LEARNING GOAL-CONDITIONED VALUE FUNCTIONS WITH ONE-STEP PATH REWARDS RATHER THAN GOAL- REWARDS
学习目标条件的价值功能与一步走的路径奖励比目标奖励更多
ABSTRACT
Multi-goal reinforcement learning (MGRL) addresses tasks where the desired goal state can change for every trial. State-of-the-art algorithms model these problems such that the reward formulation depends on the goals, to associate them with high reward. This dependence introduces additional goal reward resampling steps in algorithms like Hindsight Experience Replay (HER) that reuse trials in which the agent fails to reach the goal by recomputing rewards as if reached states were psuedo-desired goals. We propose a reformulation of goal-conditioned value func-tions for MGRL that yields a similar algorithm, while removing the dependence of reward functions on the goal. Our formulation thus obviates the requirement of reward-recomputation that is needed by HER and its extensions. We also extend a closely related algorithm, Floyd-Warshall Reinforcement Learning, from tabular domains to deep neural networks for use as a baseline. Our results are competitive with HER while substantially improving sampling efficiency in terms of reward computation.
多目标强化学习(MGRL)解决了每个试验中期望目标状态可以改变的任务。最先进的算法对这些问题进行建模,使得奖励制定取决于目标,将它们与高回报联系起来。这种依赖性在诸如Hindsight Experience Replay(HER)之类的算法中引入了额外的目标奖励重新采样步骤,其重用了通过重新计算奖励而无法达到目标的试验,好像达到状态是假想的目标。我们建议重新制定MGRL的目标条件值函数,产生类似的算法,同时消除奖励函数对目标的依赖性。因此,我们的表述避免了HER及其扩展所需的奖励 - 重新计算的要求。我们还扩展了一个密切相关的算法,Floyd-Warshall强化学习,从表格域到深度神经网络,用作基线。我们的结果与HER竞争,同时在奖励计算方面大大提高了采样效率。
1 INTRODUCTION
Many tasks in robotics require the specification of a goal for every trial. For example, a robotic arm can be tasked to move an object to an arbitrary goal position on a table (Gu et al., 2017); a mobile robot can be tasked to navigate to an arbitrary goal landmark on a map (Zhu et al., 2017). The adaptation of reinforcement learning to such goal-conditioned tasks where goal locations can change is called Multi-Goal Reinforcement Learning (MGRL) (Plappert et al., 2018). State-of-the-art MGRL algorithms (Andrychowicz et al., 2017; Pong et al., 2018) work by estimating goal-conditioned value functions (GCVF) which are defined as expected cumulative rewards from start states with specified goals. GCVFs, in turn, are used to compute policies that determine the actions to take at every state.
To learn GCVFs, MGRL algorithms use goal-reward, defined as the relatively higher reward re-cieved on reaching the desired goal state. This makes the reward function dependent on the desired goal. For example, in the Fetch-Push task (Plappert et al., 2018) of moving a block to a given lo-cation on a table, every movement incurs a “-1” reward while reaching the desired goal returns a “0” goal-reward. This dependence introduces additional reward resampling steps in algorithms like Hindsight Experience Replay (HER) (Andrychowicz et al., 2017), where trials in which the agent failed to reach the goal are reused by recomputing rewards as if the reached states were pseudo-desired goals. Due to the dependence of the reward function on the goal, the relabelling of every pseudo-goal requires an independent reward-recomputation step, which can be expensive.
In this paper, we demonstrate that goal-rewards are not needed to learn GCVFs. For the Fetch-Push example, the “0” goal-reward does not need to be achieved to learn its GCVF. Specifically, the agent continues to receive “-1” reward even when the block is in the given goal location. This reward formulation is atypical in conventional RL because high reward is used to specify the desired goal location. However, this goal-reward is not necessary in goal-conditioned RL because the goal is already specified at the start of every episode. We use this idea, to propose a goal-conditioned RL algorithm which learns to reach goals without goal-rewards. This is a counter-intuitive result which is important for understanding goal-conditioned RL.
