]# hadoop fs -text /u1.test | head
1 6 5 887431973
1 10 3 875693118
1 12 5 878542960
1 14 5 874965706
1 17 3 875073198
1 20 4 887431883
1 23 4 875072895
1 24 3 875071713
1 27 2 876892946
1 31 3 875072144
text: Unable to write to output stream.
[root@master20 spark_workstation]#
[root@master20 spark_workstation]# pwd
/home/badou/badou2/spark_test/spark_workstation
[root@master20 spark_workstation]# sbt package
...
[info] Packaging /home/badou/badou2/spark_test/spark_workstation/target/scala-2.11/wordcount_2.11-1.6.0.jar ...
[info] Done packaging.
[success] Total time: 10 s, completed Apr 3, 2019 7:48:05 PM
# 实例4 :NB.scala
[root@master20 example]# vim NB.scala
1 package spark.example
2
3 import org.apache.spark.mllib.classification.NaiveBayes
4 import org.apache.spark.mllib.linalg.Vectors
5 import org.apache.spark.mllib.regression.LabeledPoint
6 import org.apache.spark.{SparkContext,SparkConf}
7
8 object naiveBayes {
9 def main(args: Array[String]) {
10
11
12 val conf = new SparkConf().setAppName("naiveBayes")
13 val sc = new SparkContext(conf)
14
15 val data = sc.textFile(args(0))
16 val parsedData =data.map { line =>
17 val parts =line.split(',') # 首先以逗号分割
18 LabeledPoint(parts(0).toDouble,Vectors.dense(parts(1).split(' ').map(_.toDouble
)))
19 }
20 # 60%测试集,40%训练集
21 val splits = parsedData.randomSplit(Array(0.6,0.4),seed = 11L)
22 val training =splits(0)
23 val test = splits(1)
24
25 val model = NaiveBayes.train(training,lambda = 1.0) # 训练出的模型
26 # 在预测集上预测
27 val predictionAndLabel= test.map(p => (model.predict(p.features),p.label))
# 正确率
28 val accuracy =1.0 *predictionAndLabel.filter(x => x._1 == x._2).count() / test.coun
t()
29
30 println("accuracy-->"+accuracy)
31 println("Predictionof (0.0, 2.0, 0.0, 1.0):"+model.predict(Vectors.dense(0.0,2.0,0.
0,1.0)))
32 println("Predictionof (2.0, 1.0, 0.0, 0.0):"+model.predict(Vectors.dense(0.0,2.0,0.
0,1.0)))
33 }
34 }
NB.scala 34,1 Bot
[root@master20 spark_workstation]# vim run_nb.sh
1 #!/usr/bin/env bash
2
3 /usr/local/src/spark-1.6.0-bin-hadoop2.6/bin/spark-submit --master yarn-cluster \
4 --num-executors 2 \
5 --executor-memory '1024m' \
6 --executor-cores 1 \
7 --class spark.example.naiveBayes ./target/scala-2.11/wordcount_2.11-1.6.0.jar \
8 hdfs://master20(根据自己的hostname修改):9000/a.txt
9
[root@master20 spark_test]# vim a.txt
逗号前为标签, 逗号后为数据
1 0,0 0 0 0
2 0,0 0 0 1
3 1,1 0 0 0
4 1,2 1 0 0
5 1,2 2 1 0
6 0,2 2 1 1
7 1,1 2 1 1
8 0,0 1 0 0
9 1,0 2 1 0
10 1,2 1 1 0
11 1,0 1 1 1
12 1,1 1 0 1
13 1,1 0 1 0
14 0,2 1 0 1
[root@master20 spark_workstation]# sbt package
[success] Total time: 1 s, completed Apr 3, 2019 8:44:44 PM
[root@master20 spark_workstation]#
[root@master20 spark_workstation]# bash run_nb.sh
浏览器:http://master20:8088/cluster
右面trackingUI->History->Logs->stdout(若出错可查看stderr)
accuracy-->0.75
Predictionof (0.0, 2.0, 0.0, 1.0):0.0
Predictionof (2.0, 1.0, 0.0, 0.0):0.0
初步认识Spark
(解决什么问题,为什么比Hadoop快,基本组件及架构Driver/)
#解决什么问题
随着大数据的发展,人们对大数据的处理要求也越来越高,原有的批处理框架MapReduce适合离线计算,却无法满足实时性要求较高的业务,如实时推荐、用户行为分析等。 Spark Streaming是建立在Spark上的实时计算框架,通过它提供的丰富的API、基于内存的高速执行引擎,用户可以结合流式、批处理和交互试查询应用。
# 为什么比Hadoop快
(1)spark大量使用内存
(2)核心数据结构:RDD(弹性分布式数据集),在此基础上提供了许多计算函数,
(3)在原先hadoop下一个map或reduce实现的功能,在spark下可以拆分成多个job.如果把hadoop看做罐子里的大石头,那么spark的job就是罐子里的碎石子,可以装的更多。
()
---------------------
作者:seareal1
来源:CSDN
原文:https://blog.csdn.net/seareal1/article/details/80081687
版权声明:本文为博主原创文章,转载请附上博文链接!
https://blog.csdn.net/LLJJYY001/article/details/81464173
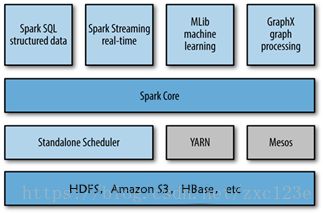
Spark基本架构及运行原理
Spark Core:
包含Spark的基本功能,包含任务调度,内存管理,容错机制等,内部定义了RDDs(弹性分布式数据集),提供了很多APIs来创建和操作这些RDDs。为其他组件提供底层的服务。
Spark SQL:
Spark处理结构化数据的库,就像Hive SQL,Mysql一样,企业中用来做报表统计。
Spark Streaming:
实时数据流处理组件,类似Storm。Spark Streaming提供了API来操作实时流数据。企业中用来从Kafka接收数据做实时统计。
MLlib:
一个包含通用机器学习功能的包,Machine learning lib包含分类,聚类,回归等,还包括模型评估和数据导入。MLlib提供的上面这些方法,都支持集群上的横向扩展。
Graphx:
处理图的库(例如,社交网络图),并进行图的并行计算。像Spark Streaming,Spark SQL一样,它也继承了RDD API。它提供了各种图的操作,和常用的图算法,例如PangeRank算法。
Spark提供了全方位的软件栈,只要掌握Spark一门编程语言就可以编写不同应用场景的应用程序(批处理,流计算,图计算等)。Spark主要用来代替Hadoop的MapReduce部分。
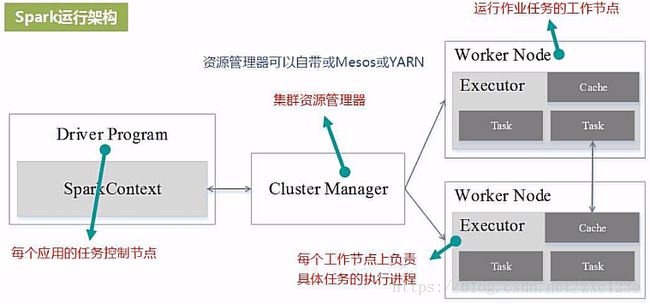
作者:zxc123e
来源:CSDN
原文:https://blog.csdn.net/zxc123e/article/details/79912343
版权声明:本文为博主原创文章,转载请附上博文链接!
