深度学习笔记(六)卷积神经网络
参考资料
- 【1】 深度学习cnn卷积神经网络原理(图文详解)https://www.sumaarts.com/share/620.html
- 【2】大话卷积神经网络(CNN) https://my.oschina.net/u/876354/blog/1620906
- 【3】大话CNN经典模型:LeNet https://my.oschina.net/u/876354/blog/1632862
- 【4】直白介绍卷积神经网络(CNN)http://www.dataguru.cn/article-13355-1.html
- 【5】AI学习笔记——卷积神经网络(CNN) https://www.jianshu.com/p/49b70f6480d1
- 【6】一文让你彻底了解卷积神经网络 https://blog.csdn.net/weixin_42451919/article/details/81381294
- 【7】卷积神经网络超详细介绍 https://blog.csdn.net/jiaoyangwm/article/details/80011656
- 【8】深度学习网络篇——ResNet https://blog.csdn.net/weixin_43624538/article/details/85049699?from=timeline&isappinstalled=0
- 【9】 【原创】对残差网络ResNet的理解 https://blog.csdn.net/pestzhang/article/details/80109330
卷积神经网络(LeNet)
下面我们通过Sequential类实现LeNet模型
import d2lzh as d2l
import mxnet as mx
from mxnet import autograd,gluon,init,nd
from mxnet.gluon import loss as gloss,nn
import time
net = nn.Sequential()
net.add(nn.Conv2D(channels=6,kernel_size=5,activation='sigmoid'),
nn.MaxPool2D(pool_size=2,strides=2),
nn.Conv2D(channels=16,kernel_size=5,activation='sigmoid'),
nn.MaxPool2D(pool_size=2,strides=2),
#Dense会默认(批量大小,通道,高,宽)形状的输入转换成
#(批量大小,通道*高*宽输入)
nn.Dense(120,activation='sigmoid'),
nn.Dense(84,activation='sigmoid'),
nn.Dense(10))
层名和形状
X = nd.random.uniform(shape=(1,1,28,28))
net.initialize()
for layer in net:
X = layer(X)
print(layer.name,X.shape)
# 因为卷积神经网络计算比多层感知机要复杂,建议使用GPU来加速计算

卷积层后跟着一个池化层
训练模型
batch_size = 256
train_iter,test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)
def try_gpu():
try:
ctx = mx.gpu()
_ = nd.zeros((1,),ctx = ctx)
except mx.base.MXNetError:
ctx = mx.cpu()
return ctx
ctx = try_gpu() # 如果有gpu,则使用gpu加速
ctx
预测准确率
def evaluate_accuracy(data_iter,net,ctx):
acc_sum,n = nd.array([0],ctx=ctx),0
for X,y in data_iter:
X,y = X.as_in_context(ctx),y.as_in_context(ctx).astype('float32')
acc_sum +=(net(X).argmax(axis=1)==y).sum()
n +=y.size
return acc_sum.asscalar()/n
训练函数
def train_ch5(net,train_iter,test_iter,batch_size,trainer,ctx,num_epochs):
print('training on',ctx)
loss = gloss.SoftmaxCrossEntropyLoss()
for epoch in range(num_epochs):
train_l_sum,train_acc_sum,n,start = 0.0,0.0,0,time.time()
for X,y in train_iter:
X,y = X.as_in_context(ctx),y.as_in_context(ctx)
with autograd.record():
y_hat = net(X)
l = loss(y_hat,y).sum()
l.backward()
trainer.step(batch_size)
y = y.astype('float32')
train_l_sum += l.asscalar()
train_acc_sum +=(y_hat.argmax(axis=1)==y).sum().asscalar()
n +=y.size
test_acc = evaluate_accuracy(test_iter,net,ctx)
print('epoch %d,loss %.4f,train acc %.3f,test acc %.3f,time %.1f sec'
%(epoch+1,train_l_sum/n,train_acc_sum/n,test_acc,time.time()-start))
lr,num_epochs = 0.9,5
net.initialize(force_reinit=True,ctx=ctx,init=init.Xavier())
trainer = gluon.Trainer(net.collect_params(),'sgd',{'learning_rate':lr})
train_ch5(net,train_iter,test_iter,batch_size,trainer,ctx,num_epochs)
运行结果
没有使用GPU的运行结果

使用GPU(1080)加速模型训练

几个注意点
- as_in_context函数将数据复制到显存上,例如gpu(0)
- 因为卷积神经网络计算比多层感知机要复杂,建议使用GPU来加速计算。
- 卷积层保留输入形状,使图像的像素在高和宽两个方向上的相关性均可能被有效识别;另一方面,卷积层通过滑动窗口将同一卷积核与不同位置的输入重复计算,从而避免参数尺寸过大。
- C1层,6个卷积层,卷积核大小5x5,能得到6个特征图,特征图大小是28x28,参数共享,参数个数是(5x5+1)6 = 156个,连接数(5x5+1)62828 = 122304个
- S2层,池化层大小2x2,6个特征图,特征图大小是14x14,参数共享,参数个数是2x6=12(池化层2x2的区域相加,乘以权重,加上偏置,激活函数),连接数是(2x2+1)614*14 = 5880
- C3层,16个卷积层,卷积核大小5x5,能得到16个特征图,大小是10x10,参数数目为(5×5×3+1)×6 +(5×5×4+1)×9 +5×5×6+1 = 1516,参数数量为1516,因此连接数为1516×10×10= 151600
- S4层,16个特征图,每个特征图的大小为5×5,需要参数个数为16×2 = 32,连接数为(2×2+1)×5×5×16 = 2000。
- C5层,该层有120个卷积核,每个卷积核的大小仍为5×5,因此有120个特征图,特征图大小1x1,参数数目为120×(5×5×16+1) = 48120,连接数为48120×1×1=48120
- F6层(全连接层):84,该层有84个特征图,特征图大小与C5一样都是1×1,与C5层全连接。参数数量为(120+1)×84=10164,接数与参数数量一样,也是10164
AlexNet
- 与相对较小的LeNet相比,AlexNet包含8层变换,其中5层卷积和2层全连接隐藏层,以及一个全连接输出层。AlexNet第一层中的卷积窗口形状是11x11。因为ImageNet中绝大多数图像的高和宽均比MNIST图像的高和宽大10倍以上。第二层的卷积窗口形状减小到5x5,之后全采用3x3。此外,第一,第二个第五个卷积层之后都采用窗口形状为3x3,步幅为2的最大池化层。
- AlexNet使用ReLu激活函数,使用丢弃法减少过拟合和引入大量的图像增广,如翻转,裁剪和颜色的变化,从而进一步扩大数据集来缓解过拟合
丢弃法
import d2lzh as d2l
from mxnet import autograd,gluon,init,nd
from mxnet.gluon import loss as gloss,nn
def dropout(X,drop_prob):
assert 0<= drop_prob <=1
keep_prob = 1-drop_prob
# 这种情况元素全丢弃
if keep_prob ==0:
return X.zeros_like()
mask = nd.random.uniform(0,1,X.shape)<keep_prob
# 大于为1,小于等于为0
return mask*X/keep_prob
X = nd.arange(16).reshape((2,8))
A= dropout(X,0.5)
A
代码实现
#%%
import d2lzh as d2l
import mxnet as mx
from mxnet import autograd,gluon,init,nd
from mxnet.gluon import loss as gloss,nn
from mxnet.gluon import data as gdata
import time
import sys
import os
net = nn.Sequential()
# 使用较大的11*11窗口来捕捉物体。同时使用步幅4来较大幅度减小输出高和宽
# 输出通道比LeNet中大很多
net.add(nn.Conv2D(96,kernel_size=11,strides=4,activation='relu'),
nn.MaxPool2D(pool_size=3,strides=2),
# 减小卷积窗口,填充2输入和输出高和宽一致,增大输出通道
nn.Conv2D(256,kernel_size=5,padding=2,activation='relu'),
nn.MaxPool2D(pool_size=3,strides=2),
# 连续3个卷积层,使用更小的卷积窗口
#(批量大小,通道*高*宽输入)
nn.Conv2D(384,kernel_size=3,padding=1,activation='relu'),
nn.Conv2D(384,kernel_size=3,padding=1,activation='relu'),
nn.Conv2D(256,kernel_size=3,padding=1,activation='relu'),
nn.MaxPool2D(pool_size=3,strides=2),
nn.Dense(4096,activation='relu'),nn.Dropout(0.5),
nn.Dense(4096,activation='relu'),nn.Dropout(0.5),
# 输出层。使用Fashion-MNIST,所以类别数位10
nn.Dense(10))
X = nd.random.uniform(shape=(1,1,224,224))
net.initialize()
for layer in net:
X = layer(X)
print(layer.name,'output shape:\t',X.shape)
# 读取数据集
#使用Fashion-MNIST来演示AlexNet。将图像高和宽扩展到224.
def load_data_fashion_mnist(batch_size,resize=None,root=os.path.join('~','.mxnet'
'datasets','fashion-mnist')):
root = os.path.expanduser(root) #展开用户路径
# root = C:\Users\Throne\.mxnetdatasets\fashion-mnist
transformer = []
if resize:
transformer +=[gdata.vision.transforms.Resize(resize)]
# 转变形状大小
transformer +=[gdata.vision.transforms.ToTensor()]
# 转变格式
transformer = gdata.vision.transforms.Compose(transformer)
# 执行
mnist_train = gdata.vision.FashionMNIST(root=root,train=True)
# 下载的训练集保存在root位置中
mnist_test = gdata.vision.FashionMNIST(root=root,train=False)
num_workers = 0 if sys.platform.startswith('win32') else 4
train_iter = gdata.DataLoader(
mnist_train.transform_first(transformer),
# 对第一个元素进行变换
batch_size,shuffle=True,num_workers=num_workers
)
test_iter = gdata.DataLoader(
mnist_test.transform_first(transformer),
batch_size,shuffle=False,num_workers=num_workers
)
return train_iter,test_iter
batch_size = 128
train_iter,test_iter = load_data_fashion_mnist(batch_size,resize=224)
lr,num_epochs,ctx = 0.01,5,d2l.try_gpu()
net.initialize(force_reinit=True,ctx=ctx,init = init.Xavier())
trainer = gluon.Trainer(net.collect_params(),'sgd',{'learning_rate':lr})
d2l.train_ch5(net,train_iter,test_iter,batch_size,trainer,ctx,num_epochs)
运行结果
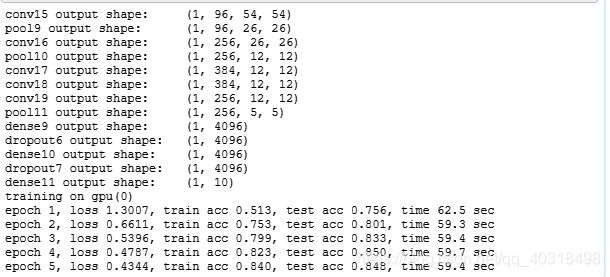
使用GPU加速计算也要60s,可见与LeNex相比,模型复杂得多。
使用重复元素的网络(VGG)
import d2lzh as d2l
from mxnet import gluon,init,nd
from mxnet.gluon import nn
# VGG块的规律:连续使用数个相同的填充为1,窗口形状为3x3的卷积层接一个
# 步幅为2,形状2x2的最大池化层
def vgg_block(num_convs,num_channels):
blk = nn.Sequential()
for _ in range(num_convs):
blk.add(nn.Conv2D(num_channels,kernel_size=3,padding=1,activation='relu'))
blk.add(nn.MaxPool2D(pool_size=2,strides=2))
return blk
# 后接全连接层构成。卷积层模块串联数个vgg_block,全连接模块与AlexNet一样
# 构造vgg网络。5个卷积块,前两个单卷积层,后三个双卷积层
# 第一块输出通道是64,之后翻倍,直到512
# 使用8个卷积层和3个全连接层,称为VGG-11
conv_arch = ((1,64),(1,128),(2,256),(2,512),(2,512))
def vgg(conv_arch):
net = nn.Sequential()
# 卷积层部分
for (num_convs,num_channels) in conv_arch:
net.add(vgg_block(num_convs,num_channels))
# 全连接层
net.add(nn.Dense(4096,activation='relu'),nn.Dropout(0.5),
nn.Dense(4096,activation='relu'),nn.Dropout(0.5),
nn.Dense(10))
# 卷积层只用于提取特征.
return net
net = vgg(conv_arch)
net.initialize()
print(net)
