隐马尔可夫(HMM)介绍及在NLP中分词的应用(python实现)
隐马尔可夫介绍
隐马字面解释就是隐藏的马尔可夫链,也就是隐藏状态,由每个隐藏状态可以得到一个可观测值,如下图所示:
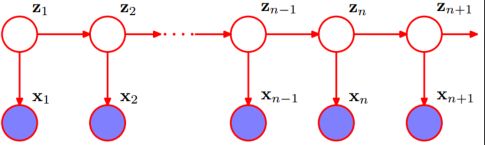
隐含状态的转移概率矩阵A,可观测值转移矩阵B,状态的初始值![]()
HMM是一个关于序列问题建模的算法,当前状态只受前一个状态的影响,可观测值是由内部的一个状态决定的。如果给定一批足够多的可观测值的数据,我们可以通过这些数据去学习HMM模型(学习问题),通过这批已发生的事件的最大概率,用极大似然估计,求得HMM模型的参数![]() 。模型参数求出来后,模型就已经建好了,我们就可以进行预测了(预测问题)。给定一组观测状态(x1,x2,x3....,xn)我们可以用动态规划思路,从第一个状态算出一条到最后状态概率值最大的路径,就是最佳的状态转移过程,这就是Viterbi算法。(高度概括浓缩版本)
。模型参数求出来后,模型就已经建好了,我们就可以进行预测了(预测问题)。给定一组观测状态(x1,x2,x3....,xn)我们可以用动态规划思路,从第一个状态算出一条到最后状态概率值最大的路径,就是最佳的状态转移过程,这就是Viterbi算法。(高度概括浓缩版本)
Viterbi算法的执行过程以及原理
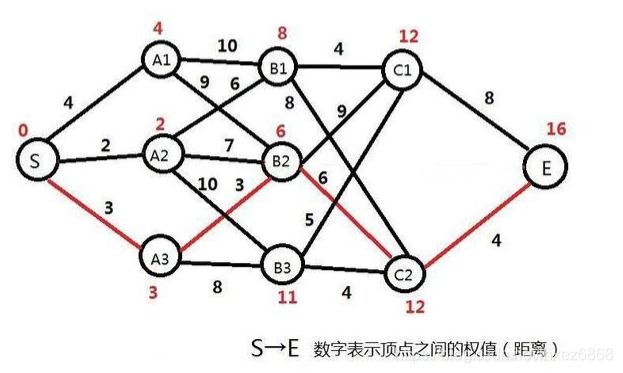
如下图所示,隐含层的全部路径是指数级别的,黄线构成的路径是其中一条,这种不是普遍的图,而叫做篱笆网络,可以看到是有层次的。

如下图所示,每条边都有一个权重,可以视为真实场景的概率值,我们要求从S点到E点所经过的路劲权重值要最大。那么我们想想从B层到C中的时候,考虑C2点,到达这个点的最大权重值是多少?是不是应该从(S到B1的最大值,B1-C2)、(S到B2的最大值,B2-C2)、(S到B3的最大值,B3-C2)这三个中选择一个。同理递推,经过B1的最大值呢,经过A3的最大值呢,S到A1、A2、A3是算法的临界点,这就是动态思路的过程,由局部最优解得到全局的最优解。此动态规划思路命名为Viterbi算法,并没有什么高大上的。
HMM模型在NLP中分词的应用
在分词时对序列进行标注,用BMES规则标注,B:代表开头字符,M:代表中间字符,E:代表结尾字符,S:代表单独存在的字符
如: 我 是 来自 厦门市 的 帅哥
标注:S S BE BME S BE
当对分词进行HMM建模时,BMES当作隐状态,隐含状态的转移概率矩阵A大小为[4,4]。可观测值为中文句子,可观测值转移矩阵B,大小为[4,出现汉字总个数]。
首先是模型的学习,如何获取参数![]() ,对一些列已经分好的文章,我们可以通过每个词的长度来辨别标注的内容,如果是单个字的肯定是S,如果是两个字的是BE,大于两个字的是B[(M)*(n-2)]E。这样就可以通过统计的方法来得到
,对一些列已经分好的文章,我们可以通过每个词的长度来辨别标注的内容,如果是单个字的肯定是S,如果是两个字的是BE,大于两个字的是B[(M)*(n-2)]E。这样就可以通过统计的方法来得到![]() ,统计每个隐含状态BMES之间的转移次数转换成概率得到A,和每个隐含状态推导出中文字的次数转换成概率得到B,初始状态就更好得到了,只需要单独计数BMES出现的频率就好了。
,统计每个隐含状态BMES之间的转移次数转换成概率得到A,和每个隐含状态推导出中文字的次数转换成概率得到B,初始状态就更好得到了,只需要单独计数BMES出现的频率就好了。
模型构建好后,就要进行预测了,那就是Veterbi的算法过程,具体的算法过程在前面已经详细说过了,就不在累述。
当给定一个句子“见过我的妹子都喜欢上我了”,找到一个概率最大的隐状态转移过程,
假如得到的是BESSBESBEBES,则分词结果“见过 我 的 妹子 都 喜欢 上我 了”(没毛病)
HMM实现分词的pyton实现
# -- encoding:utf-8 --
import jieba
import warnings
import numpy as np
warnings.filterwarnings('ignore')
def normalize(a):
tmp = np.log(np.sum(a))
for i in range(len(a)):
if a[i] == 0:
a[i] = float(-2 ** 31)
else:
a[i] = np.log(a[i]) - tmp
return a
def fit(train_file_path, encoding='utf-8'):
"""
基于给定好的数据进行分词的HMM模型训练
:param train_file_path:
:param encoding:
:return:
"""
# 1. 读取数据
with open(train_file_path, mode='r', encoding=encoding) as reader:
sentence = reader.read()[1:]
# 2. 初始化相关概率值
"""
隐状态4个,观测值65536个
隐状态:
B: 表示一个单词的开始,0
M:表示单词的中间,1
E:表示单词的结尾,2
S:表示一个字形成一个单词,3
"""
pi = np.zeros(4)
A = np.zeros((4, 4))
B = np.zeros((4, 65536))
# 3. 模型训练(遍历数据即可)
# 初始的隐状态为2
last_state = 2
# 基于空格对数据做一个划分
tokens = sentence.split(" ")
# 迭代处理所有的单词
for token in tokens:
# 除去单词前后空格
token = token.strip()
# 获取单词的长度
length = len(token)
# 过滤异常的单词
if length < 1:
continue
# 处理长度为1的单词, 也就是一个字形成的单词
if length == 1:
pi[3] += 1
A[last_state][3] += 1
# ord的函数作用是获取字符状态为ACSII码
B[3][ord(token[0])] += 1
