Self-Attention概念详解
一、Self-Attention概念详解
Self-Attention详解
了解了模型大致原理,我们可以详细的看一下究竟Self-Attention结构是怎样的。其基本结构如下
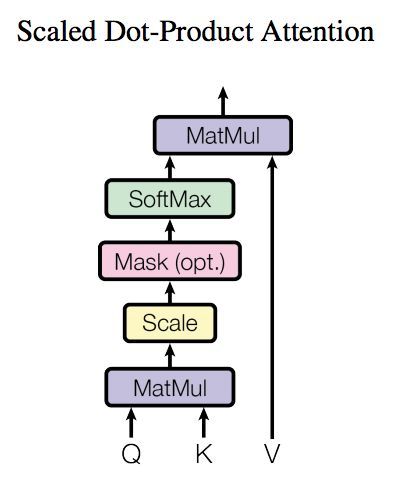

上述attention可以被描述为将query和key-value键值对的一组集合映到输出,其中 query,keys,values和输出都是向量,其中 query和keys的维度均为dk,values的维度为dv (论文中dk=dv=dm/h)(h为多头的数量,concate之后正好恢复原长度),输出被计算为values的加权和,其中分配给每个value的权重由query与对应key的相似性函数计算得来。这种attention的形式被称为“Scaled Dot-Product Attention”
这里可能比较抽象,我们来看一个具体的例子(图片来源于https://jalammar.github.io/illustrated-transformer/,该博客讲解的极其清晰,强烈推荐),假如我们要翻译一个词组Thinking Machines,其中Thinking的输入的embedding vector用X1表示,Machines的embedding vector用X2表示。
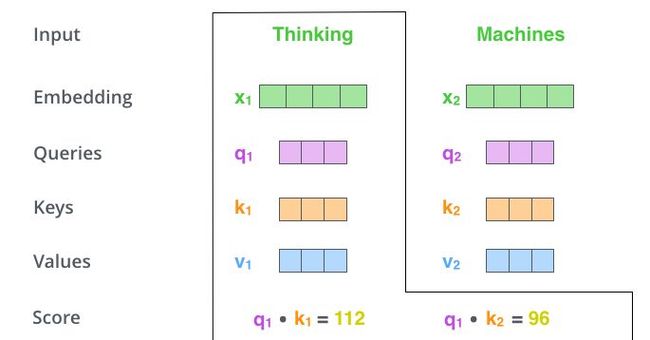
当我们处理Thinking这个词时,我们需要计算句子中所有词与它的Attention Score,这就像将当前词作为搜索的query,去和句子中所有词(包含该词本身)的key去匹配,看看相关度有多高。我们用q1代表Thinking对应的query vector,k1和k2分别代表Thinking以及Machines对应的key vector,则计算Thinking的attention score的时候我们需要计算q1与k1,k2的点乘,同理,我们计算Machines的attention score的时候需要计q2与k1,k2的点乘。如上图中所示我们分别得到q1与k1,k2的点乘积,然后我们进行尺度缩放与softmax归一化,如下图所示:
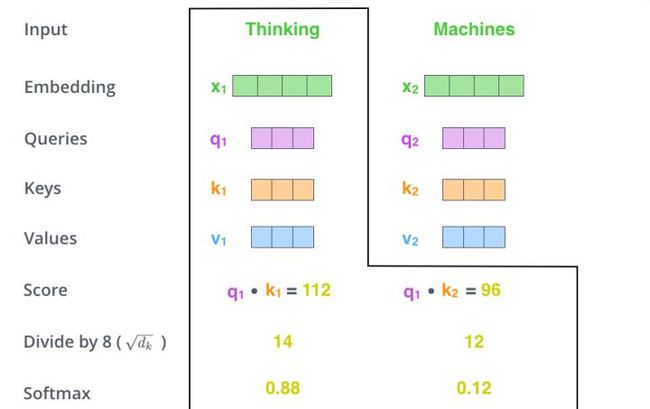
显然,当前单词与其自身的attention score一般最大,其他单词根据与当前单词重要程度有相应的score。然后我们在用这些attention score与value vector相乘,得到加权的向量。
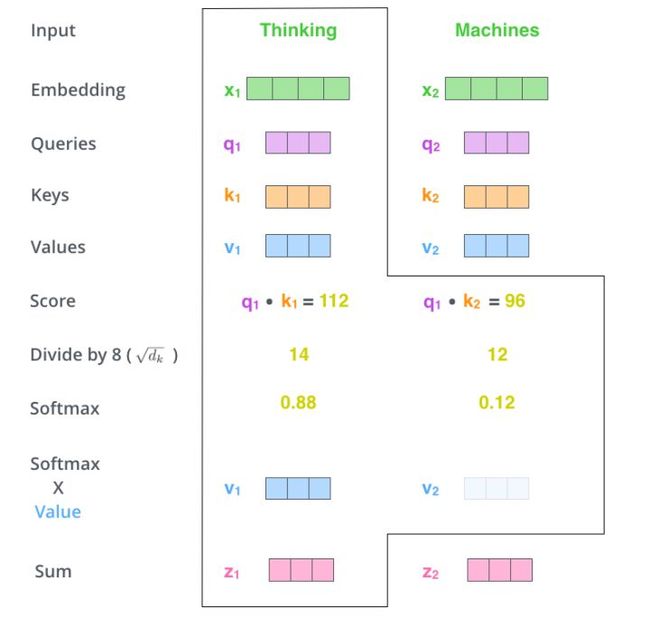
如果将输入的所有向量合并为矩阵形式,则所有query, key, value向量也可以合并为矩阵形式表示
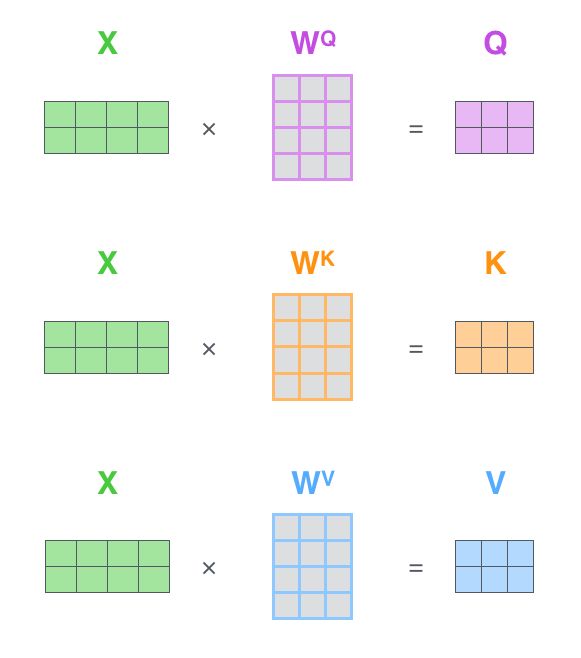
其中 是我们模型训练过程学习到的合适的参数。上述操作即可简化为矩阵形式

二、Self_Attention模型搭建
笔者使用Keras来实现对于Self_Attention模型的搭建,由于网络中间参数量比较多,这里采用自定义网络层的方法构建Self_Attention,关于如何自定义Keras可以参看这里:编写你自己的 Keras 层
Keras实现自定义网络层。需要实现以下三个方法:(注意input_shape是包含batch_size项的)
