3D Vision、SLAM求职宝典 | 图像处理篇(C)
C 图像处理
准备把这一篇写完后,SLAM求职专题系列就告一段落,还剩下E篇关于机器学习和深度学习暂不写了。

目录
C 图像处理
1. 图像平滑算子、边缘检测算子
2. 图像去噪滤波算法(高斯、均值、双边、Guide filter)
3. 三个度量patch相似度的方法(SSD、SAD、NCC)
4. 二进制描述子
5. SIFT的4个不变性
6. 特征点、描述子ORB、SIFT、SURF、BRIEF等等 。
7. Mat实现、Mat类指针引用复制函数
8. 颜色直方图统计,手撕代码
9. 形态学操作,手撕代码
10. 积分图,手撕代码
11. 连通区域算法,给二值图,求出最大联通区域(用深度优先和广度优先算法,手撕代码)
12. Mser、Swt检测
13. 图像分割(Grabcut)
14. 目标跟踪(相关滤波KCF)
1. 图像平滑算子、边缘检测算子
图像处理里面的概念不少,很容易混为一谈。所以这里我将结合《计算机视觉算法与应用》以及一些网上的博客,尽可能把这些概念用通俗的语言理清。
1. 领域算子:也叫局部算子。利用像素周围的值决定次像素的最终输出值。
- 线性算子(滤波)是一种常用的领域算子,像素的输出值取决于一小领域内输入像素的加权和
![]()

其中的h为权重核或者叫滤波系数。
- 非线性算子,例如形态学运算、距离变换等。

以上分别是一些领域算子:a. 原始图像 b. 平滑 c. 锐化 d. 保边平滑滤波 e. 图像的二值化 f. 膨胀 g. 距离变换 h. 连通量
2. 可分离的滤波(都是线性滤波)
卷积运算每个像素需要K^2操作,K是卷积核的大小。如果一个卷积核可以采用如下方式操作可加快速度,称为可分离的: 线用一维行向量进行卷积,再用一维列向量进行卷积(总共需要2K操作)。

以上这些是常用的可分离的线性滤波器。(第一个我们可以叫方框滤波器,有些地方也叫归一化滤波)
3. 拉普拉斯算子
拉普拉斯滤波器跟上面的以上滤波器的不同在于它是一种高通滤波器,能够保留图像的高频成分。图像的二阶倒数称为“Laplacian”算子 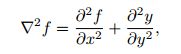
- 离散函数导数
离散函数的导数退化成了差分,一维一阶差分公式和二阶差分公式分别为
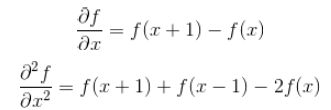
- Laplace算子的差分形式
分别对Laplace算子x,y两个方向的二阶导数进行差分就得到了离散函数的Laplace算子。在一个二维函数f(x,y)中,x,y两个方向的二阶差分分别为

写成filter mask的形式如下:

该mask的特点,mask在上下左右四个90度的方向上结果相同,也就是说在90度方向上无方向性。为了让该mask在45度的方向上也具有该性质,对该filter mask进行扩展定义为

4. 图像平滑与锐化
- 平滑核函数常用于减少高频噪声,使图片变得有些模糊,低通滤波。灰度突变在频域中代表了一种高频分量,低通滤波器的作用就是滤掉高频分量,从而达到减少图象噪声的目的。常用的平滑算子有: (1)方框滤波; (2)高斯滤波; (3)中值滤波
- 锐化就是通过增强高频分量来减少图象中的模糊,因此又称为高通滤波。锐化处理在增强图象边缘的同时增加了图象的噪声。。常用的锐化操作用拉普拉斯(Laplacian)算子。
5. 非线性滤波 (比如在噪声是散粒噪声而不是高斯噪声,即图像偶尔会出现很大的值的时候,用非线性滤波更好)
- 中值滤波:中值滤波(Median filter)是一种典型的非线性滤波技术,基本思想是用像素点邻域灰度值的中值来代替该像素点的灰度值,该方法在去除脉冲噪声、椒盐噪声的同时又能保留图像边缘细节。
- 双边滤波:双边滤波(Bilateral filter)是一种非线性的滤波方法,是结合图像的空间邻近度和像素值相似度的一种折衷处理,同时考虑空域信息和灰度相似性,达到保边去噪的目的。具有简单、非迭代、局部的特点。
- 具体可见(https://www.jianshu.com/p/09f961df9c6c)
6. 边缘检测算子——
图来自 https://blog.csdn.net/LilyNothing/article/details/78996239

