文本匹配论文Semantic Sentence Matching with Densely-connected Recurrent and Co-attentive Information
实验代码在SNLI测试集的准确率为 80.04 % 80.04\% 80.04%
这篇论文在SNLI数据集上达到的准确率超过90%,仅次于用BERT的模型,而且论文中用的densely-connected的RNN也是为数不多的可以把RNN堆叠很多层还能保证较高的准确率。众所周知,RNN由于梯度消失的问题使得它不能堆叠很多层。
下面一起看看模型:
语义句子匹配
语义句子匹配是NLP领域中很基础也很重要的任务,可以细分为
-
自然语言推理,指的是给定一个句子作为前提(premise),一个句子作为假设(hypothesis),如果可以从前提中推出来假设,那么两个句子就称为蕴含关系(entailment),如果前提和假设说的内容矛盾,那么两个句子称为矛盾(contradiction),两个关系都不是的话就称为中立关系(neutral)。自然语言推理中常用的数据集是SNLI,斯坦福大学发布的数据集。如下图所示:
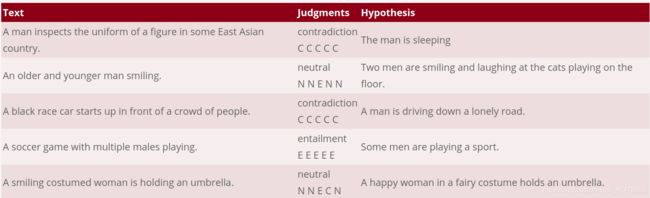
在每一个标签下面的五个字母表示的不同的人标注的结果,CCCCC表示的就是这五个人都认为两个句子是矛盾的contradiction.
NNENN表示有一个人认为两个句子是蕴含关系(Entailment),四个人认为两个句子是中立的(Neutral)。 -
释义识别(paraphrase identification),就是判断两个句子是不是一个意思。常用的数据集是quora问题对匹配。如下图所示

-
QA,在QA领域中,语义句子匹配可以用来匹配用户输入的问题和有着标准答案的问题的相似度,将相似度最高的那个问题的答案返还给用户。
ResNet vs DenseNet
假设F是一组混合的函数映射操作,比如CNN,RNN,全连接网络。。那么传统的神经网络的流动方式是 ( l − 1 ) t h {(l-1)}^{th} (l−1)th层的输出作为 l t h l^{th} lth的输入: x l = F ( x l − 1 ) , x l + 1 = F ( x l ) x_l=F(x_{l-1}),x_{l+1}=F(x_l) xl=F(xl−1),xl+1=F(xl).
ResNet的思想就是通过skip-connection跳步链接,将某一层输入与某一层输出相加送到下一层: x l = F ( x l − 1 ) + x l − 1 x_l=F(x_{l-1})+x_{l-1} xl=F(xl−1)+xl−1,显然ResNet的结构的优势之一就是梯度可以直接从后面的层流向前面的层,缓解了梯度消失的问题,但是DenseNet这篇论文的作者认为,这种求和相加的方式 ( F ( x l − 1 ) + x l − 1 ) (F(x_{l-1})+x_{l-1}) (F(xl−1)+xl−1)会阻碍信息流的前向传递过程 (我对这句话的理解就是因为把两个张量的值直接相加,那么每一个张量虽然维度不变,但是值发生了变化,这样可能会影响值的传递过程,不如把两个张量拼接起来一起送入后面的网络,举个例子吧,就好比我要训练个模型区分牛奶和咖啡,那么ResNet这种思想就是把牛奶和咖啡混在一起送入后面的网络去分类,DesNet这种思想就是把牛奶和咖啡分开,然后一起送入后面的网络分类。)
所以DenseNet的数学表达式是 x l = F ( x 0 , x 1 , ⋯ , x l − 1 ) x_l=F(x_0,x_1,\cdots,x_{l-1}) xl=F(x0,x1,⋯,xl−1)
如下图(出自论文Densely Connected Convolutional Networks)
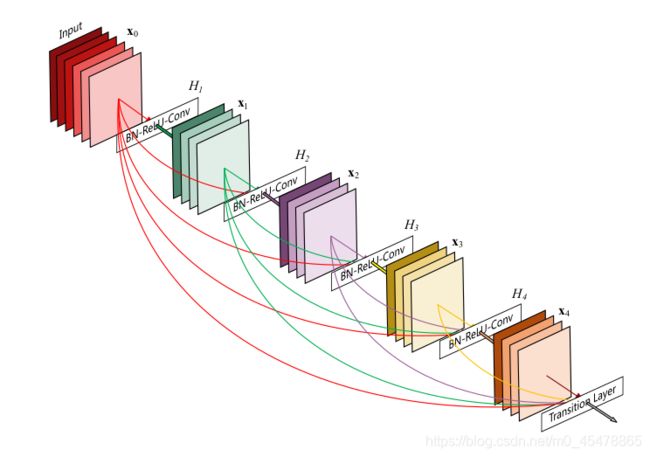
很形象是吧,就是把前面每一层的特征都保留着.