last_state = 3
else:
# 如果长度大于1,那么表示这个词语至少有两个单词,那么初始概率中为0的增加1
pi[0] += 1
# 更新状态转移概率矩阵
A[last_state][0] += 1
if length == 2:
# 这个词语只有两个字组成
A[0][2] += 1
else:
# 这个词语至少三个字组成
A[0][1] += 1
A[1][2] += 1
A[1][1] += (length - 3)
# 更新隐状态到观测值的概率矩阵
B[0][ord(token[0])] += 1
B[2][ord(token[-1])] += 1
for i in range(1, length - 1):
B[1][ord(token[i])] += 1
last_state = 2
# 4. 计算概率值
pi = normalize(pi)
for i in range(4):
A[i] = normalize(A[i])
B[i] = normalize(B[i])
return pi, A, B
def cut(decode, sentence):
T = len(decode)
t = 0
while t < T:
# 当前时刻的状态值
state = decode[t]
# 判断当前时刻的状态值
if state == 0 or state == 1:
# 表示t时刻对应的单词是一个词语的开始或者中间位置,那么后面还有字属于同一个词语
j = t + 1
while j < T:
if decode[j] == 2 or decode[j] == 3:
break
j += 1
# 返回分词结果
yield sentence[t:j + 1]
t = j
elif state == 3 or state == 2:
# 这个时候表示单个字或者最后一个字
yield sentence[t:t + 1]
t += 1
def viterbi(pi, A, B, Q, delta=None):
"""
根据传入的参数计算delta概率矩阵以及最优可能的状态序列以及出现的最大概率值
:param pi:
:param A:
:param B:
:param Q:
:param delta:
:return:
"""
# 1. 初始化参数
n = np.shape(A)[0]
T = np.shape(Q)[0]
if delta is None:
delta = np.zeros(shape=(T, n))
# pre_index[t][i]表示的是t时刻状态为i的最有可能的上一个时刻的状态值
pre_index = np.zeros((T, n), dtype=np.int64)
# 2. 求解t=0时刻对应的delta值
for i in range(n):
delta[0][i] = pi[i] + B[i][Q[0]]
# 3. 求解t=1到t=T-1时刻对应的delta值
for t in range(1, T):
for i in range(n):
# a. 获取最大值
max_delta = delta[t - 1][0] + A[0][i]
for j in range(1, n):
tmp = delta[t - 1][j] + A[j][i]
if tmp > max_delta:
max_delta = tmp
pre_index[t][i] = j
# b. 基于最大概率值计算delta值
delta[t][i] = max_delta + B[i][Q[t]]
# 4. 获取最有可能的序列
decode = np.ones(shape=T, dtype=np.int64) * -1
# 首先找出最后一个时刻对应的索引下标
max_delta_index = np.argmax(delta[-1])
max_prob = delta[-1][max_delta_index]
decode[-1] = max_delta_index
# 基于最后一个时刻的最优状态,反退前面时刻的最大概率状态
for t in range(T - 2, -1, -1):
# 获取t+1时刻对应最优下标的值
max_delta_index = pre_index[t + 1][max_delta_index]
# 赋值
decode[t] = max_delta_index
return delta, decode, max_prob
if __name__ == '__main__':
# 是进行学习模型,还是进行预测(分词)
flag = False
if flag:
pi, A, B = fit('./pku_training.utf8')
# 模型参数保存
np.save('pi.npy', pi)
np.save('A.npy', A)
np.save('B.npy', B)
else:
# 1. 加载模型参数
pi = np.load('pi.npy')
A = np.load('A.npy')
B = np.load('B.npy')
# print(pi)
# print(np.exp(pi))
# 2. 做分词
Q_str = "因为在我们对文本数据进行理解的时候,机器不可能完整的对文本进行处理,只能把每个单词作为特征属性来进行处理,所以在所有的文本处理中,第一步就是分词操作,中共中央总书记"
Q_str = "自然语言的基础是中文分词"
Q_str = "我爱中国"
Q = []
for cht in Q_str:
Q.append(ord(cht))
_, decode, _ = viterbi(pi, A, B, Q)
print(decode)
# 3. 基于隐状态做一个分词的操作
cut_result = cut(decode, Q_str)
print("分词结果为:\n{}".format(list(cut_result)))
print("jieba分词结果:\n{}".format(jieba.lcut(Q_str)))
使用的pku_training.utf8数据集可以到这边下载