基于ALS推荐系统
文章目录
- 推荐系统Spark实现
- 相关概念
- 相似度
- 偏好矩阵
- ALS算法(交替最小二乘法)
- 核心代码
- 项目实现
- 基于用户的电影推荐算法
- 基于商品的用户推荐算法(不建议使用此模型)
- 实现思路
- 模型的保存与加载
推荐系统Spark实现
推荐系统模型是基于协同过滤思想实现
- 基于用户的协同过滤(User)
- 基于物品的协同过滤(Item)
相关概念
相似度
概念:无论是基于用户还是基于物品的推荐,其本质思想是计算用户和用户之间的相似度,或者计算物品和物品之间相似度,所以我们可以用常见的一些距离来进行衡量,比如欧氏距离,马氏距离,曼哈顿距离等,也可以使用夹角余弦相似度来衡量。目前,主流做法是通过夹角余弦相似度来实现。
- 基于欧式距离‘

- 基于向量夹角余弦
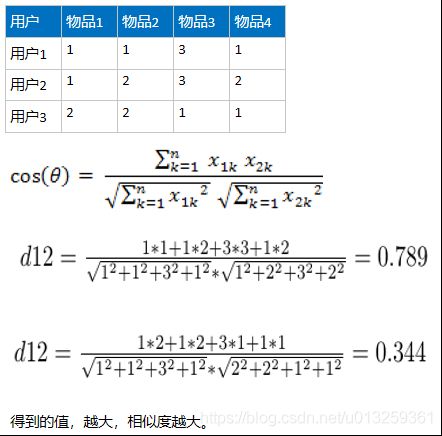
cosθ = 1完全正相关
0 < cosθ < 1 一定程度的正相关
cos90 = 0 没有相关性
-1 < cosθ < 0 一定程度的负相关
cosθ = -1 完全负相关
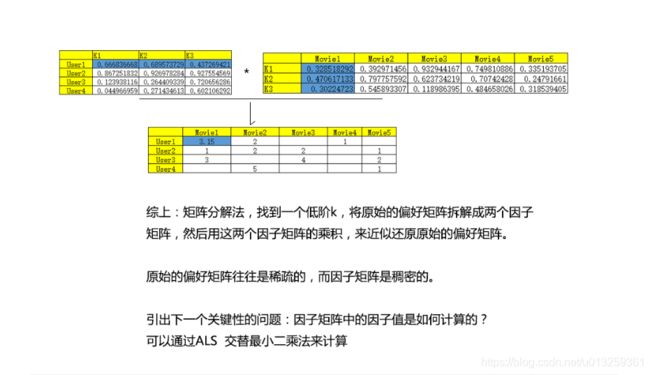
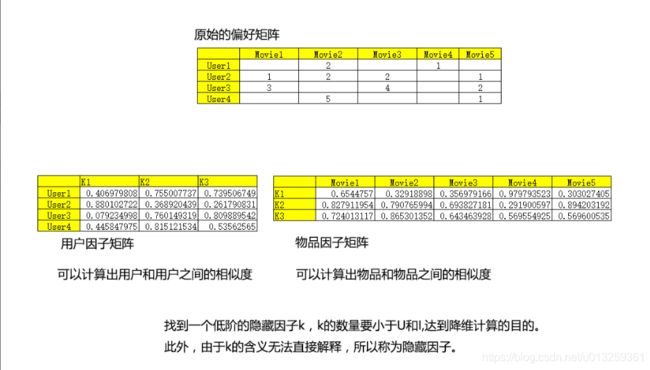
偏好矩阵
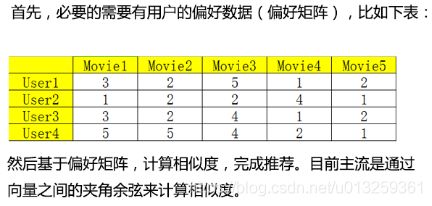
但是生产环境中偏好矩阵往往是稀疏的
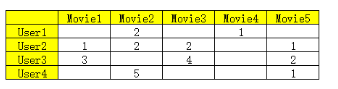
所以需要对空缺值进行处理,不能简单设置为0或者某个特定值,因为会导致最后计算的相似度不够准确,使得最终的推荐系统模型失去价值。所以需要某种算法将空缺值预测出来。
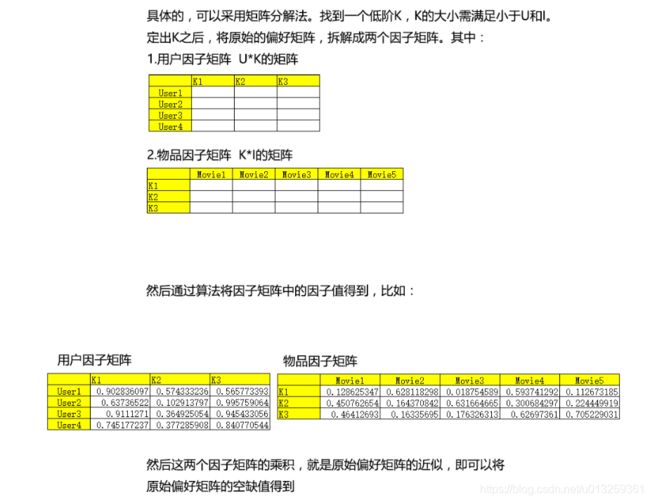
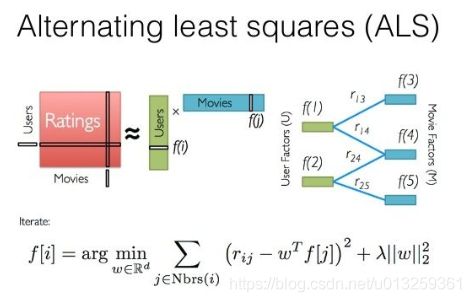
ALS算法(交替最小二乘法)
原理:多次迭代,求解一系列最小二乘法回归问题。每一次迭代时,固定(随机生成因子值)某一个因子矩阵,更新另外一个因子矩阵,然后计算误差平方和,如此迭代,直到模型收敛。
ALS只计算已知打分的重构误差
核心代码
这是ALS算法类的源码
case class Rating(user: Int, product: Int, rating: Double)
其中Rating是固定的ALS输入格式,它要求是一个元组类型的数据,其中的数值分别为[Int,Int,Double],因此在数据集建立时,用户名和物品名分别用数值代替,而最后的评分没有变化。
在这个类里,ALS.tran方法是最为重要的方法。这个方法有几个重要参数:
- 1)numBlocks:并行计算的block数(-1为自动配置);
- 2)rank:对应ALS模型中的因子个数,也就是在低阶近似矩阵中的隐含特征个数。因子个数一般越多越好。但它也会直接影响模型训练和保存时所需的内存开销,尤其是在用户和物品很多的时候。因此实践中该参数常作为训练效果与系统开销之间的调节参数。通常,其合理取值为10到200。
- 3)iterations:对应运行时的迭代次数。ALS能确保每次迭代都能降低评级矩阵的重建误差,但一般经少数次迭代后ALS模型便已能收敛为一个比较合理的好模型。这样,大部分情况下都没必要迭代太多次(10次左右一般就挺好)
- 4)lambda:ALS中的正则化参数,控制模型的过拟合情况。其值越高,正则化越严厉。该参数的赋值与实际数据的大小、特征和稀疏程度有关。
- 5)implicitPref:使用显示反馈ALS变量或隐式反馈;
- 6)alpha:ALS隐式反馈变化率用于控制每次拟合修正的幅度。
这些参数协同作用从而控制ALS算法的模型训练。
项目实现
数据集:
在这里插入代码片