DRCN(Densely-recurrent-coattention network)
词嵌入层
论文中除了字符嵌入外还用了两种词嵌入,一种固定的词嵌入,用的是预训练的词向量(Glove或word2vec),另一种是在训练过程中调整的随机初始化的词向量。这种词嵌入方式有些类似于2014年这篇论文(CNN for sentence classification),该论文中词嵌入就是预训练+随机初始化,卷积层的输入张量就是两个通道,一个通道是预训练,另一个通道是随机初始化。
Densely connected Recurrent Networks
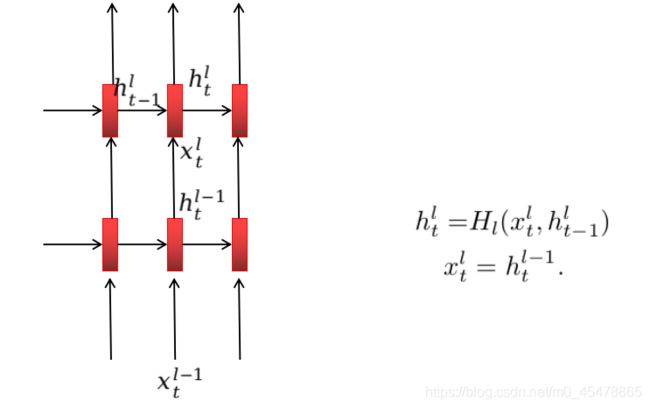
上图就是普通的堆叠式的RNN。
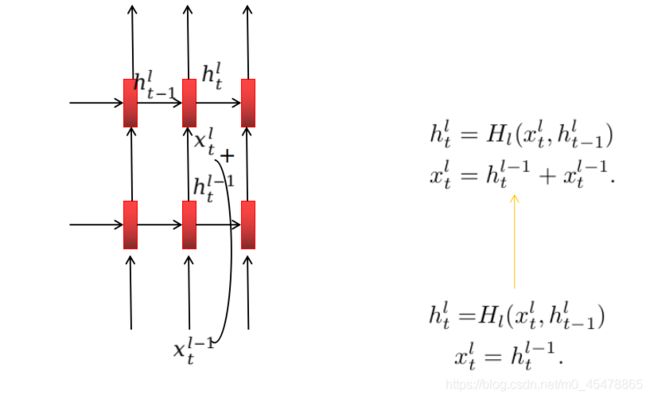
上图是残差链接形式的堆叠式RNN

上图就是密集连接形式的堆叠式RNN。
下面来看论文原图
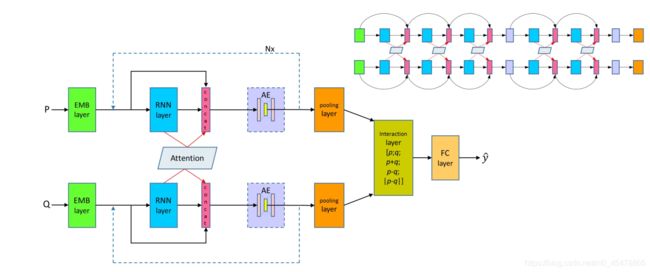
我们一部分一部分的看
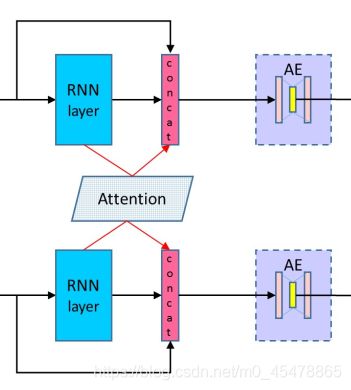
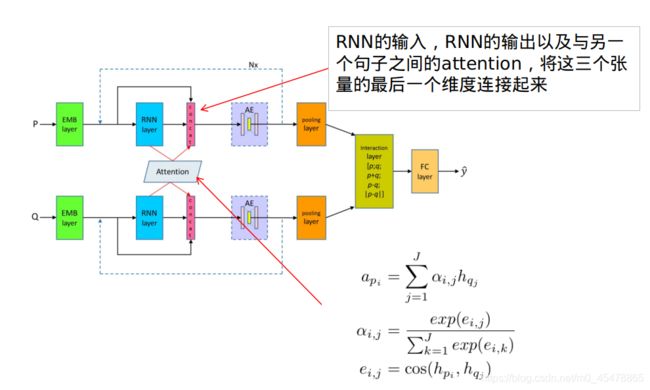
上图就展现了论文的核心思想,将上一层的输出与当前RNN层的输出以及与另一个句子计算得到的attention在最后一个维度连接(concat)作为下一层的输入,公式表示如下
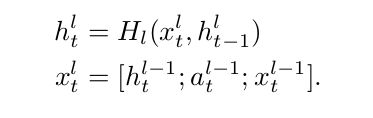
,论文中attention的计算方式很简单,就是两个句子之间的余弦距离然后softmax归一化出attention的权重,然后再分别与对应张量做加权求和:
为了防止维度过大,用自编码网络来降维。自编码随后讨论,我们来看假如没有自编码那么从词嵌入一直到最后的输出层,整个模型的维度会达到多少呢?如下图
假设词向量的维度是300,所有RNN的隐藏单元是100

显然最后的维度是1300,包括词向量的300维,然后每层的RNN输出100维,attention输出100维,一共5层,所以就是300+(100+100)*5.
这也体现了密集连接中特征重用的思想,因为最后的1300维的特征包括了从最开始的词向量的300维特征以及每一层的RNN的隐藏层的状态和每一层attention的特征。
