从输入URL到页面成功展示到浏览器的过程?
主干流程梳理:
知识体系中,最重要的是骨架,脉络。有了骨架后,才方便填充细节。所以,先梳理下主干流程:
- 从浏览器接收到url到开启网络请求线程(这一部分涉及浏览器的机制以及进程与线程之间的关系)
- 从开启网络线程到发出一个完整的http请求(这一部分涉及到dns查询,tcp/ip请求,五层因特网协议栈等知识)
- 从服务器接收到请求到对应后台接收到请求(这一部分可能涉及到负载均衡,安全拦截以及后台内部的处理等等)
- 后台和前台的http交互(这一部分包括http头部、响应码、报文结构、cookie,cookie优化,以及编码解码,如gzip压缩等)
- 单独拎出来的缓存问题,http的缓存(这部分包括http缓存头部,etag,catch-control等)
- 浏览器接收到http数据包后的解析流程(这部分包括dom树、css规则树、合并成render树,然后layout、painting渲染、复合图层合成、GPU绘制、外链资源处理、loaded和domcontentloaded等)
- CSS的可视化格式模型(元素的渲染规则,如css三大模型,BFC,IFC等概念)
- JS引擎解析过程(JS的解释阶段,预处理阶段,执行阶段生成执行上下文,VO,作用域链、回收机制等等)
- 其它(可以拓展不同的知识模块,如跨域,web安全,hybrid模式等等内容)
梳理出主干骨架,然后就需要往骨架上填充细节内容了。
1、从浏览器接收url到开启网络请求线程
1.1 多进程的浏览器
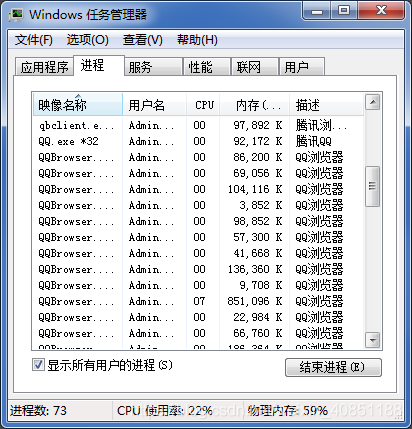
浏览器是多进程的,有一个主控进程,以及每一个tab页面都会新开一个进程(某些情况下多个tab会合并进程)进程可能包括主控进程,插件进程,GPU,tab页(浏览器内核)等等...主要有:
- Browser进程:浏览器的主进程(负责协调、主控),只有一个。
- 第三方插件进程:每种类型的插件对应一个进程,仅当使用该插件时才创建。
- GPU进程:最多一个,用于3D绘制。
- 浏览器渲染进程(内核(Renderer进程)):默认每个Tab页面一个进程,互不影响,控制页面渲染,脚本执行,事件处理等(有时候会优化,如多个空白tab会合并成一个进程)。
如下图,大多数名字QQ浏览器的进程都是我打开的一个个tab页面。如果你在浏览器新打开一个页面,浏览器就会多一个进程,反之减少一个。
1.2 多线程的浏览器内核进程(Renderer进程)
因为所有的浏览器内容展示都离不开浏览器内核进程,所以先从浏览器内核进程开始说起,随后穿插其他各大进程。每一个tab页面可以看作是浏览器内核进程,然后这个进程是多线程的,它有几大类子线程:
-
GUI线程
- 负责渲染浏览器界面,解析HTML,CSS,构建DOM树和RenderObject树,布局和绘制等。
- 当界面需要重绘(Repaint)或由于某种操作引发回流(reflow)时,该线程就会执行。
- 注意,GUI渲染线程与JS引擎线程是互斥的。当JS引擎执行时GUI线程会被挂起(相当于被冻结了),GUI更新会被保存在一个队列中等到JS引擎空闲时立即被执行。
-
事件触发线程
- 归属于浏览器而不是JS引擎,用来控制事件循环(可以理解,JS引擎自己都忙不过来,需要浏览器另开线程协助)。
- 当JS引擎执行代码块如setTimeOut时(也可来自浏览器内核的其他线程,如鼠标点击、AJAX异步请求等),会将对应任务添加到事件线程中
- 当对应的事件符合触发条件被触发时,该线程会把事件添加到待处理队列的队尾,等待JS引擎的处理。
- 注意,由于JS的单线程关系,所以这些待处理队列中的事件都得排队等待JS引擎处理(当JS引擎空闲时才会去执行)。
-
定时器线程
- 传说中的setInterval与setTimeout所在线程。
- 浏览器定时计数器并不是由JavaScript引擎计数的,(因为JavaScript引擎是单线程的, 如果处于阻塞线程状态就会影响记计时的准确)。
- 因此通过单独线程来计时并触发定时(计时完毕后,添加到事件队列中,等待JS引擎空闲后执行)。
- 注意,W3C在HTML标准中规定,规定要求setTimeout中低于4ms的时间间隔算为4ms。
-
JS引擎线程
- 也称为JS内核,负责处理Javascript脚本程序。(例如V8引擎)。
- JS引擎线程负责解析Javascript脚本,运行代码。
- JS引擎一直等待着任务队列中任务的到来,然后加以处理,一个Tab页(renderer进程)中无论什么时候都只有一个JS线程在运行JS程序。
