title: python Scrapy爬取小猪短租
date: 2018-04-07 17:58:48
tags: 随笔
个人博客Danniel's Blog,不定时更新,欢迎指正!
找工作之余,要考虑租房问题,天天刷房源,所有才有了这个想法爬几个租房的网站吧。
先来写个小猪短租的吧,废话不多说直接撸代码。
一 创建项目 tenement
scrapy startproject tenement
New Scrapy project 'tenement', using template directory 'd:\\anaconda3\\lib\\site-packages\\scrapy\\templates\\project', created in:
C:\Users\Dylan\Desktop\tenement
You can start your first spider with:
cd tenement
scrapy genspider example example.com
在scrapy框架中,如果想多个批量运行爬虫文件,常见有两种方法:
- 使用CrawProcess实现
- 使用修改craw源码+自定义命令的方式实现
(* ̄︶ ̄)在这里我们就使用常用的方法:
进入该爬虫项目所在目录,并且在该项目中实时创建爬虫文件(目的为了创建多个爬虫文件,以供待运行),下面继续码字吧
C:\Users\Dylan\Desktop>cd tenement
C:\Users\Dylan\Desktop\tenement>scrapy genspider -t basic Short_rent_for_piglets xiaozhu.com
Created spider 'Short_rent_for_piglets' using template 'basic' in module:
tenement.spiders.Short_rent_for_piglets
二 找出想要的url(发送请求,获取响应)
上个小猪短租网址吧,快速浏览第1页,第2页,第3页....通过chrome开发者工具按下ctrl+shift+I和F5(或F12+F5) 很快就找到了network(网络)里的headers(消息头),看到Request URL:(http://sh.xiaozhu.com/search-duanzufang-p{}-0/ {})内就是数字所对应的页码数,仔细看了下网页版的好像就13页左右,没有APP的多,今天我就先写个网页版的吧.
在这里记录下下次有机会去爬app看看,能加载多少房源。
TODO 记得爬小猪短租APP
写parse函数 利用Xpath或者Selector提取对应的数据
先找到所有信息
infos=response.xpath('//div[@id="page_list"]/ul/li')
标题 title =li.xpath('./div[2]/div/a/span/text()').extract_first()
价格 price =li.xpath('./div[2]/span[1]/i/text()').extract_first()
描述 desc =li.xpath('./div[2]/div/em/text()').extract_first().strip()
详情页comment_url=li.xpath('./a/@href').extract_first()
图片 images=li.xpath('./a/img/@lazy_src').extract_first()
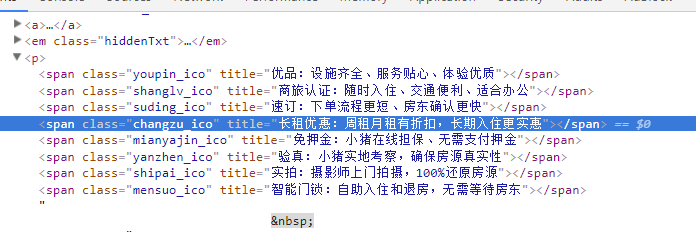
提取上面的对应的ico的title是不是很简单?直接能用xpath取出来,哈哈,结果跑起程序后肯定一脸懵,为啥我取出来的数据类似下面举例的这B玩意?
