Java 8 学习笔记7——并行数据处理与性能
内部迭代让你可以并行处理一个流,而无需在代码中显式使用和协调不同的线程。
将外部迭代换为内部迭代能够让原生Java库控制流元素的处理。这种方法让Java程序员无需显式实现优化来为数据集的处理加速。到目前为止,最重要的好处是可以对这些集合执行操作流水线,能够自动利用计算机上的多个内核。
例如,在Java 7之前,并行处理数据集合非常麻烦。第一,你得明确地把包含数据的数据结构分成若干子部分。第二,你要给每个子部分分配一个独立的线程。第三,你需要在恰当的时候对它们进行同步来避免不希望出现的竞争条件,等待所有线程完成,最后把这些部分结果合并起来。Java 7引入了一个叫作分支/合并的框架,让这些操作更稳定、更不易出错。
Stream接口可以让你不太费力气就能对数据集执行并行操作。它允许你声明性地将顺序流变为并行流。此外,流在幕后应用了Java 7引入的分支/合并框架。
并行流
Stream接口可以让你非常方便地处理它的元素:可以通过对收集源调用parallelStream方法来把集合转换为并行流。并行流就是一个把内容分成多个数据块,并用不同的线程分别处理每个数据块的流。这样一来,你就可以自动把给定操作的工作负荷分配给多核处理器的所有内核,让它们都忙起来。让我们用一个简单的例子来试验一下这个思想。假设你需要写一个方法,接受数字n作为参数,并返回从1到给定参数的所有数字的和。一个直接的方法是生成一个无穷大的数字流,把它限制到给定的数目,然后用对两个数字求和的BinaryOperator来归约这个流,如下所示:
public static long sequentialSum(long n) {
return Stream.iterate(1L, i -> i+1) //生成自然数无限流
.limit(n) //限制到前n个数
.reduce(0L, Long:: sum); //对所有数字求和来归纳流
}
用更为传统的Java术语来说,这段代码与下面的迭代等价:
public static long iterativeSum(long n) {
long result = 0;
for(long i = 1L; i <= n; i++) {
result += i;
}
return result;
}
这似乎是利用并行处理的好机会,特别是n很大的时候。用并行流的话,这问题就简单多了!
将顺序流转换为并行流
你可以把流转换成并行流,从而让前面的函数归约过程(也就是求和)并行运行——对顺序流调用parallel方法:
public static long parallelSum(long n) {
return Stream.iterate(1L, i -> i+1).limit(n).parallel() //将流转换为并行流
.reduce(0L, Long:: sum);
}
在上面的代码中,对流中所有数字求和的归纳过程的执行方式和使用流的元素求和部分中说的差不多。不同之处在于Stream在内部分成了几块。因此可以对不同的块独立并行进行归纳操作,如下图所示。最后,同一个归纳操作会将各个子流的部分归纳结果合并起来,得到整个原始流的归纳结果。
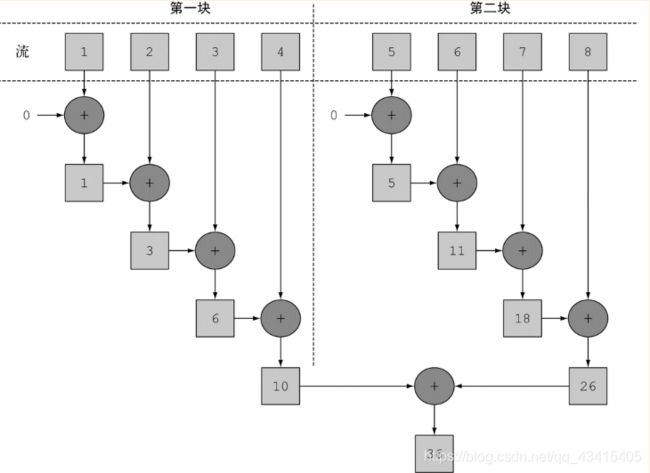
请注意,在现实中,对顺序流调用parallel方法并不意味着流本身有任何实际的变化。它在内部实际上就是设了一个boolean标志,表示你想让调用parallel之后进行的所有操作都并行执行。类似地,你只需要对并行流调用sequential方法就可以把它变成顺序流。请注意,你可能以为把这两个方法结合起来,就可以更细化地控制在遍历流时哪些操作要并行执行,哪些要顺序执行。例如,你可以这样做:
stream.parallel()
.filter(...)
.sequential()
.map(...)
