2019 CS224N Assignment 1: Exploring Word Vectors
文章目录
- 包的导入
- Part 1: Count-Based Word Vectors
- Question 1.1: Implement distinct_words
- Question 1.2: Implement compute_co_occurrence_matrix
- Question 1.3: Implement reduce_to_k_dim
- Question 1.4: Implement plot_embeddings
- Question 1.5: Co-Occurrence Plot Analysis
- Part 2: Prediction-Based Word Vectors
- 词向量导入
- Question 2.1: Word2Vec Plot Analysis
- Question 2.2: Polysemous Words
- Question 2.3: Synonyms & Antonyms
- Question 2.4: Finding Analogies
- Question 2.5: Incorrect Analogy
- Question 2.6: Guided Analysis of Bias in Word Vectors
- Question 2.7: Independent Analysis of Bias in Word Vectors
- Question 2.8: Thinking About Bias
- 总结
实验最麻烦的部分往往是环境搭建
----鲁迅
完整的notebook作业请前往我的github
包的导入
- 除 nltk 外,其他包都可以通过 conda install 或 pip install 安装
- nltk.download(‘reuters’),我这里没有下载成功。我是将这条命令注释掉后,手动下载的 reuters 数据,网上有很多教如何手动下载安装的教程。
Part 1: Count-Based Word Vectors
大多数词向量模型从下面这个想法得来的。
You shall know a word by the company it keeps
Co-Occurrence
- 这里我们使用词共现矩阵 A A A, a i j a_{ij} aij表示在词 w i w_i wi周围,词 w j w_j wj出现了多少次。根据定义易知 A A A是一个对称阵,因为假设词 w j w_j wj在词 w i w_i wi出现了m词,那么词 w i w_i wi也在词 w j w_j wj出现了m次,因此 a i j = a j i = m a_{ij} = a_{ji} = m aij=aji=m,那么共现次数怎么计算呢?下面以一个例子解释。
- 首先要选定两个词相隔多远算是共现了,即选定 window 的大小。window 表示词 w i w_i wi周围 |window| 之内的单词都算是与词 w i w_i wi 共现。
假设选定window = n,则词 w i w_i wi前n个单词和后n个单词与 w i w_i wi共现。 - 下面举一个具体的例子。选择 window = 1
- Document 1: "all that glitters is not gold"
- Document 2: "all is well that ends well"
- 得到的共现矩阵为

注:我们一般会给句子(段落/文档)前后增加 “START” 和 “END” 表示起始和结尾。并且也统计到共现矩阵中。举一个例子,“all” 行,“is” 列,为1,表示词 all 周围 is只出现了一次。看我们的语料可发现,is 只在 Dicument 2中出现在 all周围。其他计算类似。
- 由上面的介绍可知,我们得到的词共现矩阵 A ∈ R n × n A \in R^{n×n} A∈Rn×n,n为词表大小。因此我们可以将每行当作每个词的词向量。但向量维度随着语料中的词表大小而增大,且很稀疏,因此我们可以对其进行降维(dimensionality reduction)。
- 这里我们使用奇异值分解 SVD (Singular Value Decomposition) 来对矩阵进行分解
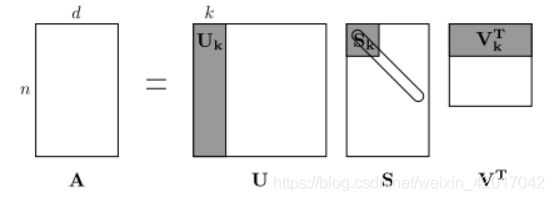
- SVD的介绍:https://davetang.org/file/Singular_Value_Decomposition_Tutorial.pdf
- 我们选择上图中矩阵 U U U的前 k 列作为我们的词向量。
Question 1.1: Implement distinct_words
- 返回语料中出现的所有单词(语料中每个句子已经加上"START"和"END"了,不用我们处理)及个数。即 去重
corpus_words = list(set([y for x in corpus for y in x]))
corpus_words.sort()
num_corpus_words = len(corpus_words)
y for x in corpus for y in x表示遍历corpus的每个句子,然后再遍历句子中的每个单词- 外面紧接着使用
set()去掉重复的单词 - 最后又转回
list, 使用.sort()进行排序,计算词数
Question 1.2: Implement compute_co_occurrence_matrix
- 计算词共现矩阵
def compute_co_occurrence_matrix(corpus, window_size=4):
""" Compute co-occurrence matrix for the given corpus and window_size (default of 4).