具体你可再参考:
图像处理常用边缘检测算子
https://blog.csdn.net/green_master/article/details/52504575
几种边缘检测算子的比较Roberts,Sobel,Prewitt,LOG,Canny
https://blog.csdn.net/gdut2015go/article/details/46779251
2. 图像去噪滤波算法(高斯、均值、双边、Guide filter)
上面的问题中我们已经把常见的一些图像处理方法以及滤波的概念介绍了。
参考: 图像去噪算法简介(https://blog.csdn.net/eric_e/article/details/79504444)
图像去噪算法分类——
(1) 空间域滤波
空域滤波是在原图像上直接进行数据运算,对像素的灰度值进行处理。常见的空间域图像去噪算法有邻域平均法、中值滤波、低通滤波等。
(2) 变换域滤波
图像变换域去噪方法是对图像进行某种变换,将图像从空间域转换到变换域,再对变换域中的变换系数进行处理,再进行反变换将图像从变换域转换到空间域来达到去除图像嗓声的目的。将图像从空间域转换到变换域的变换方法很多,如傅立叶变换、沃尔什-哈达玛变换、余弦变换、K-L变换以及小波变换等。而傅立叶变换和小波变换则是常见的用于图像去噪的变换方法。
(3) 偏微分方程
偏微分方程是近年来兴起的一种图像处理方法,主要针对低层图像处理并取得了很好的效果。偏微分方程具有各向异性的特点,应用在图像去噪中,可以在去除噪声的同时,很好的保持边缘。偏微分方程的应用主要可以分为两类:一种是基本的迭代格式,通过随时间变化的更新,使得图像向所要得到的效果逐渐逼近,这种算法的代表为Perona和Malik的方程[27],以及对其改进后的后续工作。该方法在确定扩散系数时有很大的选择空间,在前向扩散的同时具有后向扩散的功能,所以,具有平滑图像和将边缘尖锐化的能力。偏微分方程在低噪声密度的图像处理中取得了较好的效果,但是在处理高噪声密度图像时去噪效果不好,而且处理时间明显高出许多。
(4) 变分法
另一种利用数学进行图像去噪方法是基于变分法的思想,确定图像的能量函数,通过对能量函数的最小化工作,使得图像达到平滑状态,现在得到广泛应用的全变分TV模型就是这一类。这类方法的关键是找到合适的能量方程,保证演化的稳定性,获得理想的结果。
(5) 形态学噪声滤除器
将开与闭结合可用来滤除噪声,首先对有噪声图像进行开运算,可选择结构要素矩阵比噪声尺寸大,因而开运算的结果是将背景噪声去除;再对前一步得到的图像进行闭运算,将图像上的噪声去掉。据此可知,此方法适用的图像类型是图像中的对象尺寸都比较大,且没有微小细节,对这类图像除噪效果会较好。
针对这道题,应该主要考察空间域上的去噪滤波算法——
经典的图像去噪算法有: 均值滤波,高斯滤波,双边滤波,中值滤波 (具体还有不明的可以参见上个问题或者自己查阅网络)
3. 三个度量patch相似度的方法(SSD、SAD、NCC)
参考《slam十四讲》中的内容——
极线搜索与块匹配: 在极线上搜索某一像素的匹配时,单个像素的亮度很容易没有区分度,因此取像素的周围小窗口提高区分度,所谓的块匹配,算法的假设从像素的灰度不变性变为了图像块的灰度不变性
把p1周围的小块记做A(i,j),候选的匹配块为B(i,j) 。这里介绍三种相似度的计算方法
1. SAD ( sum of absolute difference )