机器人技术中的许多任务都需要为每次试验指定目标。例如,机器人手臂的任务是将物体移动到桌子上的任意目标位置(Gu et al。,2017);移动机器人的任务是导航到地图上的任意目标地标(Zhu et al。,2017)。强化学习适应目标位置可以改变的目标条件任务被称为多目标强化学习(MGRL)(Plappert等,2018)。最先进的MGRL算法(Andrychowicz等,2017; Pong等,2018)通过估计目标条件值函数(GCVF)来工作,GCVF被定义为具有指定目标的起始状态的预期累积奖励。反过来,GCVF用于计算确定每个州要采取的行动的政策。
为了学习GCVF,MGRL算法使用目标奖励,定义为在达到期望的目标状态时重新获得的相对较高的奖励。这使得奖励功能取决于期望的目标。例如,在将块移动到桌子上的给定位置的Fetch-Push任务(Plappert等,2018)中,每次移动都会产生“-1”奖励,而到达期望目标则返回“0”目标奖励。这种依赖性在诸如Hindsight Experience Replay(HER)(Andrychowicz等人,2017)之类的算法中引入了额外的奖励重新采样步骤,其中通过重新计算奖励来重复使用代理未能达到目标的试验,就好像达到的状态是伪期望的一样目标。由于奖励函数对目标的依赖性,每个伪目标的重新标记需要独立的奖励 - 重新计算步骤,这可能是昂贵的。
在本文中,我们证明了学习GCVF不需要目标奖励。对于Fetch-Push示例,不需要实现“0”目标奖励来学习其GCVF。具体而言,即使块在给定的目标位置,代理也继续接收“-1”奖励。该奖励制定在传统RL中是非典型的,因为高奖励用于指定期望的目标位置。然而,这个目标奖励在目标条件RL中是不必要的,因为目标已经在每集开始时指定。我们使用这个想法,提出一个目标条件的RL算法,该算法学会达到目标而没有目标奖励。这是一个反直觉的结果,对于理解目标条件RL很重要。

Let us consider another example to motivate the redundancy of goal-rewards. Consider a student who has moved to a new campus. To learn about the campus, the student explores it randomly with no specific goal in mind. The key intuition here is that the student is not incentivized to find specific goal locations (i.e. no goal-rewards) but is aware of the effort required to travel between points around the university. When tasked with finding a goal classroom, the student can chain together these path efforts to find the least-effort path to the classroom. Based on this intuition of least-effort paths, we redefine GCVFs to be the expected path-reward that is learned for all possible start-goal pairs. We introduce a one-step loss that assumes one-step paths to be the paths of maximum reward between pairs wherein the state and goal are adjacent. Under this interpretation, the Bellman equation chooses and chains together one-step paths to find longer maximum reward paths. Experimentally, we show how this simple reinterpretation, which does not use goal rewards, performs as well as HER while outperforming it in terms of reward computation.
We also extend a closely related algorithm, Floyd-Warshall Reinforcement Learning (FWRL) (Kael-bling, 1993) (also called Dynamic Goal Reinforcement learning) to use parametric function ap-proximators instead of tabular functions. Similar to our re-definition of GCVFs, FWRL learns a goal-conditioned Floyd-Warshall function that represents path-rewards instead of future-rewards. We translate FWRL’s compositionality constraints in the space of GCVFs to introduce additional loss terms to the objective. However, these additional loss terms do not show improvement over the baseline. We conjecture that the compositionality constraints are already captured by other loss terms.
In summary, the contributions of this work are twofold. Firstly, we reinterpret goal-conditioned value functions as expected path-rewards and introduce one-step loss, thereby removing the dependency of GCVFs on goal-rewards and reward resampling. We showcase our algorithm’s improved sample efficiency (in terms of reward computation). We thus extend algorithms like HER to domains where reward recomputation is expensive or infeasible. Secondly, we extend the tabular Floyd-Warshal Reinforcement Learning to use deep neural networks.
让我们考虑另一个例子来激励目标奖励的冗余。考虑一个搬到新校区的学生。要了解校园,学生会随意探索校园,没有特定的目标。这里的关键直觉是学生没有被激励去寻找特定的目标位置(即没有目标奖励),而是知道在大学周围的点之间旅行所需的努力。当负责找到目标教室时,学生可以将这些路径工作联系在一起,找到最不费力的课堂路径。基于这种最小努力路径的直觉,我们将GCVF重新定义为所有可能的起始目标对所学习的预期路径奖励。我们引入一步损失,假设一步路径是状态和目标相邻的对之间的最大奖励路径。根据这种解释,贝尔曼方程选择并将一步路径链接在一起以找到更长的最大奖励路径。在实验上,我们展示了这种不使用目标奖励的简单重新解释如何在奖励计算方面表现优于HER。
我们还扩展了一个密切相关的算法,Floyd-Warshall强化学习(FWRL)(Kael-bling,1993)(也称为动态目标强化学习),以使用参数函数ap-proximators而不是表格函数。与我们对GCVF的重新定义类似,FWRL学习了一个目标条件的Floyd-Warshall函数,它代表了路径奖励而不是未来奖励。我们在GCVF空间中翻译FWRL的组合性约束,为目标引入额外的损失项。但是,这些额外的损失条款并未显示出超过基线的改善。我们推测组合性约束已经被其他损失术语所捕获。
总之,这项工作的贡献是双重的。首先,我们将目标条件值函数重新解释为预期的路径奖励并引入一步损失,从而消除GCVF对目标奖励和奖励重新采样的依赖性。我们展示了我们的算法提高的样本效率(在奖励计算方面)。因此,我们将像HER这样的算法扩展到奖励重新计算昂贵或不可行的领域。其次,我们扩展表格Floyd-Warshal强化学习以使用深度神经网络。
2 RELATED WORK
Goal-conditioned tasks in reinforcement learning have been approached in two ways, depending upon whether the algorithm explicitly separates state and goal representations. The first approach is to use vanilla reinforcement learning algorithms that do not explicitly make this separation (Mirowski et al., 2016; Dosovitskiy & Koltun, 2016; Gupta et al., 2017; Parisotto & Salakhutdi-nov, 2017; Mirowski et al., 2018). These algorithms depend upon neural network architectures to carry the burden of learning the separated representations.
The second approach makes this separation explicit via the use of goal-conditioned value functions (Foster & Dayan, 2002; Sutton et al., 2011). Universal Value Function Appoximators (Schaul et al., 2015) propose a network architecture and a factorization technique that separately encodes states and goals, taking advantage of correlations in their representations. Temporal Difference Models combine model-free and model-based RL to gain advantages from both realms by defining and learning a horizon-dependent GCVF. All these works require the use of goal-dependent reward functions and define GCVFs as future-rewards instead of path-rewards, contrasting them from our contribution.