.parallel()
.reduce();
但最后一次parallel或sequential调用会影响整个流水线。在本例中,流水线会并行执行,因为最后调用的是它。
配置并行流使用的线程池
并行流内部使用了默认的ForkJoinPool,它默认的线程数量就是你的处理器数量,这个值是由Runtime.getRuntime().availableProcessors()得到的。
但是你可以通过系统属性java.util.concurrent.ForkJoinPool.common.parallelism来改变线程池大小,如下所示:
System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism","12");
这是一个全局设置,因此它将影响代码中所有的并行流。反过来说,目前还无法专为某个并行流指定这个值。一般而言,让ForkJoinPool的大小等于处理器数量是个不错的默认值,除非你有很好的理由,否则强烈建议你不要修改它。
测量流性能
在多核处理器上运行并行版本时,会有显著的性能提升。现在有三个方法,用三种不同的方式(迭代式、顺序归纳和并行归纳)做完全相同的操作,看看谁最快。
在优化性能时,应该始终遵循三个黄金规则:测量,测量,再测量。为此,你可以开发一个方法,它与用流收集数据的比较收集器的性能部分中用于比较划分质数的两个收集器性能的测试框架非常类似,如下所示,测量对前n个自然数求和的函数的性能。
public long measureSumPerf(Function<Long, Long> adder, long n) {
long fastest = Long.MAX_VALUE;
for(int i = 0; i < 10; i++) {
long start = System.nanoTime();
long sum = adder.apply(n);
long duration = (System.nanoTime()-start)/1_000_000;
System.out.println("Result: " + sum);
if(duration < fastest)
fastest = duration;
}
return fastest;
}
这个方法接受一个函数和一个long作为参数。它会对传给方法的long应用函数10次,记录每次执行的时间(以毫秒为单位),并返回最短的一次执行时间。假设你把先前开发的所有方法都放进了一个名为ParallelStreams的类,你就可以用这个框架来测试顺序加法器函数对前一千万个自然数求和要用多久:
System.out.println("Sequential sum done in: " +
measureSumPerf(ParallelStreams:: sequentialSum, 10_000_000) + " msecs");
请注意,我们对这个结果应持保留态度。影响执行时间的因素有很多,比如你的电脑支持多少个内核。你可以在自己的机器上跑一下这些代码。我们在一台四核英特尔i7 2.3GHz的MacBook Pro上运行它,输出是这样的:
Sequential sum done in: 97 msecs
用传统for循环的迭代版本执行起来应该会快很多,因为它更为底层,更重要的是不需要对原始类型做任何装箱或拆箱操作。如果你试着测量它的性能,
System.out.println("Iterative sum done in: "+
measureSumPerf(ParallelStreams:: iterativeSum, 10_000_000)+" msecs");
将得到:
Iterative sum done in : 2 msecs
现在我们来对函数的并行版本做测试:
System.out.println("Parallel sum done in: "+
measureSumPerf(ParallelStreams:: parallelSum, 10_000_000)+" msecs");
看看会出现什么情况:
Parallel sum done in : 164 msecs
发现求和方法的并行版本比顺序版本要慢很多。你如何解释这个意外的结果呢?这里实际上有两个问题:
iterate生成的是装箱的对象,必须拆箱成数字才能求和- 我们很难把
iterate分成多个独立块来并行执行
第二个问题更有意思一点,因为你必须意识到某些流操作比其他操作更容易并行化。具体来说,iterate很难分割成能够独立执行的小块,因为每次应用这个函数都要依赖前一次应用的结果,如下图所示,iterate在本质上是顺序的。
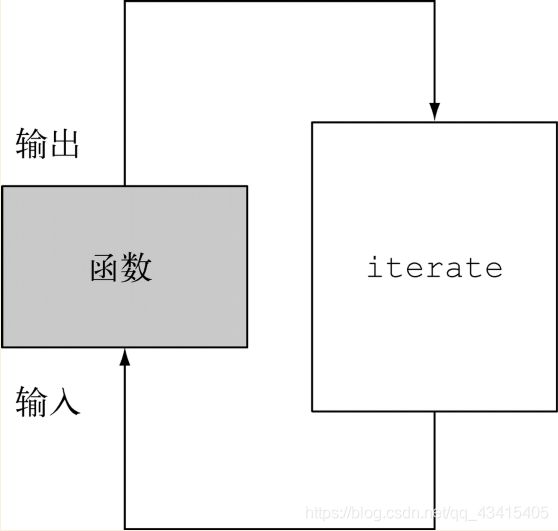
这意味着,在这个特定情况下,归纳进程不是像将顺序流转换为并行流部分中的图那样进行的;整张数字列表在归纳过程开始时没有准备好,因而无法有效地把流划分为小块来并行处理。把流标记成并行,你其实是给顺序处理增加了开销,它还要把每次求和操作分到一个不同的线程上。
这就说明了并行编程可能很复杂,有时候甚至有点违反直觉。如果用得不对(比如采用了一个不易并行化的操作,如iterate),它甚至可能让程序的整体性能更差,所以在调用那个看似神奇的parallel操作时,了解背后到底发生了什么是很有必要的。
那到底要怎么利用多核处理器,用流来高效地并行求和呢?我们在使用流的数值范围部分中讨论了一个叫LongStream.rangeClosed的方法。这个方法与iterate相比有两个优点。
LongStream.rangeClosed直接产生原始类型的long数字,没有装箱拆箱的开销。LongStream.rangeClosed会生成数字范围,很容易拆分为独立的小块。例如,范围1~20可分为1~5、6~10、11~15和16~20。
先看一下它用于顺序流时的性能如何,看看拆箱的开销到底要不要紧:
public static long rangedSum(long n) {
return LongStream.rangeClosed(1, n).reduce(0L, Long:: sum);
}
这一次的输出是:
Ranged sum done in: 17 msecs
这个数值流比前面那个用iterate工厂方法生成数字的顺序执行版本要快得多,因为数值流避免了非针对性流那些没必要的自动装箱和拆箱操作。由此可见,选择适当的数据结构往往比并行化算法更重要。但要是对这个新版本应用并行流呢?