基于用户的电影推荐算法
import org.apache.spark.mllib.recommendation.{ALS, Rating}
import org.apache.spark.{SparkConf, SparkContext}
object Driver01 {
def main(args: Array[String]): Unit = {
//196 242 3 881250949
val conf = new SparkConf().setMaster("local").setAppName("movies")
val sc = new SparkContext(conf)
val data = sc.textFile("D://data/u.data", 4)
//电影信息文件
val moviedata = sc.textFile("D://data/u.item", 4)
//ALS模型需要RDD[Ratings]类型参数
val res = data.map(line=>{
val info = line.split("\t")
val userId = info(0).toInt
val itemId = info(1).toInt
val rating = info(2).toDouble
Rating(userId,itemId, rating)
})
val mv_res = moviedata.map(line=>{
var info = line.split("\\|")
val m_id= info(0).toInt
val m_name = info(1)
(m_id, m_name)
}).collectAsMap() //转成map方便根据itenid查询name
res.foreach(println(_))
val model = ALS.train(res, 20, 10, 0.01)
val resMovies = model.recommendProducts(789, 10).map(rat=>{
val userID = rat.user
val product = rat.product
val score = rat.rating
val m_name = mv_res.apply(product)
(userID, m_name, score)
})
// resMovies.foreach(println(_))
//检验推荐系统的准确性
//获取789用户看过的所有电影
//keyby 和 lookup一般都是成对使用的
var u789movie = res.keyBy(rat=>rat.user).lookup(789)
val u789top10 = u789movie.sortBy(rat=> -rat.rating).take(10)
val RDD_Top10 = sc.makeRDD(u789top10).map(rat=>{
val userID = rat.user
val product = rat.product
val score = rat.rating
val m_name = mv_res.apply(product)
(userID, m_name, score)
})
// RDD_Top10.foreach(println(_))
//模型的存储
model.save(sc, "hdfs://hadoop01:9000/ALSmovie")
}
}
基于商品的用户推荐算法(不建议使用此模型)
python实现基于商品的相似度完成推荐算法(待完善)
Spark没有提供基于商品的API实现, 因此需要成需要手动实现
实现思路
- 通过基于ALS算法模型model获取物品之间的相似度矩阵
ALS算法原理过程中获取的K*I物品因子矩阵可以计算物品之间的相似度