Spark运行架构及流程
基本概念:
Application:用户编写的Spark应用程序。
Driver:Spark中的Driver即运行上述Application的main函数并创建SparkContext,创建SparkContext的目的是为了准备Spark应用程序的运行环境,在Spark中有SparkContext负责与ClusterManager通信,进行资源申请、任务的分配和监控等,当Executor部分运行完毕后,Driver同时负责将SparkContext关闭。
Executor:是运行在工作节点(WorkerNode)的一个进程,负责运行Task。
RDD:弹性分布式数据集,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型。
DAG:有向无环图,反映RDD之间的依赖关系。
Task:运行在Executor上的工作单元。
Job:一个Job包含多个RDD及作用于相应RDD上的各种操作。
Stage:是Job的基本调度单位,一个Job会分为多组Task,每组Task被称为Stage,或者也被称为TaskSet,代表一组关联的,相互之间没有Shuffle依赖关系的任务组成的任务集。
Cluter Manager:指的是在集群上获取资源的外部服务。目前有三种类型
- Standalon : spark原生的资源管理,由Master负责资源的分配
- Apache Mesos:与hadoop MR兼容性良好的一种资源调度框架
- Hadoop Yarn: 主要是指Yarn中的ResourceManager
一个Application由一个Driver和若干个Job构成,一个Job由多个Stage构成,一个Stage由多个没有Shuffle关系的Task组成。
当执行一个Application时,Driver会向集群管理器申请资源,启动Executor,并向Executor发送应用程序代码和文件,然后在Executor上执行Task,运行结束后,执行结果会返回给Driver,或者写到HDFS或者其它数据库中
作者:zxc123e
来源:CSDN
原文:https://blog.csdn.net/zxc123e/article/details/79912343
版权声明:本文为博主原创文章,转载请附上博文链接!
理解spark的RDD
一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合,每个RDD可分成多个分区,每个分区就是一个数据集片段,并且一个RDD的不同分区可以被保存到集群中不同的节点上,从而可以在集群的不同节点上进行并行计算。
RDD提供了一种高端受限的共享内存模型,即RDD是只读的记录分区的集合,不能直接修改,只能基于稳定的物理存储中的数据集创建RDD,或者通过在其他RDD上执行确定的转换操作(如map,join和group by)而创建得到新的RDD。
RDD执行过程:
RDD读入外部数据源进行创建
RDD经过一系列的转换(Transformation)操作,没一次都会产生不同的RDD供下一个转换操作使用
最后一个RDD经过“动作”操作进行转换并输出到外部数据源
优点:惰性调用、管道化、避免同步等待,不需要保存中间结果。这和Java8中Stream的概念极其类似。
RDD特性
高效的容错性,根据DAG图恢复分区,数据复制或者记录日志
RDD血缘关系、重新计算丢失分区、无需回滚系统、重算过程在不同节点之间并行、只记录粗粒度的操作
中间结果持久化到内存,数据在内存中的多个RDD操作之间进行传递,避免了不必要的读写磁盘开销
存放的数据可以是Java对象,避免了不必要的对象序列化和反序列化
窄依赖和宽依赖
窄依赖:表现为一个父RDD的分区对应于一个子RDD的分区或者多个父RDD的分区对应于一个子RDD的分区。
宽依赖:表现为存在一个父RDD的一个分区对应一个子RDD的多个分区。
Stage的划分
Spark通过分析各个RDD的依赖关系生成了DAG,在通过分析各个RDD中的分区之间的依赖关系来决定如何划分Stage。具体划分方法如下:
在DAG中进行反向解析,遇到宽依赖就断开,遇到窄依赖就把当前的RDD加入到Stage中;
将窄依赖尽量划分在同一个Stage中,可以实现流水线计算
此文主要参考厦门大学Spark基础教程
---------------------
作者:zxc123e
来源:CSDN
原文:https://blog.csdn.net/zxc123e/article/details/79912343
版权声明:本文为博主原创文章,转载请附上博文链接!
使用shell方式操作Spark,熟悉RDD的基本操作
spark RDD的常用操作
spark RDD的常用操作
RDD的操作分为两种,一种是转化操作,一种是执行操作,转化操作并不会立即执行,而是到了执行操作才会被执行
转化操作:
map() 参数是函数,函数应用于RDD每一个元素,返回值是新的RDD
flatMap() 参数是函数,函数应用于RDD每一个元素,将元素数据进行拆分,变成迭代器,返回值是新的RDD
filter() 参数是函数,函数会过滤掉不符合条件的元素,返回值是新的RDD
distinct() 没有参数,将RDD里的元素进行去重操作
union() 参数是RDD,生成包含两个RDD所有元素的新RDD
intersection() 参数是RDD,求出两个RDD的共同元素
subtract() 参数是RDD,将原RDD里和参数RDD里相同的元素去掉
cartesian() 参数是RDD,求两个RDD的笛卡儿积
行动操作:
collect() 返回RDD所有元素
count() RDD里元素个数
countByValue() 各元素在RDD中出现次数
reduce() 并行整合所有RDD数据,例如求和操作
fold(0)(func) 和reduce功能一样,不过fold带有初始值
aggregate(0)(seqOp,combop) 和reduce功能一样,但是返回的RDD数据类型和原RDD不一样
foreach(func) 对RDD每个元素都是使用特定函数
行动操作每次的调用时不会存储前面的计算结果的,若果想要存储前面的操作结果需要把结果加载需要在需要缓存中间结果的RDD调用cache(),cache()方法是把中间结果缓存到内存中,也可以指定缓存到磁盘中(也可以只用persisit())
---------------------
作者:小牛学堂2019
来源:CSDN
原文:https://blog.csdn.net/HANLIPENGHANLIPENG/article/details/53508746
版权声明:本文为博主原创文章,转载请附上博文链接!
