初识 fastText
参考资料:
https://blog.csdn.net/feilong_csdn/article/details/88655927
https://blog.csdn.net/qq_16633405/article/details/80578431
FastText API 文档 & 参数说明
https://blog.csdn.net/qq_32023541/article/details/80845913
https://blog.csdn.net/princemrgao/article/details/94600844
一、概要
1.1 什么是FastText
fastText是一个用于文本分类和词向量表示的库,它能够把文本转化成连续的向量然后用于后续具体的语言任务
其特点就是fast。相对于其它文本分类模型,如SVM,Logistic Regression和neural network等模型,fastText在保持分类效果的同时,大大缩短了训练时间。
1.2 FastText优缺点
- 适合大型数据+高效的训练速度:能够训练模型“在使用标准多核CPU的情况下10分钟内处理超过10亿个词汇”
- 支持多语言表达:利用其语言形态结构,fastText能够被设计用来支持包括英语、德语、西班牙语、法语以及捷克语等多种语言。FastText的性能要比时下流行的word2vec工具明显好上不少,也比其他目前最先进的词态词汇表征要好。
- fastText专注于文本分类,在许多标准问题上实现当下最好的表现(例如文本倾向性分析或标签预测)。
二、FastText原理
fastText 方法包含三部分:模型架构、层次 Softmax 和 N-gram 特征。
- fastText 模型输入一个词的序列(一段文本或者一句话),输出这个词序列属于不同类别的概率。
- 序列中的词和词组组成特征向量,特征向量通过线性变换映射到中间(隐藏)层,中间层再映射到标签。
- fastText 在预测标签时使用了非线性激活函数,但在中间层不使用非线性激活函数。
- fastText 模型架构和 Word2Vec 中的 CBOW 模型很类似。不同之处在于,fastText 预测标签,而 CBOW 模型预测中间词。
2.1 第一部分:模型架构
fastText的模型架构类似于CBOW,两种模型都是基于Hierarchical Softmax,都是三层架构:输入层、 隐藏层、输出层。

CBOW架构

fastText
其中x1,x2,…,xN−1,xN表示一个文本中的n-gram向量,每个特征是词向量的平均值。
2.2 第二部分:层次 Softmax
word2vec将上下文关系转化为多分类任务,进而训练逻辑回归模型,这里的类别数量|V|词库大小。通常的文本数据中,词库少则数万,多则百万,在训练中直接训练多分类逻辑回归并不现实。word2vec中提供了两种针对大规模多分类问题的优化手段, negative sampling 和 hierarchical softmax。在优化中,
- negative sampling 只更新少量负面类,从而减轻了计算量。
- hierarchical softmax 将词库表示成前缀树,从树根到叶子的路径可以表示为一系列二分类器,一次多分类计算的复杂度从|V|降低到了树的高度
标准softmax:
softmax函数常在神经网络输出层充当激活函数,目的就是将输出层的值归一化到0-1区间,将神经元输出构造成概率分布,主要就是起到将神经元输出值进行归一化的作用
层次softmax:
计算一个类别的softmax概率时,我们需要对所有类别概率做归一化,在这类别很大情况下非常耗时,因此提出了分层softmax(Hierarchical Softmax),思想是根据类别的频率构造哈夫曼树来代替标准softmax,通过分层softmax可以将复杂度从N降低到logN,下图给出分层softmax示例:
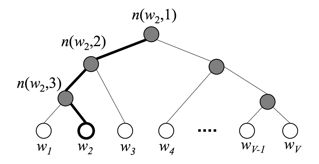
将输入层中的词和词组构成特征向量,再将特征向量通过线性变换映射到隐藏层,隐藏层通过求解最大似然函数,然后根据每个类别的权重和模型参数构建Huffman树,将Huffman树作为输出。
在层次softmax模型中,叶子结点的词没有直接输出的向量,而非叶子节点都有响应的输出在模型的训练过程中,通过Huffman编码,构造了一颗庞大的Huffman树,同时会给非叶子结点赋予向量。我们要计算的是目标词w的概率,这个概率的具体含义,是指从root结点开始随机走,走到目标词w的概率。因此在途中路过非叶子结点(包括root)时,需要分别知道往左走和往右走的概率。
以上图中目标词为w2为例,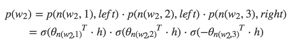
到这里可以看出目标词为w的概率可以表示为: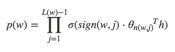
其中θn(w,j)是非叶子结点n(w,j)的向量表示(即输出向量);h是隐藏层的输出值,从输入词的向量中计算得来;sign(x,j)是一个特殊函数定义
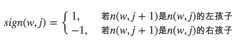
此外,所有词的概率和为1,即
最终得到参数更新公式为:
疑问:
计算每一条路径的时间复杂度是O(logD),要比O(D)低很多,但是普通的softmax是一下子把所有的词的打分都算出来了,而层次softmax只是算出来一条路径的概率,还有其他的词的概率需要再一次计算,虽然每一条路径的时间复杂度低,但是要计算所有的路径,如何比较计算多次与计算一次谁的用时少呢?
