【综述】对话系统中的口语理解技术
1. 基本介绍
对话系统中的口语理解技术一般称为NLU(natural language understanding),或SLU(spoken language understanding)。NLU的工作在于给定用户的query(或utterance),输出相应的语义结构化表示,这种结构化的表示包括三个部分:
- 领域(domain):一般指该query所属的领域范围,比如:天气、闹钟、音乐、火车票等;
- 意图(intent):一般指该query的用户意图,比如:查天气、订火车票、退火车票等;
- 槽位(slot):一般指完成用户意图所需的属性信息,比如在订火车票的时候,需要时间、出发地、目的地等槽位。
具体例子如下:
- 输入:query = show restaurant at New York tomorrow
- 输出:{domain = order, intent = find restaurant, slots = {desti = New York, date = tomorrow}}

因此,NLU的工作分为两个层面:
- 领域分类和意图识别(domain classification, intent detection):核心是分类问题;
- 语义槽填充(slot filling):核心是序列标注问题,输入一个句子序列,输出每个词对应的semantic slot序列。
其中,domain、intent和slot的集合称为语义的schema,一般是事先定义好,代表着对话系统可以理解的语义范围。一般来说有两种建模结构:
(1)intent是domain的下属概念,slot也是domain的下属概念。
比如,在火车票领域下,一方面包括查询火车票、退火车票的意图,另一方面包括时间、出发地、目的地的槽位。
(2)弱化domain的概念,仅仅建模意图和槽位。
一般intent可以认为是domain的子分类,因此直接铺平建模即可。
schema的定义在对话系统实践中非常非常非常重要,一个好的schema定义要兼顾问题的难度和体系的扩展性。
2. 评测
2.1 数据集
2.1.1 ATIS dataset
ATIS (Airline Travel Information System) ,航空旅游信息系统的日志数据。
- 数据大小
- 训练集:包含4978条数据,来自于 the Class A (context independent) portions of ATIS-2 and ATIS-3,一般开发集是从训练集中采样20%出来,剩下的作为训练集。
- 测试集:包括893条数据,来自于 the ATIS-3 Nov93 and Dec94 datasets。
- 数据标签
- 18个意图,比如:flight,flight_time,ground_service,airfare等。
- 127个槽位标签,比如:B-fromloc.city_name,B-toloc.city_name,B-arrive_time.time,I-arrive_time.time等。原始标签包括83个,经过BIO方式展开后去掉不可能存在的标签之后还剩余127个,比如:针对aircraft_code标签,只可能扩展出B-,而不可能有I-。
- 数据格式
- 可以从这里下载,https://github.com/howl-anderson/ATIS_dataset

2.1.2 CB dataset
Conversational Browser (CB) addressee, 用户和一个对话浏览器交互产生的日志数据,包括6.3小时音频数据、38个session,每个session长度5~40分钟。
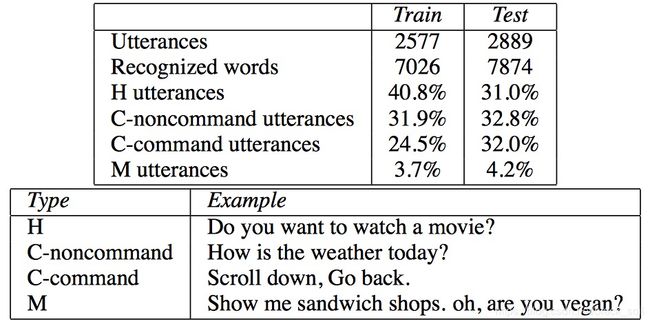
2.1.3 CQUD
CQUD(Chinese Question Understanding Dataset),来自百度知道。包含3286个问题,4个领域(航班、天气、快递、其它),43个意图和20个槽位。
2.2 评测指标
意图:准确率 accuracy
槽位:F值


