Flask数据库模型及其增删改查
Flask-sqlalchemy
Sqlalchemy 是python开发的一个ORM(数据库映射)模块: 将python面向对象的类映射为数据库的表,通过映射关系来完成数据库的操作,降低数据库操作的难度和繁琐程度。类似的模块还有(peewee)。Flask将sqlalchemy进行封装,封装到自己的项目当中,sqlalchemy和flask-sqlalchemy的操作有一部分不同。
安装flask-sqlalchemy
pip install flask-sqlalchemy
连接数据库
import os
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
BASE_DIR = os.path.abspath(os.path.dirname(__file__))
#app.config返回类字典对象,里面用来存放当前app实例的配置
#配置数据连接的参数
# MySQL——》 mysql://username:password@hostname[:port]/database
# Sqlite(windows)——》 sqlite:///d:/python/python.sqlite
# Sqlite(linux)——》 sqlite:python/python.sqlite
# Pgsql——》 postgresql://username:password@hostname/database
app.config['SQLALCHEMY_DATABASE_URI']='sqlite:///'+os.path.join(BASE_DIR,'Demo.sqlite')
#请求结束后自动提交数据库修改
app.config['SQLALCHEMY_COMMIT_ON_TEARDOWN'] = True
#如果设置成 True (默认情况),Flask-SQLAlchemy将会追踪对象的修改并且发送信号。这需要额外的内存,如果不必要的可以禁用它。
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = True
models = SQLAlchemy(app) #关联sqlalchemy和flask应用
#学员
class Student(models.Model):
__tablename__ = 'student' #表名
id = models.Column(models.Integer,primary_key=True)
name = models.Column(models.String(),unique=True)
#成绩
class Grade(models.Model):
__tablename__ = 'grade' #表名
id = models.Column(models.Integer,primary_key=True)
name = models.Column(models.String(),unique=True)
#课程
class Course(models.Model):
__tablename__ = 'course' #表名
id = models.Column(models.Integer,primary_key=True)
name = models.Column(models.String(),unique=True)
#考勤
class WorkAttendance(models.Model):
__tablename__ = 'workattendance' #表名
id = models.Column(models.Integer,primary_key=True)
time = models.Column(models.DateTime(),unique=True)
#老师
class Teacher(models.Model):
__tablename__ = 'teacher' #表名
id = models.Column(models.Integer,primary_key=True)
name = models.Column(models.String(),unique=True)
# 关系搭建
#学生与课程
Student_Course = models.Table(
'student_course',
models.Column('id',primary_key=True,autoincrement=True),
models.Column('student_id',models.Integer,models.ForeignKey('student.id')),
models.Column('course_id',models.Integer,models.ForeignKey('course.id'))
)
models.create_all()
创建数据表
定义类型,【类下需要__tablename__来定义表的名称 】
字段类型
Integer # 整型
Float # 浮点型
String # 字符串类型
Time # 时间类型 时分秒
DateTime # 时间类型 年月日时分秒
Text # 文本
Integer # int 普通整数,一般是 32 位
SmallInteger # int 取值范围小的整数,一般是 16 位
Big Integer # int 或 long 不限制精度的整数
Float # float 浮点数
Numeric # decimal.Decimal 定点数
String # str 变长字符串
Text # str 变长字符串,对较长或不限长度的字符串做了优化
Unicode # unicode 变长 Unicode 字符串
Unicode # Text unicode 变长 Unicode 字符串,对较长或不限长度的字符串做了优化
Boolean # bool 布尔值
Date # datetime.date 日期
Time # datetime.time 时间
DateTime # datetime.datetime 日期和时间
Interval # datetime.timedelta 时间间隔
Enum # str 一组字符串
PickleType # 任何 Python 对象 自动使用 Pickle 序列化
LargeBinary # str 二进制文件
字段常用的参数
Primary_key #主键
Unique #不重复
Index #索引
Nullable #如果为True是可以为空
Default #默认值
Autoincrement #自增长
数据表字段与关系
一对一
在一个表里记录另一个表的字段
一对多
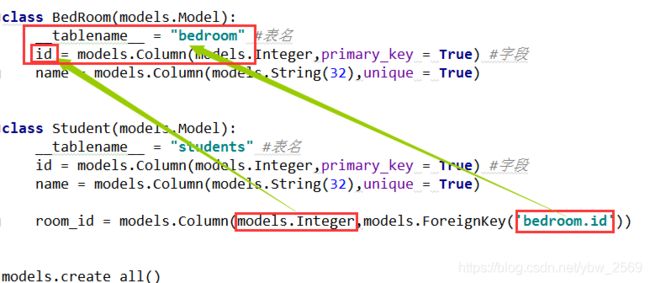
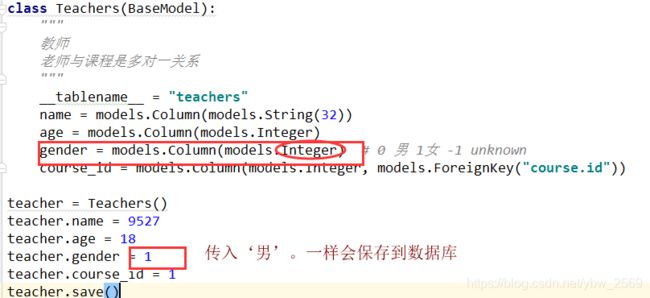
多对多