Unlike our approach, Andrychowicz et al. (2017) propose Hindsight Experience Replay, a technique for resampling state-goal pairs from failed experiences; which leads to faster learning in the pres-ence of sparse rewards. In addition to depending on goal rewards, HER also requires the repeated recomputation of the reward function. In contrast, we show how removing goal-rewards removes the need for such recomputations. We utilize HER as a baseline in our work.
Kaelbling (1993) also use the structure of the space of GCVFs to learn. This work employs com-positionality constraints in the space of these functions to accelerate learning in a tabular domain. While their definition of GCVFs is similar to ours, the terminal condition is different. We describe this difference in Section 4. We also extend their tabular formulation to deep neural networks and evaluate it against the baselines.
强化学习中的目标条件任务有两种方式,取决于算法是否明确区分状态和目标表示。第一种方法是使用未明确进行这种分离的香草强化学习算法(Mirowski等,2016; Dosovitskiy&Koltun,2016; Gupta等,2017; Parisotto&Salakhutdi-nov,2017; Mirowski等。 ,2018年)。这些算法依赖于神经网络架构来承担学习分离表示的负担。
第二种方法通过使用目标条件值函数使这种分离明确(Foster&Dayan,2002; Sutton等,2011)。通用价值函数Appoximators(Schaul等人,2015)提出了一种网络架构和分解技术,它们分别对状态和目标进行编码,利用其表示中的相关性。时间差异模型通过定义和学习与地平线相关的GCVF,将无模型和基于模型的RL结合起来,从两个领域中获得优势。所有这些工作都需要使用与目标相关的奖励函数,并将GCVF定义为未来奖励而不是路径奖励,将它们与我们的贡献进行对比。
与我们的方法不同,Andrychowicz等人。 (2017)提出Hindsight Experience Replay,这是一种从失败的经历中重新取样状态目标对的技术;这导致在稀疏奖励的情况下更快地学习。除了依赖目标奖励之外,HER还需要重复重新计算奖励功能。相比之下,我们展示了如何删除目标奖励消除了对此类重新计算的需求。我们利用HER作为我们工作的基线。
Kaelbling(1993)也使用GCVF空间的结构来学习。这项工作在这些函数的空间中使用了对位性约束,以加速表格域中的学习。虽然他们对GCVF的定义与我们的相似,但终端条件不同。我们在第4节中描述了这种差异。我们还将它们的表格表达式扩展到深度神经网络,并根据基线进行评估。
3 BACKGROUND

DEEP REINFORCEMENT LEARNING
A number of reinforcement learning algorithms use parametric function approximators to estimate the return in the form of an action-value function, Q(s; a):
许多强化学习算法使用参数函数逼近器以动作值函数Q(s; a)的形式估计回报:



Hindsight Experience Replay HER (Andrychowicz et al., 2017) builds upon this definition of GCVFs (5). The main insight of HER is that there is no valuable feedback from the environment when the agent does not reach the goal. This is further exacerbated when goals are sparse in the state-space. HER solves this problem by reusing these failed experiences for learning. It recomputes a reward for each reached state by relabeling them as pseudo-goals.
In our experiments, we employ HER’s future strategy for pseudo-goal sampling. More specifi-cally, two transitions from the same episode in the replay buffer for times t and t + f are sam-pled. The achieved goal gt+f is then assumed to be the pseudo-goal. The algorithm generates a new transition for the time step t with the reward re-computed as if gt+f was the desired goal, (st; at; st+1; R(st; at; gt+f )). HER uses this new transition as a sample.
Hindsight Experience Replay HER(Andrychowicz et al。,2017)建立在GCVFs的这个定义之上(5)。 HER的主要见解是当代理未达到目标时,没有来自环境的有价值的反馈。 当目标在状态空间稀疏时,情况会进一步恶化。 她通过重复使用这些失败的经验来解决这个问题。 它通过将它们重新标记为伪目标来重新计算每个达到状态的奖励。
在我们的实验中,我们采用了HER未来的伪目标抽样策略。 更具体地说,对于时间t和t + f,来自重放缓冲器中的相同剧集的两个转换被采样。 然后将所实现的目标gt + f假设为伪目标。 该算法为时间步长t生成新的转变,重新计算奖励,就好像gt + f是期望的目标一样,(st; at; st + 1; R(st; at; gt + f))。 HER使用这种新的过渡作为样本。
4 PATH REWARD-BASED GCVFS
In our definition of the GCVF, instead of making the reward function depend upon the goal, we count accumulated rewards over a path, path-rewards, only if the goal is reached. This makes the dependence on the goal explicit instead of implicit to the reward formulation. Mathematically,
在我们对GCVF的定义中,不是让奖励函数取决于目标,而是仅仅在达到目标时计算路径上的累积奖励,路径奖励。 这使得对目标的依赖明确而不是隐含于奖励制定。在数学上,

where l is the time step when the agent reaches the goal. If the agent does not reach the goal, the GCVF is defined to be negative infinity. This first term (6a) is the expected cumulative reward over paths from a given start state to the goal. This imposes the constraint that cyclical paths in the state space must have negative cumulative reward for (6a) to yield finite values. For most practical physical problems, this constraints naturally holds if reward is taken to be some measure of negative energy expenditure. For example, in the robot arm experiment, moving the arm must expend energy (negative reward). Achieving a positive reward cycle would translate to generating infinite energy . In all our experiments with this
其中l是代理达到目标时的时间步长。 如果代理未达到目标,则GCVF被定义为负无穷大。 该第一项(6a)是从给定开始状态到目标的路径上的预期累积奖励。 这强加了约束条件,即状态空间中的循环路径必须具有负累积奖励(6a)以产生有限值。 对于大多数实际的物理问题,如果将奖励作为负能量消耗的某种度量,则这种约束自然成立。 例如,在机器人手臂实验中,移动手臂必须消耗能量(负面奖励)。 实现积极的奖励周期将转化为产生无限的能量。 在我们所有的实验中

Notice that terminal step in this equation is the step to reach the goal. This differs from Equation (3), where the terminal step is the step at which the episode ends. This formulation is equivalent to the end of episode occuring immediately when the goal is reached. This reformulation does not require goal-rewards, which in turn obviates the requirement for pseudo-goals and reward recomputation.