2. SSD ( sum of squared distance )
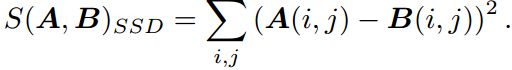
3. NCC ( normalized cross correlation )
 接近1,表示相似
接近1,表示相似
4. 二进制描述子
SIFT和SURF介绍
https://www.cnblogs.com/hepc/p/9636474.html
BRIEF描述子——
BRIEF(Binary Robust Independent Elementary Features)是一种对已检测到的特征点进行表示和描述的特征描述方法,和传统的利用图像局部邻域的灰度直方图或梯度直方图提取特征的方式不同,BRIEF是一种二进制编码的特征描述子,既降低了存储空间的需求,提升了特征描述子生成的速度,也减少了特征匹配时所需的时间。
原理概述
经典的图像特征描述子SIFT和SURF采用128维(SIFT)或者64维(SURF)特征向量,每维数据一般占用4个字节(Byte),一个特征点的特征描述向量需要占用512或者256个字节。如果一幅图像中包含有大量的特征点,那么特征描述子将占用大量的存储,而且生成描述子的过程也会相当耗时。在SIFT特征的实际应用中,可以采用PCA、LDA等特征降维的方法来减少特征描述子的维度,例如PCA-SIFT;此外还可以采用一些局部敏感哈希(Locality-Sensitive Hashing, LSH)的方法将特征描述子编码为二进制串,然后使用汉明距离(Hamming Distance)进行特征点的匹配,汉明距离计算的是两个二进制比特串中同一位置不同值的个数,可通过异或操作快速实现,大大提升了特征匹配的效率。
BRIEF正是这样一种基于二进制编码生成特征描述子,以及利用汉明距离进行特征匹配的算法。由于BRIEF只是一种特征描述子,因此事先得检测并定位特征点,可采用Harris、FAST或者是SIFT算法检测特征点,在此基础上利用BRIEF算法建立特征描述符,在特征点邻域Patch内随机选取若干点对(p,q)(p,q),并比较这些点对的灰度值,若I(p)>I(q)I(p)>I(q),则编码为1,否则编码为0。这样便可得到一个特定长度的二进制编码串,即BRIEF特征描述子。
---------------------
原文:https://blog.csdn.net/Zachary_Co/article/details/78867059
二进制描述子有: BRIEF(ORB用到)、 BRISK, FREAK。
BRISK算法是2011年ICCV上《BRISK:Binary Robust Invariant Scalable Keypoints》文章中,提出来的一种特征提取算法,也是一种二进制的特征描述算子。它具有较好的旋转不变性、尺度不变性,较好的鲁棒性等。在图像配准应用中,速度比较:SIFT geometric invariance:平移,旋转,尺度……; photometric invariance:亮度,曝光…… 计算速度: ORB>>SURF>>SIFT(各差一个量级) 旋转鲁棒性: SURF>ORB~SIFT(表示差不多) 模糊鲁棒性: SURF>ORB~SIFT 尺度变换鲁棒性: SURF>SIFT>ORB(ORB并不具备尺度变换性) SIFT、SURF、Harris、BRIEF、FAST、DAISY、FAST等描述符介绍 https://blog.csdn.net/qq_29828623/article/details/52403562 实现好像不用吧? 这里我们主要把时间用来学习OpenCV中的Mat类—— Opencv中的Mat类使用方法总结:https://blog.csdn.net/chen134225/article/details/80787665 OpenCV学习笔记(04):Mat类详解(一):https://blog.csdn.net/CV_Jason/article/details/54928920 Opencv Mat的三种常用类型简介:https://blog.csdn.net/Elen005/article/details/80066073 题目可能是要考察OpenCV的使用吧。。 颜色直方图在OpenCV的的实现—— parameters: calcHist函数的channels参数和narrays以及dims共同来确定用于计算直方图的图像;首先dims是最终的直方图维数,narrays指出了arrays数组中图像的个数,其中每一幅图像都可以是任意通道的【只要最终dims不超过36即可】。 