NLP预训练模型综述
现在深度学习越来越火了,在NLP领域主要使用CNNs、RNNs、GNNs以及attention机制。尽管这些模型取得了一些成绩,但是和CV相比,还是有些差距的,主要原因是大部分NLP任务的监督学习数据很少,而深度学习模型的参数有很多,需要大量的数据才可以学习好,否则就会发生过拟合现象,这就导致NLP模型一般都是1-3层的浅层神经网络。
近几年,预训练模型的出现在NLP领域起到里程牌的作用,NLP任务不需要从零开始训练模型了,直接在预训练模型上进行fine-tuning就可以取得很好的效果。第一代预训练模型会生成静态的词向量,以Word2Vec和Glove为代表,这种词向量可以捕捉词的语义信息,但是不能解决一词多义、语法结构、语义角色问题。第二代预训练模型是上下文词向量,例如CoVe、ELMo、GPT、BERT,这些预训练模型是根据不同的预训练任务来训练的,因此他们也就有他们适应的NLP任务,这个后面会详细讲解。
1、NLP通用的神经架构如图Figure 1:
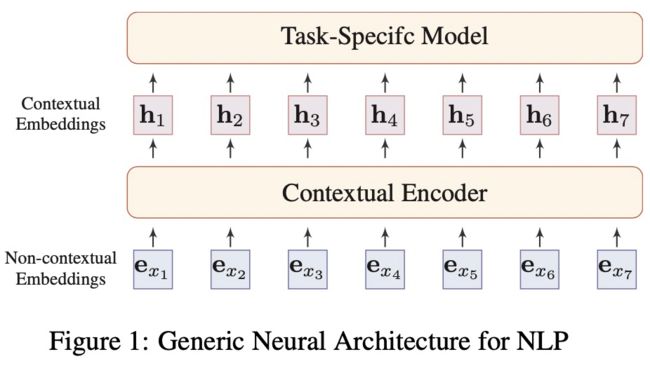
正如Bengio所说,一个好的词表示应该是可以表示隐藏在文本数据中的隐式语言规律和常识,与具体任务无关。
1.1、Non-contextual Embeddings
词表中的每个词都会通过lookup table E ∈ RDe×|V|来获取对应的词向量,但是这个词向量是静态的,除了刚才讲到的,不能处理一词多义问题,还有一个问题就是OOV,现在的解决办法是CharCNN、FastText和Byte-Pair Encoding (BPE)
1.2、Contextual Embeddings
每个词的表示都和输入的所有词相关,公式如下:
[h1,h2,···,hT]= fenc(x1,x2,···,xT)
主流的fenc(·)有如下几种形式:

2、预训练模型有哪些好处呢?
2.1、在大规模预料中训练可以学习到通用的语言表示;
2.2、可以提供一个更好的模型初始化,加速目标任务的收敛;
2.3、可以避免在小数据集上出现过拟合的情况
3、预训练模型的前世今生
3.1、第一代预训练模型Pre-trained Word Embeddings
第一代预训练模型主要是获得静态的词向量表示,代表模型有NNLM、Word2Vec、Glove,对应的论文如下:
NNLM:A neural probabilistic language model
Word2Vec:Distributed representations of words and phrases and their compositionality
Glove:GloVe: Global vectors for word representation
3.2、第二代预训练模型Pre-trained Contextual Encoders
第二代预训练模型主要获得和上下文相关的词向量表示,下面我以相关模型和对应论文的形式进行说明:
1)Dai and Le很早就使用语言模型或者序列编码器来初始化LSTM,并且用于文本分类任务,发现性能有提升。
paper:Semi-supervised sequence learning
2)Liu et al使用语言模型来预训练一个共享的LSTM编码器,并且在几个文本分类的多任务中进行fine-tuning,效果提升明显
paper:Recurrent neural network for text classification with multi-task learning
3)ELMo使用双向的LSTM来进行训练
paper:Deep contextualized word representations
4)ULMFiT (Universal Language Model Fine-tuning)是为文本分类任务提供的预训练模型,包括三个阶段:1、在通用的数据集上预训练语言模型;2、在目标数据集上Fine-tuning语言模型;3、在目标任务上进行Fine-tuning。
paper:Universal language model fine-tuning for text classification
5)OpenAI GPT (Generative Pre-training)
paper:Improving language understanding by generative pre-training. 2018.