One-Step Loss To enable algorithms like HER to work under this reformulation we need to rec-ognize when the goal is reached (7b). This recognition is usually done by the reception of high goal reward. Instead, we use (7b) as a one-step loss that serves this purpose which is one of our main contributions:
请注意,此等式中的终端步骤是达到目标的步骤。 这与等式(3)不同,其中终止步骤是情节结束的步骤。 该公式相当于达到目标时立即发生的剧集结束。 这种重新制定不需要目标奖励,这反过来又不需要伪目标和奖励重新计算。
一步损失为了使像HER这样的算法能够在这个重新制定下工作,我们需要重新认识何时达到目标(7b)。 这种认可通常是通过接收高目标奖励来完成的。 相反,我们使用(7b)作为一步失败来实现这一目的,这是我们的主要贡献之一:
![]()
This loss is based on the assumption that one-step reward is the highest reward between adjacent start-goal states and allows us to estimate the one-step reward between them. Once learned, it serves as a proxy for the reward to the last step to the goal (7b). The Bellman equation (7), serves as a one-step rollout to combine rewards to find maximum reward paths to the goal.
One-step loss is different from the terminal step of Q-Learning because one-step loss is applicable to every transition unlike the terminal step. However, one-step loss can be thought of as Q-Learning where every transition is a one-step episode where the achieved goal is the pseudo goal.
这种损失是基于这样的假设:一步奖励是相邻起始目标状态之间的最高奖励,并允许我们估计它们之间的一步奖励。 一旦学会了,它就可以作为目标最后一步奖励的代理(7b)。 贝尔曼方程(7)作为一步推出,结合奖励以找到目标的最大奖励路径。
一步损失与Q-Learning的终端步骤不同,因为一步损失适用于与终端步骤不同的每次转换。 然而,一步损失可以被认为是Q-Learning,其中每个过渡都是一步一集,其中实现的目标是伪目标。

DEEP FLOYD-WARSHALL REINFORCEMENT LEARNING
The GCVF redefinition and one step-loss introduced in this paper are inspired by the tabular for-mulation of Floyd-Warshall Reinforcement Learning (FWRL) (Kaelbling, 1993). We extend this algorithm for use with deep neural networks. Unfortunately, the algorithm itself does not show sig-nificant improvement over the baselines. However, the intuitions gained in its implementation led to the contributions of this paper.
本文介绍的GCVF重新定义和一步损失的灵感来自Floyd-Warshall强化学习(FWRL)的表格形式(Kaelbling,1993)。 我们扩展此算法以用于深度神经网络。 不幸的是,算法本身并没有显示出超过基线的显着改进。 然而,在实施过程中获得的直觉导致了本文的贡献。

Note that the above terms differ only by choice of the target and main network.
请注意,上述术语的区别仅在于选择目标网络和主网络。

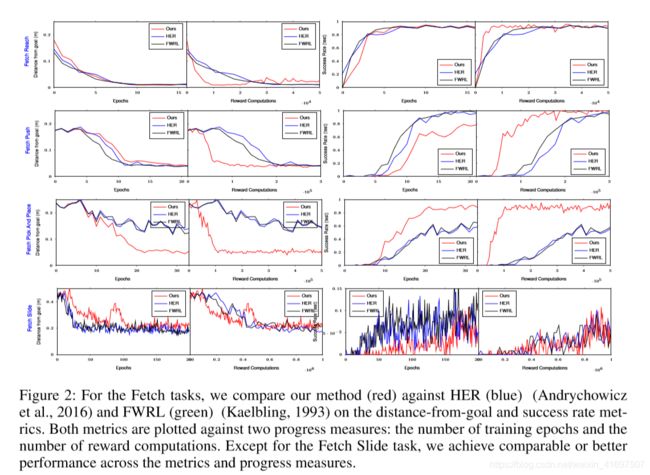
Figure 2: For the Fetch tasks, we compare our method (red) against HER (blue) (Andrychowicz et al., 2016) and FWRL (green) (Kaelbling, 1993) on the distance-from-goal and success rate met-rics. Both metrics are plotted against two progress measures: the number of training epochs and the number of reward computations. Except for the Fetch Slide task, we achieve comparable or better performance across the metrics and progress measures.