数据库操作
数据库数据插入流程
1,创建数据库操作实例:
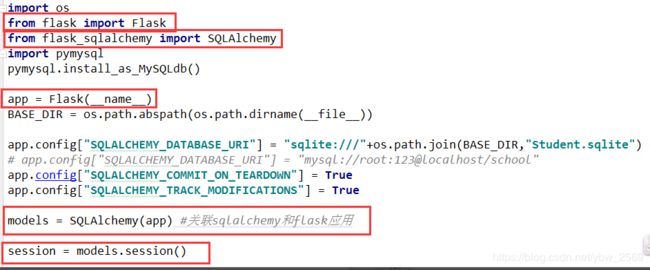
2,创建表实例,传入数据

数据库的增删改查
增
s = Students(name= '小明',age=28,gender='男')
session .add(s)
session.commit()
# 批量插入【添加的不通方式】
s = Students(name= '小刚',age=28,gender='男')
s1 = Students()
s1.name = '小红'
s1.age = 20
s1.gender = '女'
s2 = {'name': '小强','age': 20,'gender': '男'}
s3 = Students(**s2)
session .add_all([s,s1,s3])
session.commit()
删
# 1
d = Students.query.get(2) #没有数据会报错
session.delete(d)
session.commit()
# 2
Students.query.get(3).delete_obj() #没有数据会报错
改
# 1
g = Students.query.get(4)
g.name = '小明'
session.add(g)
session.commit()
# 2
g = Students.query.get(4)
g.name = 'xiaoming'
g.save()
查
c = Students.query.all() #返回查询的所有结果
print(c)
c = Students.query.first()#返回查询的第一个结果
print(c)
c = Students.query.filter_by(age = 20).all()# 返回年龄为20的所有数据
print(c)
c = Students.query.order_by('age').all() #升序
print(c)
c = Students.query.order_by(models.desc('age')).all()#降序
print(c)
c = Students.query.get(2)#以主键查询,没有返回none
print(c)
c = Students.query.offset(0).limit(1).all() #offset偏移量,limit限制条数
print(c)
如果有offset和limit的情况下,通常会用这个方法进行分页查询。
分页:用到参数
Page 页码 1
Page_size 单页条数 10
第1页 数据 0-10
第2页 数据 10-20
第3页 数据 20-30
第n页 数据 (n-1)page_size - npage_size
使用offset和limit

基于Flask_sqlalchemy的数据库操作优化
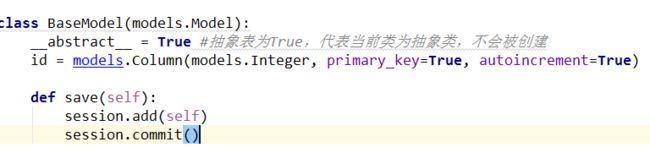
结构瑕疵
将重复的字段和方法写到一个类里,然后继承
数据映射瑕疵
Flask-sqlslchemy 继承了 sqlalchemy的数据库抽象,在一对多和多对多关系当中,需要双向映射。
Sqllite数据库,在整形的orm类型可以传入字符。