这个维度还是挺大的,因为还有另外一个句子也是1300维而且最后pooling时考虑了除了句子p和句子q,还考虑了p+q,p-q,|p-q|,(|p-q|是两个向量相减的模长,是一个数)那么如果不降维最后输出的维度是 4 ∗ 1300 + 1 = 5201 4*1300+1=5201 4∗1300+1=5201,这就更大了。
论文中的降维方法用的是自编码(autoencoder),如下图。自编码是一种无监督的神经网络,从input_layer到hidden_layer的过程是编码,从hidden_layer到output_layer的过程就是解码,通过减小输入层与输出层之间的误差使得模型学习到输入数据的隐含表示特征,从而达到降维的作用。
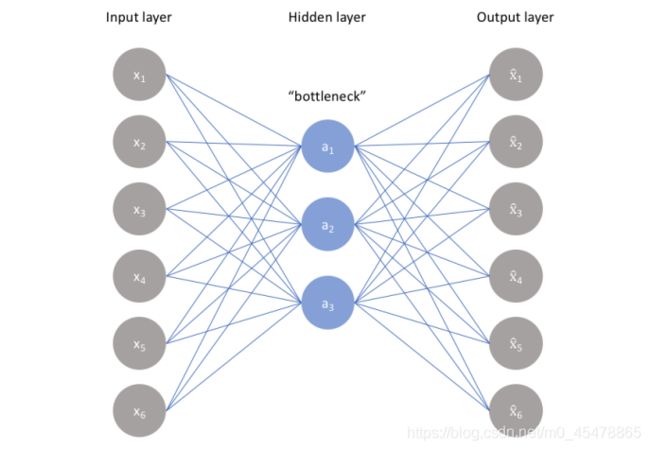
用代码表示如下:
def auto_encoder(x,bottleneck_dim=200):#论文中用的是200维
#x.shape==(batch_size,seq_length,dim)
input_dim=x.shape[-1]
hidden_features=tf.layers.dense(x,units=bottleneck_dim,activation=tf.nn.relu)
output=tf.layers.dense(hidden_features,units=input_dim,activation=tf.nn.tanh)
autoencoder_loss=tf.reduce_mean(tf.square(output-x))
return hidden_features,autoencoder_loss
#hidden_features.shape==(batch_size,seq_length,200)
模型最后的损失函数是交叉商+自编码模型的loss
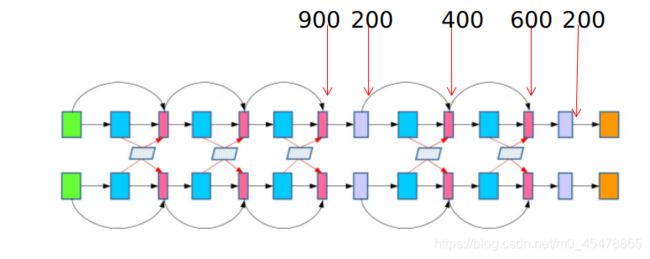
论文并没有每一层都用autoencoder。

如上图所示,就是论文的模型架构,在第三层和第五层的用了两个自编码。那么按照上述假设,词嵌入的维度是300,RNN的维度是100,自编码输出的维度是200,那么加了两个自编码后模型输出的维度如下图所示。
