支持向量机SVM
关键字:vector,support,machine,核函数,支持向量机由于自然语言分类
总结:SVM是一个分类问题,在学习复杂的非线性方程时效果很好,是监督式学习(详见前面的微博:机器学习算法总结)。
例子:from吴恩达的机器学习视频,肿瘤大小与是否患病的例子
1.定义
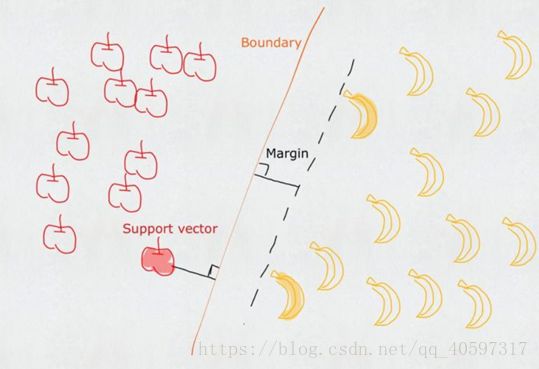
找到一条直线,使得直线可以划分两类,并且到两类的距离(就是图上的垂线长度)一样,这是一条最佳的直线。
离直线最近的点叫vector,直线叫machine,常说vector support machine(这就是SVM名称的由来),确定最近的点就确定了直线。
SVM也叫最大间距分类器
2.求解
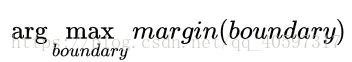
现在这里的直线叫boundary了,margin(boundary)的意思就是输入一个boundary,得到两边的类到直线的最小距离。然后寻找margin(就是类到直线的最小距离)最大的一个,这就是我们要寻找的boundary。然后取这个时候的参数boundary就可以得到分类器machine。
3.数学表达与推导
用来分类的直线表示为: ![]()
则一个点X0到直线的距离为 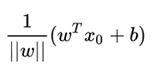
则表达式就变成 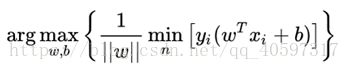
这里的yi表示-1或者+1,指点在直线的下方或者上方,这样一来 ![]() 就可以都非负了
就可以都非负了
等价变换: ![]() 等价于所有点到boundary的距离都
等价于所有点到boundary的距离都 ![]()
就是 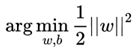 等价于
等价于 ![]() ,这里的1是一个常数,这样方便计算
,这里的1是一个常数,这样方便计算
4.拉格朗日乘子法method of lagrange multiplier
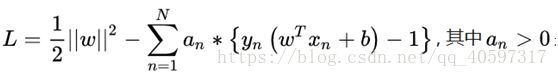
推导过程老师讲过了,以后整理,这不是重点
5.如果不能用直线划分
就用核函数
常用线性核函数 ![]()
线性核、多项式核、高斯核、拉普拉斯核、sigmoid核、通过核函数之间的线性组合或直积等运算得出的新核函数。
核函数相关知识可以参考GPR的核函数介绍
假如在二维空间不可以划分,就可以把它扩充为三维空间,这里的z选择与x,y有关,然后在三维空间分割后投回二维空间。如果在三维空间那么这就是一个三维的向量,实际上SVM需要的不是多维向量,而是两个点a,b的内积来进行分类。a与b内积得到了一个与a的x,y,b的x,y有关的值,这就是我们所说的核函数。所以我们只需要选择合适的核函数就可以,不必考虑实际上它投影到了几维空间。此时两个点的核函数就相当于这两个点投影到高维空间的对应的两个点的内积了。
