天池:新闻文本分类-NLP实践Note-04
基于深度学习的文本分类01
- 学习目标
- 文本表示方法
- FastText
- 部分API参数:
- 文本分类
- 基于FastText的文本分类
- 转换为FastText需要的格式
- 实验
- 优化
- 如何使用验证集调参
- 其他优化方法技巧 Making the model better
- 本章小结
- 参考
与传统机器学习不同,深度学习既提供特征提取功能,也可以完成分类的功能。从本章开始我们将学习如何使用深度学习来完成文本表示。
学习目标
- 学习FastText的使用和基础原理
- 学会使用验证集进行调参
文本表示方法
之前介绍几种文本表示方法:
- One-hot
- Bag of Words
- N-gram
- TF-IDF
也通过sklean进行了相应的实践,相信你也有了初步的认知。但上述方法都或多或少存在一定的问题:转换得到的向量维度很高,需要较长的训练实践;没有考虑单词与单词之间的关系,只是进行了统计。
与这些表示方法不同,深度学习也可以用于文本表示,还可以将其映射到一个低纬空间。其中比较典型的例子有:FastText、Word2Vec和Bert。在本章我们将介绍FastText,将在后面的内容介绍Word2Vec和Bert。
FastText
- 参考论文:Bag of Tricks for Efficient Text Classification, https://arxiv.org/abs/1607.01759.
FastText是一种典型的深度学习词向量的表示方法,它非常简单通过Embedding层将单词映射到稠密空间,然后将句子中所有的单词在Embedding空间中进行平均,进而完成分类操作。
所以FastText是一个三层的神经网络,输入层、隐含层和输出层。
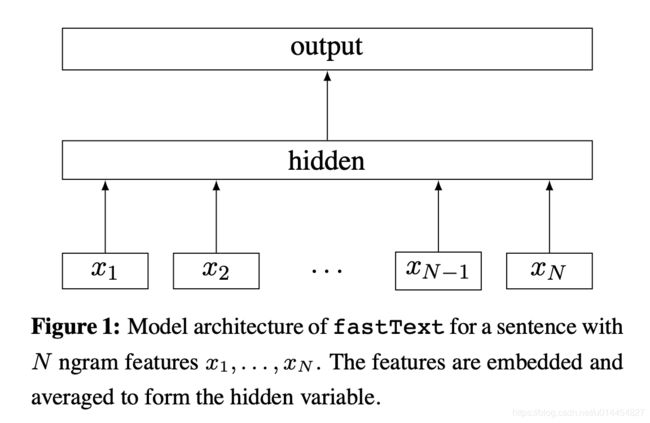
FastText在文本分类任务上,是优于TF-IDF的:
- FastText用单词的Embedding叠加获得的文档向量,将相似的句子分为一类
- FastText学习到的Embedding空间维度比较低,可以快速进行训练
部分API参数:
train_unsupervised parameters
input # training file path (required)
model # unsupervised fasttext model {cbow, skipgram} [skipgram]
lr # learning rate [0.05]
dim # size of word vectors [100]
ws # size of the context window [5]
epoch # number of epochs [5]
minCount # minimal number of word occurences [5]
minn # min length of char ngram [3]
maxn # max length of char ngram [6]
neg # number of negatives sampled [5]
wordNgrams # max length of word ngram [1]
loss # loss function {ns, hs, softmax, ova} [ns]
bucket # number of buckets [2000000]
thread # number of threads [number of cpus]
lrUpdateRate # change the rate of updates for the learning rate [100]
t # sampling threshold [0.0001]
verbose # verbose [2]
train_supervised parameters
input # training file path (required)
lr # learning rate [0.1]
dim # size of word vectors [100]
ws # size of the context window [5]
epoch # number of epochs [5]
minCount # minimal number of word occurences [1]
minCountLabel # minimal number of label occurences [1]
minn # min length of char ngram [0]
maxn # max length of char ngram [0]
neg # number of negatives sampled [5]
wordNgrams # max length of word ngram [1]
loss # loss function {ns, hs, softmax, ova} [softmax]
bucket # number of buckets [2000000]
thread # number of threads [number of cpus]
lrUpdateRate # change the rate of updates for the learning rate [100]
t # sampling threshold [0.0001]
label # label prefix ['__label__']
verbose # verbose [2]
pretrainedVectors # pretrained word vectors (.vec file) for supervised learning []
文本分类
基于FastText的文本分类
FastText可以快速的在CPU上进行训练,最好的实践方法就是官方开源的版本:https://github.com/facebookresearch/fastText/tree/master/python
pip安装
pip install fasttext
源码安装
git clone https://github.com/facebookresearch/fastText.git
cd fastText
sudo pip install .