图2:对于Fetch任务,我们将我们的方法(红色)与HER(蓝色)(Andrychowicz等人,2016)和FWRL(绿色)(Kaelbling,1993)的距离与目标距离和成功率进行比较 - RICS。 两个指标都针对两个进度度量绘制:训练时期的数量和奖励计算的数量。 除了Fetch Slide任务,我们在指标和进度指标上实现了相当或更好的性能。
5 EXPERIMENTS
We use the environments introduced in Plappert et al. (2018) for our experiments. Broadly the en-vironments fall in two categories, Fetch and Hand tasks. Our results show that learning is possi-ble across all environments without the requirement of goal-reward. More specifically, the learning happens even when reward given to our algorithm is agent is always “-1” as opposed to the HER formulation where a special goal-reward of “0” is needed for learning to happen.
The Fetch tasks involve a simulation of the Fetch robot’s 7-DOF robotic arm. The four tasks are Reach, Push, Slide and PickAndPlace. In the Reach task the arm’s end-effector is tasked to reach the a particular 3D coordinate. In the Push task a block on a table needs to be pushed to a given point on it. In the Slide task a puck must be slid to a desired location. In the PickAndPlace task a block on a table must be picked up and moved to a 3D coordinate.
The Hand tasks use a simulation of the Shadow’s Dexterous Hand to manipulate objects of different shapes and sizes. These tasks are HandReach, HandManipulateBlockRotateXYZ, HandManipula-teEggFull and HandManipulatePenRotate. In HandReach the hand’s fingertips need to reach a given configuration. In the HandManipulateBlockRotateXYZ, the hand needs to rotate a cubic block to a desired orientation. In HandManipulateEggFull, the hand repeats this orientation task with an egg, and in HandManipulatePenRotate, it does so with a pen.
Snapshots of all these tasks can be found in Figure 1. Note that these tasks use joint angles, not visual input.
我们使用Plappert等人介绍的环境。 (2018)我们的实验。从广义上讲,这些环境分为Fetch和Hand两个类别。我们的研究结果表明,在不需要目标奖励的情况下,可以在所有环境中进行学习。更具体地说,即使当给予我们的算法的奖励是代理总是“-1”而不是HER制剂时,学习也会发生,其中学习发生需要特殊的目标 - 奖励“0”。
Fetch任务涉及Fetch机器人的7-DOF机器人手臂的模拟。四个任务是Reach,Push,Slide和PickAndPlace。在Reach任务中,手臂的末端执行器的任务是到达特定的3D坐标。在Push任务中,需要将表上的块推送到其上的给定点。在幻灯片任务中,必须将冰球滑动到所需位置。在PickAndPlace任务中,必须拾取表格上的块并将其移动到3D坐标。
Hand任务使用Shadow的Dexterous Hand模拟来操纵不同形状和大小的物体。这些任务是HandReach,HandManipulateBlockRotateXYZ,HandManipula-teEggFull和HandManipulatePenRotate。在HandReach中,手的指尖需要达到给定的配置。在HandManipulateBlockRotateXYZ中,手需要将立方块旋转到所需的方向。在HandManipulateEggFull中,手用一个蛋重复这个方向任务,而在HandManipulatePenRotate中,它用一支笔完成。
所有这些任务的快照可以在图1中找到。请注意,这些任务使用关节角度,而不是视觉输入。
METRICS
Similar to prior work, we evaluate all experiments on two metrics: the success rate and the average distance to the goal. The success rate is defined as the fraction of episodes in which the agent is able to reach the goal within a pre-defined threshold region. The metric distance of the goal is the euclidean distance between the achieved goal and the desired goal in meters. These metrics are
plotted against a standard progress measure, the number of training epochs, showing comparable results of our method to the baselines.
To emphasize that our method does not require goal-reward and reward re-computation, we plot these metrics against another progress measure, the number of reward computations used during training. This includes both the episode rollouts and the reward recomputations during HER sam-pling.
与之前的工作类似,我们会根据两个指标评估所有实验:成功率和到目标的平均距离。 成功率被定义为代理能够在预定阈值区域内达到目标的事件的分数。 目标的度量距离是达到目标与所需目标之间的欧氏距离(以米为单位)。 这些指标是
根据标准进度测量,训练时期的数量绘制,显示我们的方法与基线的可比结果。
为了强调我们的方法不需要目标奖励和奖励重新计算,我们将这些指标与另一个进度测量,即训练期间使用的奖励计算的数量进行对比。 这包括剧集推出和HER采样期间的奖励重新计算。
5.2 HYPER-PARAMETERS CHOICES
Unless specified, all our hyper-parameters are identical to the ones used in the HER implementa-tion (Dhariwal et al., 2017). We note two main changes to HER to make the comparison more fair. Firstly, we use a smaller distance-threshold. The environment used for HER and FWRL returns the goal-reward when the achieved goal is within this threshold of the desired goal. Because of the ab-sence of goal-rewards, the distance-threshold information is not used by our method. We reduce the threshold to 1cm which is reduction by a factor of 5 compared to HER.