URL:https://s3-us-west-2.amazonaws. com/openai-assets/researchcovers/languageunsupervised/languageunderstandingpaper.pdf
6)BERT (Bidirectional Encoder Representation from Transformer)
paper:BERT: pre-training of deep bidirectional trans- formers for language understanding
4、预训练模型的预训练任务
预训练任务对于预训练模型非常重要,这觉得了预训练模型会在什么下游任务表现的比较好,现在的预训练任务大致分为:监督学习、无监督学习、自监督学习三种。
现在自监督学习任务比较主流,他是监督学习和无监督学习的混合。自监督学习学习的范式和监督学习一样,但是他的label是从数据中自动生成的。Table 1总结了自监督学习的损失函数
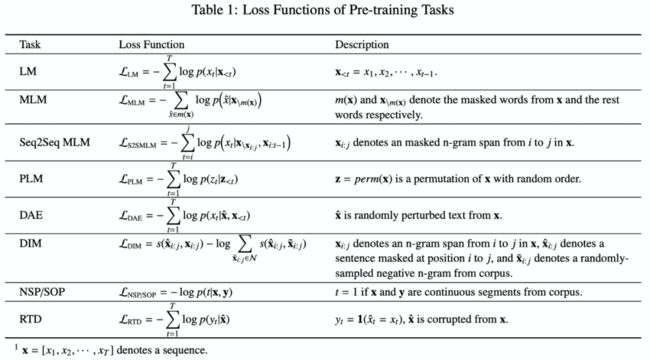
下面分别介绍一下这些损失函数
4.1、Language Modeling (LM)
语言模型就是评估给定语句出现的概率,公式如下:
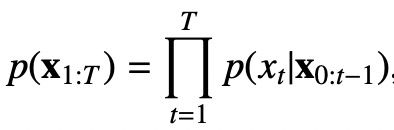
X0是一个句子的开始,p(xt|x0:t−1)通常是给定语言内容X0:t−1的一个概率分布,X0:t−1通常使用一个神经网络进行编码,公式如下:
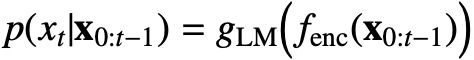
4.2、Masked Language Modeling (MLM)
MLM主要是解决传统LM只能单向,不能双向的问题。他会从输入句子中mask掉一些tokens,然后使用其他的tokens去预测这些mask tokens,但是这样有一个问题:真实的预测阶段是没有mask tokens的,这样在pre-training阶段和fine-tuning阶段就不匹配;为了解决这个问题,Devlin使用[MASK]特殊token来替换80%的mask tokens,剩下的10%使用随机tokens来替换,还有10%,则采用保留原来的tokens。
以上的MLM是把mask tokens当做分类问题去考虑的,其实如果把输入的非mask tokens作为神经网络的encoder,mask tokens作为神经网络的decoder,那么就是seq2seq MLM,这也是在MASS和T5中采用的方法。
除了上述对MLM的变种之外,还有其他的很多方法,比如,在RoBERTa采用了动态的mask策略;UniLM把LM的预测任务分为了unidirectional,bidirectional,和seq2seq预测;XLM使用了Translation Language Modeling(TLM);SpanBERT使用Random Contiguous Words Masking 和 Span Boundary Objective (SBO)去替换MLM来把结构化信息加入到预训练模型中;StructBERT把Span Order Recovery任务加入到语言结构中。
4.3、Permuted Language Modeling (PLM)
这种策略也是为了解决MLM引入[mask]tokens的问题,PLM是通过把原始输入句子中tokens顺序打乱后使用LM的方式实现双向LM的目的,XLNet采用的就是这种策略。
4.4、Denoising Autoencoder (DAE)
DAE是引入噪音的自编码器,部分打乱输入再恢复的过程。常用的方法有如下几种:
1)Token Masking:从输入中随机采样tokens,然后使用[MASK]来替换,原始BERT采用的方式模式;