支持向量机由于自然语言分类:这个时候每个词语出现的频率就是特征了,每个单词被几千维向量代表,因为有几千个文本,每个维度就是单词在相应文本出现的频率。非线性核函数在维数很高的情况下容易造成过拟合,所以我们应该坚持选择线性核函数来分析处理文本。
6.两类点有交集

此时用![]() 衡量,图里面的苹果错误分类为
衡量,图里面的苹果错误分类为 ![]() ,直线上为
,直线上为 ![]() ,准确分类的为
,准确分类的为![]() ,
,![]() 为惩罚项
为惩罚项
整体惩罚力度用 ![]() 表示,即
表示,即 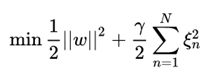
7.不止两类点
是不是A?one-versus-the-restapproach
是A还是B?one-versus-one approace
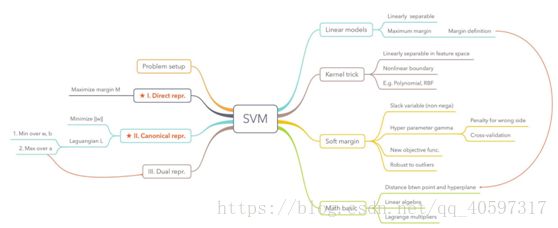
8.思维导图
9、SVM的代价函数
Logistic regression的代价函数长这样:
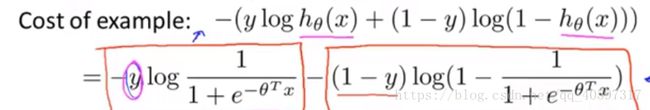
SVM的Cost Function是在Logistic regression的代价函数里的![]() 变化即可,在
变化即可,在![]() 基础上做两条直线,这两条直线就是SVM的Cost Function,就像下面的图里的粉色直线
基础上做两条直线,这两条直线就是SVM的Cost Function,就像下面的图里的粉色直线
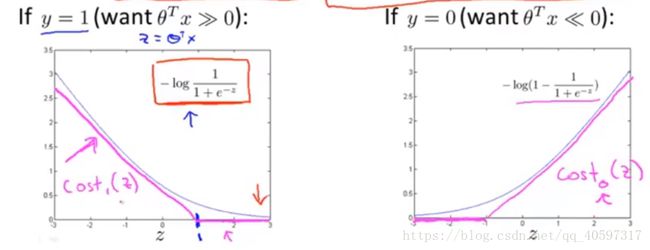
即: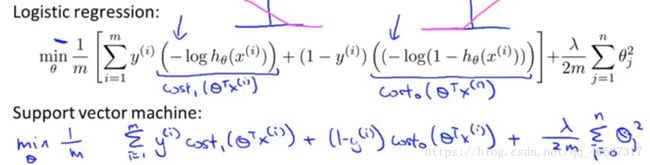 (注意负号)
(注意负号)
SVM然后需要把前面的参数 去掉,当然这对结果没什么影响,最后得到的Cost Function是
去掉,当然这对结果没什么影响,最后得到的Cost Function是
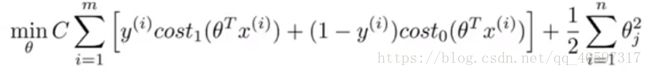
与Logistic Regression相比,SVM并不会像Logistic Regression一样输出概率,而是预测y是0或者1

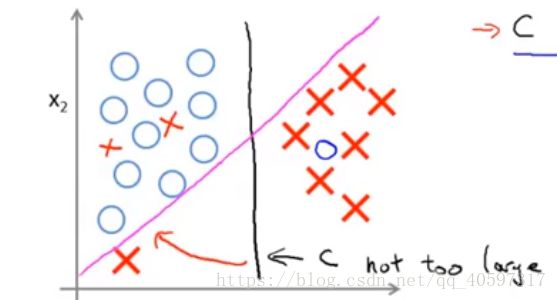
如果把C设置的不怎么大,那么SVM得到的还是黑色的线。
如果设置的很大的话,SVM会充分考虑每一个点,比如把下方的紫红色叉号加进来,那么得到的就是紫红色的线了。所以C可以控制分类的严格性。
资料:https://monkeylearn.com/blog/
侵删,参考:https://www.zhihu.com/question/21094489