Secondly, we run all experiments on 6 cores each, while HER uses 19. The batch size used is a function of the number of cores and hence this parameter has a significant effect on learning.
To ensure fair comparison, all experiments are run with the same hyper-parameters and random seeds to ensure that variations in performance are purely due to differences between the algorithms.
除非另有说明,否则我们所有的超参数都与HER实现中使用的相同(Dhariwal等,2017)。 我们注意到HER的两个主要变化,使比较更加公平。 首先,我们使用较小的距离阈值。 当达到目标在期望目标的阈值内时,用于HER和FWRL的环境返回目标奖励。 由于目标奖励的缺失,我们的方法不使用距离阈值信息。 我们将阈值降低到1cm,与HER相比减少了5倍。
其次,我们在每个6个核心上运行所有实验,而HER使用19.所使用的批量大小是核心数量的函数,因此该参数对学习具有显着影响。
为了确保公平比较,所有实验都使用相同的超参数和随机种子运行,以确保性能的变化完全是由于算法之间的差异。
5.3 RESULTS
All our experimental results are described below, highlighting the strengths and weaknesses of our algorithm. Across all our experiments, the distance-to-the-goal metric achieves comparable perfor-mance to HER without requiring goal-rewards.
Fetch Tasks The experimental results for Fetch tasks are shown in Figure 2. For the Fetch Reach and Push tasks, our method achieves comparable performance to the baselines across both metrics in terms of training epochs and outperforms them in terms of reward recomputations. Notably, the Fetch Pick and Place task trains in significantly fewer epochs. For the Fetch Slide task the opposite is true. We conjecture that Fetch Slide is more sensitive to the distance threshold information, which our method is unable to use.
Hand Tasks For the Hand tasks, the distance to the goal and the success rate show different trends. We show the results in Figure 3. When the distance metric is plotted against epochs, we get com-parable performance for all tasks; when plotted against reward computations, we outperform all baselines on all tasks except Hand Reach. The baselines perform well enough on this task, leav-ing less scope for significant improvement. These trends do not hold for the success rate metric, on which our method consistently under-performs compared to the baselines across tasks. This is surprising, as all algorithms average equally on the distance-from-goal metric. We conjecture that this might be the result of high-distance failure cases of the baselines, i.e. when the baselines fail, they do so at larger distances from the goal. In contrast, we assume our method’s success and failure cases are closer together.
我们所有的实验结果如下所述,突出了我们的算法的优点和缺点。在我们所有的实验中,距离目标指标达到了与HER相当的性能,而不需要目标奖励。
获取任务Fetch任务的实验结果如图2所示。对于Fetch Reach和Push任务,我们的方法在训练时期方面实现了两个指标的基线性能,并且在奖励重新计算方面优于它们。值得注意的是,Fetch Pick and Place任务训练的时期显着减少。对于Fetch Slide任务,情况恰恰相反。我们猜想Fetch Slide对距离阈值信息更敏感,我们的方法无法使用。
手部任务对于手部任务,到目标的距离和成功率显示不同的趋势。我们在图3中显示结果。当距离度量与时期相关时,我们可以获得所有任务的可比性能;当针对奖励计算进行绘制时,除了Hand Reach之外,我们在所有任务上的表现都优于所有基线。基线在此任务上表现良好,从而减少了显着改进的范围。这些趋势并不适用于成功率指标,与我们的方法相比,我们的方法始终表现不佳。这是令人惊讶的,因为所有算法在距目标距离度量上的平均值相同。我们推测这可能是基线的高距离失败情况的结果,即当基线失效时,它们在离目标较远的距离处这样做。相反,我们假设我们的方法的成功和失败案例更加紧密。
6 ANALYSIS
To gain a deeper understanding of the method we perform three additional experiments on different tasks. We ask the following questions: (a) How important is the step loss? (b) What happens when the goal-reward is also available to our method? © How sensitive is HER and our method to the distance-threshold?
How important is the step loss? We choose the Fetch-Push task for this experiment. We run our algorithm with no goal reward and without the step loss on this task. Results show that our algorithm fails to reach the goal when the step-loss is removed (Fig. 4a) showing its necessity.
为了更深入地了解该方法,我们对不同的任务进行了三次额外的实验。 我们提出以下问题:(a)步损有多重要? (b)当我们的方法也可以获得目标奖励时会发生什么? (c)HER和我们的方法对距离阈值有多敏感?
步损失有多重要? 我们为此实验选择了Fetch-Push任务。 我们运行我们的算法没有目标奖励,没有这项任务的步骤损失。 结果表明,当步骤损失被移除(图4a)显示其必要性时,我们的算法未能达到目标。

Figure 3: For the hand tasks, we compare our method (red) against HER (blue) (Andrychowicz et al., 2016) and FWRL (green) (Kaelbling, 1993) for the distance-from-goal and success rate metrics. Furthermore, both metrics are plotted against two progress measures, the number of training epochs and the number of reward computations. Measured by distance from the goal, our method performs comparable to or better than the baselines for both progress measurements. For the success rate, our method underperforms against the baselines.
