激活函数
目录
为什么需要激活函数?
为什么需要非线性激活函数
常见的激活函数
sigmoid激活函数
tanh激活函数
ReLU激活函数
Leaky ReLU激活函数
P-ReLU激活函数
R-ReLU激活函数
ELU激活函数
Maxout激活函数
SoftPlus激活函数
softmax激活函数
激活函数的性质
选择激活函数
为什么需要激活函数?
1、激活函数可以引入非线性因素,对模型学习、理解非常复杂和非线性的函数具有重要作用。
2、激活函数可以把当前特征空间通过一定的线性映射转换到另一个空间,让数据能够更好的被分类。
为什么需要非线性激活函数
1、线性的组合与单独一个线性分类器无异,做不到逼近任意函数。
2、加强网络的表示能力,解决线性模型无法解决的问题。
3、只要给予网络足够数量的隐藏单元,它就可以以任意的精度来近似任何从一个有限维空间到另一个有限维空间的函数。
常见的激活函数
sigmoid激活函数
函数的定义为: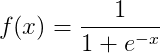 ,其值域为(0,1)
,其值域为(0,1)
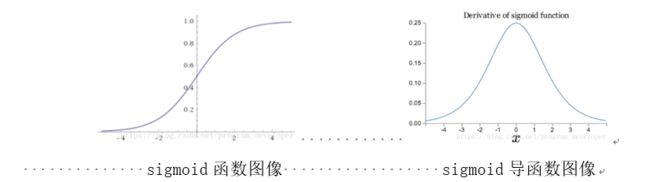
1.sigmoid函数饱和使梯度消失
为了防止饱和需注意权重矩阵的初始化。
初始化权重过大,很多神经元得到较小的梯度,提前饱和,神经网络几乎不学习。
1)初始化为0
如果权重初始化为同一个值,网络就是对称的
2)初始化为很小的随机数
并不是权重初始越小越好
3)用1/sqrt(n)校准方差
随机初始化神经元的输出的分布有一个随输入量增加而变化的方差
2.sigmoid函数输出不是“零为中心”(zero-centered)。
优化效率十分低下,模型拟合十分缓慢。因为使用sigmoid的网络,其权重w的梯度是全正或全负,要将w优化到最优状态,必须走“之字形”路线
解决方案:按batch去训练数据,那么每个batch可能得到不同的信号或正或负,这个批量的梯度叠加起来后可以缓解这个问题。
3.指数函数的计算是比较消耗计算资源的。
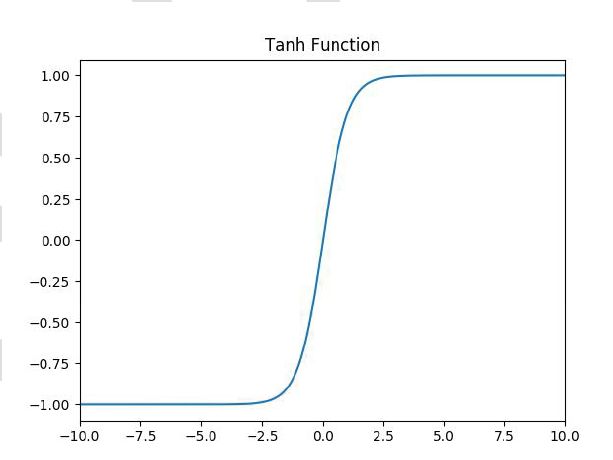
tanh激活函数
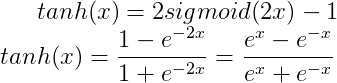
优点:
1.tanh解决了sigmoid的输出非“零为中心”的问题。
缺点:
1.依然有sigmoid函数过饱和的问题。没有解决梯度消失的问题。
2.依然指数运算。
ReLU激活函数
![]()
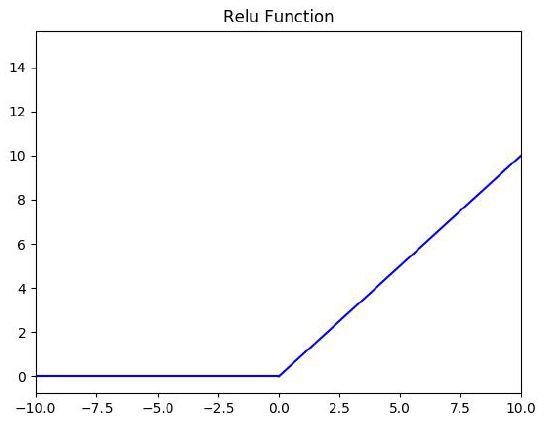
优点:
1.ReLU解决了梯度消失的问题,至少x在正区间内,神经元不会饱和。
2.由于ReLU线性、非饱和的形式,在SGD中能够快速收敛。
3.计算速度快很多。ReLU函数只有线性关系,不需要指数计算,不管在前向传播还是反向传播,计算速度都比sigmoid和tanh快。
缺点:
1.ReLU的输出不是“零为中心”(Notzero-centered output)。
2.随着训练的进行,可能会出现神经元死亡,权重无法更新的情况。这种神经元的死亡是不可逆转的死亡。
输入是负值,含有ReLU的神经节点就会死亡。可以设置较小的学习率,降低这种情况的发生
Leaky ReLU激活函数
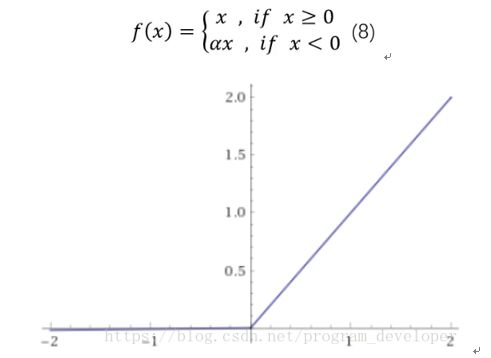
优点:
1.神经元不会出现死亡的情况。
2.对于所有的输入,不管是大于等于0还是小于0,神经元不会饱和。
2.由于Leaky ReLU线性、非饱和的形式,在SGD中能够快速收敛。
3.计算速度快很多。Leaky ReLU函数只有线性关系,不需要指数计算,不管在前向传播还是反向传播,计算速度都比sigmoid和tanh快。
缺点:
1.Leaky ReLU函数中的α,需要通过先验知识人工赋值。
P-ReLU激活函数
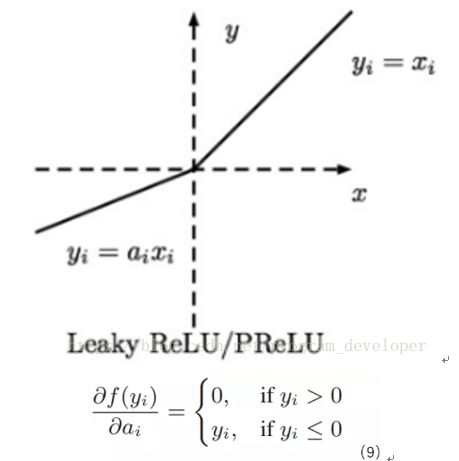
R-ReLU激活函数