public static long parallelRangedSum(long n) {
return LongStream.rangeClosed(1, n).parallel().reduce(0L, Long:: sum);
}
现在把这个函数传给你的测试方法:
System.out.println("Parallel range sum done in:" +
measureSumPerf(ParallelStreams:: parallelRangedSum, 10_000_000) + " msecs");
你会得到:
Parallel range sum done in: 1 msecs
终于,我们得到了一个比顺序执行更快的并行归纳,因为这一次归纳操作可以像将顺序流转换为并行流部分中的图那样执行了。这也表明,使用正确的数据结构然后使其并行工作能够保证最佳的性能。
从性能角度来看,使用正确的数据结构,如尽可能利用原始流而不是一般化的流,几乎总是比尝试并行化某些操作更为重要。
尽管如此,请记住,并行化并不是没有代价的。并行化过程本身需要对流做递归划分,把每个子流的归纳操作分配到不同的线程,然后把这些操作的结果合并成一个值。但在多个内核之间移动数据的代价也可能比你想的要大,所以很重要的一点是要保证在内核中并行执行工作的时间比在内核之间传输数据的时间长。总而言之,很多情况下不可能或不方便并行化。然而,在使用并行Stream加速代码之前,你必须确保用得对;如果结果错了,算得快就毫无意义了。
正确使用并行流
错用并行流而产生错误的首要原因,就是使用的算法改变了某些共享状态。下面是另一种实现对前n个自然数求和的方法,但这会改变一个共享累加器:
public static long sideEffectSum(long n) {
Accumulator accumulator = new Accumulator();
LongStream.rangeClosed(1, n).forEach(accumulator:: add);
return accumulator.total;
}
public class Accumulator {
public long total = 0;
public void add(long value) {
total += value;
}
}
这种代码非常普遍,特别是对那些熟悉指令式编程范式的程序员来说。这段代码和你习惯的那种指令式迭代数字列表的方式很像:初始化一个累加器,一个个遍历列表中的元素,把它们和累加器相加。
那这种代码又有什么问题呢?因为它在本质上就是顺序的。每次访问total都会出现数据竞争。如果你尝试用同步来修复,那就完全失去并行的意义了。为了说明这一点,让我们试着把Stream变成并行的:
public static long sideEffectParallelSum(long n) {
Accumulator accumulator = new Accumulator();
LongStream.rangeClosed(1, n).parallel().forEach(accumulator:: add);
return accumulator.total;
}
用前面的测试框架来执行这个方法,并打印每次执行的结果:
System.out.println("SideEffect parallel sum done in: " +
measurePerf(ParallelStreams:: sideEffectParallelSum, 10_000_000L) +" msecs" );
你可能会得到类似于下面这种输出:
Result: 5959989000692
Result: 7425264100768
Result: 6827235020033
Result: 7192970417739
Result: 6714157975331
Result: 7497810541907
Result: 6435348440385
Result: 6999349840672
Result: 7435914379978
Result: 7715125932481
SideEffect parallel sum done in: 49 msecs
这回方法的性能无关紧要了,唯一要紧的是每次执行都会返回不同的结果,都离正确值50000005000000差很远。这是由于多个线程在同时访问累加器,执行total += value,而这一句虽然看似简单,却不是一个原子操作。问题的根源在于,forEach中调用的方法有副作用,它会改变多个线程共享的对象的可变状态。要是你想用并行Stream又不想引发类似的意外,就必须避免这种情况。
现在你知道了,共享可变状态会影响并行流以及并行计算。记住要避免共享可变状态,确保并行Stream得到正确的结果。
高效使用并行流
下面提出一些定性意见,帮你决定某个特定情况下是否有必要使用并行流。
- 如果有疑问,测量。把顺序流转成并行流轻而易举,但却不一定是好事。并行流并不总是比顺序流快。此外,并行流有时候会和你的直觉不一致,所以在考虑选择顺序流还是并行流时,第一个也是最重要的建议就是用适当的基准来检查其性能。
- 留意装箱。自动装箱和拆箱操作会大大降低性能。
Java 8中有原始类型流(IntStream、LongStream、DoubleStream)来避免这种操作,但凡有可能都应该用这些流。 - 有些操作本身在并行流上的性能就比顺序流差。特别是
