Spark代码生成-全阶段代码生成
文章目录
- CollapseCodegenStages规则
- WholeStageCodegenExec
- CodegenSupport
- consume/doConsume 和 produce/doProduce
- inputRDDs
- WholeStageCodegenExec执行过程
- WholeStageCodegenExec.doExecute()
- WholeStageCodegenExec.doCodeGen
- produce
- doProduce
- consume
- doConsume
- 全阶段代码生成的好处
- 全阶段代码生成和表达式代码生成
CollapseCodegenStages规则
Catalyst 全阶段代码生成的入口是 CollapseCodegenStages 规则 。在QueryExecution中,当生成物理算子书之后会调用prepareForExecution,为物理算子树做执行前的准备。preparations定义了一组规则,应用于物理算子树。

CollapseCodegenStages 规则会将生成的物理计划中支持代码生成的节点生成的代码整合成一段,因此称为全阶段代码生成(WholeStageCodegen) 。
WholeStageCodegenExec
SparkSQL:select name from student where age > 18 ;
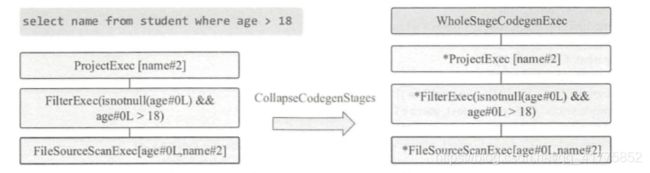
由上述SQL语句可生成物理算子树,包含物理计划括 FileSourceScanExec, Filter Exec 和 ProjectExec 3 个节点。这 3 个节点都支持代码生成,因此 CollapseCodegenStages 规则会在 3 个物理算子节点上添加一个 WholeStageCodegenExec 节点,其主要功能就是将这 3 个 节点生成的代码整合在一起。
对于物理算子树中的不支持代码生成的节点时,CollapseCodegenStages 规则会在其上插入一个名为 InputAdapter 的物理节点对其进行封装。
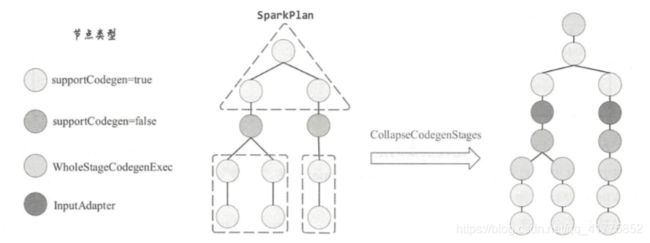
在某种程度上,这些不支持代码生成的节点可以看作是分隔的点,可将整个物理计划拆分成多个代码段。 而 InputAdapter 节点可以看作是对应 WholeStageCodegenExec 所包含子树的叶子节点,起到 InternalRow 的数据输入作用。 每个 WholeStageCodegenExec 节点负责整合一个代码段。
CodegenSupport
在 Spark 中, CodegenSupport 接口代表支持代码生成的物理节点。
CodegenSupport 本身也是 SparkPlan 的子类,提供了 11 个方法和 1 个变量。 首先, variablePrefix 返 回 String 类型,表示对应的物理算子节点生成的代码中变量名的前缀。 不同的节点类型其前缀 不同。 例如, SortMergeJ oinExec 节点生成的代码中的变量前缀缩写为 “smj”,除特定的缩写外,默认均以 nodeName 的小写作为变量前缀,这样方便彼此之间的区别。

consume/doConsume 和 produce/doProduce
在 CodegenSupport 中比较重要的是 consume/doConsume 和 produce/doPr叫uce 这两对方法。 根据方法名很容易理解, consume 和doConsume 用来“消费”,返回的是该 CodegenSupport 节点处理数据核心逻辑所对应生成的代码;而 produce/doProduce 则用来“生产”,返回的是该节点及其子节点所生成的代码。
在具体实现上, consume 和 produce 都是 final 类型,区别在于 produce 方法会调用 doProduce 方法,而 consume 方法则会调用其父节点的 doConsume 方法。
inputRDDs
此方法用于获得产生输入数据的 inputRDDs 。
在WholeStageCodegenExec中,此方法抛出异常,说明不能在WholeStageCodegenExec中调用此函数。

