感知机算法收敛性证明及Python代码实现
转载来自:https://blog.csdn.net/deramer1/article/details/87928860
大家一起学习讨论
一、感知机原理
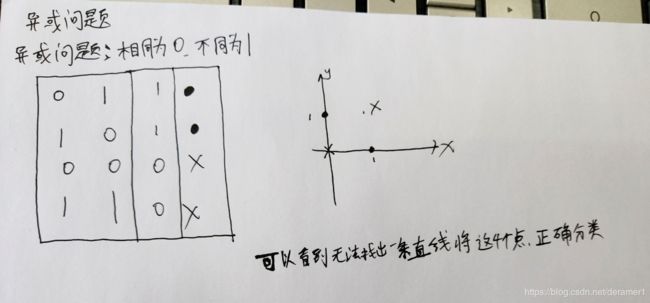
感知机是最简单的线性二分类模型,如果要处理的数据是线性可分的,则该模型能取得很好的效果,如果数据不是线性可分的,则该模型不能取得很好的效果。以二维平面为例,如果要分类的点,能被一条直线分开,直线的一侧是正类,直线的另一侧是负类,则说明数据是线性可分的。如果数据需要一个圆来分开则说明数据不是线性可分的,曾经感知机因为不能处理异或问题,而被人批判,导致神经网络的研究停滞了几十年。
1.1 感知机形式
感知机就是为了确定一条直线WX+b,让直线的一侧为正类,直线的另一侧是负类。当WX+b运算大于0时为+1,WX+b运算小于0时为-1,为此引入了sign函数。
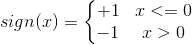
1.2感知机学习过程
感知器的训练过程就是确定W,b,从而确定一个平面分离正类和负类。训练过程中,我们需要注意的是那些被误分类的点,比如,本来是正类,却被感知机分成了负类。下面的式子是判断该点是否被误分类:
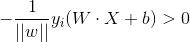
如果WX+b>0,y为-1,则整个式子大于0,该点被误分类。如果WX+b>0,y为+1,整个式子小于0,被正确分类。
如果不考虑1/||W||,上面的式子则是感知机的损失函数。如果有N个点,则损失函数为如下:

对于给定的训练集T,求解参数W,b的过程就是求解损失函数极小值的过程。
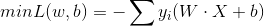
感知器的算法是由误分类确定的,首先选取一个超平面W0,b0,采用随机梯度下降法最小化上面的式子,梯度为:

整个感知器的运算流程如下:

每当有一个点被分类错误的时候,就会更新算法。我们知道w控制的是直线的斜率,b控制的是直线的平移。对w,b进行更新就是控制直线的旋转和平移,而η控制的是旋转和平移的角度。
1.3感知机收敛性证明
上面推导的时候,少加了一个注解,现补充如下:

1.4感知机无法解决异或问题
二、感知机编码实现
-
import numpy
as np
-
import pandas
as pd
-
import matplotlib.pyplot
as plt
-
from sklearn.datasets
import load_iris
我们用的数据集是iris数据集,这个数据集是用来给花做分类的数据集,每个样本包括了花萼长度、花萼宽度、花瓣长度、花瓣宽度四个特征,通过这四个特征来将花分为山鸢尾、变色鸢尾还是维吉尼亚鸢尾。本次我只抽取一部分数据做二分类。
-
#读取iris数据集,并将数据,标签存入DataFrame中,
-
iris = load_iris()
-
raw_data = iris.
data
-
data = pd.DataFrame(raw_data,columns=iris.feature_names)
-
data[
'label'] = iris.target
显示data数据集如下所示:

-
data_array = np.
array(data.iloc[:
100,[
0,
1,
-1]])
-
X,Y = data_array[:,:
-1],data_array[:,
-1]
-
Y = np.
array([
1
if i ==
1
else
-1
for i
in Y]) #将标签为
0,
1,变为
-1,+
1
将data中第一列、第二列作为特征存入X中,data最后一列作为标签存入Y中。
-
plt.scatter(X[:
50,
0],X[:
50,
1],
label=
'0')
-
plt.scatter(X[
50:
100,
0],X[
50:
100,
1],
label=
'1')
-
plt.xlabel(
'sepal length')
-
plt.ylabel(
'sepal width')
-
plt.legend()
-
plt.show()
X中数据显示如下

-
#定义sign函数
-
def sign(X,W,b):
-
return np.dot(W,X) + b
-
-
#遍历数据集
-
def train(X,Y,W,b,learning_rate=0.1):
-
for i
in range(len(X)):
-
if(Y[i]*sign(X[i],W,b)<=
0):
-
W = W + learning_rate*Y[i]*X[i]
-
b = b + learning_rate*Y[i]
-
-
return W,b
-
-
将数据集遍历
1000遍,每
100次打印一下W,b值
-
W = np.zeros([
1,
2])
-
b =
0
-
for i
in range(
1000):
-
W,b = train(X,Y,W,b)
-
if(i%
100==
0):
-
print(i,W,b)
-
x_ = np.linspace(
4,
7,
10)
-
y_ =-(W[
0][
0]*x_ + b)/W[
0][
1]
-
plt.plot(x_,y_)
-
plt.scatter(X[:
50,
0],X[:
50,
1],
label=
'0')
-
plt.scatter(X[
50:
100,
0],X[
50:
100,
1],
label=
'1')
-
plt.xlabel(
'sepal length')
-
plt.ylabel(
'sepal width')
-
plt.legend()
-
plt.show()
将超平面画出来,如下