首先,的确是普通的softmax一次就把需要的所有词的打分就计算出来了,在进行归一化时不用反复计算,层次softmax需要每条路径都计算一次,但是即使这样,层次softmax也比普通的softmax计算量少。

输出层是层次softmax,构建的霍夫曼树如题所示,现在要让输出层输出字典中所有词的概率分布,就要计算每个词的概率,每个词对应的是图中的叶节点,现在假设求出了‘足球’这个词的概率,求这个词概率的时间复杂度是 O(logD),那其他词的概率怎么求呢?需要一一计算每一条路径吗?事实上,当我们求出‘足球’这个词的概率之后,与红线相连的父节点的另一条分支的概率也求出来了,不需要再重新计算。
最后不知道概率的分支只有权值为14的父节点对应的两个叶节点,只需要求出他们其中一个的概率就可以把所有的叶节点的概率求出来,而求14对应的概率的时间复杂度 O(剩余分支时间复杂度)<=O(logD),所以,求出所有叶节点的概率的时间复杂度是O(logD)+O(剩余分支时间复杂度),根据时间复杂度的定义,时间复杂度相加的结果是几个加数的最大值,所以层次softmax的总的时间复杂度仍然是O(logD)。
参考: https://blog.csdn.net/itplus/article/details/37969979
2.3 第三部分:N-gram 特征
常用的特征是词袋模型(将输入数据转化为对应的Bow形式)。但词袋模型不能考虑词之间的顺序,因此 fastText 还加入了 N-gram 特征。n-gram是基于语言模型的算法,基本思想是将文本内容按照子节顺序进行大小为N的窗口滑动操作,最终形成窗口为N的字节片段序列。而且需要额外注意一点是n-gram可以根据粒度不同有不同的含义,有字粒度的n-gram和词粒度的n-gram。
“我 爱 她” 这句话中的词袋模型特征是 “我”,“爱”, “她”。这些特征和句子 “她 爱 我” 的特征是一样的。如果加入 2-Ngram,第一句话的特征还有 “我-爱” 和 “爱-她”,这两句话 “我 爱 她” 和 “她 爱 我” 就能区别开来了。当然,为了提高效率,我们需要过滤掉低频的 N-gram。
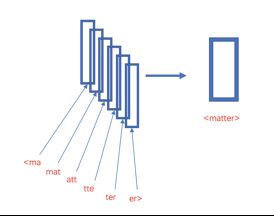
同时n-gram也可以在字符级别工作,例如对单个单词matter来说,假设采用3-gram特征,那么matter可以表示成图中五个3-gram特征,这五个特征都有各自的词向量,五个特征的词向量和即为matter这个词的向其中“<”和“>”是作为边界符号被添加,来将一个单词的ngrams与单词本身区分开来:
使用n-gram有如下优点
1、为罕见的单词生成更好的单词向量:根据上面的字符级别的n-gram来说,即是这个单词出现的次数很少,但是组成单词的字符和其他单词有共享的部分,因此这一点可以优化生成的单词向量
2、在词汇单词中,即使单词没有出现在训练语料库中,仍然可以从字符级n-gram中构造单词的词向量
3、n-gram可以让模型学习到局部单词顺序的部分信息, 如果不考虑n-gram则便是取每个单词,这样无法考虑到词序所包含的信息,即也可理解为上下文信息,因此通过n-gram的方式关联相邻的几个词,这样会让模型在训练的时候保持词序信息
三、fastText教程-单词表示词向量
1、获取数据
2、训练词向量
$ mkdir result
$ ./fasttext skipgram -input data/fil9 -output result/fil9
分解上述命令:./fasttext使用skipgram模型调用二进制fastText可执行文件,当然也可以使用cbow模型,-input表示输入数据路径,-output表示训练的词向量模型所在路径,当fastText运行时,屏幕会显示进度和估计的完成时间,程序完成后,结果目录应该出现如下两个文件,可通过下面命令查看:
$ ls -l result
-rw-r-r-- 1 bojanowski 1876110778 978480850 Dec 20 11:01 fil9.bin
-rw-r-r-- 1 bojanowski 1876110778 190004182 Dec 20 11:01 fil9.vec
fil9.bin文件是一个二进制文件,它存储了整个fastText模型,随后可以进行加载,fil9.vec文件是一个包含单词向量的文本文件,每一行对应词汇表中的每个单词,可通过如下命令查看fil9.vec中的信息
$ head -n 4 result/fil9.vec
218316 100
the -0.10363 -0.063669 0.032436 -0.040798 0.53749 0.00097867 0.10083 0.24829 ...
