机器学习入门实战 -- Titanic乘客生还预测-易学智能GPU云
机器学习入门实战 -- Titanic乘客生还预测

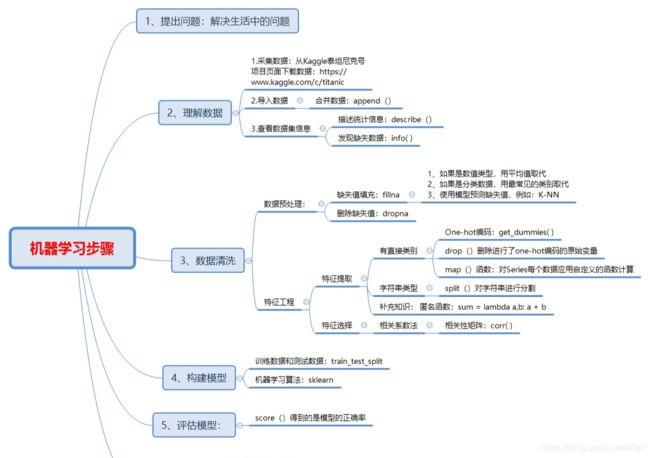
提出问题:
本文主要是对泰坦尼克号沉船事件进行预测:在当时的情况下,什么样的人更容易存活?
获取数据:
在Kaggle中泰坦尼克项目主界面的Data栏获取,有测试数据、训练数据和提交格式三个文件,本平台已在云端配置好相关数据,运行下面的代码块即可读取相应的数据集。
In [ ]:
#首先导入相关的python包 import pandas as pd import numpy as np import sklearn as sk
In [ ]:
#读取泰坦尼克数据集
import sys
sys.path.append('/home/ubuntu/MyFiles/PublicData/')
import os
import datasets_path
In [ ]:
#训练数据
train = pd.read_csv(datasets_path.titanic_train_dir)
#测试数据
test = pd.read_csv(datasets_path.titanic_test_dir)
print('训练集数量:',len(train), '测试集数量:',len(test))
In [ ]:
#合并两个数据集,对数据集进行数据清洗
Full = train.append(test)
print('合并后的数据集:',Full.shape)
数据清洗:
在处理数据之前,我们先观察数据的形式对数据有一个大概的理解
In [ ]:
#查看数据的前5行 Full.head()
查看数据集的统计信息,查看是否有异常数据。
In [ ]:
#按列获取数据类型的描述统计信息,非数字类型数据不会被统计 Full.describe()
按列查看数据关于不同特征属性的数量,检查数据是否有缺失值
In [ ]:
#查看每一列的数据类型和数据总数 Full.info()
可以看到船舱号(Cabin)缺失的数据较多,接下来需要对相应的特征属性补全缺失值。在这个例子中,对于数值型数据,我们采用平均值填补;非数值型采用众数填补。
In [ ]:
#票价(Fare)为数值型数据,缺失一条可以采用均值补充 Full['Fare'] = Full['Fare'].fillna(Full['Fare'].mean())
In [ ]:
#年龄(Age)同理 Full['Age'] = Full['Age'].fillna(Full['Age'].mean())
In [ ]:
#Embarked为非数值型数据,采用众数填充
print('众数:',Full['Embarked'].mode())
Full['Embarked'] = Full['Embarked'].fillna('S')
In [ ]:
#Cabin为字符串变量,用U补充表示UnKnown
Full['Cabin'] = Full['Cabin'].fillna('U')
In [ ]:
#查看填充结果 Full['Embarked'].value_counts()
对于字符型特征属性,需要转换为数值类型替代通常使用One-hot编码,比如性别(Sex)
In [ ]:
#对于特征属性(Sex),男(male = 1);女(female = 0)。
Sex_dict = {'male':1, 'female':0}
#下面使用map函数对数据进行转换,map函数对Series的内个数据元素应用自定义的函数计算
Full['Sex'] = Full['Sex'].map(Sex_dict)
Full.head()
#One-hot编码是对操作2个类别以上的采集型编码,因为性别只有两个类别,所以不需要使用One-hot编码。
使用数据框的get_dummies( )方法可以实现One-hot编码。所以,重编码后新的特征,需要新建一个数据框存储下来:
Embarked的值分别为S,C,Q
In [ ]:
Full['Embarked'].head()
In [ ]:
embarkerDF = pd.DataFrame() embarkerDF = pd.get_dummies(Full['Embarked'], prefix='Embarked') embarkerDF.head()
添加One-hot编码产生的虚拟变量到数据集Full,并将原有的Embarked属性删除
In [ ]:
Full = pd.concat([Full, embarkerDF], axis=1)
#删除Embarked
Full.drop('Embarked', axis=1, inplace=True)
Full.head()
接下来处理特征属性Name
In [ ]:
#定义函数,从姓名中提取头衔
def getTitle(name):
Name = name.split(',')[1] #split按指定符号分割字符串
title = Name.split('.')[0]
Title = title.strip() #移除字符串首尾制定的字符默认为空格
return Title
In [ ]:
#同上,先新建一个数据框存放处理后的数据 titleDF = pd.DataFrame() titleDF['Title'] = Full['Name'].map(getTitle) titleDF['Title'].head(),Full['Name'].head()
In [ ]:
'''
数据集中的头衔有很多,为了简化我们将其映射为下面几种头衔类别,并对其One-hot处理
例如:Ms已婚男士,Mrs已婚女士,Officer政府官员,Royalty皇室成员,Miss年轻未婚女子,Master有技能的人员
'''
title_dict = {'Capt':'Officer',
'Col': 'Officer',
'Major':'Officer',
'Jonkheer':'Royalty',
'Don':'Royalty',