shipai':

其实是忘记写了xpath().extract(),BLABLA一大堆,感觉今天咋这么多"特效",废话不多说直接上代码
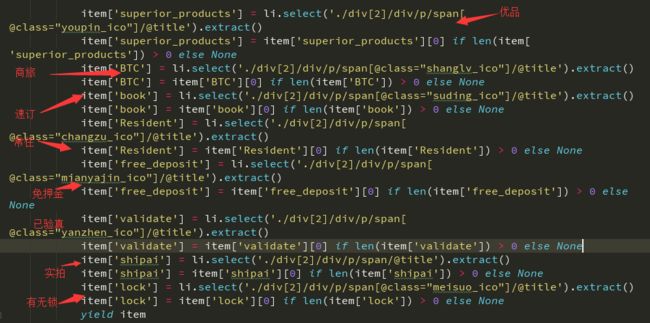
在这顺便说下extract()与extract_first()的区别
在scrapy.Selector选择器中提取字符串:
- extract()返回一个包含有字符串数据的列表
- extract_first()返回列表中的第一个字符串
DEBUG调试
**出现Filtered offsite request to **
官方对这个的解释,是你要request的地址和allow_domain里面的冲突,从而被过滤掉。可以停用过滤功能。
yield Request(url, callback=self.parse_item, dont_filter=True)
如果出现Unhandled error in Deferred:
请检验python是否没装pywin32模块或者pywin32的64位模块(https://pypi.python.org/pypi/pywin32)
或:
作为程序运行错误时,提示作用
因为我在程序中设定了自定义配置,故会在log日志里存储对应时间内的异常错误代码提示
爬取数据过程中要与反爬技术常打交道,该程序只用了常规的IP代理,UA随机请求头两中间件。
先从编写代理中间件开始吧
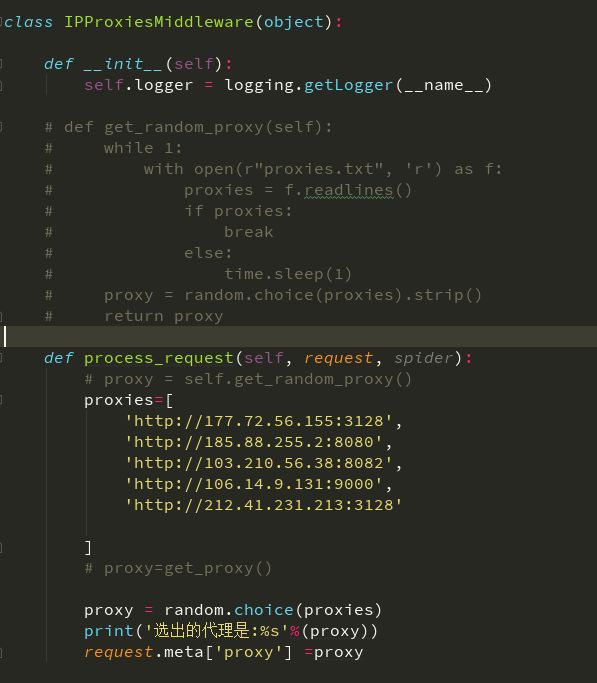
顺便说下免费代理与付费代理的使用:
- 手动更新ip pool,如上图所示从免费代理网站爬取的ip写入proxies的列表内,通过random模块的方法随机一个IP作为代理
- 自动更新ip pool, 顾名思义就是将爬取到的代理通过创建IP pool池,使用Flask+Redis维护动态代理池,定时CRUD,获取最新、有效的IP地址,用于IP代理. 参考项目:
大神 ps:惭愧啊! 自学的时候常用它,竟还不知道尊姓大名,对不住!
七夜大神开源项目
大神 - 那就是付费代理啦
这里整个阿布云代理的代码,作为示范:
proxyServer = "http://http-dyn.abuyun.com:9020" #阿布云服务
proxyUser = "............."
proxyPass = "................."
proxyAuth = "Basic " + str(base64.b64encode((proxyUser + ":" + proxyPass).encode('utf-8')), 'utf-8')
def process_request(self, request, spider):
request.meta["proxy"] = proxyServer
request.headers["Proxy-Authorization"] = proxyAuth
'''
如果有用户名和密码建议使用base64编码一下
proxy_user_pass="USERNAME:PASSWORD" encode_user_pass=base64.encodestring(proxy_user_pass)
request.headers['Proxy-Authorization']='Basic'+encode_user_pass
'''
- Python爬虫还在找代理你就OUT了!Crawlera神器还需要找代理IP?
scrapy_crawlera(https://scrapinghub.com/crawlera) 免费兼收费,由于免费代理十混九瞎折腾老半天没出几个好用的,这种代理来的不太算容易吧!还要有验证的麻烦事。那我们可以利用Crawlera轻松解决,岂不快哉? 是不是感觉比以往的那种寻找出的代理池棒多了?