Note: Each word in a document should be at the center of a window. Words near edges will have a smaller
number of co-occurring words.
For example, if we take the document "START All that glitters is not gold END" with window size of 4,
"All" will co-occur with "START", "that", "glitters", "is", and "not".
Params:
corpus (list of list of strings): corpus of documents
window_size (int): size of context window
Return:
M (numpy matrix of shape (number of corpus words, number of corpus words)):
Co-occurence matrix of word counts.
The ordering of the words in the rows/columns should be the same as the ordering of the words given by the distinct_words function.
word2Ind (dict): dictionary that maps word to index (i.e. row/column number) for matrix M.
"""
words, num_words = distinct_words(corpus)
M = None
word2Ind = {}
# ------------------
# Write your implementation here.
for idx,val in enumerate(words): #构造单词到下标的对应字典(NLP中经常需要)
word2Ind[val]=idx
M = np.zeros((num_words,num_words)) #初始化共现矩阵
for sen in corpus: #遍历每个句子
for idx,cen in enumerate(sen): #遍历每个单词
for i in range(-window_size,window_size+1,1): #遍历窗口
if i!=0 and idx+i>=0 and idx+i<len(sen): #!=0表示跳过该单词本身。然后就是范围判断
M[word2Ind[cen]][word2Ind[sen[idx+i]]]+=1 #将第cen行,第sen[idx+i] 列数加一
# ------------------
return M, word2Ind
- 函数输入为 语料 和 window大小。
- 首先调用第一题写的函数计算出所有的单词以及总词数。
- 构建了一个字典
word2Ind用于将词映射到下标,为词共现矩阵M赋值时需要 - 代码中有详细注释,请看上面的代码
Question 1.3: Implement reduce_to_k_dim
- 实现我们之前所讲的 SVD,将共现矩阵分解得到词向量维度为 k ,只需加下面两行代码
svd = TruncatedSVD(n_components=k, n_iter=n_iters)
M_reduced = svd.fit_transform(M)
- 函数使用见官方文档。
Question 1.4: Implement plot_embeddings
- 将单词画到图中即可,代码如下
for word in words:
x = M_reduced[word2Ind[word]][0]
y = M_reduced[word2Ind[word]][1]
plt.scatter(x, y, marker='x', color='red')
plt.text(x,y,word)
plt.show()
- 根据作业中给出的一个例子写即可。
- matplotlib的更多绘图教程。
Question 1.5: Co-Occurrence Plot Analysis
What clusters together in 2-dimensional embedding space?
What doesn’t cluster together that you might think should have?
Note: “bpd” stands for “barrels per day” and is a commonly used abbreviation in crude oil topic articles.
