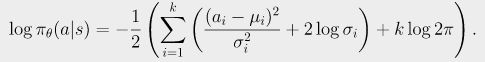强化学习系列之翻译OpenAI用户手册(三)
强化学习系列文章
第一章 强化学习入门
第二章 翻译OpenAI用户手册(一)
第三章 翻译OpenAI用户手册(二)
第四章 翻译OpenAI用户手册(三)
目录
1. 强化学习中的关键概念
1.1 强化学习能做什么?
1.2 关键的概念和术语
1.3 状态和观察
1.4 行为空间
1.5 策略
1.6 确定性策略
1.7 随机策略
1. 强化学习中的关键概念
欢迎来到我们关于强化学习的介绍!在此,我们旨在使您熟悉:
- 用来讨论这个问题的语言和符号,
- 对强化学习算法的作用做了一个高层次的解释(尽管我们通常避免讨论它们是如何做到这一点的),
- 还有一些算法基础上的核心数学。
简而言之,强化学习就是研究智能体以及它们如何通过尝试和错误来学习。它将奖励或惩罚智能体的行为使其更有可能在未来重复或放弃该行为这一观点规则化。
1.1 强化学习能做什么?
深度学习方法最近获得了各种各样的成功。例如,它被用来教计算机在模拟中控制机器人……或者在真实世界中。


它还被用于为复杂的战略游戏创造突破性的人工智能,最著名的是围棋Alphago和Dota,它教计算机从原始像素玩雅达利游戏,训练模拟机器人遵循人类的指令。
1.2 关键的概念和术语

图1 智能体和环境交互循环
深度学习的主要特征是agent和environment。环境是agent生活和相互作用的世界。在交互的每一步中,agent看到对世界状态的观察(可能是部分的),然后决定要采取的行动。当智能体对环境起作用时环境会发生变化,但环境本身也可能发生变化。
agent还会感知到来自环境的奖励信号,这个数字告诉它当前世界的状态是好是坏。代理人的目标是最大化其累积报酬,称为回报。强化学习方法是agent通过学习行为来实现其目标的方法。
为了更具体地讨论深度学习是做什么的,我们需要引入额外的术语。我们得谈谈如下几个术语:
- 状态和观察;
- 行为空间;
- 策略;
- 轨迹;
- 不同的回报公式;
- 强化学习最优化问题;
- 值函数。
1.3 状态和观察
状态s是一个是对世界状态的完整描述。世界上没有什么信息是瞒着状态的。
观察o是对状态的部分描述,可能会省略一些信息。
在深度强化学习中,我们几乎总是用实值向量、矩阵或高阶张量来表示状态和观测值。例如,一个视觉观察可以用其像素值的RGB矩阵来表示;机器人的状态可以用它的关节角和速度来表示。
当智能体能够观察到环境的完整状态时,我们说环境是完全观察到的。当智能体只能看到部分观察,我们说环境是部分观察。
你应该知道的:
强化学习符号有时会把状态s的符号,放在技术上更适合为观察o写符号的地方。具体地说,当我们讨论智能体如何决定一个行为时,这种情况就会发生:我们通常用符号表示行为取决于状态,而实际上,行为取决于观察,因为智能体无法访问状态。
在我们的指南中,我们将遵循表示法的标准约定,但是从上下文的含义来看应该是清楚的。如果有不清楚的地方,请提出问题!我们的目标是教导,而不是混淆。
1.4 行为空间
不同的环境允许不同类型的操作。给定环境中所有有效操作的集合通常称为行为空间。一些环境,如Atari和Go,具有离散的动作空间,其中只有有限数量的动作可供代理使用。其他环境,比如agent在物理世界中控制机器人的环境,具有连续的动作空间。在连续空间中,动作是实值向量。
这种区别对于深度强化学习中的方法有一些非常深刻的影响。有些算法家族只能直接应用于一种情况,而必须为另一种情况进行大量的修改。
1.5 策略
策略是agent用来决定采取什么行动的规则。它可以是确定性的,在这种情况下,它通常表示为:
![]()
也可以是随机的,通常用π表示:
![]()
因为策略本质上是智能体的大脑,用“策略”这个词代替“智能体”是很常见的,比如说“策略试图最大化回报”。
在深度强化学习中,我们处理参数化策略:策略的输出是可计算的函数,依赖于一组参数(如神经网络的权重和偏差),我们可以通过一些优化算法调整这些参数来改变行为。
我们经常用![]() 来表示这种政策的参数,然后将其作为下标写入策略符号,以突出显示连接:
来表示这种政策的参数,然后将其作为下标写入策略符号,以突出显示连接:
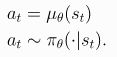
1.6 确定性策略
例子:确定性的政策。下面是使用 torch.nn包为PyTorch中的连续操作空间构建简单的确定性策略的代码片段。
pi_net = nn.Sequential(
nn.Linear(obs_dim, 64),
nn.Tanh(),
nn.Linear(64, 64),
nn.Tanh(),
nn.Linear(64, act_dim)