limit和findFirst等依赖于元素顺序的操作,它们在并行流上执行的代价非常大。例如,findAny会比findFirst性能好,因为它不一定要按顺序来执行。你总是可以调用unordered方法来把有序流变成无序流。那么,如果你需要流中的n个元素而不是专门要前n个的话,对无序并行流调用limit可能会比单个有序流(比如数据源是一个List)更高效。 - 还要考虑流的操作流水线的总计算成本。设
N是要处理的元素的总数,Q是一个元素通过流水线的大致处理成本,则N*Q就是这个对成本的一个粗略的定性估计。Q值较高就意味着使用并行流时性能好的可能性比较大。 - 对于较小的数据量,选择并行流几乎从来都不是一个好的决定。并行处理少数几个元素的好处还抵不上并行化造成的额外开销。
- 要考虑流背后的数据结构是否易于分解。例如,
ArrayList的拆分效率比LinkedList高得多,因为前者用不着遍历就可以平均拆分,而后者则必须遍历。另外,用range工厂方法创建的原始类型流也可以快速分解。 - 流自身的特点,以及流水线中的中间操作修改流的方式,都可能会改变分解过程的性能。例如,一个
SIZED流可以分成大小相等的两部分,这样每个部分都可以比较高效地并行处理,但筛选操作可能丢弃的元素个数却无法预测,导致流本身的大小未知。 - 还要考虑终端操作中合并步骤的代价是大是小(例如
Collector中的combiner方法)。如果这一步代价很大,那么组合每个子流产生的部分结果所付出的代价就可能会超出通过并行流得到的性能提升。
虽然并行处理一个流很容易,却不能保证程序在所有情况下都运行得更快。并行软件的行为和性能有时是违反直觉的,因此一定要测量,确保你并没有把程序拖得更慢。
像并行流那样对一个数据集并行执行操作可以提升性能,特别是要处理的元素数量庞大,或处理单个元素特别耗时的时候。
下表按照可分解性总结了一些流数据源适不适于并行。
| 源 | 可分解性 |
|---|---|
| ArrayList | 极佳 |
| LinkedList | 差 |
| IntStream.range | 极佳 |
| Stream.iterate | 差 |
| HashSet | 好 |
| TreeSet | 好 |
分支/合并框架
并行流背后使用的基础架构是Java 7中引入的分支/合并框架。
分支/合并框架让你得以用递归方式将可以并行的任务拆分成更小的任务,在不同的线程上执行,然后将各个子任务的结果合并起来生成整体结果。
分支/合并框架的目的是以递归方式将可以并行的任务拆分成更小的任务,然后将每个子任务的结果合并起来生成整体结果。它是ExecutorService接口的一个实现,它把子任务分配给线程池(称为ForkJoinPool)中的工作线程。首先来看看如何定义任务和子任务。
使用RecursiveTask
要把任务提交到这个池,必须创建RecursiveTask的一个子类,其中R是并行化任务(以及所有子任务)产生的结果类型,或者如果任务不返回结果,则是RecursiveAction类型(当然它可能会更新其他非局部机构)。要定义RecursiveTask,只需实现它唯一的抽象方法compute:
protected abstract R compute();
这个方法同时定义了将任务拆分成子任务的逻辑,以及无法再拆分或不方便再拆分时,生成单个子任务结果的逻辑。正由于此,这个方法的实现类似于下面的伪代码:
if(任务足够小或不可分){
顺序计算该任务
}else{
将任务分成两个子任务
递归调用本方法,拆分每个子任务,等待所有子任务完成
合并每个子任务的结果
}
递归的任务拆分过程如下图所示。
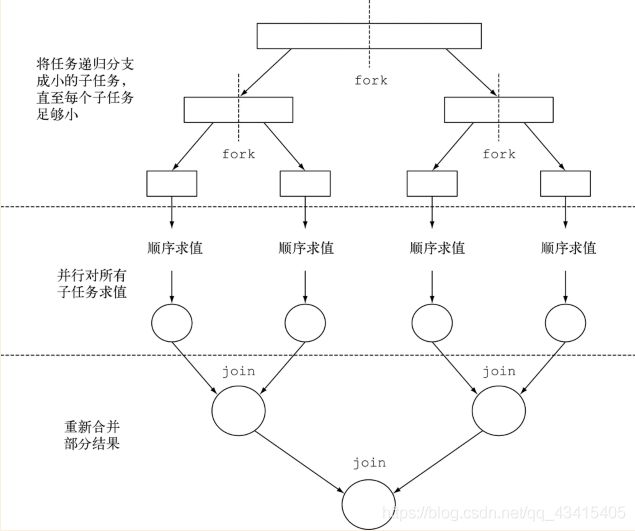
这是著名的分治算法的并行版本。这里举一个用分支/合并框架的实际例子,还以前面的例子为基础,让我们试着用这个框架为一个数字范围(这里用一个long[]数组表示)求和。如前所述,你需要先为RecursiveTask类做一个实现,就是下面的ForkJoinSumCalculator。
//继承RecursiveTask来创建可以用于分支/合并框架的任务
public class ForkJoinSumCalculator extends java.util.concurrent.RecursiveTask<Long> {
//要求和的数组
private final long[] numbers;
//子任务处理的数组的起始和终止位置
private final int start;
private final int end;
//不再将任务分解为子任务的数组大小
public static final long THRESHOLD = 10_000;
//公共构造函数用于创建主任务
public ForkJoinSumCalculator(long[] numbers) {
this(numbers, 0, numbers.length);
}
//私有构造函数用于以递归方式为主任务创建子任务
private ForkJoinSumCalculator(long[] numbers, int start, int end) {
this.numbers = numbers;
this.start = start;
this.end = end;
}
@Override
protected Long compute() { //覆盖RecursiveTask抽象方法