两种安装方法都可以安装,优先考虑使用pip安装。
分类模型
import pandas as pd
from sklearn.metrics import f1_score
转换为FastText需要的格式
train_df = pd.read_csv('../input/train_set.csv', sep='\t', nrows=15000)
train_df['label_ft'] = '__label__' + train_df['label'].astype(str)
train_df[['text','label_ft']].iloc[:-5000].to_csv('train.csv', index=None, header=None, sep='\t')
实验

调试发现:数据10000条时,此时数据量比较小得分为0.80左右,当不断增加训练集数量时,FastText的精度也会不断增加5w条训练样本时,验证集得分可以到0.89-0.90左右。增加lr(0.1-1.0范围)和epoch(5-50范围)能够适当增加得分,ngrams=2时得分最好。
优化
如何使用验证集调参
在使用TF-IDF和FastText中,有一些模型的参数需要选择,这些参数会在一定程度上影响模型的精度,那么如何选择这些参数呢?
- 通过阅读文档,要弄清楚这些参数的大致含义,那些参数会增加模型的复杂度
- 通过在验证集上进行验证模型精度,找到模型在是否过拟合还是欠拟合
这里我们使用10折交叉验证,每折使用9/10的数据进行训练,剩余1/10作为验证集检验模型的效果。这里需要注意每折的划分必须保证标签的分布与整个数据集的分布一致。
label2id = {}
for i in range(total):
label = str(all_labels[i])
if label not in label2id:
label2id[label] = [i]
else:
label2id[label].append(i)
通过10折划分,我们一共得到了10份分布一致的数据,索引分别为0到9,每次通过将一份数据作为验证集,剩余数据作为训练集,获得了所有数据的10种分割。不失一般性,我们选择最后一份完成剩余的实验,即索引为9的一份做为验证集,索引为1-8的作为训练集,然后基于验证集的结果调整超参数,使得模型性能更优。方便查看效果,自己设置了10000条训练集句子进行训练,查看10折交叉验证效果:

其他优化方法技巧 Making the model better
The model obtained by running fastText with the default arguments is pretty bad at classifying new questions. Let’s try to improve the performance, by changing the default parameters.
1. 预处理数据(preprocessing the data)
Looking at the data, we observe that some words contain uppercase letter or punctuation(大写字母和标点符号). One of the first step to improve the performance of our model is to apply some simple pre-processing. A crude normalization(粗略的规范化) can be obtained using command line tools such as sed and tr(sed和tr命令行工具):
>> cat cooking.stackexchange.txt | sed -e "s/\([.\!?,'/()]\)/ \1 /g" | tr "[:upper:]" "[:lower:]" > cooking.preprocessed.txt
>> head -n 12404 cooking.preprocessed.txt > cooking.train
>> tail -n 3000 cooking.preprocessed.txt > cooking.valid
2. 增加epoch和学习率(more epochs and larger learning rate)
By default, fastText sees each training example only five times during training(默认epoch=5), which is pretty small, given that our training set only have 12k training examples. The number of times each examples is seen (also known as the number of epochs), can be increased using the -epoch option.
This is much better! Another way to change the learning speed of our model is to increase (or decrease) the learning rate of the algorithm. This corresponds to how much the model changes after processing each example. A learning rate of 0 would mean that the model does not change at all, and thus, does not learn anything. Good values of the learning rate are in the range 0.1 - 1.0.
两者结合的话,一般会提升更多一点(例如lr=1.0,epoch=25)。
3. 合适的ngrams(word n-grams)
Finally, we can improve the performance of a model by using word bigrams(实验中ngrams=2效果最好), instead of just unigrams. This is especially important for classification problems where word order is important, such as sentiment analysis.
总结:With a few steps, Important steps included
- preprocessing the data ;
- changing the number of epochs (using the option -epoch, standard range [5 - 50]) ;
- changing the learning rate (using the option -lr, standard range [0.1 - 1.0]) ;
- using word n-grams (using the option -wordNgrams, standard range [1 - 5]).
本章小结
本章介绍了FastText的原理和基础使用,并进行相应的实践。然后介绍了通过10折交叉验证划分数据集,以及一些优化方式,在实验中对与预处理数据这一块还没有展开尝试,之后会更多的尝试,希望得到进一步的优化。
参考
Paper:Bag of Tricks for Efficient Text Classification, https://arxiv.org/abs/1607.01759
FastText Tutorial:https://fasttext.cc/docs/en/supervised-tutorial.html
基于深度学习的文本分类1:https://github.com/datawhalechina/team-learning-nlp/blob/master/NewsTextClassification/Task4%20基于深度学习的文本分类1.md