如果channels参数为0,则narrays和dims必须相等,否则弹出assert,此时计算直方图的时候取数组中每幅图像的第0通道。当channels不是0的时候,用于计算直方图的图像是arrays中由channels指定的通道的图像,channels与arrays中的图像的对应关系,如channels的参数说明的,将arrays中的图像从第0幅开始按照通道摊开排列起来,然后channels中的指定的用于计算直方图的就是这些摊开的通道。 假设有arrays中只有一幅三通道的图像image,那么narrays应该为1,如果是想计算3维直方图【最大也只能是3维的】,想将image的通道2作为第一维,通道0作为第二维,通道1作为第三维,则可以将channels设置为channesl={2,0,1};这样calcHist函数计算时就按照这个顺序来统计直方图。 OpenCV中计算RGB空间的颜色直方图—— (参考https://blog.csdn.net/zhu_hongji/article/details/80443585) 统计颜色直方图方法一:采用三维数组a[][][]来遍历Mat每一个像素 这道题目我们主要学习的是以上的代码,如果对其中的概念还有所不理解,那么请看下面的链接中的例子,会有较直观的认识: http://www.cnblogs.com/ldxsuanfa/p/9942564.html 统计颜色直方图方法二:采用一维数组a[]来遍历Mat每一个像素 (参考https://blog.csdn.net/dyx810601/article/details/50520243) 图像形态学操作是基于形状的一系列图像处理操作的合集,主要是基于集合论基础上的形态学数学。主要有四个操作:膨胀,腐蚀,开,闭。 这个问题似乎不需要自己实现形态学的代码吧,我们这里主要贴两篇博客,讲形态学的概念以及OpenCV中的实现! 形态学操作、腐蚀、膨胀、开运算、闭运算http://blog.sina.com.cn/s/blog_159aff7940102xdf4.html 形态学操作https://www.jianshu.com/p/29eddeddcccb 积分图简介—— 有时候只需要计算图像中某个特定区域的直方图。实际上累计图像的某个子区域内的像素总和,是很多计算机视觉算法中常见的过程。现在假设需要对图像中的多个兴趣区域计算几个此类直方图。这些计算过程都马上会变得非常耗时。这种情况下,有一个工具可以极大地提高统计图像子区域像素的效率:积分图像。 积分图的定义: 取图像左上侧的全部像素计算累加和,并用这个累加和替换图像中的每一个像素,用这种方式得到的图像称为积分图像。为了防止溢出,积分图像的值通常采用int类型或float类型。 如果知道了积分图,就可以很容易的计算出图下A区域的像素之和。 求图像积分图的代码—— 其中要注意,W×H的图像,积分图为(W+1)×(H+1), 其中的第一列和第一行都是0。原图像是用一维数组来存储像素的。 (来自https://www.cnblogs.com/Imageshop/p/6219990.html) 注意原文中函数参数列表中还有一个参数是stride,应该指的是步长,但是一般都是每一行都要进行积分,所以代码中我将这个参数取消掉了。而且原文作者还给了更高效的解法,略过 。 这个问题在SLAM篇(D1)中已经解答过。 先来看一篇检测算法的比较: 图像处理中,SIFT,FAST,MSER,STAR等特征提取算法的比较与分析 https://blog.csdn.net/Real_Myth/article/details/51305908 再来看一篇关于检测文本的: MSER+NMS检测图像中文本区域 https://www.jianshu.com/p/b5af24e2f9ff 1. MSER MSER(Maximally Stable Extrernal Regions)是区域检测中影响最大的算法。 MSER基于分水岭的概念:对图像进行二值化,二值化阈值取[0, 255],这样二值化图像就经历一个从全黑到全白的过程(就像水位不断上升的俯瞰图)。在这个过程中,有些连通区域面积随阈值上升的变化很小,这种区域就叫MSER。 2. Swt 也是主要用于文本检测,名称为笔画宽度变换检测。 流程首先计算图像的canny 边缘,然后根据边缘的方向信息计算图像的SWT ,根据笔画宽度信息将像素聚集成连通域,利用几何推理如连通域的高宽比,连通域笔画的方差,均值,中值等来过滤连通域,将连通域聚集成文本行,最后将文本行分割成一个个词。