//该任务负责求和的部分的大小
int length = end - start;
//如果大小小于或等于阈值,顺序计算结果
if (length <= THRESHOLD) {
return computeSequentially();
}
//创建一个子任务来为数组的前一半求和
ForkJoinSumCalculator leftTask
= new ForkJoinSumCalculator(numbers, start, start+length/2);
//利用另一个ForkJoinPool线程异步执行新创建的子任务
leftTask.fork();
//创建一个任务为数组的后一半求和
ForkJoinSumCalculator rightTask
= new ForkJoinSumCalculator(numbers, start+length/2, end);
//同步执行第二个子任务,有可能允许进一步递归划分
Long rightResult = rightTask.compute();
//读取第一个子任务的结果,如果尚未完成就等待
Long leftResult = leftTask.join();
//该任务的结果是两个子任务结果的组合
return leftResult + rightResult;
}
//在子任务不再可分时计算结果的简单算法
private long computeSequentially() {
long sum = 0;
for(int i = start; i < end; i++) {
sum += numbers[i];
}
return sum;
}
}
现在编写一个方法来并行对前n个自然数求和就很简单了。你只需把想要的数字数组传给ForkJoinSumCalculator的构造函数:
public static long forkJoinSum(long n){
long[] numbers=LongStream.rangeClosed(1,n).toArray();
ForkJoinTask<Long> task=new ForkJoinSumCalculator(numbers);
return new ForkJoinPool().invoke(task);
}
这里用了一个LongStream来生成包含前n个自然数的数组,然后创建一个ForkJoinTask(RecursiveTask的父类),并把数组传递给上面所示ForkJoinSumCalculator的公共构造函数。最后,你创建了一个新的ForkJoinPool,并把任务传给它的调用方法。在ForkJoinPool中执行时,最后一个方法返回的值就是ForkJoinSumCalculator类定义的任务结果。
请注意在实际应用时,使用多个ForkJoinPool是没有什么意义的。正是出于这个原因,一般来说把它实例化一次,然后把实例保存在静态字段中,使之成为单例,这样就可以在软件中任何部分方便地重用了。这里创建时用了其默认的无参数构造函数,这意味着想让线程池使用JVM能够使用的所有处理器。更确切地说,该构造函数将使用Runtime.availableProcessors的返回值来决定线程池使用的线程数。请注意availableProcessors方法虽然看起来是处理器,但它实际上返回的是可用内核的数量,包括超线程生成的虚拟内核。
当把ForkJoinSumCalculator任务传给ForkJoinPool时,这个任务就由池中的一个线程执行,这个线程会调用任务的compute方法。该方法会检查任务是否小到足以顺序执行,如果不够小则会把要求和的数组分成两半,分给两个新的ForkJoinSumCalculator,而它们也由ForkJoinPool安排执行。因此,这一过程可以递归重复,把原任务分为更小的任务,直到满足不方便或不可能再进一步拆分的条件(本例中是求和的项目数小于等于10000)。这时会顺序计算每个任务的结果,然后由分支过程创建的(隐含的)任务二叉树遍历回到它的根。接下来会合并每个子任务的部分结果,从而得到总任务的结果。这一过程如下图所示。
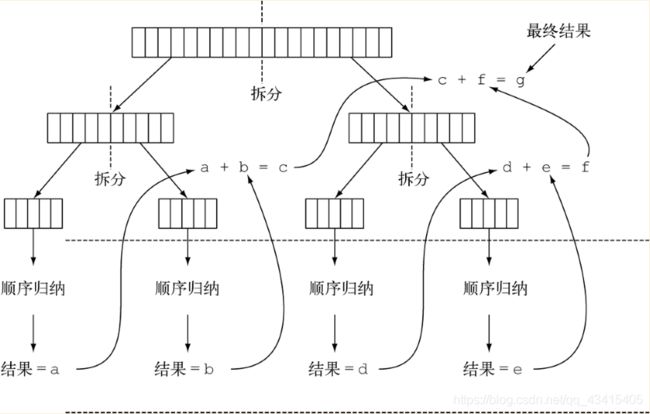
你可以再用一次前面写的测试框架,来看看显式使用分支/合并框架的求和方法的性能:
System.out.println("ForkJoin sum done in : "+measureSumPerf(
ForkJoinSumCalculator:: forkJoinSum, 10_000_000) + " msecs");
它生成以下输出:
ForkJoin sum done in: 41 msecs
这个性能看起来比用并行流的版本要差,但这只是因为必须先要把整个数字流都放进一个long[],之后才能在ForkJoinSumCalculator任务中使用它。
使用分支/合并框架的最佳做法
虽然分支/合并框架还算简单易用,但它也很容易被误用。以下是几个有效使用它的最佳做法。
- 对一个任务调用
join方法会阻塞调用方,直到该任务做出结果。因此,有必要在两个子任务的计算都开始之后再调用它。否则,你得到的版本会比原始的顺序算法更慢更复杂,因为每个子任务都必须等待另一个子任务完成才能启动。 - 不应该在
RecursiveTask内部使用ForkJoinPool的invoke方法。相反,你应该始终直接调用compute或fork方法,只有顺序代码才应该用invoke来启动并行计算。 - 对子任务调用