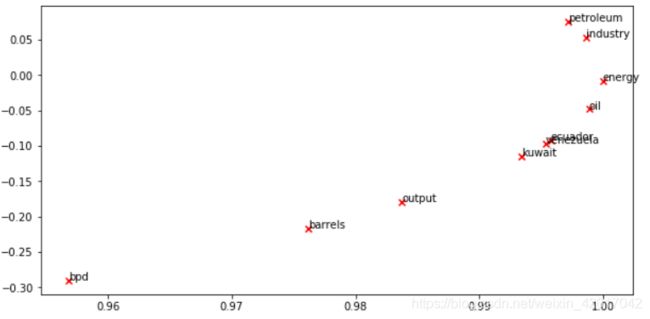
- 根据可视化的结果,可以发现地名(kuawait、venezuela、ecuador)cluster 一起了
- 我觉得产量,桶/每天等名词(bpd,output),还有petroleum、oil 应该 cluster 在一起,而没有。
Part 2: Prediction-Based Word Vectors
word2vec论文:https://papers.nips.cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality.pdf
环境搭建是实验最麻烦的地方
我没说过。 — 鲁迅
词向量导入
- notebook中使用了 gensim.downloader 来下载,一开始我每次尝试都是终止连接等一系列报错。之后虽然可以下载了,但非常慢。

- 因此我就手动下载了数据,首先在 spyder 中使用 ctrl+clik 查看源码,找到下载链接

- 然后找到对应的数据 word2vec-google-news-300.gz 和 init.py,下载好后,放入源码中的下载代码找到的目录。但依旧会报错


- 最后我查看了 init.py,发现好像有载入模型的代码,然后我将 notebook 中载入词向量的代码进行了修改,如下。终于能够使用词向量了~
def load_word2vec():
""" Load Word2Vec Vectors
Return:
wv_from_bin: All 3 million embeddings, each lengh 300
"""
# import gensim.downloader as api
# wv_from_bin = api.load("word2vec-google-news-300")
import os
from gensim.models import KeyedVectors
from gensim.downloader import base_dir
path = os.path.join(base_dir, 'word2vec-google-news-300', "word2vec-google-news-300.gz")
wv_from_bin = KeyedVectors.load_word2vec_format(path, binary=True)
vocab = list(wv_from_bin.vocab.keys())
print("Loaded vocab size %i" % len(vocab))
return wv_from_bin
- 注:需要占用很大内存,建议不要开太多应用
Question 2.1: Word2Vec Plot Analysis
What clusters together in 2-dimensional embedding space?
What doesn’t cluster together that you might think should have?
How is the plot different from the one generated earlier from the co-occurrence matrix?
- 直接运行代码即可
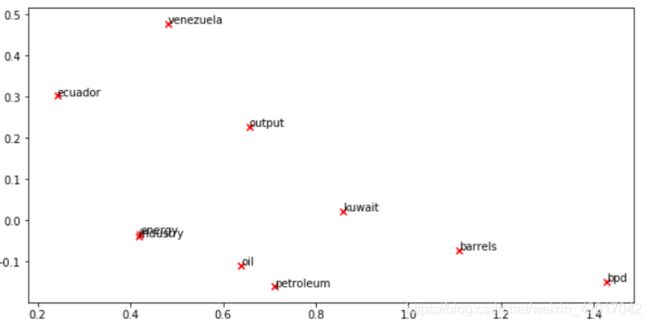
- 很明显,enegy 和 industry cluster在一起了
- 地名没有 cluster在一起,还有之前所说的应该cluster在一起的,也没在一起
- 与使用共现矩阵得到的词向量的不同之处在于
- 词的位置不同
- cluster情况不同(我觉得原因之一是语料,两者使用语料不同)
Question 2.2: Polysemous Words
- 通过余弦相似度找多义词
Cosine Similarity
即根据两个词向量直接的夹角来衡量两个词的距离
Please state the polysemous word you discover and the multiple meanings that occur in the top 10.
Why do you think many of the polysemous words you tried didn’t work?