build(input_shape): 这是你定义权重的地方。这个方法必须设self.built = True,可以通过调用super([Layer], self).build()完成。call(x): 这里是编写层的功能逻辑的地方。你只需要关注传入call的第一个参数:输入张量,除非你希望你的层支持masking。compute_output_shape(input_shape): 如果你的层更改了输入张量的形状,你应该在这里定义形状变化的逻辑,这让Keras能够自动推断各层的形状。
实现代码如下:
#%%
from keras.preprocessing import sequence
from keras.datasets import imdb
from matplotlib import pyplot as plt
import pandas as pd
from keras import backend as K
from keras.engine.topology import Layer
class Self_Attention(Layer):
def __init__(self, output_dim, **kwargs):
self.output_dim = output_dim
super(Self_Attention, self).__init__(**kwargs)
def build(self, input_shape):
# 为该层创建一个可训练的权重
#inputs.shape = (batch_size, time_steps, seq_len)
self.kernel = self.add_weight(name='kernel',
shape=(3,input_shape[2], self.output_dim),
initializer='uniform',
trainable=True)
super(Self_Attention, self).build(input_shape) # 一定要在最后调用它
def call(self, x):
WQ = K.dot(x, self.kernel[0])
WK = K.dot(x, self.kernel[1])
WV = K.dot(x, self.kernel[2])
print("WQ.shape",WQ.shape)
print("K.permute_dimensions(WK, [0, 2, 1]).shape",K.permute_dimensions(WK, [0, 2, 1]).shape)
QK = K.batch_dot(WQ,K.permute_dimensions(WK, [0, 2, 1]))
QK = QK / (self.output_dim**0.5)
QK = K.softmax(QK)
print("QK.shape",QK.shape)
V = K.batch_dot(QK,WV)
return V
def compute_output_shape(self, input_shape):
return (input_shape[0],input_shape[1],self.output_dim)
max_features = 20000
print('Loading data...')