fork方法可以把它排进ForkJoinPool。同时对左边和右边的子任务调用它似乎很自然,但这样做的效率要比直接对其中一个调用compute低。这样做你可以为其中一个子任务重用同一线程,从而避免在线程池中多分配一个任务造成的开销。 - 调试使用分支/合并框架的并行计算可能有点棘手。特别是你平常都在你喜欢的
IDE里面看栈跟踪(stacktrace)来找问题,但放在分支-合并计算上就不行了,因为调用compute的线程并不是概念上的调用方,后者是调用fork的那个。 - 和并行流一样,你不应理所当然地认为在多核处理器上使用分支/合并框架就比顺序计算快。一个任务可以分解成多个独立的子任务,才能让性能在并行化时有所提升。所有这些子任务的运行时间都应该比分出新任务所花的时间长;一个惯用方法是把输入/输出放在一个子任务里,计算放在另一个里,这样计算就可以和输入/输出同时进行。此外,在比较同一算法的顺序和并行版本的性能时还有别的因素要考虑。就像任何其他
Java代码一样,分支/合并框架需要“预热”或者说要执行几遍才会被JIT编译器优化。这就是为什么在测量性能之前跑几遍程序很重要,我们的测试框架就是这么做的。同时还要知道,编译器内置的优化可能会为顺序版本带来一些优势(例如执行死码分析——删去从未被使用的计算)。
工作窃取
在ForkJoinSumCalculator的例子中,我们决定在要求和的数组中最多包含10000个项目时就不再创建子任务了。这个选择是很随意的,但大多数情况下也很难找到一个好的启发式方法来确定它,只能试几个不同的值来尝试优化它。在我们的测试案例中,我们先用了一个有1000万项目的数组,意味着ForkJoinSumCalculator至少会分出1000个子任务来。这似乎有点浪费资源,因为我们用来运行它的机器上只有四个内核。在这个特定例子中可能确实是这样,因为所有的任务都受CPU约束,预计所花的时间也差不多。
但分出大量的小任务一般来说都是一个好的选择。这是因为,理想情况下,划分并行任务时,应该让每个任务都用完全相同的时间完成,让所有的CPU内核都同样繁忙。但实际中,每个子任务所花的时间可能天差地别,要么是因为划分策略效率低,要么是有不可预知的原因,比如磁盘访问慢,或是需要和外部服务协调执行。
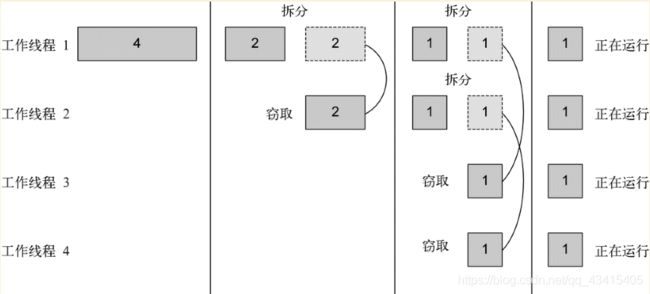
分支/合并框架工程用一种称为工作窃取(work stealing)的技术来解决这个问题。在实际应用中,这意味着这些任务差不多被平均分配到ForkJoinPool中的所有线程上。每个线程都为分配给它的任务保存一个双向链式队列,每完成一个任务,就会从队列头上取出下一个任务开始执行。基于前面所述的原因,某个线程可能早早完成了分配给它的所有任务,也就是它的队列已经空了,而其他的线程还很忙。这时,这个线程并没有闲下来,而是随机选了一个别的线程,从队列的尾巴上“偷走”一个任务。这个过程一直继续下去,直到所有的任务都执行完毕,所有的队列都清空。这就是为什么要划成许多小任务而不是少数几个大任务,这有助于更好地在工作线程之间平衡负载。
一般来说,这种工作窃取算法用于在池中的工作线程之间重新分配和平衡任务。下图展示了这个过程。当工作线程队列中有一个任务被分成两个子任务时,一个子任务就被闲置的工作线程“偷走”了。如前所述,这个过程可以不断递归,直到规定子任务应顺序执行的条件为真。
Spliterator
Spliterator定义了并行流如何拆分它要遍历的数据。
Spliterator是Java 8中加入的另一个新接口;这个名字代表“可分迭代器”(splitable iterator)。和Iterator一样,Spliterator也用于遍历数据源中的元素,但它是为了并行执行而设计的。虽然在实践中可能用不着自己开发Spliterator,但了解一下它的实现方式会让你对并行流的工作原理有更深入的了解。Java 8已经为集合框架中包含的所有数据结构提供了一个默认的Spliterator实现。集合实现了Spliterator接口,接口提供了一个spliterator方法。这个接口定义了若干方法,如下所示。
public interface Spliterator<T>{
boolean tryAdvance(Consumer<? super T> action);
Spliterator<T> trySplit();
long estimateSize();
int characteristics();
}
与往常一样,T是Spliterator遍历的元素的类型。tryAdvance方法的行为类似于普通的Iterator,因为它会按顺序一个一个使用Spliterator中的元素,并且如果还有其他元素要遍历就返回true。但trySplit是专为Spliterator接口设计的,因为它可以把一些元素划出去分给第二个Spliterator(由该方法返回),让它们两个并行处理。Spliterator还可通过estimateSize方法估计还剩下多少元素要遍历,因为即使不那么确切,能快速算出来是一个值也有助于让拆分均匀一点。
重要的是,要了解这个拆分过程在内部是如何执行的,以便在需要时能够掌控它。
拆分过程
将Stream拆分成多个部分的算法是一个递归过程,如下图所示。
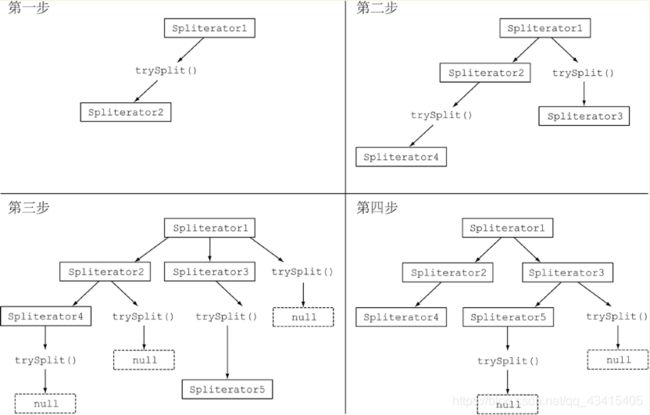
