《零基础入门数据挖掘 - 二手车交易价格预测》Task4:建模与调参
经过Task 2 EDA和Task 3特征工程后,已经准备好数据,下面是开始建模和调参的过程。
Step 1:导入函数工具箱
## 基础工具
import numpy as np
import pandas as pd
import warnings
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.special import jn
from IPython.display import display, clear_output
import time
warnings.filterwarnings('ignore')
%matplotlib inline
## 模型预测的
from sklearn import linear_model
from sklearn import preprocessing
from sklearn.svm import SVR
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor
## 数据降维处理的
from sklearn.decomposition import PCA, FastICA, FactorAnalysis, SparsePCA
import lightgbm as lgb
import xgboost as xgb
## 参数搜索和评价的
from sklearn.model_selection import GridSearchCV, cross_val_score, StratifiedKFold, train_test_split
from sklearn.metrics import mean_squared_error, mean_absolute_error
Step 2:数据读取
在任务3:特征工程中我们已经准备好了数据,并保存在子目录output中。
1) 导入数据
# 从特征工程存储的数据文件中读取数据
data = pd.read_csv('.\output\data_for_tree-V2.csv')
2) 数据拆分
# 训练集和测试集放在一起,需要拆分
Train_data = data.loc[data.train == 1]
Test_data = data.loc[data.train == 0]
3) 构建训练和测试样本
# 从导入数据构造训练样本和测试样本
X_data = Train_data.drop(['price', 'train'], axis=1)
Y_data = Train_data['price']
X_test = Test_data.drop(['price', 'train'], axis=1)
print(('X train shape:', X_data.shape))
print(('X test shape:', X_test.shape))
4) 创建统计函数
## 定义了一个统计函数,方便后续信息统计
def Statistics_inf(data):
print('_min', np.min(data))
print('_max:', np.max(data))
print('_mean', np.mean(data))
print('_ptp', np.ptp(data))
print('_std', np.std(data))
print('_var', np.var(data))
5) 统计标签的基本分布信息
print('Statistics of label:')
Statistics_inf(Y_data)
## 绘制标签的统计图,查看标签分布
matplotlib.rcParams['figure.figsize'] = (12.0, 6.0)
prices1 = pd.DataFrame({"Price": Y_data})
prices1.hist()
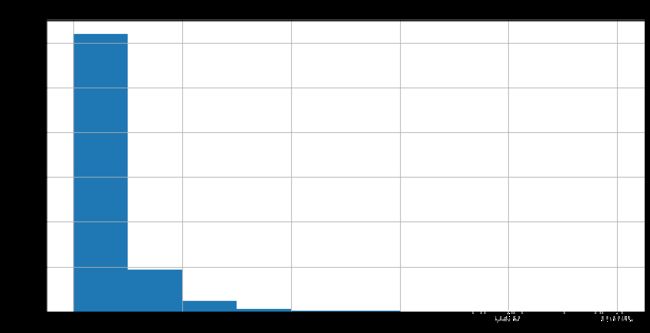
6) 缺省值用-1填补
X_data = X_data.fillna(-1)
X_test = X_test.fillna(-1)
Step 3:模型训练与预测
1) 定义随机森林RF模型函数
forest = RandomForestRegressor(criterion='mse',
n_estimators=100,
max_depth=20,
min_samples_split=2,
min_samples_leaf=2,
random_state=10,
n_jobs=-1)
2)切分数据集(Train、Val)进行模型训练,评价和预测
# Split data with validation,
# Test data set is 50000, split train data set 33% to validation data set
x_train, x_val, y_train, y_val = train_test_split(X_data,
Y_data,
test_size=0.33)
3) RF进行模型训练和预测
训练、验证
print('Training rf...')
forest.fit(x_train, y_train)
val_rf = forest.predict(x_val)
MAE_rf = mean_absolute_error(y_val, val_rf)
print('MAE of val with rf:', (MAE_rf))
结果如下图:
![]()
训练、预测
print('Predicting rf...')
forest.fit(X_data, Y_data)
sub_rf = forest.predict(X_test)
print('Statistics of Predict RF:')
Statistics_inf(sub_rf)
结果如下图:
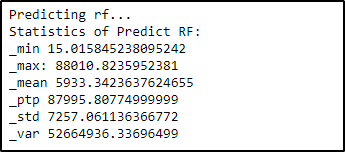
查看预测结果的统计图,从图中可以看出和训练数据集有相似的分布。

4) 输出结果
sub = pd.DataFrame()
sub['SaleID'] = Test_data.SaleID
sub['price'] = sub_rf
sub.to_csv('.\sub\sub-V15-LR-RF-1.csv', index=False)
检查输出结果的前5行
sub.head()
格式正确。

总结
由于对特征工程不是很熟悉,结果不是很好,并且随机森林的学习能力比XGBoost和LightGBM略差。
特征工程、模型、调参都有进一步改善的空间。