Learning Spark——使用spark-shell运行Word Count
https://blog.csdn.net/Trigl/article/details/70445949
scala> val textFile = sc.textFile("hdfs://master20:9000/The_Man_of_Property.txt")
textFile: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[7] at textFile at <console>:27
scala> val wordCounts = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b)
scala> wordCounts.collect()
res8: Array[(String, Int)] = Array((scornfully.,1), (dangerous!”,1), (mattered,1), (Ah!,7), (one.”,1), (Let,3), (bone,1), (softly.,3), (Phil,”,1), (park,,2), (welshed,1), (father-in-law,1), (taste,8), (gaping,1), (secure,3), (hem,1), (onyx,1), (Imperial,1), (end,38), (irritatingly,2), (brains,1), (been,337), (all,’,3), (tough,1), (they,,5), (Fiske,1), (crying,3), (soon;,1), (inquisitively,,1), (breath,5), (musician,,1), (clients,2), (swain,1), (situation;,1), (coat;,2), (afterward,1), (8,,1), (different,15), (She’d,1), (joined.,1), (tea,,5), (stern,1), (constitution),,1), (seductive,2), (Bar.,1), (Nature,5), (people!,1), (Bosinney’s.,2), (Jo,”,3), (Italian!”,1), (altogether,,2), (entered.,2), (visit.,1), (understand?”,1), (dangers,1), (less,”,1), (mobile’,1), (whimpered,1), (descending,...
scala>
使用jupyter连接集群的pyspark
https://blog.csdn.net/weixin_41867777/article/details/80401640
Hadoop+spark+jupyter环境搭建(三):Pyspark+jupyter部署在Linux
https://blog.csdn.net/u013129944/article/details/80107214
jupyter中使用pyspark连接spark集群
https://blog.csdn.net/RayCchou/article/details/51273117
Linux下远程连接Jupyter+pyspark部署教程
https://mp.weixin.qq.com/s/gIf_QGQL26MqMzZKk-YTLg
Spark伪分布式环境搭建 + jupyter连接spark集群
https://blog.csdn.net/qq_23860475/article/details/90476197
pyspark:连接spark集群Windows环境搭建
[root@master20 ~]$ pip install jupyter -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
[root@master20 badou]# vim ~/.bashrc
31
32 export JUPYTER=/usr/local/src/python3.6.3
33
34 export PATH=$PATH:$JAVA_HOME/bin:$SCALA_HOME/bin:$HADOOP_HOME/bin:$SBT_HO
ME/bin:$KAFKA_HOME/bin:$FLUME_HOME/bin:$JUPYTER/bin:$PATH
[root@master20 badou]# source ~/.bashrc
https://www.cnblogs.com/sharesdk/p/10070988.html
python3.6.0 提示 ModuleNotFoundError: No module named '_ssl' 模块问题 ;
检测 系统 安装 OpenSSL
yum install openssl-devel bzip2-devel expat-devel gdbm-devel readline-devel sqlite-devel gcc gcc-c++ openssl-devel
然后 重新编译 python
编辑 取消注释 以下几行:
~ python3-6-3/Modules/Setup.dist
大约在 209 行
209 SSL=/usr/local/ssl
210 _ssl _ssl.c \
211 -DUSE_SSL -I$(SSL)/include -I$(SSL)/include/openssl \
212 -L$(SSL)/lib -lssl -lcrypto
重新编译
./configure --prefix=/usr/local/src/python3.6.3
make
make install
python 3.6.0 (default, Nov 30 2018, 15:04:54)
[GCC 4.4.7 20120313 (Red Hat 4.4.7-16)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import ssl
>>>
Use quit() or Ctrl-D (i.e. EOF) to exit
import ssl 没有提示,验证正常。
[root@master20 Python-3.6.3]# vim ~/.jupyter/jupyter_notebook_config.py
85 #c.NotebookApp.allow_root = False
86 c.NotebookApp.allow_root = True
204 #c.NotebookApp.ip = 'localhost'
205 c.NotebookApp.ip = '*'
206 c.NotebookApp.password = u'sha1:801205fa5b4b:c402d5fa3c6a4503ef531efe2192
1e1e5542d661'
207 c.NotebookApp.open_browser = False
208 c.NotebookApp.port = 8888
209 NotebookApp.allow_root=True # 依root账户启动
[root@master20 python3.6.3]# jupyter notebook
[I 16:17:09.550 NotebookApp] http://master20:8888/
https://blog.csdn.net/u014676657/article/details/83750224
阿里云服务器安装jupyter
密码:111111
https://blog.csdn.net/qq_18293213/article/details/72910834
在服务器上配置jupyter, 远程登录
[root@master20 badou]# pip install pypandoc py4j
[root@master20 badou]# pip install pyspark -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
理解Spark的shuffle过程
shuffle write:
stage结束之后,每个task处理的数据按key进行“分类”
数据先写入内存缓冲区
缓冲区满,溢出到磁盘文件
最终,相同key被写入同一个磁盘文件
创建的磁盘文件数量 = 当前stagetask数量 * 下一个stage的task数量
shuffle read:
从上游stage的所有task节点上拉取属于自己的磁盘文件
每个read task会有自己的buffer缓冲,每次只能拉取与buffer缓冲相同大小的数据,然后聚合,聚合完一批后拉取下一批
该拉取过程,边拉取边聚合
---------------------
作者:OddBillow
来源:CSDN
原文:https://blog.csdn.net/quitozang/article/details/80904040
版权声明:本文为博主原创文章,转载请附上博文链接!
[root@master20 badou]# pip install pypandoc py4j
https://blog.csdn.net/quitozang/article/details/80904040
关于spark shuffle过程的理解
学会使用SparkStreaming
4.使用spark-Streaming进行流式wordcount计算
package day07
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Milliseconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
/*
rdd:创建程序入口 sparkContext
dataframe: sparkSession
Dstream:
*/
object WordCount {
def main(args: Array[String]): Unit = {
//1.创建sparkCOntect
val conf = new SparkConf().setAppName("WordCount").setMaster("local[2]")
val sc = new SparkContext(conf)
//2.创建streamingContext
val ssc: StreamingContext = new StreamingContext(sc,Milliseconds(2000))
//3.可以创建Dstream, 首先接入数据源
//socket
val data: ReceiverInputDStream[String] =
ssc.socketTextStream("192.168.64.111",7788)
//4.进行计算,创建dstream
val rd: DStream[(String, Int)] = data
.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
//5.打印结果
rd.print()
//6.注意:需要启动sparstreaming程序
ssc.start()
ssc.awaitTermination()
}
}
说一说take,collect,first的区别,为什么不建议使用collect?
take
rdd.take(n)返回第n个元素
scala> val rdd = sc.parallelize(List(1,2,3,3))
scala> rdd.take(2)
res3: Array[Int] = Array(1, 2)
first
返回第一个元素
scala> val rdd = sc.parallelize(List(1,2,3,3))
scala> rdd.first()
res1: Int = 1
collect
rdd.collect() 返回 RDD 中的所有元素
scala> val rdd = sc.parallelize(List(1,2,3,3))
scala> rdd.collect()
res4: Array[Int] = Array(1, 2, 3, 3)
官方原文如下
Printing elements of an RDD
Another common idiom is attempting to print out the elements of an RDD using rdd.foreach(println) or rdd.map(println). On a single machine, this will generate the expected output and print all the RDD’s elements. However, in cluster mode, the output to stdout being called by the executors is now writing to the executor’s stdout instead, not the one on the driver, so stdout on the driver won’t show these! To print all elements on the driver, one can use the collect() method to first bring the RDD to the driver node thus: rdd.collect().foreach(println). This can cause the driver to run out of memory, though, because collect() fetches the entire RDD to a single machine; if you only need to print a few elements of the RDD, a safer approach is to use the take(): rdd.take(100).foreach(println).