)
这构建了一个多层感知器(MLP)网络,它有两个大小为64的隐藏层和tanh激活函数。如果obs是一个包含一批观测数据的Numpy数组,则可以使用pi_net来获取一批操作,具体如下:
obs_tensor = torch.as_tensor(obs, dtype=torch.float32)
actions = pi_net(obs_tensor)
你应该知道的:
如果您不熟悉神经网络的内容,请不必担心——本教程将关注强化学习,而不是神经网络方面的内容。因此,您可以跳过这个示例,稍后再回到它。但我们认为,如果你已经知道了,这可能会有帮助。
1.7 随机策略
深度强化学习中最常见的两种随机策略是分类策略和对角高斯策略。
分类策略可用于离散行动空间,对角高斯策略可用于连续行动空间。
在使用和训练随机策略时,两个关键的计算是至关重要的:
- 根据策略的采样操作,
- 计算特定行为的对数概率,
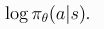
接下来,我们将描述如何对分类高斯策略和对角高斯策略进行这些操作。
分类策略:
分类策略就像离散动作上的分类器。你建立的神经网络分类策略是与你建立分类器相同的:输入是观察,其次是一些层数(卷积或紧密连接,根据输入的形式),然后最后一个线性层为每个行动给你分对数,后跟一个softmax分对数转化为概率。
采样:给定每个动作的概率,像PyTorch和Tensorflow这样的框架都有内置的采样工具。例如,请参阅PyTorch中的分类分布文档。Categorical distributions in PyTorch, torch.multinomial, tf.distributions.Categorical, or tf.multinomial.
对数概率:表示概率的最后一层为![]() 。它是一个向量,有多少项就有多少动作,所以我们可以把动作当作向量的索引。一个动作a的对数概率可以通过对向量进行索引得到:
。它是一个向量,有多少项就有多少动作,所以我们可以把动作当作向量的索引。一个动作a的对数概率可以通过对向量进行索引得到:
![]()
对角高斯策略:
多元高斯分布(或多元正态分布,如果你更喜欢这样叫的话)由均值向量![]() 、协方差矩阵
、协方差矩阵![]() 描述。对角高斯分布是协方差矩阵只有对角上的项的一种特殊情况。因此,我们可以用一个向量来表示它。
描述。对角高斯分布是协方差矩阵只有对角上的项的一种特殊情况。因此,我们可以用一个向量来表示它。
对角高斯策略总是有一个神经网络,从观察映射到平均行为![]() 。协方差矩阵有两种不同的表示方式。
。协方差矩阵有两种不同的表示方式。
第一种方式:只有一个对数标准差![]() 的向量,这不是一个状态函数:
的向量,这不是一个状态函数:![]() 是独立的参数。(您应该知道:我们的VPG、TRPO和PPO实现就是这样做的。)
是独立的参数。(您应该知道:我们的VPG、TRPO和PPO实现就是这样做的。)
第二种方式:有一个神经网络可以从状态映射到对数标准差![]() 。它可以选择与平均网络共享一些层。
。它可以选择与平均网络共享一些层。
注意,在这两种情况下,我们输出的是对数标准差,而不是直接的标准差。这是因为对数stds可以自由获取(负无穷大,正无穷大)中的任何值,而stds必须是非负的。如果您不需要强制执行这些类型的约束,那么训练参数会更容易。对对数标准差取幂就能得到标准差,所以我们通过这种表示不会有任何损失。
采样:给定平均动作![]() 和标准差
和标准差![]() ,以及来自球面高斯
,以及来自球面高斯![]() 的噪声向量z,可以计算出动作采样:
的噪声向量z,可以计算出动作采样:
![]()
其中![]() 表示两个向量的元素积。标准框架有内置的方法来生成噪声向量,如 torch.normal 或者 tf.random_normal。或者,您可以构建分布对象,例如通过 torch.distributions.Normal or tf.distributions.Normal,并使用它们来生成样本。(后一种方法的优点是,这些对象还可以为您计算对数概率。)
表示两个向量的元素积。标准框架有内置的方法来生成噪声向量,如 torch.normal 或者 tf.random_normal。或者,您可以构建分布对象,例如通过 torch.distributions.Normal or tf.distributions.Normal,并使用它们来生成样本。(后一种方法的优点是,这些对象还可以为您计算对数概率。)
对数概率:对于均值为![]() 且标准差
且标准差![]() 的对角高斯函数,k维行动a的对数概率由如下公式给出:
的对角高斯函数,k维行动a的对数概率由如下公式给出: