BERT面向语言理解的深度双向变换预训练
https://www.toutiao.com/a6648267891932135949/
2019-01-20 02:04:22
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
原文:https://arxiv.org/abs/1810.04805
作者:Google AI团队
译者:Tony
时长:2K+字,约5分钟
说明:为了方便理解,未一对一翻译,仅翻译了主要内容,并进行了重新组织
摘要
Google提出了一种新型的语言表征模型BERT(Bidirectional Encoder Representations from Transformers)。ELMo只是在顶层连接左上下文和右上下文,OpenAI GPT只考虑左上下文,而BERT在每一层都融合了左上下文和右上下文,是一个预训练的深度双向表征。只需要在BERT上以微调方式增加一个输出层,就可以在11个NLP任务上取得了最新水平,包括:GLUE达到80.4%(提高了7.6%);MultiNLI达到86.7% (提高了5.6%);SQuAD v1.1 F1达到93.2 (提高了1.5),比人类还要高2.0。
1 引言
Google认为有两种方法可以将预训练的语言表征应用到下游NLP任务中:基于特征的方法和基于微调的方法。基于特征的方法是把语言表征作为下游特定任务模型的特征,例如ELMo;基于微调的方法是直接在语言表征模型的基础上微调,作为下游特定任务模型,例如OpenAI GPT。这两种方法都是使用无向语言模型来学习通用语言表征,这限制了预训练表征的能力,例如sentence-level任务中的局部最优,在token-level任务中微调是毁灭性的,需要双向上下文才能解决。
为此,Google提出了BERT。BERT引入两种新的机制:一是masked language model (MLM),它随机mask一些输入token,根据上下文预测mask的token;二是next sentence prediction(NSP)任务,它可以联合训练文本对表征。
Google认为他们有三点贡献:一是指出双向预训练语言表征的重要性;二是预训练表征不需要很重的特定任务架构,基于预训练表征架构微调即可应用到下游NLP任务中;三是BERT在11个NLP任务中取得最先进水平,并通过剥离实验证明双向表征起了最重要的作用。
2 相关工作
2.1 基于特征的方法
相比从零开始学习的词表征,预训练词表征作为下游NLP任务模型的特征使用,虽然下游NLP任务模型的参数需要从零开始训练,但是模型的性能有显著地提升。这些方法泛化到粗粒度的句表征和段表征。ELMo也是基于特征的方法,不过相比传统的词表征,ELMo是语境化的词表征,在一些NLP任务中取得了最先进水平,例如:问答、情感分析、命名实体识别等。
2.2 基于微调的方法
基于微调的方法也是一个趋势,它首先预训练语言模型架构,然后通过微调方式,将预训练的语言模型架构直接应用到下游NLP任务中。这样做的一个优点是:复用大多数参数,只有少量的参数需要从零开始训练。OpenAI GPT在GLUE基准的sentence-level任务中取得最先进水平。
2.3 监督数据迁移学习
一些研究表明,先在大型数据集上监督学习,然后迁移到其他任务上,也是有效的,例如自然语言推理、机器翻译。
3 BERT
3.1 模型架构
BERT是一个多层双向Transformer编码器,其中,层数记为L、隐含单元个数记为H、自我注意力头数记为A,前馈全连接单元个数记为4H。Google给出了两种模型:一是BERT_BASE:L=12,H=768,A=12,参数总个数为110M;二是BERT_LARGE:L=24,H=1024,A=16,参数总个数为340M。BERT_BASE大小同OpenAI GPT,主要是为了比较。BERT Transformer使用双向自我注意力模型,记作Transformer encoder,GPT Transformer使用单向自我注意力模型,记作Transformer decoder,EMLo在各层单独使用单向LSTM,在顶层连接双向LSTM,比较如图1所示。
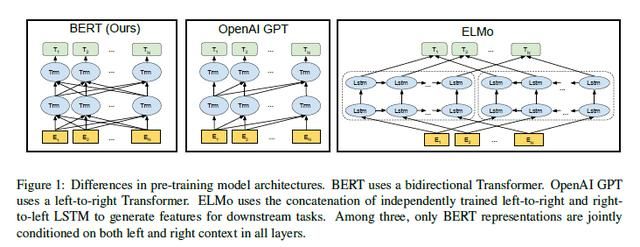
3.2 输入表征
输入表征由词表征(token embeddings)、段表征(segment embeddings)、位置表征(position embeddings)求和而来,如图2所示。
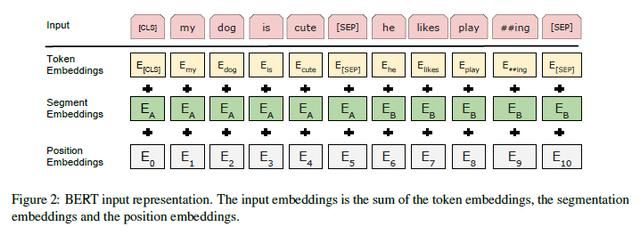
3.3 预训练任务
3.3.1 Task#1: Masked LM
为了训练一个深度双向表征,BERT模型会随机mask一定比例的输入token,这个过程叫masked LM(MLM)。在BERT中,mask比例为15%,相比auto-encoder,BERT只预测mask的token,而不是重构整个输入token。mask过程如下:80%机会使用[MASK],10%机会使用随机词,10%机会使用原词。
3.3.2 Task#2: NSP
语言模型无法直接捕获两条语句之间的关系,例如:问答、自然语言推理。BERT构造语句对A和B,其中B有50%概率是真实的,50%概率是假的。例如:
Input = [CLS] the man went to [MASK] store [SEP]
he bought a gallon [MASK] milk [SEP]
Label = IsNext
Input = [CLS] the man [MASK] to the store [SEP]
penguin [MASK] are flight ##less birds [SEP]
Label = NotNext
通过NSP,QA和NLI的精确度达到97%-98%。
3.4 预训练过程
BERT联合使用了BooksCorpus (800M words)和English Wikipedia (2,500M words)。语料库共有3.3 billion个词,使用40个epoch,每个epoch有1,000,000个批次,每个批次256个语句,每个语句512个token,即每批次128,000个token。使用Adam,其中,LR=1e-4,β1=0.9,β2=0.999,L2权重衰减为0.01,LR在前10,000步中逐渐上升,然后线性下降;所有层dropout概率为0.1;使用gelu激活函数;loss函数是平均masked LM似然和平均next sentence prediction似然之和。BERT_BASE使用4个Cloud TPU(16个TPU chips),BERT_LARGE使用16个Cloud TPU(64个TPU chips),训练需要4天。
3.5 微调过程
BERT微调和预训练的绝大多数超参是一样的,不一样的有:batch size、LR和epoch数量,dropout概率是依旧是0.1,批次大小为16、32,Adam学习率为5e-5、3e-5、2e-5,epoch数量为3、4。
3.6 BERT和OpenAI GPT比较
GPT的语料库是BooksCorpus (800M个单词)。BERT的语料库是BooksCorpus (800M 个单词) 和Wikipedia (2,500M个单词)。
GPT在微调阶段使用[SEP]分割语句,使用[CLS]分类token。BERT在预训练阶段使用[SEP]、[CLS]、A/B语句嵌入。
GPT使用1M个批次,每批次32,000个词。BERT使用1M个批次,每批次128,000个词。
GPT在所有微调任务中使用相同的学习率5e-5。BERT在不同的微调任务中使用不同的学习率。
4 评估
BERT在11个任务中取得了最先进水平,11个任务分四类,如图3所示:
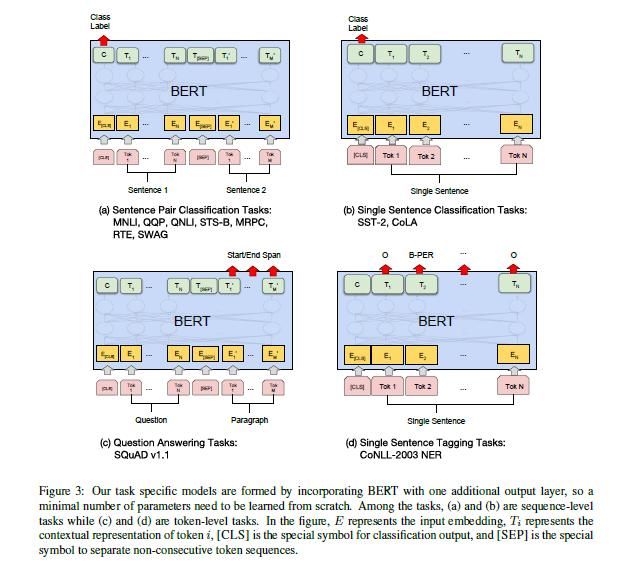
4.1 GLUE基准