第一步是对第一个Spliterator调用trySplit,生成第二个Spliterator。第二步对这两个Spliterator调用trysplit,这样总共就有了四个Spliterator。这个框架不断对Spliterator调用trySplit直到它返回null,表明它处理的数据结构不能再分割,如第三步所示。最后,这个递归拆分过程到第四步就终止了,这时所有的Spliterator在调用trySplit时都返回了null。
这个拆分过程也受Spliterator本身的特性影响,而特性是通过characteristics方法声明的。
Spliterator的特性
Spliterator接口声明的最后一个抽象方法是characteristics,它将返回一个int,代表Spliterator本身特性集的编码。使用Spliterator的客户可以用这些特性来更好地控制和优化它的使用。下表总结了这些特性。(虽然它们在概念上与收集器的特性有重叠,但编码却不一样。)
| 特性 | 含义 |
|---|---|
| ORDERED | 元素有既定的顺序(例如List),因此Spliterator在遍历和划分时也会遵循这一顺序 |
| DISTINCT | 对于任意一对遍历过的元素x和y,x.equals(y)返回false |
| SORTED | 遍历的元素按照一个预定义的顺序排序 |
| SIZED | 该Spliterator由一个已知大小的源建立(例如Set),因此estimatedSize()返回的是准确值 |
| NONNULL | 保证遍历的元素不会为null |
| IMMUTABLE | Spliterator的数据源不能修改。这意味着在遍历时不能添加、删除或修改任何元素 |
| CONCURRENT | 该Spliterator的数据源可以被其他线程同时修改而无需同步 |
| SUBSIZED | 该Spliterator和所有从它拆分出来的Spliterator都是SIZED |
实现你自己的Spliterator
让我们来看一个可能需要你自己实现Spliterator的实际例子。我们要开发一个简单的方法来数数一个String中的单词数。这个方法的一个迭代版本可以写成下面的样子。
public int countWordsIteratively(String s){
int counter=0;
boolean lastSpace=true;
for(char c : s.toCharArray()){ //逐个遍历String中的所有字符
if(Character.isWhitespace(c)){
lastSpace=true;
}else{
if(lastSpace)
counter++; //上一个字符是空格,而当前遍历的字符不是空格时,将单词计数器加一
lastSpace=false;
}
}
return counter;
}
把这个方法用在但丁的《神曲》的《地狱篇》的第一句话上:
final String SENTENCE = " Nel mezzo del cammin di nostra vita " +
"mi ritrovai in una selva oscura" +
" ché la dritta via era smarrita ";
System.out.println("Found " + countWordsIteratively(SENTENCE) + " words");
我们在句子里添加了一些额外的随机空格,以演示这个迭代实现即使在两个词之间存在多个空格时也能正常工作。正如我们所料,这段代码将打印以下内容:
Found 19 words
理想情况下,你会想要用更为函数式的风格来实现它,因为就像前面说过的,这样你就可以用并行Stream来并行化这个过程,而无需显式地处理线程和同步问题。
以函数式风格重写单词计数器
首先你需要把String转换成一个流。但原始类型的流仅限于int、long和double,所以你只能用Stream:
Stream<Character> stream=IntStream.range(0,SENTENCE.length())
.mapToObj(SENTENCE:: charAt);
你可以对这个流做归约来计算字数。在归约流时,你得保留由两个变量组成的状态:一个int用来计算到目前为止数过的字数,还有一个boolean用来记得上一个遇到的Character是不是空格。因为Java没有元组(tuple,用来表示由异类元素组成的有序列表的结构,不需要包装对象),所以你必须创建一个新类WordCounter来把这个状态封装起来,如下所示。
class WordCounter{
private final int counter;
private final boolean lastSpace;
public WordCounter(int counter,boolean lastSpace){
this.counter=counter;
this.lastSpace=lastSpace;
}
//和迭代算法一样,accumulate方法一个个遍历Character
public WordCounter accumulate(Character c){
//上一个字符是空格,而当前遍历的字符不是空格时,将单词计数器加一
if(Character.isWhitespace(c)){
return lastSpace ?
this : new WordCounter(counter, true);
}else{
return lastSpace ?