of -0.0083724 0.0059414 -0.046618 -0.072735 0.83007 0.038895 -0.13634 0.60063 ...
one 0.32731 0.044409 -0.46484 0.14716 0.7431 0.24684 -0.11301 0.51721 0.73262 ...
从上面结果可见,第一行显示的是单词向量和向量维度,接下来几行是词汇表中所有单词的单词向量,顺序是按照频率降低的顺序进行排序
3、模型参数调优
1、模型中最重要的两个参数是:词向量大小维度、subwords范围的大小
- 词向量维度越大,便能获得更多的信息但同时也需要更多的训练数据,同时如果它们过大,模型也就更难训练速度更慢,默认情况下使用的是100维的向量,但在100-300维都是常用到的调参范围。
- subwords是一个单词序列中包含最小(minn)到最大(maxn)之间的所有字符串(也即是n-grams),默认情况下我们接受3-6个字符串中间的所有子单词,但不同的语言可能有不同的合适范围
$ ./fasttext skipgram -input data/fil9 -output result/fil9 -minn 2 -maxn 5 -dim 300
2、另外两个参数:epoch、learning rate
- epoch根据训练数据量的不同,可以进行更改,epoch参数即是控制训练时在数据集上循环的次数,默认情况下在数据集上循环5次,但当数据集非常大时,我们也可以适当减少训练的次数
- 另一个参数学习率,学习率越高模型收敛的速度就越快,但存在对数据集过度拟合的风险,默认值时0.05,这是一个很好的折中,当然在训练过程中,也可以对其进行调参,可调范围是[0.01, 1],下面命令便尝试对这两个参数进行调整:
$ ./fasttext skipgram -input data/fil9 -output result/fil9 -epoch 1 -lr 0.5
3、最后fastText是多线程的,默认情况下使用12个线程,如果你的机器只有更少的CPU核数,也可以通过如下参数对使用的CPU核数进行调整
$ ./fasttext skipgram -input data/fil9 -output result/fil9 -thread 4四、FastText词向量与word2vec对比
FastText= word2vec中 cbow + h-softmax的灵活使用
灵活体现在两个方面:
- 模型的输出层:word2vec的输出层,对应的是每一个term,计算某term的概率最大;而fasttext的输出层对应的是分类的label。不过不管输出层对应的是什么内容,其对应的vector都不会被保留和使用;
- 模型的输入层:word2vec的输入层,是 context window 内的term;而fasttext 对应的整个sentence的内容,包括term,也包括 n-gram的内容;
两者本质的不同,体现在 h-softmax的使用。
Word2vec的目的是得到词向量,该词向量 最终是在输入层得到,输出层对应的 h-softmax 也会生成一系列的向量,但最终都被抛弃,不会使用。
fasttext则充分利用了h-softmax的分类功能,遍历分类树的所有叶节点,找到概率最大的label(一个或者N个)。
五、常见问题
3、模型中使用单词短语而不是单个单词最佳方式是什么
目前使用单词短语或句子最好的方式是使用词向量的bow(bag of words),另一种方式例如New York,我们可以将其处理成New_York也会有帮助
4、为什么fastText甚至可以为语料库中未出现的单词产生词向量
fastText一个重要的特性便是有能力为任何单词产生词向量,即使是未出现的,组装的单词。主要是因为fastText是通过包含在单词中的子字符substring of character来构建单词的词向量,正文中也有论述,因此这种训练模型的方式使得fastText可以为拼写错误的单词或者连接组装的单词产生词向量
8、可以在连续的数据集上使用fastText吗
不可以,fastText仅仅是用于离散的数据集,因此无法直接在连续的数据集上使用,但是可以将连续的数据离散化后使用fastText
12、如何完全重现fastText的运行结果,为什么每次运行的结果都有些差异
当多次运行fastText时,因为优化算法异步随机梯度下降算法或Hogwild,所以每次得到的结果都会略有不同,如果想要fastText运行结果复现,则必须将参数thread设置为1,这样你就可以在每次运行时获得完成相同的性能