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features)
#标签转换为独热码
y_train, y_test = pd.get_dummies(y_train),pd.get_dummies(y_test)
print(len(x_train), 'train sequences')
print(len(x_test), 'test sequences')
#%%数据归一化处理
maxlen = 64
print('Pad sequences (samples x time)')
x_train = sequence.pad_sequences(x_train, maxlen=maxlen)
x_test = sequence.pad_sequences(x_test, maxlen=maxlen)
print('x_train shape:', x_train.shape)
print('x_test shape:', x_test.shape)
#%%
batch_size = 32
from keras.models import Model
from keras.optimizers import SGD,Adam
from keras.layers import *
from Attention_keras import Attention,Position_Embedding
S_inputs = Input(shape=(64,), dtype='int32')
embeddings = Embedding(max_features, 128)(S_inputs)
O_seq = Self_Attention(128)(embeddings)
O_seq = GlobalAveragePooling1D()(O_seq)
O_seq = Dropout(0.5)(O_seq)
outputs = Dense(2, activation='softmax')(O_seq)
model = Model(inputs=S_inputs, outputs=outputs)
print(model.summary())
# try using different optimizers and different optimizer configs
opt = Adam(lr=0.0002,decay=0.00001)
loss = 'categorical_crossentropy'
model.compile(loss=loss,
optimizer=opt,
metrics=['accuracy'])
#%%
print('Train...')
h = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=5,
validation_data=(x_test, y_test))
plt.plot(h.history["loss"],label="train_loss")
plt.plot(h.history["val_loss"],label="val_loss")
plt.plot(h.history["acc"],label="train_acc")
plt.plot(h.history["val_acc"],label="val_acc")
plt.legend()
plt.show()
#model.save("imdb.h5")这里可以对照一中的概念讲解来理解代码
如果将输入的所有向量合并为矩阵形式,则所有query, key, value向量也可以合并为矩阵形式表示
上述内容对应
WQ = K.dot(x, self.kernel[0])
WK = K.dot(x, self.kernel[1])
WV = K.dot(x, self.kernel[2])其中
是我们模型训练过程学习到的合适的参数。上述操作即可简化为矩阵形式
上述内容对应(为什么使用batch_dot呢?这是由于input_shape是包含batch_size项的)
QK = K.batch_dot(WQ,K.permute_dimensions(WK, [0, 2, 1]))
QK = QK / (self.output_dim**0.5)
QK = K.softmax(QK)
print("QK.shape",QK.shape)
V = K.batch_dot(QK,WV)这里 QK = QK / (self.output_dim**0.5)是除以一个归一化系数。
三、训练网络
项目完整代码如下,这里使用的是Keras自带的imdb影评数据集
#%%
from keras.preprocessing import sequence
from keras.datasets import imdb
from matplotlib import pyplot as plt
import pandas as pd
from keras import backend as K
from keras.engine.topology import Layer
class Self_Attention(Layer):
def __init__(self, output_dim, **kwargs):
self.output_dim = output_dim
super(Self_Attention, self).__init__(**kwargs)
def build(self, input_shape):
# 为该层创建一个可训练的权重
#inputs.shape = (batch_size, time_steps, seq_len)
self.kernel = self.add_weight(name='kernel',
shape=(3,input_shape[2], self.output_dim),
initializer='uniform',
trainable=True)
super(Self_Attention, self).build(input_shape) # 一定要在最后调用它
def call(self, x):
WQ = K.dot(x, self.kernel[0])
WK = K.dot(x, self.kernel[1])
WV = K.dot(x, self.kernel[2])
print("WQ.shape",WQ.shape)
print("K.permute_dimensions(WK, [0, 2, 1]).shape",K.permute_dimensions(WK, [0, 2, 1]).shape)
QK = K.batch_dot(WQ,K.permute_dimensions(WK, [0, 2, 1]))
QK = QK / (self.output_dim**0.5)
QK = K.softmax(QK)
print("QK.shape",QK.shape)
V = K.batch_dot(QK,WV)
return V
def compute_output_shape(self, input_shape):
return (input_shape[0],input_shape[1],self.output_dim)
max_features = 20000
print('Loading data...')
