识别MNIST数据集之(一):读取数据
1.下载数据集
MNIST是一个标注的手写数据集,可以用来测试你的网络是否成功,你可以从这个网站下载数据集
http://yann.lecun.com/exdb/mnist/
可以看到它分为四个部分,分别是训练图片的图像和标签,以及训练数据的图像和标签,我们需要分别对他们进行读入
在读入之前,我们还需要用np.zeros申请空间,方便追加数据
self.train_img_list = np.zeros((self.N, 28 * 28))
self.train_label_list = np.zeros((self.N, 1))2.读入数据集
这里的数据被用python的struct打包成了二进制文件,我们需要python.struct来把这些数据读入进来
首先我们把文件用二进制的方式读进来
binfile = open(filename,'rb')
buf = binfile.read()然后用struct进行解包
struct.unpack_from( '>IIII', buf, index )这个函数的意思就是,从buf的index这个地方,用大段序的方法读4个unsigned int32,这里面包含了图像数量,行数,列数一些元信息。
读完了之后,我们就调整读指针的位置
index += struct.calcsize('>IIII')2.1读入图像数据
然后每次读取784B的数据,就是图像的信息了
im = struct.unpack_from('>784B', buf, index)
index += struct.calcsize('>784B') def read_train_images(self,filename):
binfile = open(filename, 'rb')
buf = binfile.read()
index = 0
magic, self.train_img_num, self.numRows, self.numColums = struct.unpack_from('>IIII', buf, index)
print magic, ' ', self.train_img_num, ' ', self.numRows, ' ', self.numColums
index += struct.calcsize('>IIII')
for i in range(self.train_img_num):
im = struct.unpack_from('>784B', buf, index)
index += struct.calcsize('>784B')
im = np.array(im)
im = im.reshape(1, 28 * 28)
self.train_img_list[ i , : ] = im
plt.imshow(im, cmap='binary') # 黑白显示
plt.show()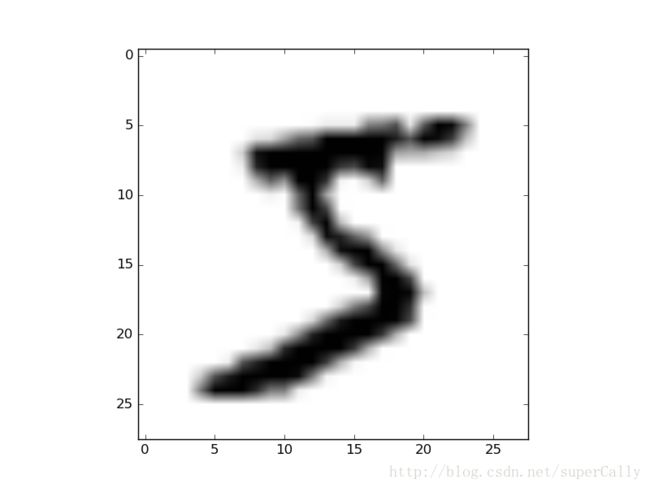
2.2读入标签数据
每次读入2个unsigned int的元数据,并且相应的调整位置,代码如下
magic, self.train_label_num = struct.unpack_from('>II', buf, index)
index += struct.calcsize('>II')
for i in range(self.train_label_num):
# for x in xrange(2000):
label_item = int(struct.unpack_from('>B', buf, index)[0])
self.train_label_list[ i , : ] = label_item
index += struct.calcsize('>B')3.其他数据
除了训练数据以外还有测试用的数据,读法也和上面读训练数据一样,成功读完之后就可以开始训练了