主要意思是:
打印一个弹性分布式数据集元素,使用时要注意不要导致内存溢出!
建议使用 take(): rdd.take(100).foreach(println),
而不使用rdd.collect().foreach(println)。
因为后者会导致内存溢出!!
---------------------
作者:highfei2011
来源:CSDN
原文:https://blog.csdn.net/high2011/article/details/53138279
版权声明:本文为博主原创文章,转载请附上博文链接!
向集群提交Spark程序
向Spark集群提交任务(https://www.cnblogs.com/dhName/p/10593762.html)
1.启动spark集群。
启动Hadoop集群
cd /usr/local/hadoop/
sbin/start-all.sh
启动Spark的Master节点和所有slaves节点
cd /usr/local/spark/
sbin/start-master.sh
sbin/start-slaves.sh
2.standalone模式:
向独立集群管理器提交应用,需要把spark://master:7077作为主节点参数递给spark-submit。下面我们可以运行Spark安装好以后自带的样例程序SparkPi,它的功能是计算得到pi的值(3.1415926)。
在Shell中输入如下命令:
bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://master:7077 examples/jars/spark-examples_2.11-2.0.2.jar 100 2>&1 | grep "Pi is roughly"
3.hadoop yarn 管理模式:
向Hadoop YARN集群管理器提交应用,需要把yarn-cluster作为主节点参数递给spark-submit。请登录Linux系统,打开一个终端,在Shell中输入如下命令:
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-cluster examples/jars/spark-examples_2.11-2.0.2.jar
输入途中的urI,即可查看任务进程。
使用spark计算《The man of property》
使用spark计算《The man of property》中共出现过多少不重复的单词,以及出现次数最多的10个单词。
1.在集群上 面运行
[root@master20 spark_test]# mkdir -p spark_workstation/lib #
[root@master20 spark_test]# mkdir -p spark_workstation/project
# 源代码目录
[root@master20 spark_test]# mkdir -p spark_workstation/src
# 源代码编译后jar包存放的路径
[root@master20 spark_test]# mkdir -p spark_workstation/target
# 编写的scala代码
[root@master20 spark_test]# mkdir -p spark_workstation/src/main/scala
# 拷贝 (spark-assembly-1.6.0-hadoop2.6.0.jar)jar包到spark_workstation/lib lib库
[root@master20 sbt]# cd /usr/local/src/spark-1.6.0-bin-hadoop2.6/lib
[root@master20 lib]# ls
datanucleus-api-jdo-3.2.6.jar spark-1.6.0-yarn-shuffle.jar
datanucleus-core-3.2.10.jar spark-assembly-1.6.0-hadoop2.6.0.jar
datanucleus-rdbms-3.2.9.jar spark-examples-1.6.0-hadoop2.6.0.jar
# 工作开发的目录
[root@master20 spark_workstation]# pwd
/home/badou/datawhale/bigdata/datawhale_spark/spark_workstation
[root@master20 datawhale_spark]# tree ./
./
└── spark_workstation # scala 项目文件
├── build.sbt # 定义生成项目jar包的文件名
├── lib
├── project
├── src
│ └── main
│ └── scala # 编写的scala 代码
│ └── spark # spark 与下面的example 自己随便定义的
│ └── example
│ └── Test.scala
├── target # 生成的jar包
└── train_new.data
# 若下载慢,可添加阿里云
[root@master20 .sbt]# vim repositories
1 [repositories]
2 localmy-maven-repo: https://maven.aliyun.com/repository/public]
# 编译国内源
https://www.oschina.net/question/3028912_2205632?sort=default
https://www.cnblogs.com/codingexperience/p/5372617.html
[root@master20 spark_workstation]# vim build.sbt
1 name := "WordCount" # 编译后的jar包文件名
2 version := "1.6.0"
3 scalaVersion := "2.11.4"
4 libraryDependencies ++= Seq(
5 "ch.qos.logback" % "logback-core" % "1.0.0",
6 "ch.qos.logback" % "logback-classic" % "1.0.0",
7 ...
8 )
9 libraryDependencies ++= Seq("org.scalatest" %% "scalatest" % "1.8" % "test")
# 输出文件
[root@master20 badou]# hadoop fs -mkdir /output/spark
# 输入文件到hdfs
[root@master20 badou]# hadoop fs -put ./The_Man_of_Property.txt /
[root@master20 badou]# hadoop fs -text /The_Man_of_Property.txt | head -3
Preface
“The Forsyte Saga” was the title originally destined for that part of it which is called “The Man of Property”; and to adopt it for the collected chronicles of the Forsyte family has indulged the Forsytean tenacity that is in all of us. The word Saga might be objected to on the ground that it connotes the heroic and that there is little heroism in these pages. But it is used with a suitable irony; and, after all, this long tale, though it may deal with folk in frock coats, furbelows, and a gilt-edged period, is not devoid of the essential heat of conflict. Discounting for the gigantic stature and blood-thirstiness of old days, as they have come down to us in fairy-tale and legend, the folk of the old Sagas were Forsytes, assuredly, in their possessive instincts, and as little proof against the inroads of beauty and passion as Swithin, Soames, or even Young Jolyon. And if heroic figures, in days that never were, seem to startle out from their surroundings in fashion unbecoming to a Forsyte of the Victorian era, we may be sure that tribal instinct was even then the prime force, and that “family” and the sense of home and property counted as they do to this day, for all the recent efforts to “talk them out.”
So many people have written and claimed that their families were the originals of the Forsytes that one has been almost encouraged to believe in the typicality of an imagined species. Manners change and modes evolve, and “Timothy’s on the Bayswater Road” becomes a nest of the unbelievable in all except essentials; we shall not look upon its like again, nor perhaps on such a one as James or Old Jolyon. And yet the figures of Insurance Societies and the utterances of Judges reassure us daily that our earthly paradise is still a rich preserve, where the wild raiders, Beauty and Passion, come stealing in, filching security from beneath our noses. As surely as a dog will bark at a brass band, so will the essential Soames in human nature ever rise up uneasily against the dissolution which hovers round the folds of ownership.
text: Unable to write to output stream.