'Sir':'Royalty',
'Dr':'Officer',
'Rev':'Officer',
'the Countess':'Royalty',
'Dona':'Royalty',
'Mme':'Mrs',
'Mlle':'Miss',
'Ms':'Mrs',
'Mr':'Mr',
'Mrs':'Mrs',
'Miss':'Miss',
'Master':'Master',
'Lady':'Royalty'}
titleDF['Title'] = titleDF['Title'].map(title_dict)
titleDF = pd.get_dummies(titleDF['Title'])
titleDF.head()
In [ ]:
#将titleDF添加到Full数据集并删除特征属性Name
Full = pd.concat([Full,titleDF], axis=1)
Full.drop('Name', axis=1, inplace=True)
Full.head()
In [ ]:
#家庭情况信息处理 familyDF = pd.DataFrame() familyDF['family_size'] = Full['Parch'] + Full['SibSp'] + 1#家庭人数=同代亲属(Parch)+不同代亲属(SibSp)+乘客本身 familyDF['family_single'] = familyDF['family_size'].map(lambda s:1 if s==1 else 0) familyDF['family_small'] = familyDF['family_size'].map(lambda s:1 if 2<=s<=4 else 0) familyDF['family_large'] = familyDF['family_size'].map(lambda s:1 if s>4 else 0) familyDF.head()
In [ ]:
Full = pd.concat([Full, familyDF], axis=1) Full.head()
特征选择:
选取原则:根据所有变量的相关系数矩阵,筛选出与预测标签Survived最相关的特征变量。
In [ ]:
corrDF = Full.corr() corrDF
这里选择‘Survived’列,按列降序排列,就能看到哪些特征最正相关,哪些特征最负相关,将其筛选出来作为模型的特征输入。
In [ ]:
#按相关系数降序排列 corrDF['Survived'].sort_values(ascending = False)
选择title_df, pclass_df, family_df, Fare, cabin_df, Sex作为特征。
构建整体数据集的特征数据框full_x(包含1309行整体数据集特征),再使用loc属性拆分出891行原始数据集特征source_x和标签source_y、481行测试数据集特征test_x:
In [ ]:
Full_X = pd.concat([titleDF,
Full['Pclass'],
familyDF,
Full['Fare'],
embarkerDF,
Full['Sex'],
Full['Age']], axis=1)
Full_X.head()
建立模型
建模的时候,需要将原始数据集进行二八拆分:80%训练集+20%测试集。
训练集用于训练模型;测试集用于评估模型效果。
建模:
因为本例没有测试集的真实标记,所以从训练集中拆分出训练集和验证集以调整我们的模型。(可以上传模型提交到Kaggle验证自己模型的效果)
In [ ]:
#训练集特征属性 Row = 891 data_x = Full_X.loc[:Row-1,:] #训练集标签 data_y = Full.loc[:Row-1, 'Survived'] predict_x = Full_X.iloc[Row:, :] #loc会从0开始选取到指定的位置,所以Row需要减1
In [ ]:
data_x.shape,data_y.shape,predict_x.shape
依据8:2的比例划分训练集与验证集的数量
In [ ]:
from sklearn.cross_validation import train_test_split
#划分训练集与验证集
train_x, val_x, train_y, val_y = train_test_split(data_x,
data_y,
train_size=0.8)
开始训练一个机器学习算法
这里我们选择较为简单的逻辑回归算法
In [ ]:
#导入算法 from sklearn.linear_model import LogisticRegression #建立模型 model = LogisticRegression(C=1, max_iter=100)
In [ ]:
#训练模型 model.fit(train_x, train_y)
评估模型:
使用model.score方法,通过测试集得到模型预测准确率。
In [ ]:
model.score(val_x, val_y)
保存结果上传到Kaggle看看结果如何¶
In [ ]:
pred_y = model.predict(predict_x)
pred_y = pred_y.astype(int)
passenger_id = Full.iloc[891:,4]
predDF = pd.DataFrame({'PassengerId':passenger_id,
'Survived':pred_y})
predDF.shape
predDF.head()
In [ ]:
predDF.to_csv('titanic_pred.csv', index=False)
期待你们更好的成绩
易学智能云平台任一主机后可体验本案例的操作与交互式运行效果。传送门https://www.easyaiforum.cn/instanceList
更多学习案例请访问https://www.easyaiforum.cn/case