# 每次将输入的高和宽减半,直到高和宽变为7后传入全连接层。输出通道变为512.
# 训练模型
ratio = 4
small_conv_arch = [(pair[0],pair[1]//ratio) for pair in conv_arch]
net = vgg(small_conv_arch)
lr,num_epochs,batch_size,ctx = 0.05,3,128,d2l.try_gpu()
net.initialize(ctx=ctx,init=init.Xavier())
trainer = gluon.Trainer(net.collect_params(),'sgd',{'learning_rate':lr})
train_iter,test_iter = d2l.load_data_fashion_mnist(batch_size,resize=224)
d2l.train_ch5(net,train_iter,test_iter,batch_size,trainer,ctx,num_epochs)
运行结果
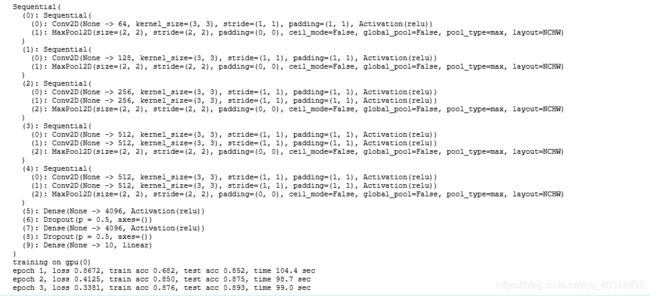
ResNet
import d2lzh as d2l
from mxnet import gluon,init,nd
from mxnet.gluon import nn
class Residual(nn.Block):
def __init__(self,num_channels,use_1x1conv=False,strides=1,**kwargs):
super(Residual,self).__init__(**kwargs)
self.conv1 = nn.Conv2D(num_channels,kernel_size=3,padding=1,strides=strides)
self.conv2 = nn.Conv2D(num_channels,kernel_size=3,padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2D(num_channels,kernel_size=1,strides=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm()
self.bn2 = nn.BatchNorm()
def forward(self,X):
Y = nd.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
return nd.relu(Y+X)
#ResNet模型
net = nn.Sequential()
net.add(nn.Conv2D(64,kernel_size=7,strides=2,padding=3),
nn.BatchNorm(),nn.Activation('relu'),
nn.MaxPool2D(pool_size=3,strides=2,padding=1))
# ResNet使用4个残差块组成模块,每个模块使用若干个同样输出通道数的残差块
# 第一个模块的通道数同输入通道数一致。之后的每个模块在第一个
# 残差块里将上一个模块通道数翻倍,高和宽减半
def resnet_block(num_channels,num_residuals,first_block=False):
blk = nn.Sequential()
for i in range(num_residuals):
if i==0 and not first_block:
blk.add(Residual(num_channels,use_1x1conv=True,strides=2))
else:
blk.add(Residual(num_channels))
return blk
# 为ResNet加入所有残差块,每个模块两个残差块
net.add(resnet_block(64,2,first_block=True),
resnet_block(128,2),
resnet_block(256,2),
resnet_block(512,2))
# 加入全局平均池化层
net.add(nn.GlobalMaxPool2D(),nn.Dense(10))
print(net)
lr,num_epochs,batch_size,ctx = 0.05,3,128,d2l.try_gpu()
net.initialize(ctx=ctx,init=init.Xavier())
trainer = gluon.Trainer(net.collect_params(),'sgd',{'learning_rate':lr})
train_iter,test_iter = d2l.load_data_fashion_mnist(batch_size,resize=224)
print('Train')
d2l.train_ch5(net,train_iter,test_iter,batch_size,trainer,ctx,num_epochs)
Sequential(
(0): Conv2D(None -> 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3))
(1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=None)
(2): Activation(relu)
(3): MaxPool2D(size=(3, 3), stride=(2, 2), padding=(1, 1), ceil_mode=False, global_pool=False, pool_type=max, layout=NCHW)
(4): Sequential(
(0): Residual(
(conv1): Conv2D(None -> 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv2): Conv2D(None -> 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=None)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=None)
)
(1): Residual(
(conv1): Conv2D(None -> 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv2): Conv2D(None -> 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=None)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=None)
)
)
(5): Sequential(
(0): Residual(
(conv1): Conv2D(None -> 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(conv2): Conv2D(None -> 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv3): Conv2D(None -> 128, kernel_size=(1, 1), stride=(2, 2))
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=None)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=None)
)
(1): Residual(
(conv1): Conv2D(None -> 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv2): Conv2D(None -> 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=None)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=None)
)
)
(6): Sequential(
(0): Residual(
(conv1): Conv2D(None -> 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(conv2): Conv2D(None -> 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv3): Conv2D(None -> 256, kernel_size=(1, 1), stride=(2, 2))
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=None)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=None)
)
(1): Residual(
(conv1): Conv2D(None -> 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv2): Conv2D(None -> 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=None)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=None)
)
)
(7): Sequential(
(0): Residual(
(conv1): Conv2D(None -> 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(conv2): Conv2D(None -> 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv3): Conv2D(None -> 512, kernel_size=(1, 1), stride=(2, 2))
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=None)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=None)
)
(1): Residual(
(conv1): Conv2D(None -> 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv2): Conv2D(None -> 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=None)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=None)
)
)
(8): GlobalMaxPool2D(size=(1, 1), stride=(1, 1), padding=(0, 0), ceil_mode=True, global_pool=True, pool_type=max, layout=NCHW)
(9): Dense(None -> 10, linear)
)
Train
training on gpu(0)
epoch 1, loss 2.5807, train acc 0.481, test acc 0.817, time 267.9 sec
epoch 2, loss 0.5280, train acc 0.831, test acc 0.866, time 256.2 sec
epoch 3, loss 0.3356, train acc 0.873, test acc 0.869, time 262.0 sec