在继承CodegenSupport 的物理计划中,该方法返回子物理计划的inputRDDs()函数结果。

在继承CodegenSupport 的数据源物理计划中,该方法返回数据源RDD,比如FileSourceScanExec中:

在InputAdapter中,其执行子物理计划的executor方法,将结果RDD进行返回。

WholeStageCodegenExec执行过程
WholeStageCodegenExec 是物理计划节点,所以其主要逻辑在execute()方法中。其execute方法具体分为数据获取与代码生成两部分。 假设物理算子节点 A 支持代码生成,物理算子节 点 B 不支持代码生成,因此 B 会采用 InputAdapter 封装(图中的 Fakelnput,起到了数据源的作用) 。
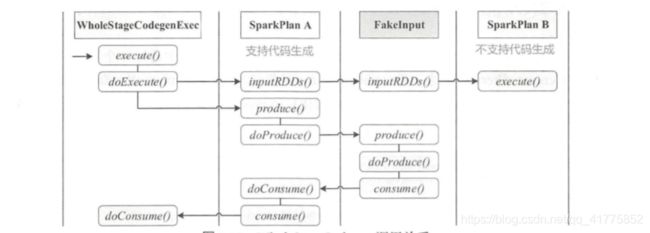
数据的获取比较直接,调用 inputRDDs 递归得到整段代码的输入数据。
代码生成可以看作是两个方向相反的递归过程:代码的整体框架由 produce/doProduce 方法负责,父节点调用子节点;代码具体处理逻辑由 consume/doConsume 方法负责,由子节点调用父节点。
由此可以看出 WholeStageCodegenExec执行过程是一个整体。整个物理算子树的执行过程被InputAdapter分隔开。每一个WholeStageCodegenExec执行时,首先获取输入inputRDDs,递归执行子节点的inputRDDs函数,直到碰到InputAdapter或者数据源物理计划节点,返回子物理计划节点的executor计算结果RDD或者数据源RDD。然后进行代码生成,递归执行produce()函数,直到碰到InputAdapter或者数据源物理计划节点,返回所有子节点生成的综合代码。利用在WholeStageCodegenExec节点上利用生成代码对inputRDDs进行处理。
所以WholeStageCodegenExec的executor方法不会递归调用子物理计划节点的executor方法,而是首先获得整个WholeStageCodegenExec子树的输入inputRDDs,然后获得整个WholeStageCodegenExec子树的生成代码。然后用生成代码对inputRDD进行处理,一次性的完成了子树中所有物理计划节点的执行任务。
WholeStageCodegenExec.doExecute()

首先调用doCodeGen()方法,对WholeStageCodegenExec的子树进行代码生成,获得所有子节点生成的综合代码。然后调用CodeGenerator.compile进行编译,如果编译失败且配置回退机制(参数 spark.sql.codegen.wholeStage 默认为 true),则代码生成将被舍弃转而执行 Spark原生的逻辑(调用child.execute()获得结果RDD)。

如果编译成功,则调用子物理计划节点的inputRDDs(),获得整个WholeStageCodegenExec子树的inputRDDS。然后调用inputRDD的mapPartitions函数,在每个分区上编译生成代码,获得生成的对象(clazz),然后调用其 generate 方法得到 BufferedRowlterator 对象(此对象就是WholeStageCodegenExec子树中所有子节点生成的综合代码)。
生成的BufferedRowlterator 对象重写了processNext()函数(综合了所有子节点的处理逻辑),表示对一行数据的处理过程。每次调用BufferedRowlterator 的hasNext函数都会触发processNext()对一行数据进行处理。所以将RDD分区iter作为参数初始化BufferedRowlterator,得到的分区数据都是经过processNext()函数处理的。