橘色框表示的pooling操作,论文用的是max-pooling,在sequence_length这一维度上取特征最大的那个单词的向量表示作为分类的依据。pooling之后会得到两个向量p,q。到了这一步比较直观的做法是计算两个向量之间的距离,比如余弦距离,然后得到一个分值与标签0和1做对比,或者连接两个向量然后输入给一层神经网络与标签做logistic regression或cross entropy。
论文中的做法是将p,q,p+q,p-q,|p-q|在最后一个维度连接在一起。|p-q|是两个向量相减之后的模长 ( ∑ 1 N x i 2 ) 1 / 2 (\sum_{1}^{N}x_{i}^2)^{1/2} (∑1Nxi2)1/2。用代码表示如下:
distance_pq=tf.sqrt(tf.reduce_sum(tf.square(p-q),axis=1,keep_dims=True))
distance_pq.shape==(batch_size,1)
concat_tensor=tf.concat(values=[p,q,p+q,p-q,distance_pq],axis=-1)
到了最后一层了:
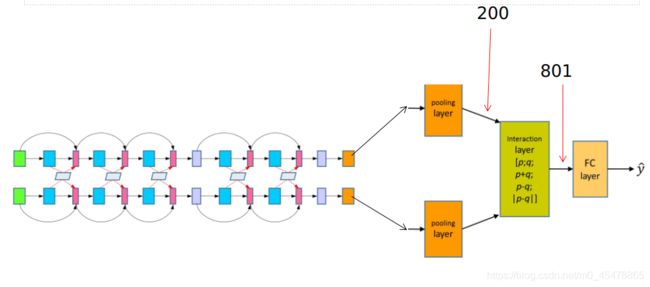
801我想大家知道怎么来的了。然后就是输出层了。
这里要注意的是损失函数=交叉商损失函数+两个自编码网络的损失函数。
Ablation Study
我们把这个翻译为简化实验,也就是通过简化模型来测试出模型的那些部分是关键的。
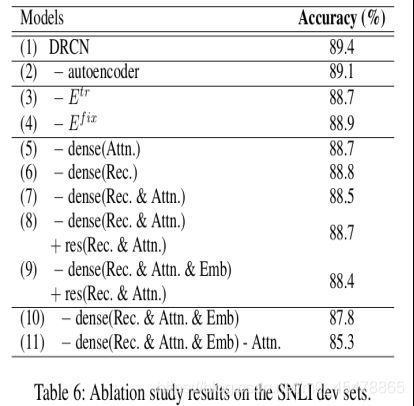
上图就是Ablation Study的结果,(1)表示的就是原模型DRCN,准确率最高。(2)表示的是去掉了autoencoder,也就是不要降维,下降了0.3个百分点。(3)是去掉了随机初始化的词向量,仅仅保留预训练的300维的词向量而且在模型训练过程中是不改变的。(4)是去掉了预训练的词向量,用随机初始化的向量,在训练过程中要一起训练的。对比(3),(4)可以发现随着模型一起训练的词向量比预训练的词向量效果要好,因为去掉它后准确率下降更多。
(5)–(11)要划重点了!!!!!!!!!!