安装 方法 pip install crawlera
官方文档
我也还在学习中,就小举下使用方法吧
'tenement.middlewares.TenementSpiderMiddleware': 543,
# 'tenement.middlewares.IPProxiesMiddleware': 300,
'tenement.middlewares.RandomUserAgent': 400,
# 使用scrapy_crawlera 就可以将之前设置过的代理ip中间件注释掉了,加入了crawlera的代理
'scrapy_crawlera.CrawleraMiddleware': 600
},
官方还提示了:
为了使crawlera生效,需求添加你创建的api信息(如果填写了API key的话,pass可以设置为空)
'CRAWLERA_ENABLED': True,
'CRAWLERA_USER'=""
'CRAWLERA_PASS': '',
其他就去crawlera官方文档学习吧(嘿嘿自个学习去,我也还没看完,不能在这误人子弟)
在scrapy中的middlewares中写入代理中间件
class RandomUserAgent(object):
def process_request(self, request, spider):
useragent = random.choice(USER_AGENTS)
request.headers['User-Agent'] = useragent
随机头User-Agent 将收集着的全放出
USER_AGENTS = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) "
"Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) "
"Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) "
"Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) "
"Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) "
"Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) "
"Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) "
"Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) "
"Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) "
"Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) "
"Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) "
"Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) "
"Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) "
"Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) "
"Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) "
"Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) "
"Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) "
"Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) "
"Chrome/19.0.1055.1 Safari/535.24"
]
USER-AGENT_MOBILE = ["Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/59.0.3071.115 Mobile Safari/537.36",
"Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 like Mac OS X) AppleWebKit/601.1.46 "
"(KHTML, like Gecko) Version/9.0 Mobile/13B143 Safari/601.1",
"Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 like Mac OS X) AppleWebKit/601.1.46 (KHTML, "
"like Gecko) Version/9.0 Mobile/13B143 Safari/601.1",
"Mozilla/5.0 (Linux; Android 5.0; SM-G900P Build/LRX21T) AppleWebKit/537.36 (KHTML, "
"like Gecko) Chrome/62.0.3202.75 Mobile Safari/537.36",
"Mozilla/5.0 (iPad; CPU OS 9_1 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) "
"Version/9.0 Mobile/13B143 Safari/601.1"]
说完中间件了,那就来一波scrapy的settings文件骚操作吧。Scrapy既然设置允许您自定义所有Scrapy组件的行为,包括核心,扩展,管道和爬虫本身。那肯定有它的理由,学的浅就不深究了,还是实打实上图吧。
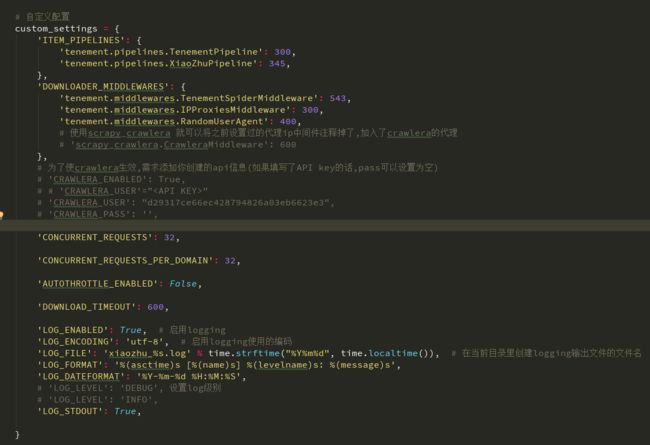
尴尬!篇幅太长了,在这里我就省去日志编写、保存数据这两步,保存方法不唯一,想怎么保存就怎么来
scrapy crawl spider_name -o xxx.json/xxx.csv 可直接保存对应的文件哦
最后附上我的源码
谢谢您的阅读,有不足之处或代码优化方面欢迎指正!