流程的核心为SWT和滤除连通域。 (可以参考https://www.cnblogs.com/dawnminghuang/p/3807678.html) 图像分割大致了解下,看着一篇博客就够了,其中也讲到了Grabcut—— 图像分割技术介绍https://blog.csdn.net/SIGAI_CSDN/article/details/84024925 如果更全面对图像分割的算法进行分类,请看—— 图像处理--图像分割算法介绍https://blog.csdn.net/yangleo1987/article/details/53173753 现在的图像分割离不开深度学习,请看深度学习之图像分割综述—— 图像分割综述【深度学习方法】https://blog.csdn.net/weixin_41923961/article/details/80946586 都比较长,学习很花时间额。 高速跟踪方法KCF主要出自2015的一篇PAMI的文章,请看下面的博客—— KCF目标跟踪方法分析与总结 http://www.cnblogs.com/YiXiaoZhou/p/5925019.html 写博不易,您的支持让知识之花绽放得更美丽 ^_^
5. SIFT的4个不变性
6. 特征点、描述子ORB、SIFT、SURF、BRIEF等等 。
7. Mat实现、Mat类指针引用复制函数
8. 颜色直方图统计,手撕代码
void calcHist(const Mat* arrays,
int narrays,
const int* channels,
InputArray mask,
OutputArray hist,
int dims,
const int* histSize,
const float** ranges,
bool uniform=true,
bool accumulate=false )
//计算图像RGB空间的颜色直方图
#includevectorvector
9. 形态学操作,手撕代码
10. 积分图,手撕代码
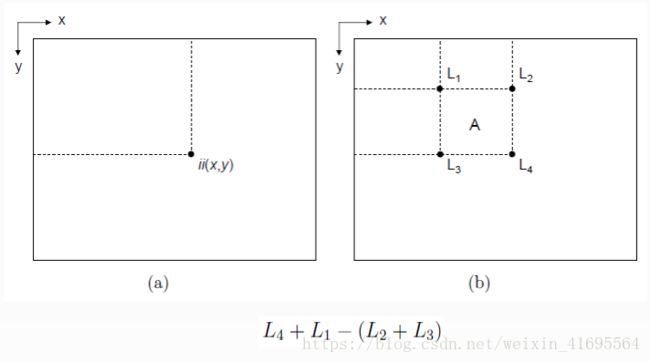
void GetGrayIntegralImage(unsigned char *Src, int *Integral, int Width, int Height)
{
memset(Integral, 0, (Width + 1) * sizeof(int)); // 第一行都为0
for (int Y = 0; Y < Height; Y++)
{
unsigned char *LineSrc = Src + Y * Width; //原图像中每一行的起始位置
int *LinePre = Integral + Y * (Width + 1) + 1; // 上一行位置
int *LineCur = Integral + (Y + 1) * (Width + 1) + 1; // 当前位置,注意每行的第一列的值都为0
LineCur[-1] = 0; // 第一列的值为0
//这一步我也是头一次见,数组的下标可以为负数,表示内存中的上一位置
for (int X = 0, Sum = 0; X < Width; X++)
{
Sum += LineSrc[X]; // 行方向累加
LineCur[X] = LinePre[X] + Sum; // 更新积分图
}
}
}
11. 连通区域算法,给二值图,求出最大联通区域(用深度优先和广度优先算法,手撕代码)
12. Mser、Swt检测
 ,其中Qi表示第i个连通区域的面积,Δ表示微小的阈值变化(注水),当vi小于给定阈值时认为该区域为MSER。显然,这样检测得到的MSER内部灰度值是小于边界的,想象一副黑色背景白色区域的图片,显然这个区域是检测不到的。因此对原图进行一次MSER检测后需要将其反转,再做一次MSER检测,两次操作又称MSER+和MSER-
,其中Qi表示第i个连通区域的面积,Δ表示微小的阈值变化(注水),当vi小于给定阈值时认为该区域为MSER。显然,这样检测得到的MSER内部灰度值是小于边界的,想象一副黑色背景白色区域的图片,显然这个区域是检测不到的。因此对原图进行一次MSER检测后需要将其反转,再做一次MSER检测,两次操作又称MSER+和MSER-
13. 图像分割(Grabcut)
14. 目标跟踪(相关滤波KCF)