WholeStageCodegenExec.doCodeGen
上面介绍了WholeStageCodegenExec总体执行逻辑,这里介绍一下具体的代码生成过程。

首先创建代码生成上下文CodegenContext,调用子节点的produce函数。produce函数返回的对象code为字符串类型,我们从上面可以看出,code的全部内容都添加到processNext函数中,所以produce函数得到的是WholeStageCodegenExec的子树中所有物理计划的综合生成代码,概括了子树中所有物理计划的执行逻辑。
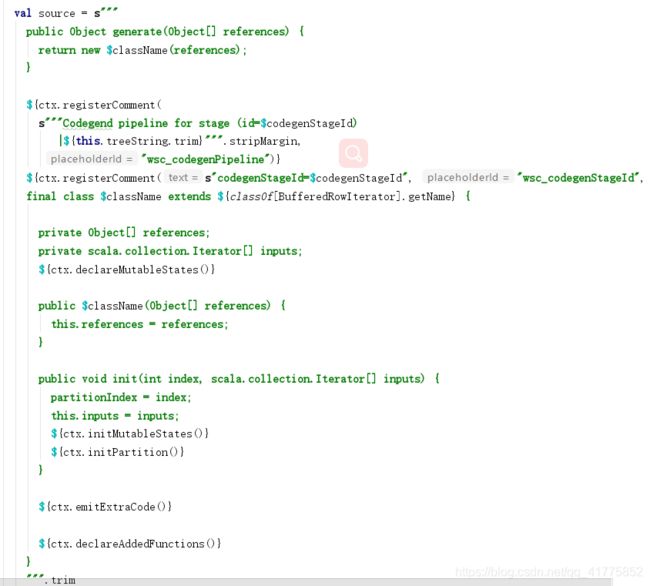
然后是利用代码生成上下文ctx,构造java源代码字符串。源代码表示 Generatedlterator 类,其是 Spark 中 BufferedRowiterator 对象的子 类,重载实现了 init 方法(负责相关变量的初始化)和 processNext 方法(用于循环处理 RDD 中 的数据行) 。
Generatedlterator 类中会声明 Codegen Context 中保存的状态变量,在初始化方法 init 中会加入 initMutableStates 与 initPartition 方法。 同样的,也会加入 declareAddedFunctions 来 声明 CodegenContext 中定义的相关函数。 在核心的 processNext 方法中, 直接加入 WholeStageCodegenExec 中 produce 方法生成的代码。
produce
以文中的物理算子书为例,WholeStageCodegenExec 执行时会调用其子节点 ProjectExec 中的 produce 方法得到生成的代码。 ProjectExec 节点的 produce 调用 doProduce 方法,继而 调用 FilterExec 节点的 produce 方法。 依此类推。 一直到叶子节点 FileSourceScanExec 的 doProduce 方法,构造出将要生成的 Java 代码框架。
produce函数定义在CodegenSupport中,且为final,不可重写:
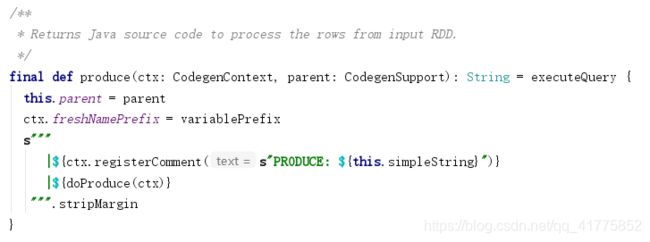
其作用是把传入的CodegenSupport作为parent, 设置CodegenContext 的变量前缀,添加注释和调用 doProduce 方法。
produce的整个调用过程如下:

doProduce
doProduce函数定义在各个物理计划中,一般是调用子节点的produce函数,并将自己作为参数传入。

直到碰见InputAdapter或者数据源物理计划节点,其doProduce会返回正在的生成代码。InputAdapter的doProduce函数如下:

首先在代码生成上下文中增加input迭代器对象,并给其添加初始化赋值语句,$v = inputs[0]; 。这里的inputs其实就是最后生成的Generatedlterator类中的init方法中传入的第二个参数。在WholeStageCodegenExec.doExecute函数中,会将RDD分区的iterator迭代器传入init函数,所以input表示的就是InputRDD的分区迭代器。

然后创建row变量,调用分区迭代器的next函数获取输入行。调用consume函数,对输入行进行处理。
consume
consume在CodegenSupport中定义,final修饰,也是不可重写的。


consume函数所起到的作用是整合当前节点的处理逻辑,构造(ctx, inputVars, rowVar)三元组并提交到下一个处理逻辑(父节点的 doConsume 方法) 。
consume 方法会检查当前生成的 代码中是否已经包含了下一步所需的变量,并完成 3 个方面的功能。
- 生成下一步逻辑处理的变量 inputVars,类型为 Seq[ExprCode], 不同的变量代表不同的列。
- 生成 rowVar,类型为 ExprCode,代表整行数据的变量名 。
- 在构造上述对象的过程中,相应修改 CodegenContext 对象中的元素。
inputVars生成逻辑分两种情况:
- 如果有行变量,那么将 CodegenContext 对象的 INPUT_ROW 指向该行变量,且 currentVars 设为 null,得到的 inputVars 为该节点的输出宇段对应的 BoundReference 生成的代码;
- 如果行变量为空,则直接将 outputVars 复制。
rowVar 的生成逻辑(prepareRowVar):
- 如果传入的行变量 不为空, 则直接对应该行变量的 ExprCode 对象;
- 如果行变量为空,但是传入的列变量不为空,那么根据 output 由GenerateUnsafeProjection 生成代码的主要内容(createCode)
- 否则构造名为 unsafeRow 的 ExprCode 对象。
最后将生成的inputVars和rowVar传给父节点的doConsume函数。本文实例中,FileSourceScanExec 节点将调用FilterExec 算子的 doConsume 操作,inputVars和rowVar如下:

CodegenContext 内部储存情况,如下:

目前生成的代码如下:

doConsume
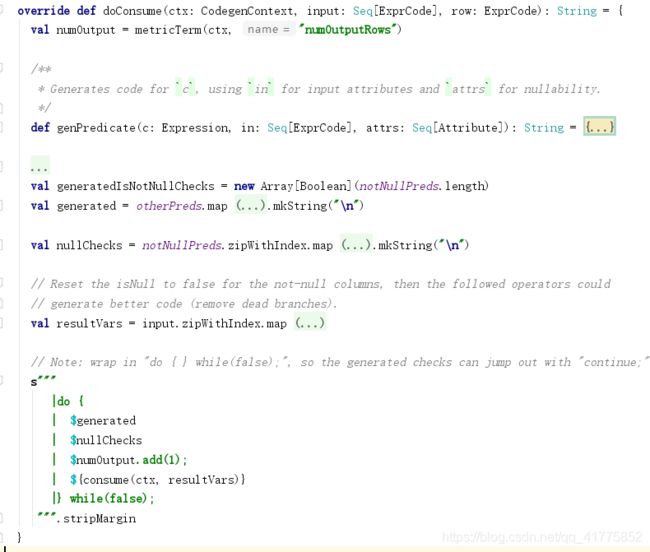
FilterExec 算子的 doConsume 方法实际上完成了 4 件事,分别是实际过滤条件的代码生成(generated)、 null 检测的代码生成(nullChecks)、 SQLMetric 变量更新 (numOutput.add(l))和 consume 方法的调用。
在 FilterExec 算子中,会将过滤谓词分为 notNullPreds 和 otherPreds 两部分, notNullPreds 是所有的 IsNotNull表达式, otherPreds对应 其它的过滤条件。 本例中的 notNullPreds 列表中只有一个表达式 isnotnull(age), otherPreds 列表中也只有一个过滤条件“age > 18”。