- 同样注意,GUI渲染线程与JS引擎线程是互斥的,所以如果JS执行的时间过长,这样就会造成页面的渲染不连贯,导致页面渲染加载阻塞。
-
网络请求线程
- 在XMLHttpRequest在连接后是通过浏览器新开一个线程请求。
- 将检测到状态变更时,如果设置有回调函数,异步线程就产生状态变更事件,将这个回调再放入事件队列中。再由JavaScript引擎执行。

可以看到,里面的JS引擎是内核进程中的一个线程,这也是为什么常说JS引擎是单线程的。
1.3 Browser主进程和浏览器内核进程(Renderer进程)的通信过程
如果自己打开任务管理器,然后打开一个浏览器,就可以看到:任务管理器中出现了两个进程(一个是主控进程,一个则是打开Tab页的渲染进程),然后在这前提下,看下整个简化的过程:
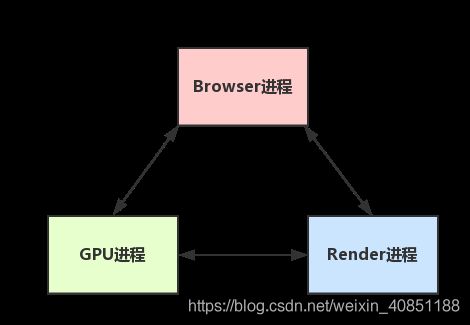
- Browser进程收到用户请求,首先需要获取页面内容(譬如通过网络下载资源),随后将该任务通过RendererHost接口传递给Render进程。
- Renderer进程的Renderer接口收到消息,简单解释后,交给GUI渲染线程,然后开始渲染。
- 渲染线程接收请求,加载网页并渲染网页,这其中可能需要Browser进程获取资源和需要GPU进程来帮助渲染。
- 当然可能会有JS线程操作DOM(这样可能会造成回流并重绘)。
- 最后Render进程将结果传递给Browser进程。
- Browser进程接收到结果并将结果绘制出来
这里绘一张简单的图:(很简化)
看完这一整套流程,应该对浏览器的运作有了一定理解了,这样有了知识架构的基础后,后续就方便往上填充内容。
1.4 浏览器内核进程(Renderer进程)的GUI线程的渲染流程
根据上文我们可以知道,当我们输入url然后回车后:
- 浏览器获取url,浏览器主进程接管,开一个下载线程。
- 然后进行 http请求(略去DNS查询,IP寻址等等操作),然后等待响应,获取内容。
- 随后将内容通过RendererHost接口转交给Renderer进程,GUI线程开始运行,浏览器渲染流程开始。
浏览器器内核的Render进程拿到内容后,渲染过程大概可以划分成以下几个步骤:
- 解析html建立dom树。
- 解析css构建render树(将CSS代码解析成树形的数据结构,然后结合DOM合并成render树)。
- 布局render树(Layout/reflow),负责各元素尺寸、位置的计算。
- 绘制render树(paint),绘制页面像素信息。
- 浏览器会将各层的信息发送给GPU,GPU会将各层合成(composite),显示在屏幕上。
具体过程如下图:

所有详细步骤都已经略去,渲染完毕后就是load事件了,之后就是自己的JS逻辑处理了.既然略去了一些详细的步骤,那么就提一些可能需要注意的细节把。
-
load事件与DOMContentLoaded事件的先后
- 当 DOMContentLoaded 事件触发时,仅当DOM加载完成,不包括样式表,图片。
- 当 onload 事件触发时,页面上所有的DOM,样式表,脚本,图片都已经加载完成了。
-
css加载是否会阻塞dom树渲染?
- css是由单独的下载线程异步下载的,所以css加载不会阻塞DOM树解析(异步加载时DOM照常构建)
- 但会阻塞render树渲染(渲染时需等css加载完毕,因为render树需要css信息)。
1.5 由GUI线程的渲染引出GPU进程中的普通图层和复合图层
根据上文我们可以知道了composite概念。可以简单的这样理解,浏览器渲染的图层一般包含两大类:普通图层以及复合图层。
首先,普通文档流内可以理解为一个复合图层(这里称为默认复合层,里面不管添加多少元素,其实都是在同一个复合图层中)。 其次,absolute布局(fixed也一样),虽然可以脱离普通文档流,但它仍然属于默认复合层。然后,可以通过硬件加速的方式,声明一个新的复合图层,它会单独分配资源(当然也会脱离普通文档流,这样一来,不管这个复合图层中怎么变化,也不会影响默认复合层里的回流重绘)。
因此,GPU中,各个复合图层是单独绘制的,所以互不影响,这也是为什么某些场景硬件加速效果一级棒。可以Chrome源码调试 -> More Tools -> Rendering -> Layer borders中看到,黄色的就是复合图层信息。
如何变成复合图层(硬件加速):
- 最常用的方式:translate3d、translateZ。
- opacity属性/过渡动画(需要动画执行的过程中才会创建合成层,动画没有开始或结束后元素还会回到之前的状态)。