特点:
1.RReLU是Leaky ReLU的random版本,在训练过程中,α是从一个高斯分布中随机出来的,然后再测试过程中进行修正。
2.数学形式与PReLU类似,但RReLU是一种非确定性激活函数,其参数是随机的。
ELU激活函数

优点:
1.ELU包含了ReLU的所有优点。
2.神经元不会出现死亡的情况。
3.ELU激活函数的输出均值是接近于零的。
缺点:
计算的时候是需要计算指数的,计算效率低的问题。
Maxout激活函数
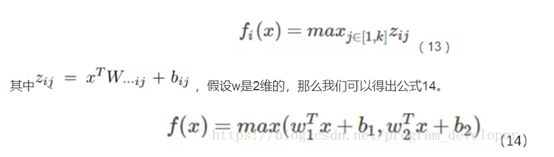
优点:
1.Maxout具有ReLU的所有优点,线性、不饱和性。
2.同时没有ReLU的一些缺点。如:神经元的死亡。
缺点:
每个神经元参数增加,导致整体参数数量激增
SoftPlus激活函数
![]() ,值域为
,值域为![]()

softmax激活函数
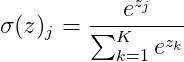
将多个神经元的输出,映射到(0,1)区间
Softmax多用于多分类神经网络输出
激活函数的性质
1.非线性
2.可微性。当优化方法是基于梯度的时候,就体现了该性质;
3.单调性。当激活函数是单调的时候,单层网络能够保证是凸函数;
4.f(x)≈x。满足:参数的初始化是随机的较小值,神经网络的训练很高效;
不满足:需要详细地去设置初始值;
5.输出值的范围。
有限:基于梯度的优化方法更稳定,特征的表示受有限权值的影响更显著;
无限:模型的训练会更加高效,需要更小的学习率。
选择激活函数
1、如果输出是0、1值(二分类问题),则输出层选择sigmoid函数,然后其它的所有单元都选择ReLU函数。
2、如果在隐藏层上不确定使用哪个激活函数,那么通常会使用Relu激活函数。有时,也会使用tanh激活函数,但Relu的一个缺点是:当是负值的时候,导数等于0。
3、sigmoid激活函数:除了输出层是一个二分类问题基本不会用它。
4、tanh激活函数:tanh是非常优秀的,几乎适合所有场合。
5、ReLu激活函数:最常用的默认函数,如果不确定用哪个激活函数,就使用ReLu或者LeakyReLu,再去尝试其他的激活函数。
6、如果遇到了一些死的神经元,我们可以使用LeakyReLU函数。
7、输出层大多使用线性激活函数
最后如果转载,麻烦留个本文的链接,因为如果读者或我自己发现文章有错误,我会在这里更正,留个本文的链接,防止我暂时的疏漏耽误了他人宝贵的时间。