说明:准确率和召回率是以槽位为单元,而不是query为单元,如果某个query包含2个槽位,则计为2个单元,如果某个query没有任何槽位,则计为0个单元。
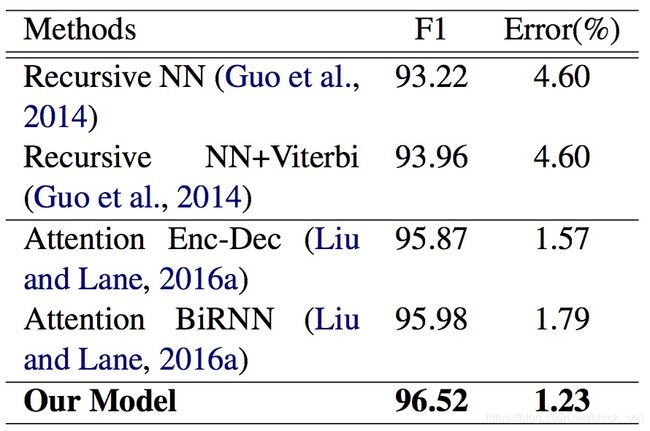
2.3 效果对比
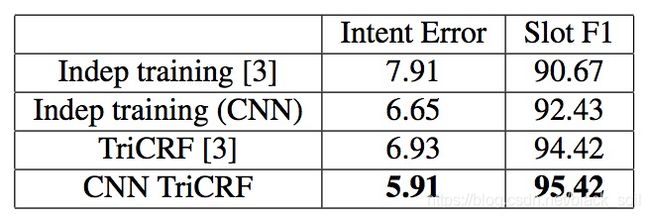
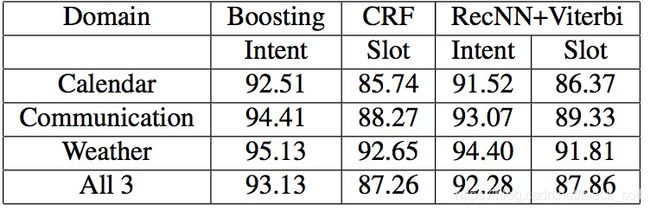
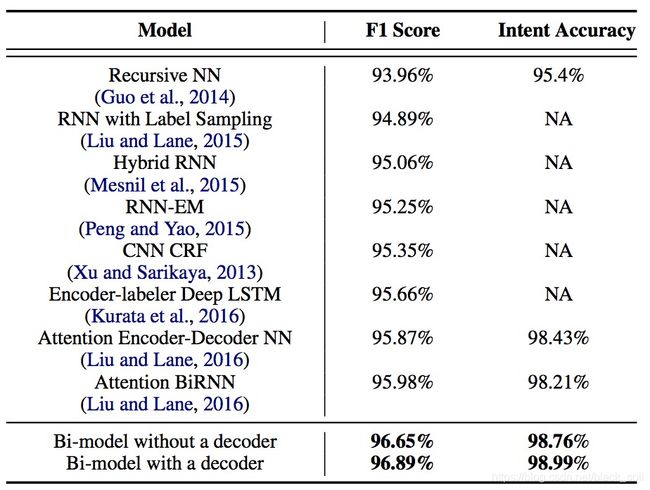
ATIS 是一个比较常用的数据集,这里把在该数据集上评测过的模型结果汇总在一起进行对比,结果如下表,从上往下依次包括意图分类效果、槽位抽取效果、联合模型效果。
可以看出:目前最好的结果来自联合模型,Intent错误率为1.01%,Slot F1为96.89%。
| Model |
Intent EER (%) |
Slot F1 (%) |
Paper |
| RNN-word |
5.26 |
- |
Suman Ravuri, 2015 |
| RNN-word + tag |
2.45 |
- |
同上 |
| LSTM-word |
2.45 |
- |
同上 |
| LSTM-word+tag |
1.94 |
- |
同上 |
| CRF |
- |
92.94/92.36 |
- |
| Bi-Jordan-RNN |
- |
93.98 |
Mesnil, 2013 |
| RNN trained with sampled label (pi=0.8) |
- |
94.89 |
B Liu, 2015 |
| LSTM |
- |
94.85 |
Kaisheng Yao, 2014 |
| LSTM-ma(3) |
- |
94.92 |
同上 |
| Deep LSTM (2 layers) |
- |
95.08 |
同上 |
| Hybrid RNN |
- |
95.06 |
Grégoire Mesnil, 2015 |
| Hybrid RNN + NE |
- |
95.85 |
同上 |
| R-CRF + NE |
- |
96.46 |
同上 |
| Encoder-labeler LSTM (W) |
- |
95.40 |
Gakuto Kurata, 2016 |
| Encoder-labeler Deep LSTM (W) |
- |
95.66 |
同上 |
| RecNN |
4.60 |
93.22 |
Daniel Guo, 2014 |
| RecNN + Viterbi |
4.60 |
93.96 |
同上 |
| RNN based (W) |
1.90 |
95.49 |
Xiaodong Zhang, 2016 |
| RNN based (W+N) |
1.68 |
96.89 |
同上 |
| Attention Encoder-Decoder NN |
1.57 |
95.87 |
Bing Liu, 2016 |
| Attention BiRNN |
1.79 |
95.98 |
同上 |
| Self attention |
1.23 |
96.52 |
Changliang Li, 2018 |
| Bi-model without a decoder |
1.24 |
96.65 |
Yu Wang, 2018 |
| Bi-model with a decoder |
1.01 |
96.89 |
同上 |
3. 现有方法
本节首先介绍领域分类、意图识别、槽位填充的代表性方法,然后介绍联合NLU方法。
3.1 Domain classification / Intent Detection
首先,领域分类和意图识别是一个标准的分类问题,因此所有的分类模型都可以尝试使用,比如传统的SVM、MaxEnt之类的方法,该类方法一般需要从用户的utterance中提取句法、词法、词性等特征。其次,utterance是一句话,因此文本分类的方法也都可以直接使用,相比普通的句子(sentence),utterance来自于口语场景ASR识别的结果,往往更加口语化,包含更多的噪声。
目前流行方法是深度学习方法,包括CNN、RNN、DNN等,下面选择一些代表性方法进行介绍。
3.1.1 CNN classifier
Paper: Convolutional Neural Networks for Sentence Classification, Yoon Kim, EMNLP2014
提出用 CNN 进行句子分类,属于通用的句子分类,并非针对口语的分类。
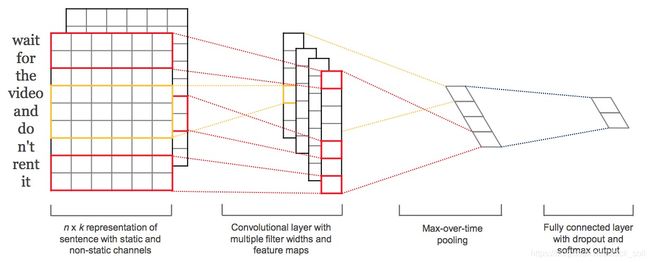
实验结果:发现即使只有1层卷积,也可以达到很不错的效果,此外通过词向量的 fine-tune 和 multichannel 往往可以进一步提升效果。
CNN-rand 表示词向量随机初始化;
CNN-static 表示词向量预先训练好(word2vec)不改变;
CNN-non-static 表示词向量预先训练好,并且训练过程进行 fine-tune;
CNN-multichannel 表示词向量分两组,梯度反传更新时一组进行 fine-tune,另一个组保持不变。

Paper: A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification,Ye Zhang,Byron C. Wallace,2015
论文对利用CNN进行句子分类的方法进行了敏感性分析,在模型选择、参数设置等方面给出一些建议。主要结论如下:
(1) 输入的词向量:GloVe和word2vec各有千秋,one-hot效果不佳;
(2)filter region大小:对效果影响较大,2~25,采用多个最优值附近的filter对效果有帮助,可以先采用线性搜索发现最优大小,然后结合多个;
(3)feature map个数:50~600;
(4)激活函数:建议采用Iden(无激活函数),ReLU(as per the original setting),tanh(hyperbolic tangent),比Sigmoid function、SoftPlus function、Cube function、tanh cube function要好一些。
(5)polling策略:1-max polling优于k-max polling,max polling优于average polling。
(6)正则项:作用不明显,不要使用过强的正则,dropout rate取值在0~0.5,l2 norm不超过3。
(7)算法存在随机性,评价时不应该只说均值,应该包括方差,10-fold交叉验证中平均效果有1.5个点的提高。
3.1.2 RNN classifier
Paper: Recurrent Neural Network and LSTM Models for Lexical Utterance Classification,Suman Ravuri,Andreas Stolcke,InterSpecch2015
论文提出采用RNN和LSTM来进行领域分类,RNN是每个时刻预测生成label的概率,所有时刻的概率乘起来作为最终的概率。
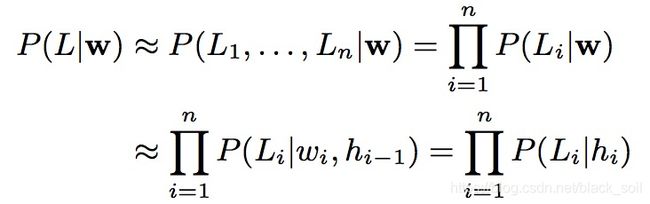