4.2 SQuAD v1.1

4.3 命名实体识别

4.4 SWAG
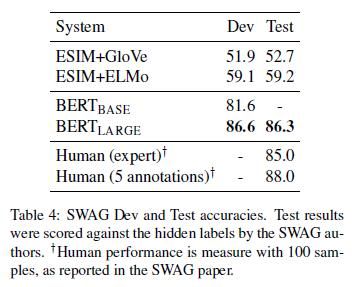
5 分析
5.1 预训练任务影响
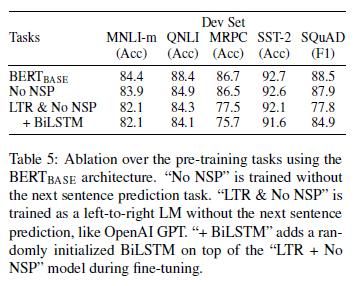
Masked LM和NSP是性能提升的关键,见表5:
5.2 模型大小影响
模型越大,性能越高,见表6:

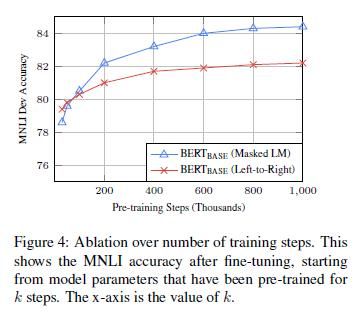
5.3 训练步数影响
以MNLI Dev为例,BERT_BASE确实需要大量预训练steps,因为500k steps到1M steps,精准度可以提升1.0%。另外,虽然MLM模型的收敛速度比LTR模型慢,但其性能很快就会超过LTR模型。
5.4 基于特征的BERT方法
基于特征的方法的优点是:不是所有的NLP任务都可以用Transformer encoder架构表示,需要任务相关的架构;学习表征需要花费大量的计算资源,只需要在预训练时计算一次,下游任务模型中可以直接用。实验结果表明,基于Sum Last Four Hidden的特征方法性能最高,为95.9,只比基于微调的方法少0.5,这说明BERT对微调和表征方法都适用。

6 总结
Google的一个主要贡献是,在大型数据集上,对深度双向架构进行预训练,通过微调迁移到下游NLP任务中,取得了最先进水平。虽然BERT很强大,但是还有一些NLP任务尚未解决,需要继续研究。