new WordCounter(counter+1,false) : this;
}
}
//合并两个Word-Counter,把其计数器加起来
public WordCounter combine(WordCounter wordCounter){
//仅需要计数器的总和,无需关心lastSpace
return new WordCounter(counter + wordCounter.counter, wordCounter.lastSpace);
}
public int getCounter(){
return counter;
}
}
在这个列表中,accumulate方法定义了如何更改WordCounter的状态,或更确切地说是用哪个状态来建立新的WordCounter,因为这个类是不可变的。每次遍历到Stream中的一个新的Character时,就会调用accumulate方法。具体来说,就像实现你自己的Spliterator部分中的countWordsIteratively方法一样,当上一个字符是空格,新字符不是空格时,计数器就加一。下图展示了accumulate方法遍历到新的Character时,WordCounter的状态转换。

调用第二个方法combine时,会对作用于Character流的两个不同子部分的两个WordCounter的部分结果进行汇总,也就是把两个WordCounter内部的计数器加起来。
现在已经写好了在WordCounter中累计字符,以及在WordCounter中把它们结合起来的逻辑,那写一个方法来归约Character流就很简单了:
private int countWords(Stream<Character> stream){
WordCounter wordCounter=stream.reduce(new WordCounter(0,true),
WordCounter:: accumulate,
WordCounter:: combine);
return wordCounter.getCounter();
}
现在可以试一试这个方法,给它由包含但丁的《神曲》中《地狱篇》第一句的String创建的流:
Stream<Character> stream=IntStream.range(0,SENTENCE.length())
.mapToObj(SENTENCE:: charAt);
System.out.println("Found "+countWords(stream)+" words");
可以和迭代版本比较一下输出:
Found 19 words
到现在为止都很好,但我们以函数式实现WordCounter的主要原因之一就是能轻松地并行处理,下面来看看具体是如何实现的。
让WordCounter并行工作
尝试用并行流来加快字数统计,如下所示:
System.out.println("Found"+countWords(stream.parallel())+"words");
这次的输出是:
Found 25 words
问题的根源并不难找。因为原始的String在任意位置拆分,所以有时一个词会被分为两个词,然后数了两次。这就说明,拆分流会影响结果,而把顺序流换成并行流就可能使结果出错。
如何解决这个问题呢?解决方案就是要确保String不是在随机位置拆开的,而只能在词尾拆开。要做到这一点,你必须为Character实现一个Spliterator,它只能在两个词之间拆开String(如下所示),然后由此创建并行流。
class WordCounterSpliterator implements Spliterator<Character>{
private final String string;
private int currentChar=0;
public WordCounterSpliterator(String string){
this.string=string;
}
@Override
public boolean tryAdvance(Consumer<? super Character> action){
action.accept(string.charAt(currentChar++)); //处理当前字符
return currentChar<string.length(); //如果还有字符要处理,则返回true
}
@Override
public Spliterator<Character>trySplit(){
int currentSize=string.length()-currentChar;
if(currentSize < 10){
return null; //返回null表示要解析的String已经足够小,可以顺序处理
}
//将试探拆分位置设定为要解析的String的中间
for(int splitPos = currentSize / 2 + currentChar; splitPos < string.length(); splitPos++){
//让拆分位置前进直到下一个空格
if(Character.isWhitespace(string.charAt(splitPos))){
//创建一个新WordCounter-Spliterator来解析String从开始到拆分位置的部分
Spliterator<Character> spliterator=
new WordCounterSpliterator(string.substring(currentChar,splitPos));
//将这个WordCounter-Spliterator的起始位置设为拆分位置
currentChar=splitPos;
return spliterator;
}
}
return null;
}
@Override
public long estimateSize(){
return string.length() - currentChar;
}
@Override
public int characteristics(){
return ORDERED + SIZED + SUBSIZED + NONNULL + IMMUTABLE;
}
}
这个Spliterator由要解析的String创建,并遍历了其中的Character,同时保存了当前正在遍历的字符位置。下面是实现了Spliterator接口的WordCounterSpliterator中的各个函数。
tryAdvance方法把String中当前位置的Character传给了Consumer,并让位置加一。作为参数传递的Consumer是一个Java内部类,在遍历流时将要处理的Character传给了一系列要对其执行的函数。这里只有一个归约函数,即WordCounter类的accumulate方法。如果新的指针位置小于String的总长,且还有要遍历的Character,则tryAdvance返回true。trySplit方法是Spliterator中最重要的一个方法,因为它定义了拆分要遍历的数据结构的逻辑。就像在使用RecursiveTask部分中实现的RecursiveTask的compute方法一样(分支/合并框架的使用方式),首先要设定不再进一步拆分的下限。这里用了一个非常低的下限——10个Character,仅仅是为了保证程序会对那个比较短的String做几次拆分。在实际应用中,就像分支/合并的例子那样,你肯定要用更高的下限来避免生成太多的任务。如果剩余的Character数量低于下限,你就返回null表示无需进一步拆分。相反,如果你需要执行拆分,就把试探的拆分位置设在要解析的String块的中间。但我们没有直接使用这个拆分位置,因为要避免把词在中间断开,于是就往前找,直到找到一个空格。一旦找到了适当的拆分位置,就可以创建一个新的Spliterator来遍历从当前位置到拆分位置的子串;把当前位置this设为拆分位置,因为之前的部分将由新Spliterator来处理,最后返回。- 还需要遍历的元素的
estimatedSize就是这个Spliterator解析的String的总长度和当前遍历的位置的差。 - 最后,
characteristic方法告诉框架这个Spliterator是ORDERED(顺序就是String中各个Character的次序)、SIZED(estimatedSize方法的返回值是精确的)、SUBSIZED(trySplit方法创建的其他Spliterator也有确切大小)、NONNULL(String中不能有为null的Character)和IMMUTABLE(在解析String时不能再添加Character,因为String本身是一个不可变类)的。
运用WordCounterSpliterator
现在就可以用这个新的WordCounterSpliterator来处理并行流了,如下所示:
Spliterator<Character> spliterator=new WordCounterSpliterator(SENTENCE);
Stream<Character> stream=StreamSupport.stream(spliterator,true);
传给StreamSupport.stream工厂方法的第二个布尔参数意味着你想创建一个并行流。把这个并行流传给countWords方法:
System.out.println("Found "+countWords(stream)+" words");
可以得到意料之中的正确输出:
Found 19 words
Spliterator还有最后一个值得注意的功能,就是可以在第一次遍历、第一次拆分或第一次查询估计大小时绑定元素的数据源,而不是在创建时就绑定。这种情况下,它称为延迟绑定(late-binding)的Spliterator。