LSTM也可以同RNN一样每个时刻都进行标签预测,但是作者发现,在结尾的时候预测一次效果会更好。
实验结果:
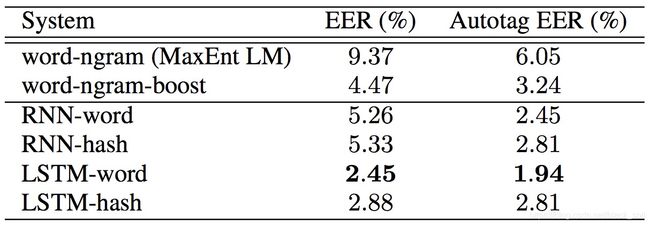
ATIS数据集,autotag表示数据中的某些命名实体用标签替换,该数据集上LSTM-word效果最好。
CB数据集,combo表示和基线系统word-ngram集合,该数据集上RNNLM-hash效果最好。
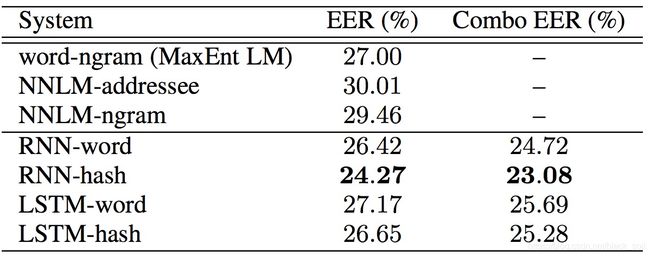
实验结论:发现RNN更适合短文本(2~6个词),LSTM更适合长文本(10~15个词),命名实体替换为标签或者结合ngram都会进一步提升效果。
Paper: Sequential Short-Text Classification with Recurrent and Convolutional Neural Networks, Ji Young Lee, Franck Dernoncourt, 2016
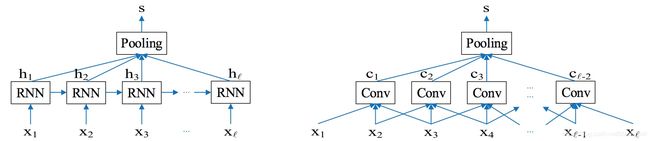
提出基于RNN和CNN进行文本表示,并融合preceding short texts(即前面的几个词)的模型。
(1)短文本表示:可以使用RNN或CNN把短文本表示成向量,如下:
(2)序列短文本分类:基于文本向量表示和preceding short texts进行分类,如下:
图1表示不采用任何历史词,图2表示第一层采用历史2个词,图3表示第一层不采用历史词,第二层采用2个历史词;图4表示第一层和第二层均采用1个历史词。
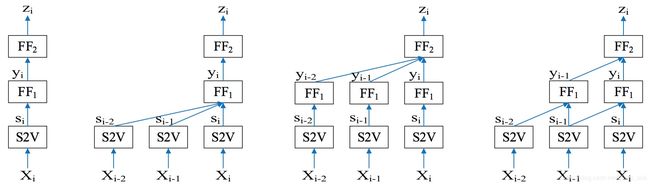
实验结果表明:在第一层增加历史词会比第二层增加历史词效果更好。

3.1.3 CNN + RNN classifier
同时采用CNN和RNN,相比使用单个结构,可以同时结合两者的优势,效果可以进一步提升,比如:
Paper: Recurrent Convolutional Neural Networks for Text Classification,Siwei Lai, Liheng Xu, Kang Liu, Jun Zhao,AAAI2015
论文提出RCNN,具体地,首先利用一个双向的recurrent结构提取特征,为了考虑上下文特征,每个词会把左右的词拼接在一起;然后输出到一个max-pooling层,最后进行预测。通过recurrent结构和max-pooling layer,该模型可以同时具有rnn和cnn的优势,这就是该模型命名的含义吧。
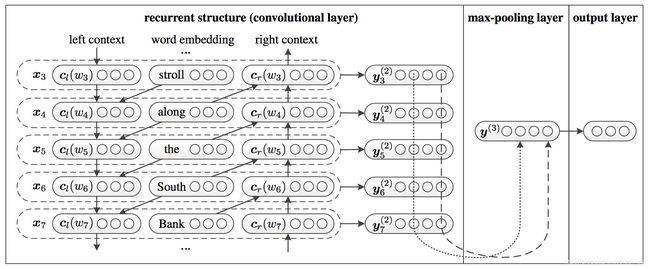
Paper: A C-LSTM Neural Network for Text Classification,Chunting Zhou, Chonglin Sun, Zhiyuan Liu (Tsinghua), Francis C.M. Lau,2015
论文提出先利用CNN从句子中提取high-level的短语表示,然后送进LSTM结构获得句子级的表示。
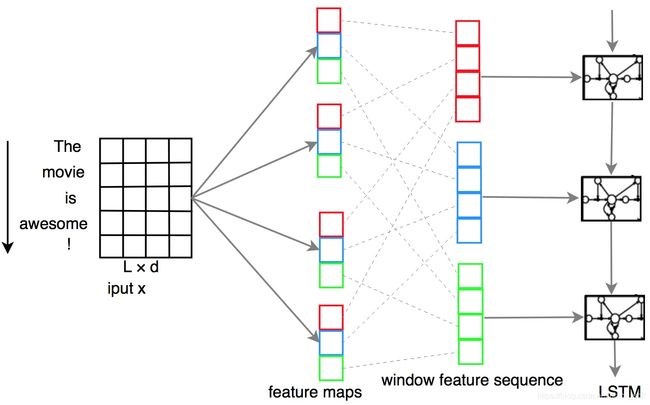
3.2 Slot Filling
槽位填充是一个标准的序列标注问题,因此传统的机器学习算法MEMM(Maximum entropy markov model)和CRF(Conditional random field)可以直接应用于槽位填充。相比MEMM,CRF可以解决标签偏置(label bias)的问题,在序列标注问题中被广泛使用,也经常作为新提出模型的基线模型。目前流行的做法是基于RNN及其各种变种,以及与CRF的结合,下面介绍一些典型方法。
3.2.1 RNN
Paper: Investigation of recurrent-neural-network architectures and learning methods for spoken language understanding.;Mesnil et al, Interspeech, 2013
利用RNN结构进行槽位填充,包括两种RNN结构:Elman-type RNN和Jordan-type RNN,两者的区别在于隐层h(t)更新时,前者是跟上一时刻隐层h(t-1)相关,后者是跟上一时刻输出y(t-1)相关。