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features)
#标签转换为独热码
y_train, y_test = pd.get_dummies(y_train),pd.get_dummies(y_test)
print(len(x_train), 'train sequences')
print(len(x_test), 'test sequences')
#%%数据归一化处理
maxlen = 64
print('Pad sequences (samples x time)')
x_train = sequence.pad_sequences(x_train, maxlen=maxlen)
x_test = sequence.pad_sequences(x_test, maxlen=maxlen)
print('x_train shape:', x_train.shape)
print('x_test shape:', x_test.shape)
#%%
batch_size = 32
from keras.models import Model
from keras.optimizers import SGD,Adam
from keras.layers import *
S_inputs = Input(shape=(64,), dtype='int32')
embeddings = Embedding(max_features, 128)(S_inputs)
O_seq = Self_Attention(128)(embeddings)
O_seq = GlobalAveragePooling1D()(O_seq)
O_seq = Dropout(0.5)(O_seq)
outputs = Dense(2, activation='softmax')(O_seq)
model = Model(inputs=S_inputs, outputs=outputs)
print(model.summary())
# try using different optimizers and different optimizer configs
opt = Adam(lr=0.0002,decay=0.00001)
loss = 'categorical_crossentropy'
model.compile(loss=loss,
optimizer=opt,
metrics=['accuracy'])
#%%
print('Train...')
h = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=5,
validation_data=(x_test, y_test))
plt.plot(h.history["loss"],label="train_loss")
plt.plot(h.history["val_loss"],label="val_loss")
plt.plot(h.history["acc"],label="train_acc")
plt.plot(h.history["val_acc"],label="val_acc")
plt.legend()
plt.show()
#model.save("imdb.h5")
四、结果输出
(TF_GPU) D:\Files\DATAs\prjs\python\tf_keras\transfromerdemo>C:/Files/APPs/RuanJian/Miniconda3/envs/TF_GPU/python.exe d:/Files/DATAs/prjs/python/tf_keras/transfromerdemo/train.1.py
Using TensorFlow backend.
Loading data...
25000 train sequences
25000 test sequences
Pad sequences (samples x time)
x_train shape: (25000, 64)
x_test shape: (25000, 64)
WQ.shape (?, 64, 128)
K.permute_dimensions(WK, [0, 2, 1]).shape (?, 128, 64)
QK.shape (?, 64, 64)
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 64) 0
_________________________________________________________________
embedding_1 (Embedding) (None, 64, 128) 2560000
_________________________________________________________________
self__attention_1 (Self_Atte (None, 64, 128) 49152
_________________________________________________________________
global_average_pooling1d_1 ( (None, 128) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 128) 0
_________________________________________________________________
dense_1 (Dense) (None, 2) 258
=================================================================
Total params: 2,609,410
Trainable params: 2,609,410
Non-trainable params: 0
_________________________________________________________________
None
Train...
Train on 25000 samples, validate on 25000 samples
Epoch 1/5
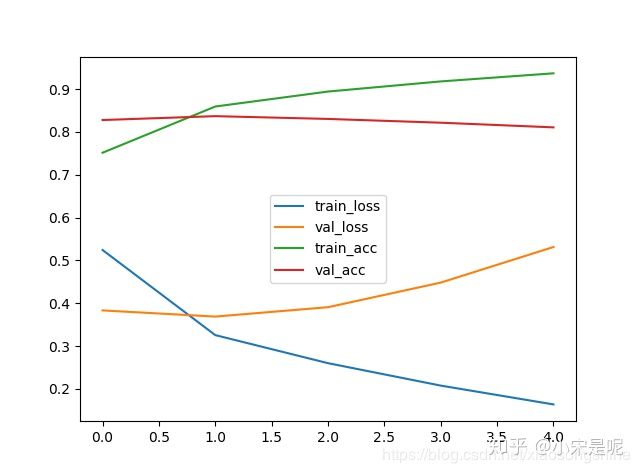
25000/25000 [==============================] - 17s 693us/step - loss: 0.5244 - acc: 0.7514 - val_loss: 0.3834 - val_acc: 0.8278
Epoch 2/5
25000/25000 [==============================] - 15s 615us/step - loss: 0.3257 - acc: 0.8593 - val_loss: 0.3689 - val_acc: 0.8368
Epoch 3/5
25000/25000 [==============================] - 15s 614us/step - loss: 0.2602 - acc: 0.8942 - val_loss: 0.3909 - val_acc: 0.8303
Epoch 4/5
25000/25000 [==============================] - 15s 618us/step - loss: 0.2078 - acc: 0.9179 - val_loss: 0.4482 - val_acc: 0.8215
Epoch 5/5
25000/25000 [==============================] - 15s 619us/step - loss: 0.1639 - acc: 0.9368 - val_loss: 0.5313 - val_acc: 0.8106
五、Reference
1.https://zhuanlan.zhihu.com/p/47282410
https://zhuanlan.zhihu.com/p/67115572
https://zhuanlan.zhihu.com/p/82391768 transformer介绍