generated会将otherPreds中的每一个表达式生成nullChecks代码,因为generated之后还有一个nullChecks代码,所以为了避免重复null检测,专门设置了一个记录某个字段是否执行了 null 检查的布尔数组 (generatedisNotNullChecks) 。
然后调用genPredicate(c, input, child.output)生成过滤表达式代码。
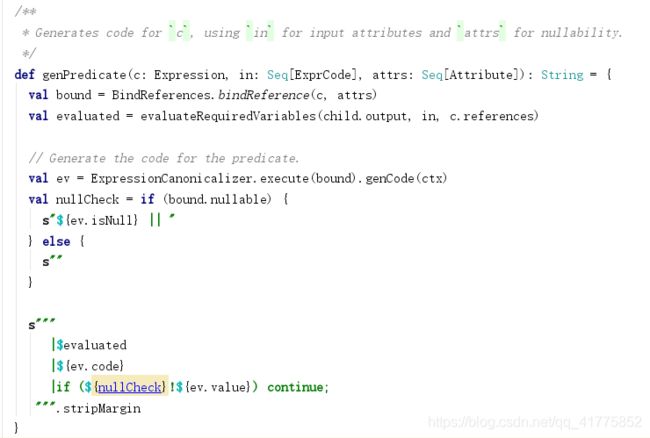
先对表达式调用BindReferences.bindReference,然后会调用表达式的genCode函数,生成表达式的ExprCode对象。genCode的执行逻辑与单独的表达式代码生成是一样的。最后在代码块中加入ExprCode的code字符串,即添加了过滤表达式的逻辑。
最后代码块中加入了consume(ctx, resultVars)函数,即再次调用consume函数。
全阶段代码生成(WholeStageCodegen)的最后一步都会落脚在 WholeStageCodegenExec 算 子的 doConsume 方法。 如图 所示,生成的代码首先会输出 row变量的 code。是否对得到的结果执行 copy操作取决于 CodegenContext对象中的 copyResult变量。 在上述例子中,不需要 copy操作,因此最终添加结果的代码为 append (project_result)。append方法会将处理之后的数据行加入BufferedRowIterator中的currentRows,使用next即可取出数据。

综上可以看出 doConsume 函数主要是对物理算子的中的表达式调用genCode函数生成代码,然后添加到整个的代码块中。然后再次调用consume函数,生成rowVar和intputVars传递给父节点的doConsume方法,递归调用,将各物理节点的表达式进行代码生成,并添加到整个的代码块中。
全阶段代码生成的好处
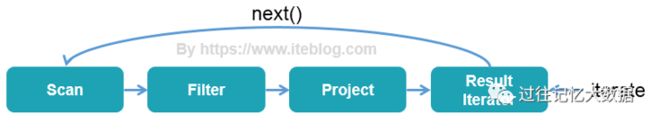
当今绝大多数数据库系统处理 SQL 在底层都是基于Volcano Iterator Model模型的。这个模型的执行可以概括为:首先数据库引擎会将 SQL 翻译成一系列的关系代数算子或表达式,然后依赖这些关系代数算子逐条处理输入数据并产生结果。每个算子在底层都实现同样的接口,比如都实现了 next 方法,然后最顶层的算子 next 调用子算子的 next,子算子的 next 在调用孙算子的 next,直到最底层的 next,具体过程如下图表示:

Volcano Iterator Model 的优点是抽象起来很简单,很容易实现,而且可以通过任意组合算子来表达复杂的查询。但是缺点也很明显,存在大量的虚函数调用,会引起 CPU 的中断,最终影响了执行效率。
全阶段代码生成的执行过程如下:
通过引入全阶段代码生成,大大减少了虚函数的调用,减少了 CPU 的调用,使得 SQL 的执行速度有很大提升。
全阶段代码生成和表达式代码生成
表达式代码生成是将一个物理计划节点中的表达式进行代码生成,转换成一个类。利用这个生成的类完成物理节点的逻辑操作。
全阶段代码生成是检测到物理算子树中有多个连续的可以进行代码生成的物理计划节点。所以对这多个连续的物理计划节点一次性进行代码生成,将多个物理计划节点的代码生成放在一个类中。利用这个类一次性的完成多个物理计划节点的逻辑操作。