TextCNN模型原理及理解
1.概要
TEXTCNN是由Yoon Kim在论文(2014 EMNLP) Convolutional Neural Networks for Sentence Classification中提出的,其主要思想是将不同长度的短文作为矩阵输入,使用多个不同size的filter去提取句子中的关键信息(类似于多窗口大小的ngram),并用于最终的分类。
2.网络结构
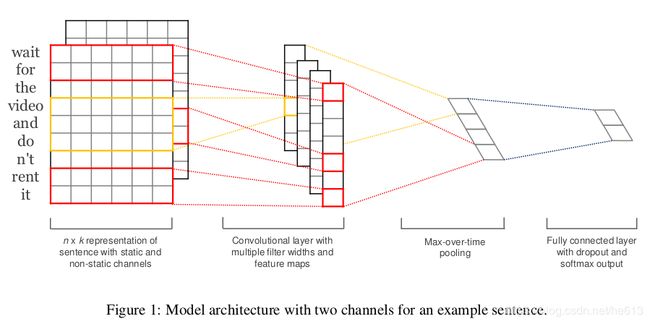
输入层:
文本矩阵。
对于文本中的词语可先构建大的词库集,用word2vec进行训练,获取得到每个词语的词向量,所有词向量拼接能够得到对应的文本矩阵。
注意点:
特征:这里用的是词向量表示方式
数据量较大:可以直接随机初始化embeddings,然后基于语料通过训练模型网络来对embeddings进行更新和学习。
数据量较小:可以利用外部语料来预训练(pre-train)词向量,然后输入到Embedding层,用预训练的词向量矩阵初始化embeddings。(通过设置weights=[embedding_matrix])。
(1)static(静态词向量)
使用预训练的词向量,即利用word2vec、fastText或者Glove等词向量工具,在开放领域数据上进行无监督的学习,获得词汇的具体词向量表示方式,拿来直接作为输入层的输入,并且在TextCNN模型训练过程中不再调整词向量, 这属于迁移学习在NLP领域的一种具体的应用。
(2)non-static(非静态词向量)
在训练过程中对embeddings进行更新和微调(fine tune),能加速收敛。(通过设置trainable=True)。预训练的词向量+ 动态调整 , 即拿word2vec训练好的词向量初始化, 训练过程中再对词向量进行微调。
(3)multiple channel(多通道)
借鉴图像中的RGB三通道的思想, 这里也可以用 static 与 non-static 两种词向量初始化方式来搭建两个通道。
(4)CNN-rand(随机初始化)
指定词向量的维度embedding_size后,文本分类模型对不同单词的向量作随机初始化, 后续有监督学习过程中,通过BP的方向更新输入层的各个词汇对应的词向量。
卷积层:
使用不同的卷积核,卷积核的宽度和词向量的长度一致,每个卷积核获得一列feature map.
Max-pooling:
每个feature map通过 max-pooling都会得到一个特征值,这个操作也使得TextCNN能处理不同长度的文本。
全连接层:
该层的输入为池化操作后形成的一维向量,经过激活函数输出,再加上Dropout层防止过拟合。并在全连接层上添加l2正则化参数。
Softmax:
将全连接层的输出使用softmax函数,获取文本分到不同类别的概率。
3.直观解释
我们知道图像处理中卷积的作用是在整幅图像中计算各个局部区域与卷积核的相似度,一般前几层的卷积核是可以很方便地做可视化的,可视化的结果是前几层的卷积核是在原始输入图像中寻找一些简单的线条。NLP中的卷积核没法做可视化,那么是不是就不能理解他在做什么了呢,其实可以通过模型的结构来来推断他的作用。因为TextCNN中卷积过后直接就是全局max pooling,那么它只能是在卷积的过程中计算与某些关键词的相似度,然后通过max pooling层来得出模型关注那些关键词是否在整个输入文本中出现,以及最相似的关键词与卷积核的相似度最大有多大。我们假设中文输出为字向量,理想情况下一个卷积核代表一个关键词,如下图所示:
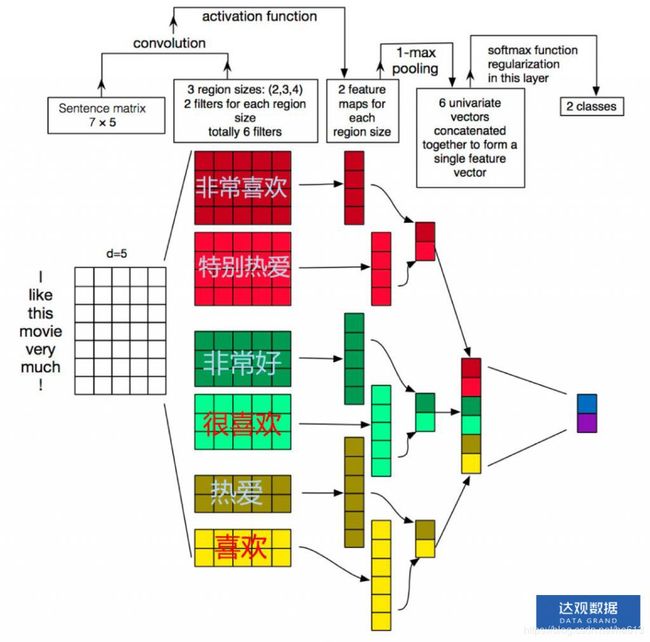
比如说一个2分类舆情分析任务中,如果把整个模型当成一个黑箱,那么去检测他的输出结果,会发现这个模型对于输入文本中是否含有“喜欢”,“热爱”这样的词特别敏感,那么他是怎么做到的呢?整个模型中能够做到遍历整个句子去计算关键词相似度的只有卷积的部分,因为后面直接是对整个句子长度的max pooling。但是因为模型面对的是字向量,并不是字,所以他一个卷积核可能是只学了半个关键词词向量,然后还有另外的卷积核学了另外半个关键词词向量,最后在分类器的地方这些特征值被累加得到了最终的结果。
TextCNN模型最大的问题也是这个全局的max pooling丢失了结构信息,因此很难去发现文本中的转折关系等复杂模式,TextCNN只能知道哪些关键词是否在文本中出现了,以及相似度强度分布,而不可能知道哪些关键词出现了几次以及出现这些关键词出现顺序。假想一下如果把这个中间结果给人来判断,人类也很难得到对于复杂文本的分类结果,所以机器显然也做不到。针对这个问题,可以尝试k-max pooling做一些优化,k-max pooling针对每个卷积核都不只保留最大的值,他保留前k个最大值,并且保留这些值出现的顺序,也即按照文本中的位置顺序来排列这k个最大值。在某些比较复杂的文本上相对于1-max pooling会有提升。
此外,在文本分类中,我们常常会遇到类别不均衡的问题,可更改相应的损失函数,如引入Focal Loss,更关注于困难的、错分样本的分类。
参考文献:
1.Kim, Yoon. "Convolutional Neural Networksfor Sentence Classification." Proceedings of the 2014 Conferenceon Empirical Methods in Natural Language Processing (EMNLP). 2014.
2.达观数据曾彦能:如何用深度学习做好长文本分类与法律文书智能化处理
3.[NLP] TextCNN模型原理和实现
4.深度学习(十五) TextCNN理解
5.吾爱NLP(4)—基于Text-CNN模型的中文文本分类实战