val movieFactors = model.productFeatures
- 获取某个item的因子数
val i123_score = movieFactors.lookup(123).head //head后获取的数据类型是Array[Double]
- 使用夹角余弦计算与其他商品的相似度生成(id, cos值)
val movies123Cos = movieFactors.map{case (id, faxtor)=>{
val res = faxtor zip i123_score
val fenzi = res.map(x=>(x._1*x._2)).sum //分子
val fenmu = Math.sqrt(res.map(x=>x._1*x._1).sum) * Math.sqrt(res.map(x=>x._2*x._2).sum) //分母
(id,fenzi/fenmu)
}}.sortBy(x=> -x._2)
完整代码如下
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.mllib.recommendation.MatrixFactorizationModel
object itemDriver {
def main(args: Array[String]): Unit = {
//基于物品推荐的核心->计算物品与物品之间的相似度
//需要先计算所有电影和123号电影的相似度
val conf = new SparkConf().setMaster("local").setAppName("movies")
val sc = new SparkContext(conf)
//推荐系统模型的加载
val model = MatrixFactorizationModel.load(sc,"hdfs://hadoop01:9000/ALSmovie")
//为123用户推荐
val u123Res = model.recommendProducts(123,10)
//第一步获取物品因子矩阵RDD[(itemid, 物品的因子数组)]
val movieFactors = model.productFeatures
// movieFactors.foreach(x=>{println(x._1, x._2.mkString(","))})
//第二部:获取123号电影的因子数
val i123_score = movieFactors.lookup(123).head
i123_score.foreach(println(_))
//第三步:计算其他电影与123号电影的相似度,使用向量之间的夹角余弦
val movies123Cos = movieFactors.map{case (id, faxtor)=>{
val res = faxtor zip i123_score
val fenzi = res.map(x=>(x._1*x._2)).sum //分子
val fenmu = Math.sqrt(res.map(x=>x._1*x._1).sum) * Math.sqrt(res.map(x=>x._2*x._2).sum) //分母
(id,fenzi/fenmu)
}}.sortBy(x=> -x._2)
movies123Cos.foreach(println(_))
}
}
模型的保存与加载
保存
model.save(sc, "hdfs://hadoop01:9000/res")
加载
org.apache.spark.mllib.recommendation.MatrixFactorizationModel.load(sc, "hdfs://hadoop01:9000/res")