[root@master20 badou]#
[root@master20 spark_workstation]# find ./
./
./project
./target
./build.sbt
./lib
./lib/spark-assembly-1.6.0-hadoop2.6.0.jar
./src
./src/main
./src/main/scala
./src/main/scala/spark
./src/main/scala/spark/example
./src/main/scala/spark/example/WordCount.scala
[root@master20 spark_workstation]# cd ./src/main/scala/spark/example
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 用spark实现单词统计
*/
object SparkWordCount {
def main(args: Array[String]): Unit = {
/**
* 1.创建sparkConf对象,并设置App名称
* 这个conf就是之前学习的MapReduce中的conf的配置
* 通过这个conf对集群中的aprk-env.sh文件进行修改
* setAppName设置集群的名字,不设置默认即是所产生的一个名字
* setMaster设置运行模式,不写默认是提交到集群
* 本地:
* setMaster("local[2]")
* setMaster("local["使用多少个core"]") 设置本地模式
* core 值不是是核心,可以当做有多少个线程数,什么都不写或者写 * ,
* 那么就相当于系统中有多少个空闲的线程就使用多少个线程
*/
val conf = new SparkConf().setAppName("SparkWordCount").setMaster("local")
//2.创建SparkContext,提交sparkApp的人口
val sc = new SparkContext(conf)
/**
* sc所调用的方法叫做算子,算子有两种:
* transformation[只能计算没有结果] 和 action(触发得到结果)
* 什么是RDD,transformation,action
* RDD--通用数据结果集,想存储数据的方式---集合,数组
* 本身不存数据,但是可以把结果集放在那里
*/
//3.获取HDFS上的数据
val lines: RDD[String] = sc.textFile("/The_Man_of_Property.txt")
//4.将数据进行切分,并压平
val words: RDD[String] = lines.flatMap(_.split(" "))
//5.遍历当前数据组成二元组(key,1)
val tuples: RDD[(String,Int)] = words.map((_,1))
//6.进行聚合操作,相同key的value进行相加
//hello,1 hello,1
val sumed: RDD[(String,Int)] = tuples.reduceByKey(_+_,1)
//7.可以对数据进行排序操作,有默认参数true,降序false 就可以
val sorted: RDD[(String,Int)] = sumed.sortBy(_._2,false)
//8.将数据存储到HDFS上
val unit: Unit = sorted.saveAsTextFile("/output/spark")
//9.回收资源停止sc,结束任务
sc.stop()
}
}
[root@master20 spark_workstation]# pwd
/home/badou/datawhale/bigdata/datawhale_spark/spark_workstation
[root@master20 spark_workstation]# vim build.sbt
1 name := "WordCount"-
2 version := "1.6.0"--
3 scalaVersion := "2.11.4"
~
build.sbt 3,1 All
"build.sbt" 3L, 67C
[root@master20 spark_workstation]# sbt compile # 编译(只需要执行一次)
...
[success] Total time: 2 s, completed Aug 4, 2019 10:01:30 PM
[root@master20 example]#
[root@master20 spark_workstation]# sbt package # 相当于对此目录下所有代码进行打成jar包
[root@master20 spark_workstation]# sbt package
.....
[success] Total time: 0 s, completed Aug 4, 2019 10:38:09 PM
[root@master20 spark_workstation]#
# 生成jar包的位置
[root@master20 scala-2.11]# ls
wordcount_2.11-1.6.0.jar
[root@master20 scala-2.11]# pwd
/home/badou/datawhale/bigdata/datawhale_spark/spark_workstation/target/scala-2.11
[root@master20 spark_workstation]# pwd
/home/badou/datawhale/bigdata/datawhale_spark/spark_workstation
[root@master20 spark_workstation]# vim run_wordcount.sh
1 #!/usr/bin/env bash
2
3 hadoop fs -rmr /output/spark
4 /usr/local/src/spark-1.6.0-bin-hadoop2.6/bin/spark-submit --master spark://master:7077
\
5 #/usr/local/src/spark-1.6.0-bin-hadoop2.6/bin/spark-submit --master yarn-cluster \
6 --num-executors 2 \
7 --executor-memory '512m' \
8 --executor-cores 1 \
9 --class spark.example.WordCount ./target/scala-2.11/wordcount_2.11-1.6.0.jar \
10 hdfs://master20:9000/The_Man_of_Property.txt \
11 hdfs://master20:9000/output/spark
12 -
~
~
~
~
run_wordcount.sh 5,1 All
"run_wordcount.sh" 12L, 476C
chmod u+x file.sh 就表示对当前目录下的file.sh文件的所有者增加可执行权限。
[root@master20 spark_workstation]# chmod u+x run_wordcount.sh
以下来源与网络,仅供学习,参考
计算出movielen数据集中,平均评分最高的五个电影。
package com.bj.scalacode
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
/**
* 平均评分最高的10部电影
*/
object RDD_Movie_Users_Analyzer2 {
def main(args: Array[String]): Unit = {
var dataPath="F:\\baidu\\ml-1m"
//配置SparkConf,这里指本地运行,并把程序的名字设置为RDD_Movie_Users_Analyzer2
val conf=new SparkConf().setMaster("local[*]").setAppName("RDD_Movie_Users_Analyzer2")
//Spark2.0 引入SparkSession 封装了SparkContext 和SQLContext ,并且会在
//builder 的getOrCreate 方法中判断是否有符合要求的SparkSession 存在,有则使用,没有则进行创建
val spark=SparkSession.builder().config(conf).getOrCreate()
//获取SparkSession 的SparkContext
val sc=spark.sparkContext
//把Spark 程序运行时的日志设置为warn 级别,以方便查看运行结果
sc.setLogLevel("warn")
//把用到的数据加栽进来转换为RDD ,此时使用sc.textFile 并不会读取文件,而是标记了有这个操作,遇到Action 级别算子时才会真正去读取文件
val usersRDD=sc.textFile(dataPath+"/users.dat")
val moviesRDD=sc.textFile(dataPath+"/movies.dat")
val ratingsRDD=sc.textFile(dataPath+"/ratings.dat")
//具体的数据处理业务逻辑
//打印出所有电影中评分最高的前10 个电影名和平均评分
println("所有电影中评分最高(口碑最好)的前10个电影名和平均评分:")
//第一步:
//,从moviesRDD 中取出MovieID 和Name,如果后面的代码重复使用这些数据,则可以把它们缓存起来。