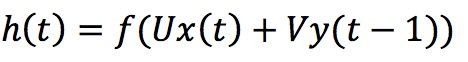
基于ATIS数据集,实验发现:基于RNN的方法明显超过CRF;两种RNN结构中,前向的版本(use past information)要比后向的版本(use future information)效果好,同时Jordan-RNN的前后向效果差异比Elman-RNN的要小,说明Jordan-RNN具有更好的鲁棒性;最后,双向的RNN取得了最好的结果。

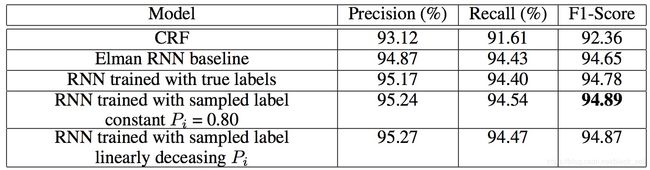
Paper: Recurrent Neural Network Structured Output Prediction for Spoken Language Understanding, B Liu, I Lane, NIPS, 2015
提出在隐层更新时直接采用前一时刻真实的标签,而不是像Jordan-RNN那样使用标签的概率。

为了提高模型训练的鲁棒性,训练时在真实标签和预测标签之间按照比例随机采样,测试时只能采用预测标签。
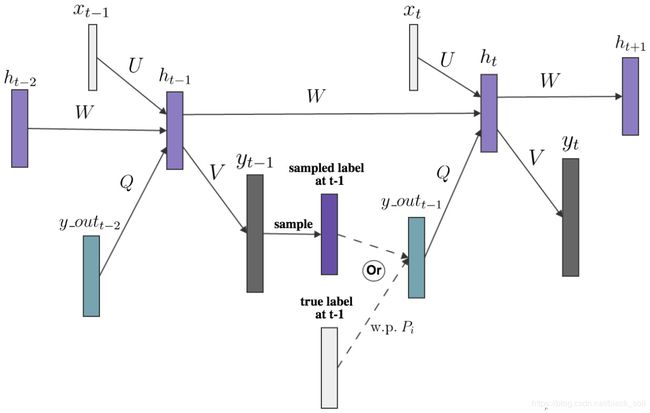
实验发现,利用真实标签确实要一些,随机策略也有帮助。(ATIS数据集)
3.2.2 RNN + 标签偏置
Paper: Spoken language understanding using long short-term memory neural networks, Kaisheng Yao, Baolin Peng, Yu Zhang, Dong Yu, Geoffrey Zweig, and Yangyang Shi, 2014
提出用LSTM进行槽位填充,并在lstm的基础上扩展一个回归模型来解决标签偏置的问题。这里采用移动平均(moving average),体现在计算输出yt的时候需要用到qt,而qt是历史时间窗口内ht,…, ht-M的累计表示。
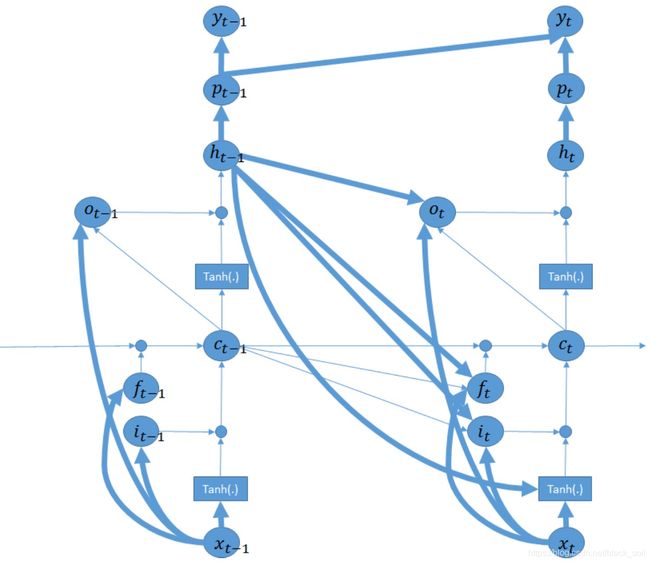
实验表明:基于ATIS数据集,在LSTM基础上采用移动平均会有略微的提升,同时,多层deep的LSTM(实验中2层)效果更好。

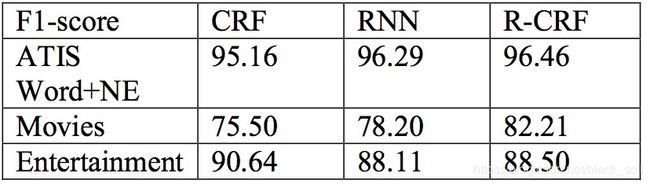
Paper: Using Recurrent Neural Networks for Slot Filling in Spoken Language Understanding, Grégoire Mesnil, Yann Dauphin, Kaisheng Yao, Yoshua Bengio, Li Deng, Dilek Hakkani-Tur, Xiaodong He, Larry Heck, Gokhan Tur, Dong Yu, and Geoffrey Zweig, 2015
长文,对比RNN不同结构在槽位填充上的效果,在Elman-RNN和Jordan-RNN基础上提出Hybrid-RNN(隐层h(t)更新时,同时跟上一时刻隐层h(t-1)和输出y(t-1)相关)。
原始的RNN同MEMM一样,存在标记偏置的问题,为了解决这个问题,提出两个办法:
(1)Viterbi decoding with slot language:建立slot tag的trigram语言模型
(2)recurrent CRF:CRF的特征产生于RNN,不需要特征函数。
ATIS数据集,实验结果显示:RNN方法显著超过CRF和FFN,另外,增加命名实体特征会进一步提升效果。


Paper: Bidirectional LSTM-CRF Models for Sequence Tagging,Zhiheng Huang,Wei Xu,Kai Yu,Computer Science,2015
详细对比CRF、LSTM、BI-LSTM、LSTM-CRF、BI-LSTM-CRF的效果,CRF layer的参数是一个转移矩阵。
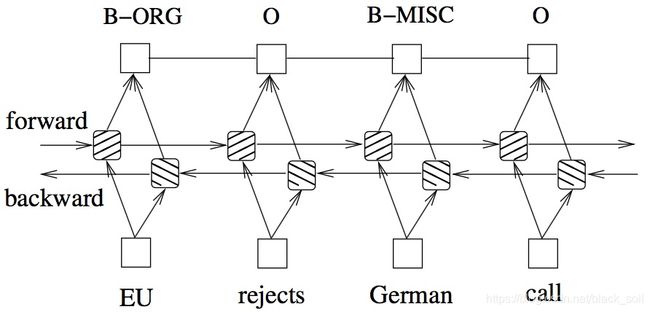
实验结果表明:还是应该选择BI-LSTM-CRF。