图3:对于手部任务,我们比较了我们的方法(红色)与HER(蓝色)(Andrychowicz等人,2016)和FWRL(绿色)(Kaelbling,1993)的目标距离和成功率指标。 此外,两个指标都针对两个进度度量,训练时期的数量和奖励计算的数量绘制。 通过距离目标的距离来测量,我们的方法与两个进度测量的基线相当或更好。 对于成功率,我们的方法在基线方面表现不佳。

Figure 5: We measure the sensitive of HER and our method to the dsitance-threshold ( ) with respect to the success-rate and distance-from-goal metrics. Both algorithms success-rate is sensitive the threshold while only HER’s distance-from-goal is affected by it.
What happens when the goal-reward is also available to our method? We run this experiment on the Fetch PickAndPlace task. We find that goal-rewards do not affect the performance of our algorithm further solidifying the avoidability of goal-reward (Fig 4b).
How sensitive is HER and our method to the distance-threshold? In the absence of goal-rewards, our algorithm is not to able capture distance threshold information that decides whether the agent has reached the goal or not. This information is available to HER. To understand the sen-sitivity of our algorithm and HER on this parameter, we vary it over 0.05 (the original HER value), 0.01 and 0.001 meters (Fig. 5). Results show that for the success-rate metric, which is itself a func-tion of this parameter, both algorithms are affected equally (Fig. 5a). For the distance-from-goal, only HER is affected (Fig. 5b). This fits our expectations as set up in section 5.2.
图5:我们测量HER和我们的方法对dsitance-threshold()的敏感度,关于成功率和目标距离指标。两种算法的成功率都是敏感的阈值,而只有HER的距离目标受其影响。
当目标奖励也可用于我们的方法时会发生什么?我们在Fetch PickAndPlace任务上运行此实验。我们发现目标奖励不会影响我们算法的性能,进一步巩固了目标奖励的可避免性(图4b)。
她和我们的方法对距离阈值有多敏感?在没有目标奖励的情况下,我们的算法无法捕获决定代理是否已达到目标的距离阈值信息。这些信息可供HER使用。为了理解我们的算法和HER对该参数的敏感性,我们将其变化超过0.05(原始HER值),0.01和0.001米(图5)。结果表明,对于成功率度量,它本身就是这个参数的函数,两种算法都受到相同的影响(图5a)。对于距离目标的距离,只有HER受到影响(图5b)。这符合我们在第5.2节中设定的期望。
7 CONCLUSION
In this work we pose a reinterpretation of goal-conditioned value functions and show that under this paradigm learning is possible in the absence of goal reward. This is a surprising result that runs counter to intuitions that underlie most reinforcement learning algorithms. In future work, we will augment our method to incorporate the distance-threshold information to make the task easier to learn when the threshold is high. We hope that the experiments and results presented in this paper lead to a broader discussion about the assumptions actually required for learning multi-goal tasks.
在这项工作中,我们对目标条件价值函数进行了重新解释,并表明在这种范式下,在没有目标奖励的情况下学习是可能的。 这是一个令人惊讶的结果,与大多数强化学习算法背后的直觉背道而驰。 在未来的工作中,我们将增加我们的方法来合并距离阈值信息,以便在阈值高时更容易学习任务。 我们希望本文中提供的实验和结果能够更广泛地讨论学习多目标任务所需的假设。
REFERENCES
Marcin Andrychowicz, Misha Denil, Sergio Gomez, Matthew W Hoffman, David Pfau, Tom Schaul, Brendan Shillingford, and Nando De Freitas. Learning to learn by gradient descent by gradient descent. In Advances in Neural Information Processing Systems, pp. 3981–3989, 2016.
Marcin Andrychowicz, Filip Wolski, Alex Ray, Jonas Schneider, Rachel Fong, Peter Welinder, Bob McGrew, Josh Tobin, OpenAI Pieter Abbeel, and Wojciech Zaremba. Hindsight experience re-play. In Advances in Neural Information Processing Systems, pp. 5048–5058, 2017.
Richard Bellman. The theory of dynamic programming. Technical report, RAND Corp Santa Mon-ica CA, 1954.
Prafulla Dhariwal, Christopher Hesse, Oleg Klimov, Alex Nichol, Matthias Plappert, Alec Radford, John Schulman, Szymon Sidor, Yuhuai Wu, and Peter Zhokhov. Openai baselines. https: //github.com/openai/baselines, 2017.
Alexey Dosovitskiy and Vladlen Koltun. Learning to act by predicting the future. arXiv preprint arXiv:1611.01779, 2016.
David Foster and Peter Dayan. Structure in the space of value functions. Machine Learning, 49 (2-3):325–346, 2002.
Shixiang Gu, Ethan Holly, Timothy Lillicrap, and Sergey Levine. Deep reinforcement learning for robotic manipulation with asynchronous off-policy updates. In Robotics and Automation (ICRA), 2017 IEEE International Conference on, pp. 3389–3396. IEEE, 2017.
Saurabh Gupta, James Davidson, Sergey Levine, Rahul Sukthankar, and Jitendra Malik. Cognitive mapping and planning for visual navigation. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017.
Leslie Pack Kaelbling. Learning to achieve goals. In IJCAI, pp. 1094–1099. Citeseer, 1993.
Timothy P Lillicrap, Jonathan J Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. Continuous control with deep reinforcement learning. arXiv preprint arXiv:1509.02971, 2015.
Long-Ji Lin. Reinforcement learning for robots using neural networks. Technical report, Carnegie-Mellon Univ Pittsburgh PA School of Computer Science, 1993.
