从头学习爬虫(三十四)实战篇----动漫之家漫画(Scrapy实战)
工具:python3
本文主要由于改造Scrapy下载中间件拖了比较久,安装模块自行解决。
一 创建项目
创建项目:CMD进入你需要放置项目的目录
输入:scrapy startproject XXXXX XXXXX代表你项目的名字
二 导入IDE
由于IDE不一样这边自行解决

结构如上
三 IDE配置可以直接运行Scrapy
Scrapy默认是不能在IDE中调试的,我们在根目录中新建一个py文件叫:entrypoint.py;在里面写入以下内容:
from scrapy.cmdline import execute
execute(['scrapy', 'crawl', 'shiling'])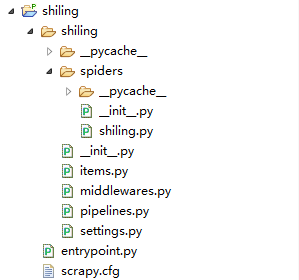
结构如上
四 settings.py设置
ROBOTSTXT_OBEY = False 前篇讲过
DOWNLOADER_MIDDLEWARES = {
'shiling.middlewares.ShilingDownloaderMiddleware': 543,
}
打开下载中间件的注释
ITEM_PIPELINES = {
'shiling.pipelines.ShilingPipeline': 300,
}
打开数据处理中间件的注释
HTTPCACHE_ENABLED = True
HTTPCACHE_EXPIRATION_SECS = 0
HTTPCACHE_DIR = 'httpcache'
HTTPCACHE_IGNORE_HTTP_CODES = []
HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
配置缓存
# -*- coding: utf-8 -*-
# Scrapy settings for shiling project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'shiling'
SPIDER_MODULES = ['shiling.spiders']
NEWSPIDER_MODULE = 'shiling.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'shiling (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'shiling.middlewares.ShilingSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'shiling.middlewares.ShilingDownloaderMiddleware': 543,
}
# Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'shiling.pipelines.ShilingPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
HTTPCACHE_ENABLED = True
HTTPCACHE_EXPIRATION_SECS = 0
HTTPCACHE_DIR = 'httpcache'
HTTPCACHE_IGNORE_HTTP_CODES = []
HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
# DOWNLOADER_MIDDLEWARES = { #开启注册中间件
# 'shiling.middlewares.ShilingDownloaderMiddleware': 543
# }
五 items.py
构造数据对象
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class ShilingItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()#文件名
sourceurl = scrapy.Field()#图片地址
cfile = scrapy.Field()#文件夹名字
pass
六 middlewares.py
由于我们采用selenium webdriver方式
所以要重写middleware这个下载中间件
# -*- coding: utf-8 -*-
# Define here the models for your spider middleware
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
from scrapy import signals
class ShilingSpiderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the spider middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_spider_input(self, response, spider):
# Called for each response that goes through the spider
# middleware and into the spider.
# Should return None or raise an exception.
return None
def process_spider_output(self, response, result, spider):
# Called with the results returned from the Spider, after
# it has processed the response.
# Must return an iterable of Request, dict or Item objects.
for i in result:
yield i
def process_spider_exception(self, response, exception, spider):
# Called when a spider or process_spider_input() method
# (from other spider middleware) raises an exception.
# Should return either None or an iterable of Response, dict
# or Item objects.
pass
def process_start_requests(self, start_requests, spider):
# Called with the start requests of the spider, and works
# similarly to the process_spider_output() method, except
# that it doesn’t have a response associated.
# Must return only requests (not items).
for r in start_requests:
yield r
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
from scrapy.http import HtmlResponse
class ShilingDownloaderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
if spider.name =="shiling":
spider.dr.get(request.url)#浏览器打开url
return HtmlResponse(url=spider.dr.current_url,body=spider.dr.page_source,encoding="utf-8",request=request)
def process_response(self, request, response, spider):
# Called with the response returned from the downloader.
# Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
return response
def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception.
# Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
pass
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
七 pipelines.py
pipelines这个数据处理我们要实现保存图片到本地
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import os
import time
from urllib.request import urlretrieve
from urllib.request import build_opener
from urllib.request import install_opener
class ShilingPipeline(object):
def process_item(self, item, spider):
index_dest="E:/manhua"
if not os.path.exists(index_dest) :
os.makedirs(index_dest)
else:
print(index_dest+"已创建")
imgdest=index_dest+"/"+item['cfile'].split('-')[0].strip()
if not os.path.exists(imgdest):
os.makedirs(imgdest)
else:
print(imgdest+"已创建")
opener=build_opener()
opener.addheaders=[('User-Agent','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1941.0 Safari/537.36'),("Referer","https://manhua.dmzj.com/")]
install_opener(opener)
img_url=item['sourceurl']
filename=imgdest+"/"+item['name'] +"."+img_url.split('.')[len(img_url.split('.'))-1]
if filename not in os.listdir():
urlretrieve(url = img_url,filename = filename)
else:
print(filename+"已下载")
time.sleep(1)
print("下载完成")
return item
八 shiling.py
主要Spider 逻辑模块
import scrapy
import re
from lxml import etree
from scrapy.http import Request
from bs4 import BeautifulSoup
from shiling.items import ShilingItem
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.options import Options
import os
import time
class MySpider(scrapy.Spider):
name='shiling'
def __init__(self):
# allowed_domains = ['23wx.com']
# bash_url = 'http://www.23wx.com/class/'
# bashurl = '.html'
self.start_urls = ['https://manhua.dmzj.com/shiling']#主页
self.chrome_options = Options()
self.chrome_options.add_argument('--disable-gpu') #谷歌文档提到需要加上这个属性来规避bug
self.chrome_options.add_argument('--headless') #浏览器不提供可视化页面. linux下如果系统不支持可视化不加这条会启动失败
self.abspath = os.path.abspath(r"D:\newChromeDriver\chromedriver_win32\chromedriver.exe")
self.dr = webdriver.Chrome(executable_path=self.abspath,chrome_options=self.chrome_options)
def start_requests(self):
#开始
yield Request(url=self.start_urls[0],callback=self.parse)
def spider_closed(self,spider):
#当爬虫退出的时候 关闭chrome
print ("spider closed")
dr.quit()
#
def parse(self, response):
#遍历拿到每一话的地址 继续
html = response.text
html1=etree.HTML(html)
selector1=html1.xpath("//div[@class='cartoon_online_border']/ul/li/a/@href")
for sel2 in range(0,len(selector1)):
yield Request(url="https://manhua.dmzj.com"+selector1[sel2],callback=self.parse2)
def parse2(self, response):
#遍历拿到每一页的地址 包装成item
html = response.text
html1=etree.HTML(html)
selector1=html1.xpath("//div[@class='btmBtnBox']/select/option/text()")
selector3=html1.xpath("//div[@class='btmBtnBox']/select/option/@value")
selector2=html1.xpath("//title/text()")[0];
for sel2 in range(0,len(selector1)):
item=ShilingItem()
item['name']= selector1[sel2]
item['sourceurl']= "https:"+selector3[sel2]
item['cfile']= selector2
yield item
九 运行entrypoint.py
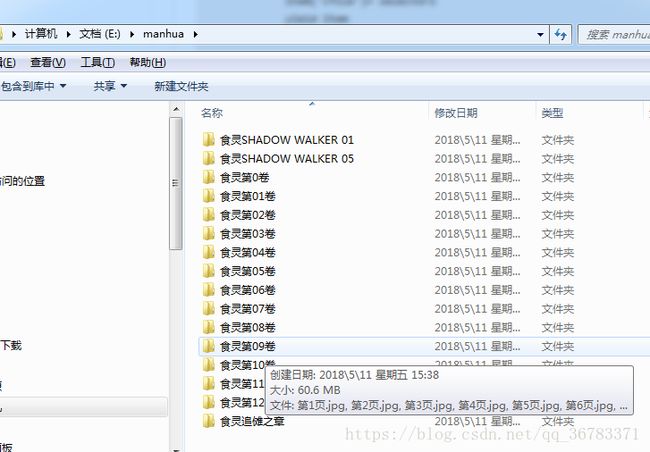
十 成果

代码比较low,请见谅