3.2.3 Sentence-level information
Paper: Leveraging Sentence-level Information with Encoder LSTM for Semantic Slot Filling, Gakuto Kurata, Bing Xiang, Bowen Zhou, Mo Yu, 2016
首先利用LSTM将query编码表示为一个向量,然后将该向量作为序列标注LSTM的初始状态。模型变种如下:
(a)标准的LSTM序列标注模型;
(b)将前一时刻的输出引入当前时刻的输入;
(c)标准的encoder-decoder模型;
(d)将后向encoder的表示作为标准序列标注的初始状态;
(e)在d的基础上,将前一时刻的输出引入当前时刻的输入。
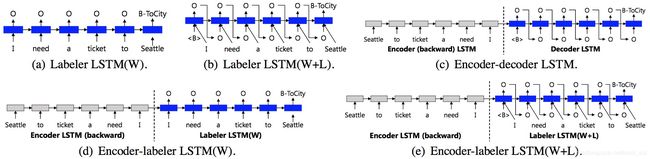
实验结果发:将encoder的表示作为序列标注的初始状态可以提升效果,比较意外的是e的效果不如d,也就是说引入前一时刻的输出对已经增加encoder的模型并没有帮助。


3.3 Joint NLU
如前所述,NLU的任务包括领域分类、意图识别和槽位抽取,那么当给定一个utterance时,很自然的想法是先进行领域分类,然后在相应领域内进行意图识别和槽填充,这种结构下任务之间存在先后关系,下游任务依赖上游任务的结果,一般称这类方法为基于流水线(pipeline)的方法。
基于流水线的方法存在以下问题:
(1)错误传递:上游任务的错误会直接传递给下游任务,一旦上游的领域预测发生错误,下游的意图预测和槽填充必然错误;
(2)上游任务不能从下游任务受益,而实际中下游任务意图预测和槽填充的结果是可以辅助进行领域预测的;
(3)很难共享领域不变的特征,比如所有领域通用或相似的的意图和槽。
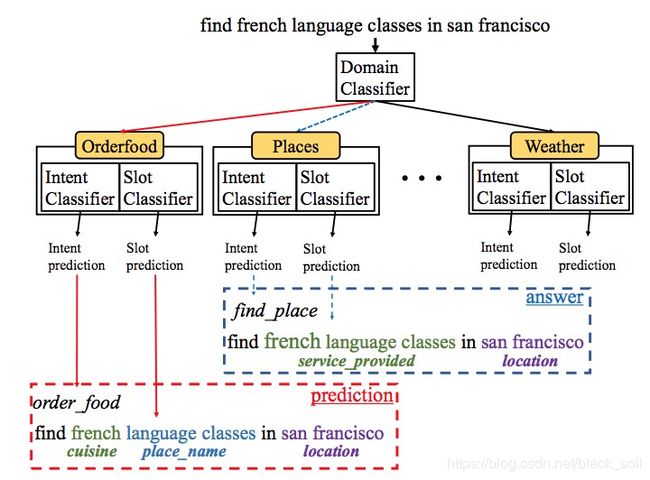
针对这些问题,学者提出了联合模型(joint model),将这些相互依赖的任务同时建模,使它们可以相互促进。联合的形式有两种,第一种将多个任务合并成一个任务,建模领域意图和槽位的联合概率;第二种是让多个任务共享底层特征,上层分为多个输出,计算损失的时候将每个输出的损失加起来。下面介绍一些代表性的方法。
3.3.1 任务合并
Paper: Convolutional neural network based triangular CRF for joint intent detection and slot filling, Puyang Xu and Ruhi Sarikaya, IEEE, 2013
利用CNN提取底层特征表示,利用triangular CRF建模意图和槽位的联合条件概率分布。
(1)三角链条件随机场
Paper: Triangular-chain conditional random fields,Minwoo Jeong and G Geunbae Lee, 2008.
三角链条件随机场(triangular-chain CRF)定义为:随机向量 x 表示输入的观察序列,随机向量 y 表示输出的标记序列,随机变量 z 是一个输出变量,表示主题或者意图。
在口语理解任务中,用 x 表示词序列,y 表示实体类别,z 表示意图类别,x0 表示意图 z 的一个观察特征向量,这种表示可以将其他知识整合到这个模型中。

一个三角链CRF模型是一个条件概率分布(给定 x 时, y和z的联合概率),有如下的形式:

三角链CRF可以分解为时间相关的 ϕt 和时间不相关的 φ 因子,ϕt 表示序列在 t 时刻的状态,而 φ 表示整个序列。三角链CRF可以看作一个线性链CRF和一个0阶CRF的组合。这样变量和势函数可以很自然地来源于两个CRF:(1)对于0阶CRF,x0是观察值,φ 是预测 z 的势函数;(2)对于线性链CRF,{xt }, t = 1,2,…,T 是观察值,ϕt 是势函数用于预测 y 。
(2)CNN + triangular CRF
意图识别:先得到隐藏层的特征h,再使用max pooling来获取整句的表示,最后用softmax做意图分类。
槽位填充:输入词向量到卷积层得到特征表示h,再用triangular-CRF打分。
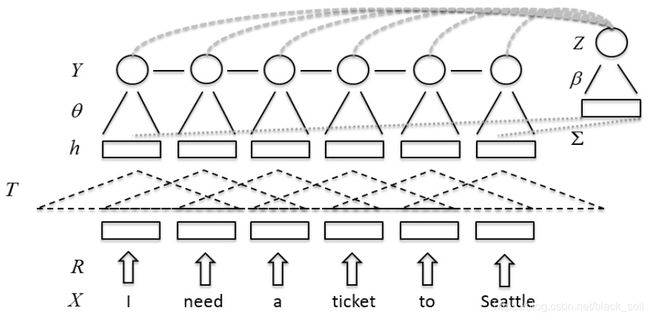
实验结果:数据采用老版本ATIS(包括5138条utterance,注意和新版数据不一样)和一个新的真实场景数据集,实验结果显示,利用CNN提取特征后再用TriCRF效果提升明显,同时联合模型比独立模型提升也很明显。
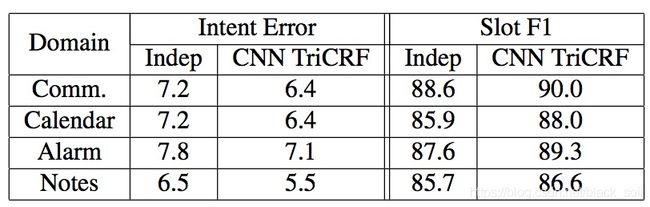
Paper: Multi-domain joint semantic frame parsing using bi-directional rnn-lstm. Dilek Hakkani-Tu ̈ r, Go ̈ khan Tu ̈ r, Asli Celikyilmaz, Yun-Nung Chen, Jianfeng Gao, Li Deng, and Ye- Yi Wang. 2016.
提出在utterance结尾增加一个额外的token,即
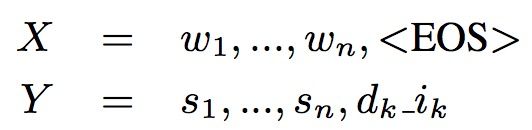
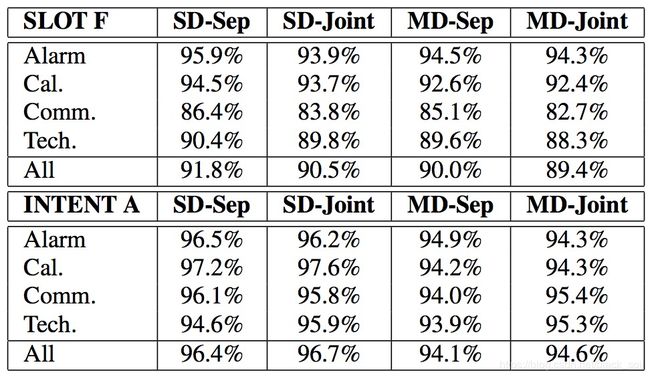
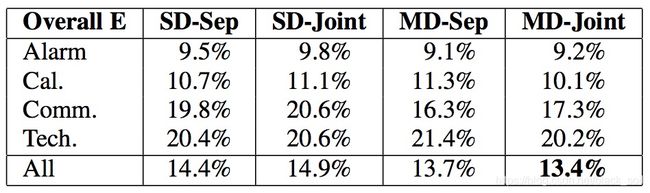
实验对比方法:SD表示single domain,MD表示multi domain,Sep表示seperate models,Joint表示联合模型,因此:
SD-Sep:每个领域有一个意图识别和槽位填充模型,共2D个模型;
SD-Joint:每个领域有一个联合模型同时得到意图和槽位,共D个模型;
MD-Sep:意图和槽位在所有领域展开,整个只有一个意图模型和槽位模型,共2个模型
MD-Joint:意图和槽位在所有领域展开,整个只有一个联合模型,共1个模型。
实验发现:不管是单领域还是多领域,联合模型对意图准确率都有提升(尽管不大),但槽位F值却是下降的。不过从全局来看,多领域的联合模型在整体错误率上是最小的。
3.3.2 RecNN based
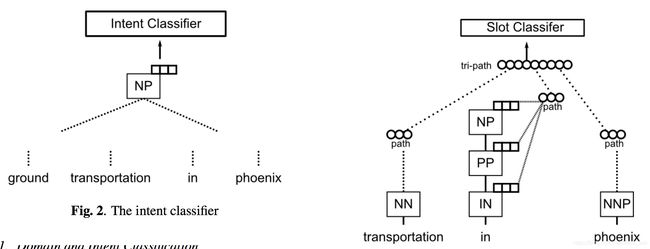
Paper: Joint semantic utterance classification and slot filling with recursive neural networks. Daniel Guo, Gokhan Tur, Wen-tau Yih, and Geoffrey Zweig. 2014.
本文直接进行意图识别,因为领域可以通过识别出来的意图直接推导出来。
意图识别:自底向上得到树的root节点的输出向量,与每一个意图标签的向量点乘,然后softmax归一化得到各个意图的概率。
槽位填充:一方面,一条路径上的节点的向量加权求和得到路径的表示向量,权重跟节点类型相关;另一方面,将前一个和后一个的路径向量与当前的路径向量拼接在一起,形成一个tri-path向量。采用Viterbi来建模槽位标签的转移概率,而不是用CRF。
损失函数为意图和槽位的softmax classifier输出的交叉熵损失之和。
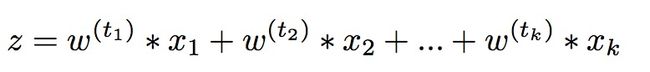
ATIS数据集上,新方法意图识别和对比方法效果相当;槽位填充明显超过CRF,与RNN和CNN+TriCRF相当。

Cortana数据集上,意图均低于boosting,slot效果3个领域提升,1个领域下降。
3.3.3 RNN based
Paper: A Joint Model of Intent Determination and Slot Filling for Spoken Language Understanding, Xiaodong Zhang and Houfeng Wang, IJCAI2016
利用RNN提取底层共享特征,上层一部分是意图分类,另一部分是槽位填充,损失函数为意图损失和槽位损失的加权和。
输入xt的表示包括e(wt)—word embeddings和e'(nt)—named entity embeddings,并且,利用滑动窗口将前后的context拼接起来。
然后,输入到双向的GRU得到隐层表示。
经过max polling得到句子的全局表示:

意图和槽的类别:
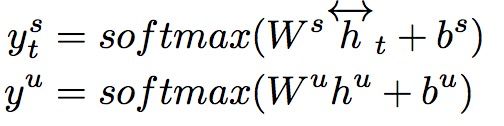
建模槽标签的转移概率:

损失函数:
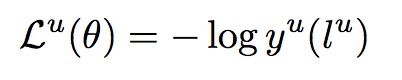
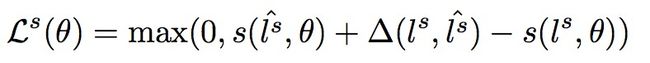
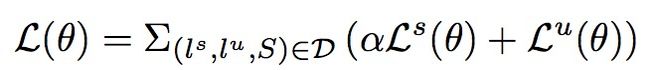
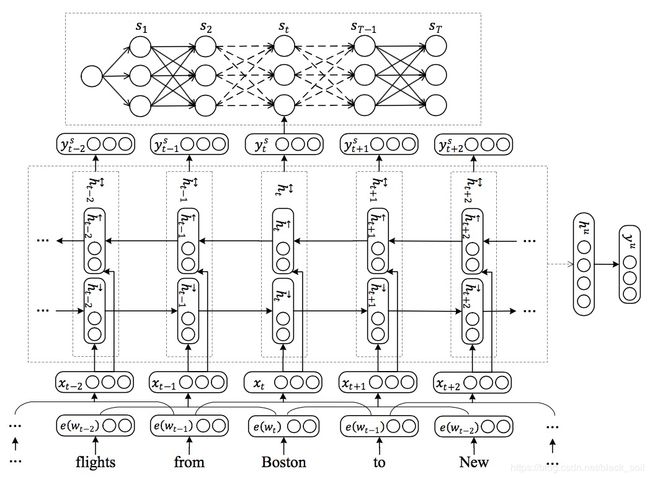
数据集:ATIS, CQUD,其中feature列W, N and S代表词、命名实体和句法特征。
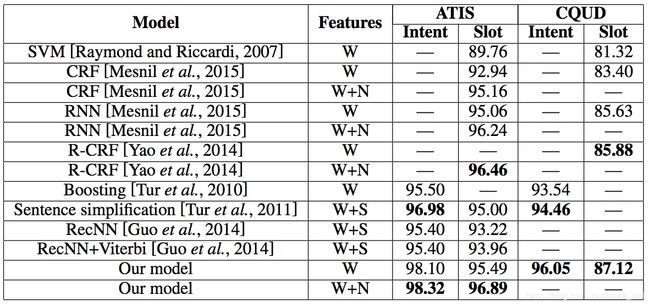
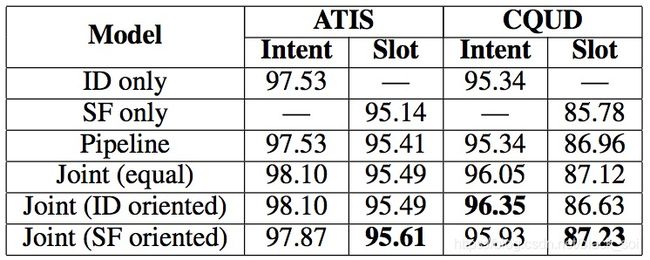
如果我们将联合模型的某一个任务设置为面向的任务(更大的权重系数),那么可能针对这个任务会获得更高的效果。比如,某个系数下intent效果最好,而另个系数下slot效果最好。
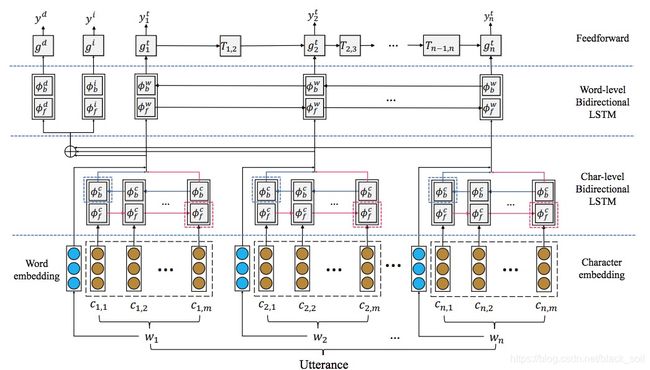
Paper: Onenet: Joint domain, intent, slot prediction for spoken language understanding. Young-Bum Kim, Sungjin Lee, and Karl Stratos. 2017.
利用char-level BLSTM建模单词的char序列特征,和word embeding一起作为输入表示,然后分别预测领域、意图和槽位。
损失函数为领域负对数似然、意图负对数似然、槽位负对数似然之和。
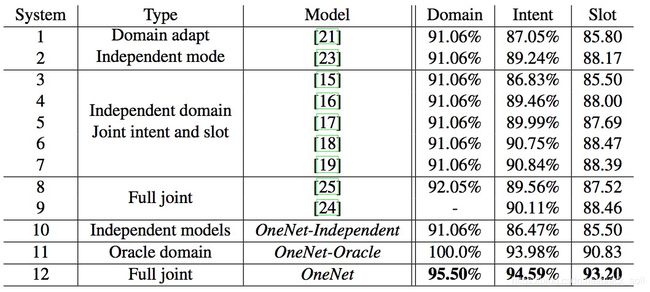
实验发现,预训练每个模型非常重要,因此,首先优化domain classifier,然后优化intent classifier,接着联合优化domain和intent classifier,最后联合优化domain classifier、intent classifier和slot tagging。
数据集cortana data,包括5个领域:闹钟、日历、通信、地点和提醒。
Paper: Jointly modeling intent identification and slot filling with contextual and hierarchical information. Liyun Wen, Xiaojie Wang, Zhenjiang Dong, and Hong 866 Chen. 2017.
联合模型中考虑上下文信息和层级信息。
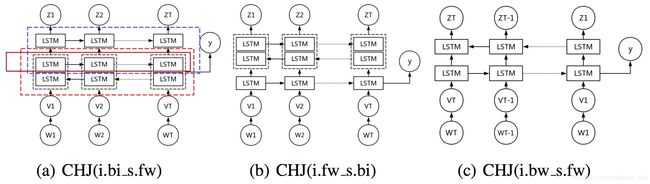
实验数据:DSTC2,DSTC5,CMRS,三个数据集上都最好。
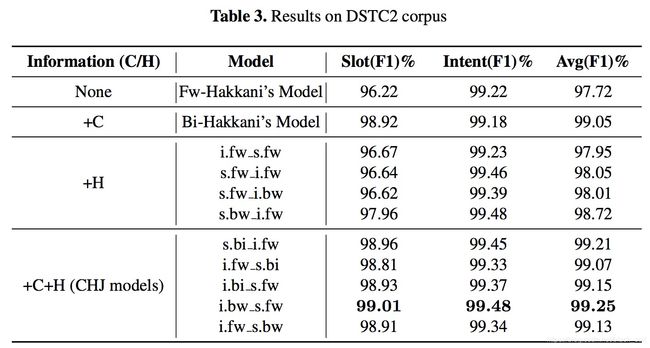
Paper: A bi-model based rnn semantic frame parsing model for intent detection and slot filling. Yu Wang, Yilin Shen, and Hongxia Jin. 2018.
提出考虑两个任务之间的交叉影响,用两个相关的BLSTM来实现,实际上就是一个LSTM输出的隐层会和另一个的合在一起发挥作用。分为有decoder和无decoder版本。