2)Token Deletion:从输入中随机删除tokens,模型去预测删除的位置;
3)Text Infilling:类似SpanBERT一样,使用[MASK]替换文中的片段span,每个span的长度服从泊松分布(λ = 3),模型需要预测出每个span包含tokens的数量;
4)Sentence Permutation:把一个文档根据可以划分为句子的符合都划分为句子,然后随机打乱句子的顺序;
5)Document Rotation:以均匀分布随机选择一个token,旋转文档使得文档以这个被旋转的token为开始符合,模型去预测真正的开始符合。
4.5、Contrastive Learning (CTL)
对抗学习主要是学习文档中语义相似句子对,公式如下:
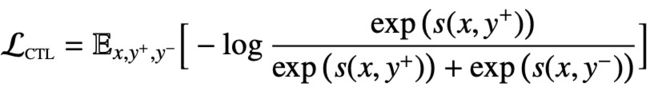
y+表示与x语义相似的句子,是正样本;y−表示与x语义不相似的句子,是负样本。s(x, y)一般都是神经网络,比如:s(x, y) = f T fenc(y) 或者s(x,y)= fenc(x⊕y)
下面介绍一下常用的CTL任务:
1)Replaced Token Detection(RTD)
RTD和NCE类似,去预测一个token是否被替换。CBOW-NS是一个RTD的简化版,他只是从词表中随机的采样一些负样本。ELECTRA是使用一个生成器来替换序列中的tokens,这是借助GAN网络的思想;分为两个过程:首先使用MLM任务训练生成器;然后使用生成器的权值初始化判别器,判别器的任务是判断产生的token是否是生成器生成,训练结束后,生成器被丢弃,下游任务只使用判别器。类似地、WKLM使用相同类似的实体去替换。
2)Next Sentence Prediction(NSP)
NSP是判断两句话是否在训练预料中是连续的,50%采用正确的连续句子,50%在预料中随机抽取句子作为负样本进行训练,这是BERT的采用的方式。然而Yang发现NSP这个任务其实作用不大,去掉了NSP,单句训练的损失反而比句子对的损失低,主要原因是NSP包括了话题任务和句子连贯性两个任务,而且负样本有可能来自预料中的不同文档,因为不同文档的话题一般不同,这样模型更容易依赖话题任务,而忽略了句子连贯性。
3)Sentence Order Prediction(SOP)
由于NSP有上述确定,ALBERT采用了SOP来实现句子连贯性,SOP是从一个文档中选择两个连续的句子作为正样本,把正样本的两个句子颠倒顺序作为负样本,效果比BERT好。
个人看法:从ALBERT的实验结果并不能看出是因为SOP这个任务比NSP好,因为ALBERT做了一些其他的改进,比如共享模型参数,减少词嵌入矩阵的大小等等。从原理上我觉得SOP应该比NSP好。
5、预训练模型的分类
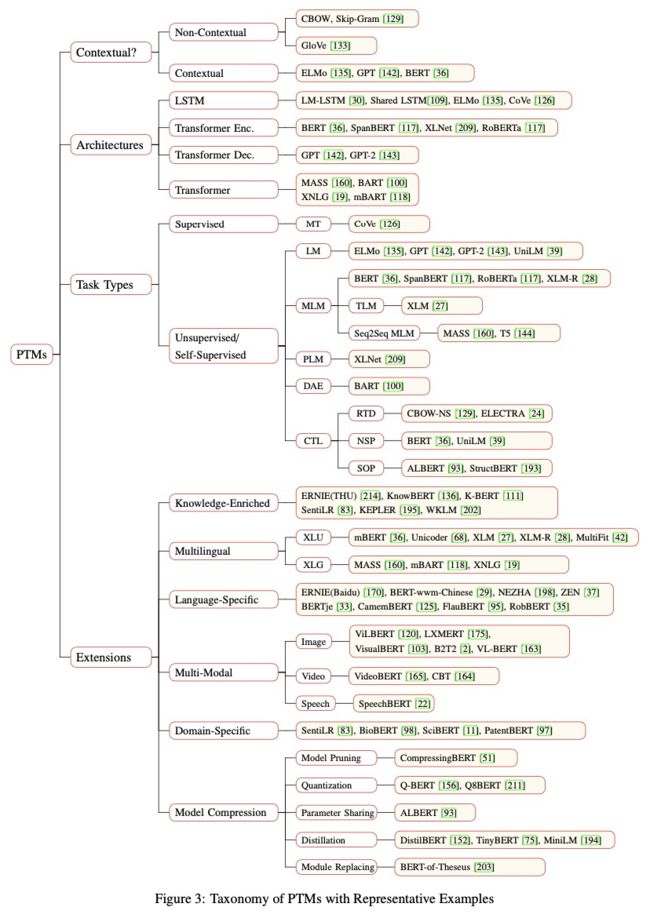
6、常用预训练模型的细节
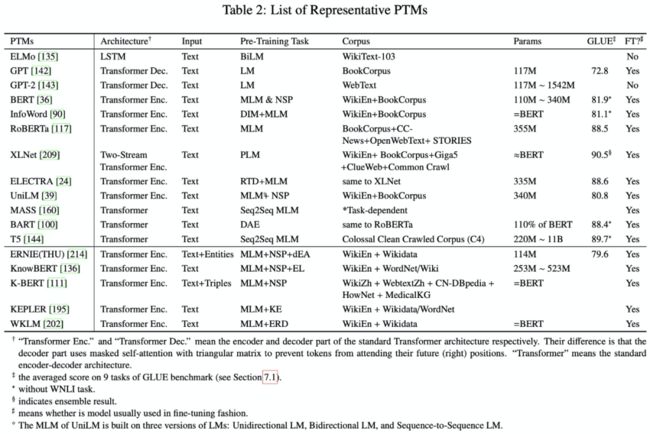
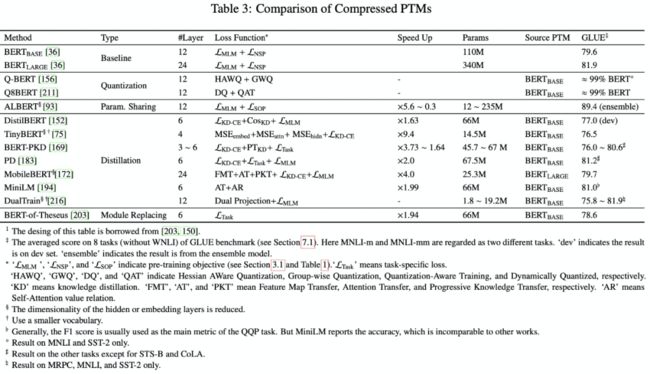
7、预训练模型压缩
最近的预训练模型至少都有百万级的参数量,由于资源限制和在线的响应速度,这些预训练很难直接部署上线,一般都需要进行压缩,常用的压缩方法有:模型剪枝、权重量化、参数共享、知识蒸馏、模块替换。
模型剪枝:移除少量的不重要的参数;
权重量化:使用更少的bits来替换参数;
参数共享:这个比较直观,就是不同模型直接参数要一样;
知识蒸馏:使用一个小的学生模型去学习原始模型的中间输出层;
模块替换:使用更小的替换品去替换原始模型的模块
1)Model Pruning
模型剪枝就是移除模型的权重、神经元、部分层、通道数、注意力头数,从而减少模型的大小,加快模型推理速度。