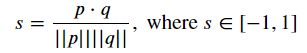
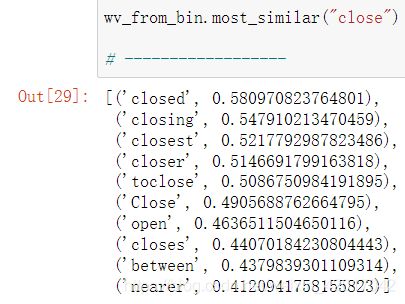
- 我找到的多义词为 close,如下图,前十相近的含义中有:关闭,近的
- 为什么需要大多数多义词,前十中并没有出现多个意义
- 因为一些多义词的多个含义使用的频率不同,因此训练结果可能偏向于其中最常用的含义。例如,我查了 pen大部分是笔的意思,而围栏不在top ten中,novel(小说、新奇的)也是。
Question 2.3: Synonyms & Antonyms
- 找出三个词 w 1 , w 2 , w 3 w_1,w_2,w_3 w1,w2,w3,其中 w 1 w_1 w1 和 w 2 w_2 w2是近义词, w 1 w_1 w1 和 w 3 w_3 w3是反义词。且 w 1 w_1 w1 和 w 2 w_2 w2之间的余弦距离大于 w 1 w_1 w1 和 w 3 w_3 w3之间的余弦距离。余弦距离 = 1 - 余弦相似度
- 找的结果如下

- 分析为什么会出现这样的情况
- 可能是找出的这对反义词比起近义词更常在一起出现
Question 2.4: Finding Analogies
- 找出类比,例如
man : king :: woman : x中,x最有可能是什么 - 我找的结果如下,即
boy:son :: girl:daughter

- 要注意这个函数的用法,上图表示求
boy:son :: girl:x中的 x
Question 2.5: Incorrect Analogy
- 找出一个不正确的类比例子
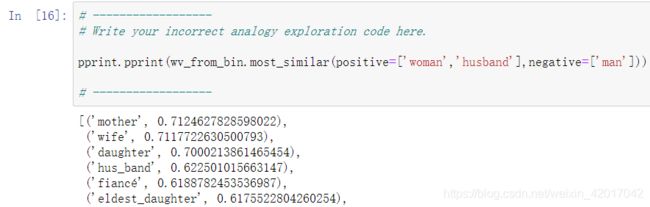
- 如上图,我求了
man:husband :: woman:x,给出的最匹配是错误的,应为 wife
Question 2.6: Guided Analysis of Bias in Word Vectors
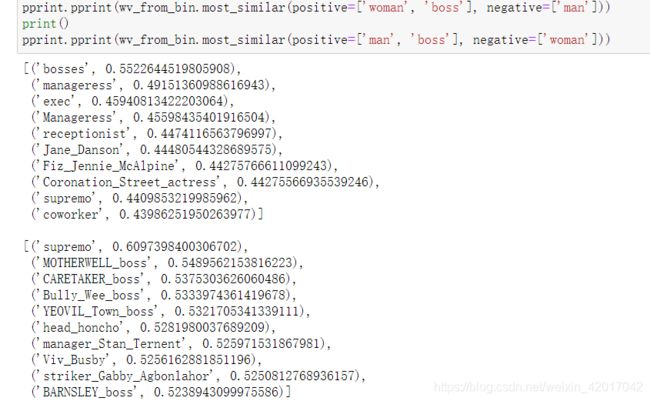
- 题中分别求了
man:boss :: woman:x和woman:boss :: man:y - 结果为 x = bosses,依旧为老板,而 y = supremo,最高领导人。明显在性别上有 bias,结果应该也为boss。
Question 2.7: Independent Analysis of Bias in Word Vectors
- 找出另一个有bias的例子
- 我找了一个经典的例子
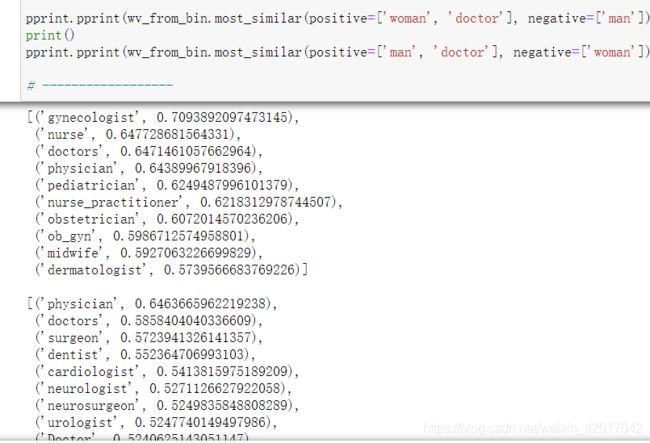
man:doctor :: woman:x,得出的 x 有护士(第二位),而反过来,求出来的都是各种”医生“,因此带有bias
Question 2.8: Thinking About Bias
- What might be the cause of these biases in the word vectors?
- 在lecture19中有讲解。这里的bias来源主要是 数据中的bias,因为这是通过新闻语料训练得来,因此,媒体报道的偏差也有影响
总结
- 第一个assignment比较简单,不过搭建环境要花费一些时间
- 两种求词向量的方法
- 基于计数(词共现矩阵 + SVD)
- 基于预测(word2vec)