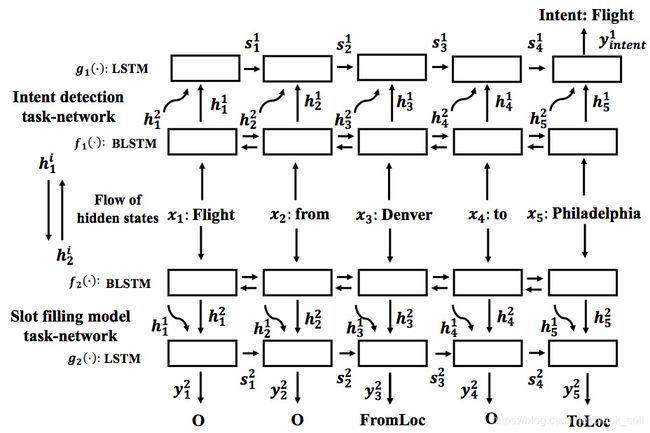
实验结果:刷新指标啊。ATIS数据集
3.3.4 Attention based
Paper: Attention-based recurrent neural network models for joint intent detection and slot filling, Bing Liu and Ian Lane. 2016.
(1)encoder-decoder
利用encoder对文本进行编码,decoder分为两部分:一个是直接进行intent分类,另一个是按照序列的方式解码slot。
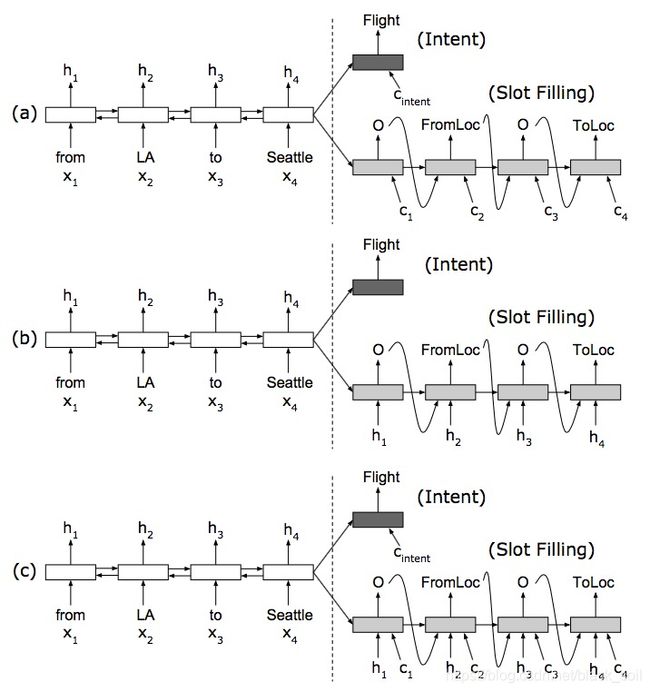
图a 非对齐attention模型:decoder每个时刻的输入ci是基于attention的隐层加权表示;
图b 对齐无attention模型:decoder每个时刻的输入就是encoder的输出的隐层表示hi;
图c 对齐attention模型:decoder每个时刻的输入包括ci和hi。
(2)Attention-based RNN
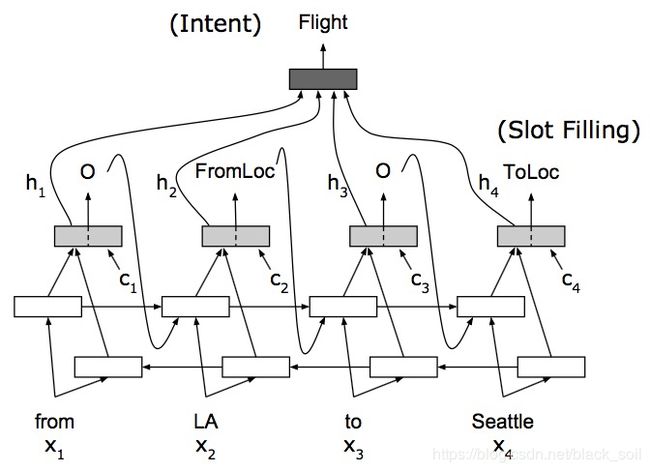
encoder包括前向和后向,其中前向包括槽位的序列的依赖;BiRNN得到特征并与文本向量拼接后作为单层decoder的输入,然后识别槽位,decoder的隐层输出加权后进行意图分类。
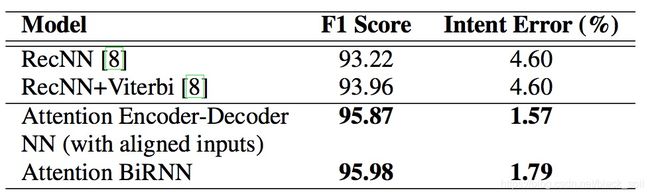
实验结果:发现attention机制对最终效果提升很明显。ATIS数据集
Paper: A self-attentive model with gate mechanism for spoken language understanding. Changliang Li, Liang Li, and Ji Qi. 2018.
提出self-attention进行意图识别和槽位填充。
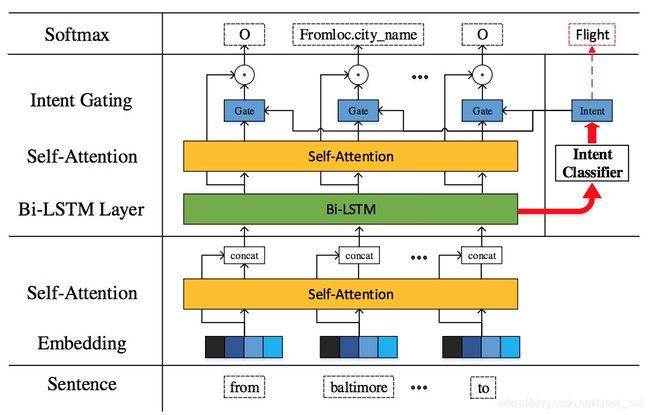
实验结果:进一步刷新了测试集指标。ATIS数据集
3.3.5 在线实时预测
Paper: Joint Online Spoken Language Understanding and Language Modeling with Recurrent Neural Networks, 2016
考虑实时语义理解场景中,utterance的词是一个一个到来的,该模型支持在线实时预测,不用等到所有words到来之后再预测,新的word到来后会更新预测结果。
联合学习意图识别、槽填充、下一个词预测。输入先经过LSTM,然后分别经过3个MLP结构得到各自的预测。
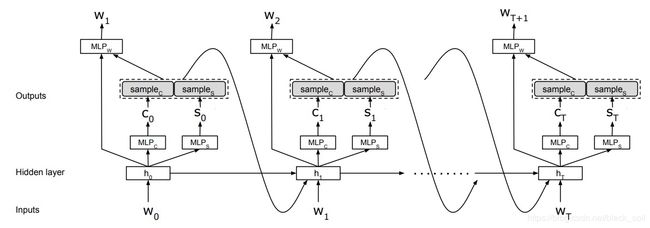
ATIS数据集
4. 总结
意图分类和槽位抽取目前模型已经很成熟,实践中应该更多关注场景和数据,比如意图和槽位类别如何定义、数据质量如何保证、以及相应的特征工程(实体特征、词性等)。