(5)是指在密集连接中去掉了attention的密集连接,我再用图表示一下,我们再来看一次这个图
词向量假设还是300,第一个RNN层经过连接后的输出是500(300+100+100),然后把这500送入到下一层,此时RNN隐藏层输出100,attention输出100,注意此时concat要去掉前面那一层的attention的100维特征,这样此时concat的维度就是400+100+100=600。这就是去掉了attention密集链接,注意不是去掉了attention,而是把上一层计算出来的attention在下一层做concat时不要了。
那么解释完了(5)大家也就明白(6),(7)的原理了。
(8)指的是将dense链接改为resnet链接。(7)与(8)的相同之处是词嵌入这300维的特征会一直以dense连接的方式保留到最后,而每一层所计算的attention,和RNN的输出虽然会输入到下一层,但是都不会与下一层的输出连接。不同之处是(8)将每一层所计算的attention和RNN的输出以residual connection的链接方式连接到下一层,也就是与下一层的输出相加。
这里面下降最显著的还是(11),连attention都不要了,就是最最最普通的堆叠式RNN。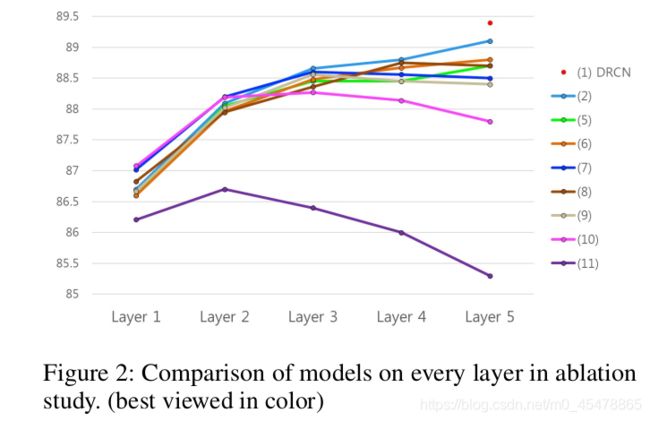
我们观察一下(10)和(11),这两个都是普通的堆叠式RNN,正如前面所说,简单的堆叠RNN会随着层数的增加效果下降,通常来讲,大部分的NLP任务(不局限于语义句子匹配)两层RNN即可。这篇论文叠了5层RNN还能保持准确率稳步上升。
Word Alignment and Importance
最后讲一讲论文用attention weights和max-pooling来解释分类结果。

不知道大家能不能看清上面的图,我把图单独显示出来如下
前提: two bicyclists in spandex and helmets in a race pedaling uphill
假设: A pair of humans are riding their bicycle with tight clothing,competing with each other.
显然two–pairs,bicyclists–bicycle,spandex–tight clothing,race–competing,pedaling–riding.模型很好的学习到了单词之间的对齐关系(alignment)。
下面看一个比较有意思的情形:

在第一层的时候,在每一个句子中的单词与对应句子中相同或者相似的单词有较强的相关性,随着层数的增加,那些对分类没有帮助作用的相关性就变得弱了,到了第五层,两个句子的相关性仅仅维持在white与gray之间,这也正是模型分类的依据。
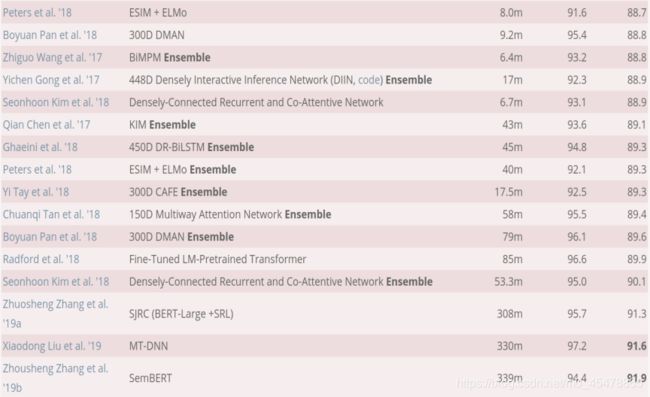
上图就是SNLI测试集上的所有论文的结果,这篇论文的效果还是很好的,除了那几种用了BERT的方法,仅仅就模型架构上而言,这篇论文的准确率是最高的。