// 首先把使用map 算子上面的RDD 中的每一个元素(即文件中的每一行)以"::" 为分隔符进行拆分,
// 然后再使用map算子从拆分后得到的数组中取出需要用到的元素,并把得到的RDD 缓存起来。
//取出MovieID 和Name
val movieinfo = moviesRDD.map(x=>(x.split("::"))).map(x=>(x(0),x(1))).cache()
//从ratingsRDD中取出UserID,MovieID 和rating
val ratings = ratingsRDD.map(_.split("::")).map(x=>(x(0),x(1),x(2),x(3))).cache()
//第二步:
//从ratings 的数据中使用map 算子获取到形如(movieID,(rating,1)格式的RDD,
//然后使用reduceByKey 把每个电影的总评分以及点评人数算出来。
//ratings.map(x=>(x._1,x._2,x._3,x._4)).take(10).foreach(println)//(1,1193,5,978300760)
//ratings.map(x=>(x._2,(x._3,1))).take(10).foreach(println)//(1193,(5,1))
//此时得到的RDD 格式为(movieID,(Sum(ratings ),Count(ratings)))(1380,(2923.0,817))
val moviesAndRatings = ratings.map(x => (x._2, (x._3.toDouble, 1)))
.reduceByKey((x, y) => (x._1 + y._1, x._2 + y._2))//(2828,(255.0,121))
//第三步:得到格式为(movieID,(Sum(ratings ),Count(ratings))),
// 把每个电影的Sum(ratings)和 Count(ratings)相除,得到包含了电影ID 和平均评分的RDD:
val avgRatings = moviesAndRatings.map(x=>(x._1,x._2._1.toDouble/x._2._2))
// avgRatings.foreach(println)//得到包含了电影ID 和平均评分的RDD :(2834,3.5555555555555554)
//第四步:把avgRatings 与movielnfo 通过关键字key(movieID)连接到一起,得到形如(movieID,(MovieName,AvgRating)) 的RDD ,
// 然后格式化为( AvgRating,MovieName ),并按照key (也就是平均评分)降序排列,最终取出前10 个并打印出来。
avgRatings.join(movieinfo).map(item=>(item._2._1,item._2._2))
.sortByKey(false).take(10).foreach(record=>println(record._2+"平均评分为:"+record._1))
// avgRatings.join(movieinfo).map(item=>(item._2._1,item._2._2)).take(1).foreach(println)
// //(2.1074380165289255,Dudley Do-Right (1999))
// println("++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++")
// avgRatings.join(movieinfo).map(item=>(item._1,item._2,item._2._2,item._2._1)).take(1).foreach(println)
// // (2828,(2.1074380165289255,Dudley Do-Right (1999)),Dudley Do-Right (1999),2.1074380165289255)
// println("@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@")
//
// avgRatings.take(1).foreach(println)
// //(2828,2.1074380165289255)
// println("#################################################################################")
// movieinfo.take(1).foreach(println)
//(1,Toy Story (1995))
//最后关闭SparkSession
sc.stop()
}
}
所有电影中评分最高(口碑最好)的前10个电影名和平均评分:
Schlafes Bruder (Brother of Sleep) (1995)平均评分为:5.0
Gate of Heavenly Peace, The (1995)平均评分为:5.0
Lured (1947)平均评分为:5.0
Bittersweet Motel (2000)平均评分为:5.0
Follow the Bitch (1998)平均评分为:5.0
Song of Freedom (1936)平均评分为:5.0
One Little Indian (1973)平均评分为:5.0
Baby, The (1973)平均评分为:5.0
Smashing Time (1967)平均评分为:5.0
Ulysses (Ulisse) (1954)平均评分为:5.0
计算出movielen中,每个用户最喜欢的前5部电影
https://www.cnblogs.com/muchen/p/6882465.html
第三篇:一个Spark推荐系统引擎的实现
Spark取TopN问题
https://blog.csdn.net/OiteBody/article/details/82467264
Spark Scala 分组排序取TopN
https://blog.csdn.net/leen0304/article/details/78278089
使用surprise框架为Movieslen数据集中的每个user推荐Top-N个item
https://blog.csdn.net/u014680432/article/details/83387428
求TopN思路
https://blog.csdn.net/qq_39839745/article/details/86610647
https://www.cnblogs.com/muchen/p/6881823.html
第一篇:使用Spark探索经典数据集MovieLens
#导入相关的库文件
import os
from surprise import Dataset
from surprise import Reader
from surprise import SVD
from surprise import accuracy
from surprise.model_selection import train_test_split
from surprise import evaluate, print_perf
##读取数据
#指定文件的路径
file_path = os.path.expanduser('ml-100k/u.data')
#告诉文本阅读器,文本的格式是什么样子的
reader = Reader(line_format='user item rating timestamp', sep='\t')
#加载数据
data = Dataset.load_from_file(file_path, reader=reader)
# testset占比25%.
#trainset, testset = train_test_split(data, test_size=.25)
trainset = data.build_full_trainset()
#这里使用SVD算法,也可以使用其他的算法
algo = SVD()
# 在trainset上进行模型的训练, 在testset进行预测
algo.fit(trainset)
#进行预测
testset = trainset.build_anti_testset() #这里的testset是trainset中 rui为0的(user, item, 0)
predictions = algo.test(testset)
# Then compute RMSE
accuracy.rmse(predictions)
RMSE: 0.6043
0.6042835704959628
from collections import defaultdict #defaultdict是一个字典,当key不存在时,会返回默认值
#从一个prediction集合中返回每个 user Top-N推荐
def get_top_n(predictions, n = 10):
'''从一个prediction集合中返回每个 user Top-N推荐
Args:
predictions(list of Prediction objects): The list of predictions, as
returned by the test method of an algorithm.
n(int): The number of recommendation to output for each user. Default
is 10.
Returns:
A dict where keys are user (raw) ids and values are lists of tuples:
[(raw item id, rating estimation), ...] of size n.
'''
#首先将prediction映射到每个user上
top_n = defaultdict(list)
for uid, iid, true_r, est, _ in predictions:
top_n[uid].append((iid, est))
#再对每个user的item按照评分进行排序
for uid, user_ratings in top_n.items():
user_ratings.sort(key = lambda x : x[1], reverse = True)
top_n[uid] = user_ratings[:n] #取前n个
return top_n
get_top_n(predictions, n = 10)
学会阅读Spark源码,整理Spark任务submit过程
https://blog.csdn.net/do_yourself_go_on/article/details/75005204
Spark源码解析之任务提交(spark-submit)篇
https://blog.csdn.net/qq_16495805/article/details/87982681
Spark2.2源码分析:Spark-Submit提交任务
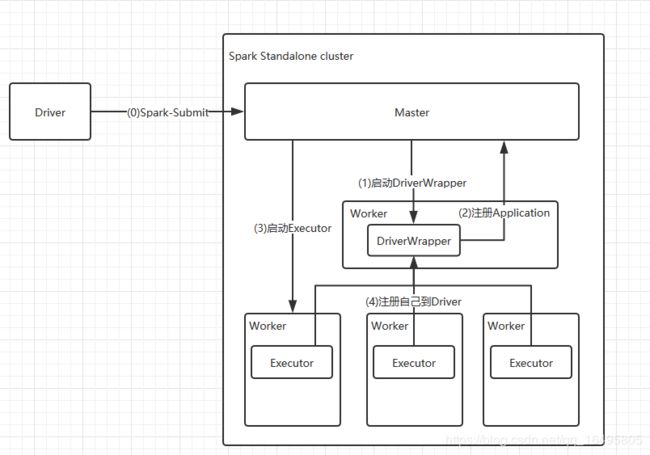
概述整体步骤
1.先执行spark-submit脚本,准备参数,选择集群管理器
2.启动driver,注册application,启动executor,划分任务,分发任务
3.返回(或则落地)计算结果,spark任务计算完成
参考资料: 远程连接jupyter
【没有jblas库解决办法】 下载jblas包 :https://pan.baidu.com/s/1o8w6Wem
运行spark-shell时添加jar:spark-shell --jars [jblas path] /jblas-1.2.4.jar
【Task6】Hive原理及其使用
- 安装MySQL、Hive
- 采用MySQL作为hive元数据库
- Hive与传统RDBMS的区别
- HIve原理及架构图
- HQL的基本操作(Hive中的SQL)
- Hive内部表/外部表/分区
参考资料:
https://www.shiyanlou.com/courses/running
MySQL安装
采用MySQL作为hive元数据库
Hive on Spark环境部署
https://blog.csdn.net/qq_26937525/article/details/54136317
https://docs.azure.cn/zh-cn/hdinsight/hadoop/python-udf-hdinsight
安装MySQL、Hive
https://blog.csdn.net/z13615480737/article/details/78906598
CentOS 7 下使用yum安装MySQL5.7.20 最简单 图文详解
- 采用MySQL作为hive元数据库
- Hive与传统RDBMS的区别
- HIve原理及架构图
- HQL的基本操作(Hive中的SQL)
- Hive内部表/外部表/分区
参考资料:
https://www.shiyanlou.com/courses/running
MySQL安装
采用MySQL作为hive元数据库
Hive on Spark环境部署
https://blog.csdn.net/qq_26937525/article/details/54136317
https://docs.azure.cn/zh-cn/hdinsight/hadoop/python-udf-hdinsight
【Task7】实践
- 计算每个content的CTR。
数据集下载:链接:https://pan.baidu.com/s/1YDvBWp35xKLg5zsysEjDGA 提取码:rpgs
-
【选做】 使用Spark实现ALS矩阵分解算法 movielen
数据集:http://files.grouplens.org/datasets/movielens/ml-100k.zip
基于ALS矩阵分解算法的Spark推荐引擎实现
-
使用Spark分析Amazon DataSet(实现 Spark LR、Spark TFIDF)
数据集:http://jmcauley.ucsd.edu/data/amazon/
preprocess
Spark LR
Spark TFIDF
【截止时间】任务时间是3天**(最终以石墨文档的记录为准)**
1)2019.8.10 周六 22:00 前提交博客/Github链接(描述:任务、遇到的问题、实现代码和参考资料)
2)2019.8.11中午12:00 前点评完毕
【考核方式】
1)链接发到群里同时@点评人 + 在群里对下一号学员进行点评
2)并在下面贴上自己链接、对他人的点评
**【学员打卡】**参考作业分享http://t.cn/EUBStT7xxx点评优点:xxx号排版简单明了缺点:如果能将模型结果贴出来,做一些简单的分析就更完美了。疑问:ALS矩阵分解算法原理是? -----------------点评也是一门学问,认真对待每一次队友给你点评的机会,加油!!!
计算每个content的CTR。
CTR点击率预估干货分享
https://blog.csdn.net/bitcarmanlee/article/details/52138970
CTR预估算法小结
https://blog.csdn.net/bitcarmanlee/article/details/52138713
1.指标
广告点击率预估是程序化广告交易框架的非常重要的组件,点击率预估主要有两个层次的指标:
1.排序指标。排序指标是最基本的指标,它决定了我们有没有能力把最合适的广告找出来去呈现给最合适的用户。这个是变现的基础,从技术上,我们用AUC来度量。
2.数值指标。数值指标是进一步的指标,是竞价环节进一步优化的基础,一般DSP比较看中这个指标。如果我们对CTR普遍低估,我们出价会相对保守,从而使得预算花不出去或是花得太慢;如果我们对CTR普遍高估,我们的出价会相对激进,从而导致CPC太高。从技术上,我们有Facebook的NE(Normalized Entropy)还可以用OE(Observation Over Expectation)。
2.框架
工业界用得比较多的是基于LR的点击率预估策略,我觉得这其中一个重要的原因是可解释性,当出现bad case时越简单的模型越好debug,越可解释,也就越可以有针对性地对这种bad case做改善。但虽然如此,我见到的做广告的算法工程师,很少有利用LR的这种好处做模型改善的,遗憾….. 最近DNN很热,百度宣布DNN做CTR预估相比LR产生了20%的benefit,我不知道比较的benchmark,但就机理上来讲如果说DNN比原本传统的人工feature engineering的LR高20%,我一点也不奇怪。但如果跟现在增加了FM和GBDT的自动高阶特征生成的LR相比,我觉得DNN未必有什么优势。毕竟看透了,DNN用线性组合+非线性函数(tanh/sigmoid etc.)来做高阶特征生成,GBDT + FM用树和FM来做高阶特征生成,最后一层都是非线性变换。从场景上来讲,可能在拟生物的应用上(如视、听觉)上DNN这种高阶特征生成更好,在广告这种情境下,我更倾向于GBDT + FM的方法。
整个CTR预估模块的框架,包含了exploit/explore的逻辑。
3.计算公式为
CTR=点击量/展示量,即 Click / Show content。
CTR:点击率,Click-Through-Rate (点击通过比率)
使用Spark计算PV、UV
https://blog.csdn.net/laozhaokun/article/details/43196425
【选做】 使用Spark实现ALS矩阵分解算法 movielen
https://blog.csdn.net/u011239443/article/details/51752904
深入理解Spark ML:基于ALS矩阵分解的协同过滤算法与源码分析
https://blog.csdn.net/wzgl__wh/article/details/80369907
基于Spark ALS算法的个性化推荐
import os
import sys
#下面这些目录都是你自己机器的Spark安装目录和Java安装目录
os.environ['SPARK_HOME'] = "C:/Tools/spark-1.6.1-bin-hadoop2.6/"
sys.path.append("C:/Tools/spark-1.6.1-bin-hadoop2.6/bin")
sys.path.append("C:/Tools/spark-1.6.1-bin-hadoop2.6/python")
sys.path.append("C:/Tools/spark-1.6.1-bin-hadoop2.6/python/pyspark")
sys.path.append("C:/Tools/spark-1.6.1-bin-hadoop2.6/python/lib")
sys.path.append("C:/Tools/spark-1.6.1-bin-hadoop2.6/python/lib/pyspark.zip")
sys.path.append("C:/Tools/spark-1.6.1-bin-hadoop2.6/python/lib/py4j-0.9-src.zip")
sys.path.append("C:/Program Files (x86)/Java/jdk1.8.0_102")
from pyspark import SparkContext
from pyspark import SparkConf
sc = SparkContext("local", "testing")
print sc
#下面目录要用解压后u.data所在的目录
user_data = sc.textFile("C:/Temp/ml-100k/u.data")
user_data.first()