Piotr Mirowski, Razvan Pascanu, Fabio Viola, Hubert Soyer, Andrew J Ballard, Andrea Banino, Misha Denil, Ross Goroshin, Laurent Sifre, Koray Kavukcuoglu, et al. Learning to navigate in complex environments. arXiv preprint arXiv:1611.03673, 2016.
Piotr Mirowski, Matthew Koichi Grimes, Mateusz Malinowski, Karl Moritz Hermann, Keith An-derson, Denis Teplyashin, Karen Simonyan, Koray Kavukcuoglu, Andrew Zisserman, and Raia Hadsell. Learning to navigate in cities without a map. arXiv preprint arXiv:1804.00168, 2018.
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wier-stra, and Martin Riedmiller. Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602, 2013.
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Belle-mare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. Human-level control through deep reinforcement learning. Nature, 518(7540):529–533, 2015a.
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Belle-mare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. Human-level control through deep reinforcement learning. Nature, 518(7540):529, 2015b.
Emilio Parisotto and Ruslan Salakhutdinov. Neural map: Structured memory for deep reinforcement learning. arXiv preprint arXiv:1702.08360, 2017.
Matthias Plappert, Marcin Andrychowicz, Alex Ray, Bob McGrew, Bowen Baker, Glenn Pow-ell, Jonas Schneider, Josh Tobin, Maciek Chociej, Peter Welinder, et al. Multi-goal reinforce-ment learning: Challenging robotics environments and request for research. arXiv preprint arXiv:1802.09464, 2018.
Vitchyr Pong, Shixiang Gu, Murtaza Dalal, and Sergey Levine. Temporal difference models: Model-free deep rl for model-based control. arXiv preprint arXiv:1802.09081, 2018.
Tom Schaul, Daniel Horgan, Karol Gregor, and David Silver. Universal value function approxima-tors. In International Conference on Machine Learning, pp. 1312–1320, 2015.
Richard S Sutton, Andrew G Barto, et al. Reinforcement learning: An introduction. MIT press, 1998.
Richard S Sutton, Joseph Modayil, Michael Delp, Thomas Degris, Patrick M Pilarski, Adam White, and Doina Precup. Horde: A scalable real-time architecture for learning knowledge from unsuper-vised sensorimotor interaction. In The 10th International Conference on Autonomous Agents and Multiagent Systems-Volume 2, pp. 761–768. International Foundation for Autonomous Agents and Multiagent Systems, 2011.
Christopher JCH Watkins and Peter Dayan. Q-learning. Machine learning, 8(3-4):279–292, 1992.
Yuke Zhu, Roozbeh Mottaghi, Eric Kolve, Joseph J Lim, Abhinav Gupta, Li Fei-Fei, and Ali Farhadi. Target-driven visual navigation in indoor scenes using deep reinforcement learning. In Robotics and Automation (ICRA), 2017 IEEE International Conference on, pp. 3357–3364. IEEE, 2017.

Figure6 :Ablation on loss functions for Fetch Push task. The Floyd-Warshall inspired loss functions Llo and Lup do not help much. Lstep helps a little but only in conjunction with HER Andrychowicz et al. (2016).
图6:Fetch Push任务的损失函数的消融。 Floyd-Warshall激发了失落的功能Llo和Lup没有多大帮助。 Lstep有一点帮助,但只与HER Andrychowicz等人合作。(2016)。

Figure 7: Even when the Goal rewards are removed from HER Andrychowicz et al. (2016) training, the HER is able to learn only if the Lstep is added again. (HER-Goal Rewards+Lstep) is our proposed method.
图7:即使从HER Andrychowicz等人中删除了目标奖励。 (2016)训练,HER只有在再次添加Lstep时才能学习。 (HER-Goal Rewards + Lstep)是我们提出的方法。
APPENDIX
Our algorithm 1 is different from HER Andrychowicz et al. (2016) because it contains additional
step-loss term Lstep at line number 17 which allows the algorithm to learn even when the rewards received are independent of desired goal. Also in HER sampling (line 13), the algorithm recomputes
the rewards because the goal is replaced with a pseudo-goal. Our algorithm does not need reward recomputation because the reward formulation does not depend on the goal and is not affected by choice of pseudo-goal. Our algorithm is also different from Floyd-Warshall Reinforcement learning because it does not contain Lup and Llo terms and contains the additional Lstep.
我们的算法1与HER Andrychowicz等人不同。 (2016)因为它包含额外的
在行号17处的步进丢失项Lstep,其允许算法即使在所接收的奖励独立于期望目标时也学习。 同样在HER采样(第13行)中,算法重新计算
奖励因为目标被伪目标取代。 我们的算法不需要奖励重新计算,因为奖励制定不依赖于目标,也不受伪目标选择的影响。 我们的算法也不同于Floyd-Warshall强化学习,因为它不包含Lup和Llo项并包含额外的Lstep。

9ABLATION ON LOSS AND GOAL REWARDS
In Figure 6 and Figure 7 we show ablation on loss functions and goal rewards. In Figure 7 Our method is shown in blue with HER - Goal rewards + Lstep.
在图6和图7中,我们显示了对损失函数和目标奖励的消融。 在图7中,我们的方法以蓝色显示,其中HER - 目标奖励+ Lstep。