rates = user_data.map(lambda x: x.split("\t")[0:3])
print rates.first()
from pyspark.mllib.recommendation import Rating
rates_data = rates.map(lambda x: Rating(int(x[0]),int(x[1]),int(x[2])))
print rates_data.first()
from pyspark.mllib.recommendation import ALS
from pyspark.mllib.recommendation import MatrixFactorizationModel
sc.setCheckpointDir('checkpoint/')
ALS.checkpointInterval = 2
model = ALS.train(ratings=rates_data, rank=20, iterations=5, lambda_=0.02)
print model.predict(38,20)
#现在我们来预测了用户38最喜欢的10个物品,代码如下:
print model.recommendProducts(38,10)
# 接着我们来预测下物品20可能最值得推荐的10个用户,代码如下:
print model.recommendUsers(20,10)
# 现在我们来看看每个用户最值得推荐的三个物品,代码如下:
print model.recommendProductsForUsers(3).collect()
# 而每个物品最值得被推荐的三个用户,代码如下:
print model.recommendUsersForProducts(3).collect()
使用Spark分析Amazon DataSet(实现 Spark LR、Spark TFIDF)
数据集:http://jmcauley.ucsd.edu/data/amazon/
preprocess
Spark LR
#主要代码是最速下降算法的主要实现部分
def sigmoid(xi: Array[Int], w: Array[Double]):Double = {
var sum = 0.0
xi.foreach{i => sum += w(i)}
if(sum > 35.0)
sum = 35.0
if(sum < -35.0)
sum = -35.0
1.0 / (1.0 + math.exp(-sum))
}
/*迭代求权重*/
for(i <- 0 until iter){
var h = input.map{ case (label,indices) =>
(label,indices,sigmoid(indices,weight))
}
val loss = h.map{ case (label,indices,hh) =>
label*math.log(hh)+(1.0-label)*math.log(1.0-hh)
}
val sum = loss.reduce(_+_)
val num = loss.count
//loss.collect.foreach(ll => logger.error(ll))
logger.error("loss rate: ")
logger.error(sum)
logger.error(num)
logger.error(-sum/num)
//gradient
h.map{ case (label,indices,hh) =>
(indices,label - hh)
}.map{case (indices,e) => indices.map{f => (f,alpha*e)}.toMap
}.reduce{case (map1,map2) => map1 ++ map2.map{ case (k,v) => (k,v + map1.getOrElse(k,0.0)) }}
.foreach{case(k,v)=>weight(k) += v}
}
weight.foreach{w => logger.error(w)}
weight
}
def splitSamples(input:RDD[(Double, Array[Int])], splitNum:Int=10, iterNum:Int=2){
val logger = Logger.getRootLogger()
var splitWeight = new Array[Map[Int,Double]](splitNum)
var ww = new Array[Double](1861181)
for(j <- 0 until iterNum){
//calculate loss
val loss = input.map{case (label,indices) => (label,indices,sigmoid(indices,ww))}
.map{case (label,indices,hh) => label*math.log(hh)+(1.0-label)*math.log(1.0-hh)}
val sum = loss.reduce(_+_)
val num = loss.count
logger.error("loss rate: ")
logger.error(sum)
logger.error(num)
logger.error(-sum/num)
for(i <- 0 until splitNum){
var j = 0
train(input.map{case (label,indices) =>
j += 1
(j,label,indices)
}.filter{case(num,label,indices) => num % splitNum == i}
.map{case(num,label,indices) => (label,indices)},ww).foreach{case(k,v)=>ww(k) += v/splitNum}
}
}
}
def sigmoid(xi: Array[Int], w: Array[Double]):Double = {
var sum = 0.0
xi.foreach{i => sum += w(i)}
if(sum > 35.0)
sum = 35.0
if(sum < -35.0)
sum = -35.0
1.0 / (1.0 + math.exp(-sum))
}
def train(input:RDD[(Double, Array[Int])], weight:Array[Double], alpha:Double=0.001):Map[Int,Double]={
val rst = input.map{case (label,indices) =>
indices.map{ arr =>
weight(arr) += alpha*(label-sigmoid(indices,weight))
(arr,weight(arr))
}.toMap
}.reduce(_++_)
rst
}
}
Spark TFIDF
https://www.cnblogs.com/soyo/p/7725404.html
Spark 机器学习 —TF-IDF (https://www.cnblogs.com/soyo/p/7725404.html)
package Spark_MLlib
import org.apache.spark.ml.feature.{HashingTF, IDF, Tokenizer}
import org.apache.spark.sql.SparkSession
/**
* TF-IDF
*/
object 特征抽取 {
val spark=SparkSession.builder().master("local").appName("TF-IDF").getOrCreate()
import spark.implicits._
def main(args: Array[String]): Unit = {
val soureceData= spark.createDataFrame(Seq(
(0,"soyo spark like spark hadoop spark and spark like spark"),
(1,"i wish i can like java i"),
(2,"but i dont know how to soyo"),
(3,"spark is good spark tool")
)).toDF("label","sentence")
//进行分词
val tokenizer=new Tokenizer().setInputCol("sentence").setOutputCol("words")
val wordsData=tokenizer.transform(soureceData)
wordsData.show(false) //表示不省略,打印字符串的所有单词
val hashTF=new HashingTF().setInputCol("words").setOutputCol("rawsFeatures").setNumFeatures(1000)
//生成特征向量
val featuredData=hashTF.transform(wordsData)
featuredData.show(false)
val idf=new IDF().setInputCol("rawsFeatures").setOutputCol("features")
val idfModel=idf.fit(featuredData)
val result=idfModel.transform(featuredData)
result.show(false)
result.select("label","features").show(false)
}
}
END参考
http://dblab.xmu.edu.cn/
http://blog.sina.com.cn/s/blog_17ab314080102xdtm.html