paper:Com- pressing BERT: Studying the effects of weight pruning on transfer learning
Are sixteen heads really better than one?
Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned
2)Quantization
权重量化就是降低模型的精度,比如从float32降低到float16
paper:Q8BERT: Quantized 8bit BERT
-
Q- BERT: Hessian based ultra low precision quantization of BERT
3)Parameter Sharing
CNN是比较早的使用参数共享,预训练ALBERT是参数共享的典型例子,ALBERT的参数大幅度减少,但是在训练和推理阶段并没有比标准的BERT快。一般认为,参数共享不能在推理阶段提高计算效率。
paper:ALBERT: A lite BERT for self-supervised learning of language representa- tions
4)Knowledge Distillation
知识蒸馏一般是从一个已经预训练好的模型中通过优化目标来训练一个小的学生模型,目的是找到一个比较稀疏的架构。常用的知识蒸馏方法有:
distillation from soft target probabilities、distillation from other knowledge 和 distillation to other structures
(1) Distillation from soft target probabilities
Bucilua提出让学生模型尽量逼近老师模型的logit,把老师模型当做黑箱子,比如DistilBERT模型,其损失函数公式如下:
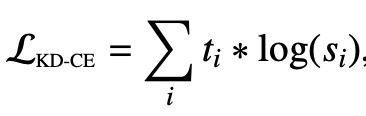
paper:DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
(2) Distillation from other knowledge
Distillation from soft target probabilities方式只是考虑了老师模型的输出层,如果考虑更多层,也会提高学生模型的性能。
TinyBERT考虑了层到层的蒸馏,涉及到embedding 输出层、隐藏层、自注意力分布。
paper:TinyBERT: Distilling BERT for natural language understanding
MobileBERT考虑了层到层的蒸馏,涉及到目标模型的概率(与Distillation from soft target probabilities)类似、隐藏层、自注意力分布。
paper:MobileBERT: a compact task- agnostic BERT for resource-limited devices
MiniLM在自注意力分布和自注意力值关系蒸馏
paper:MiniLM: Deep self-attention distillation for task-agnostic compression of pre-trained transformers
(3) Distillation to other structures
一般的蒸馏方式,学生模型和老师模型是一样的,只是层数和隐藏层大小变少了,其实还可以使用CNN或者RNN来替换Transformer
5)Module Replacing
模块替换是使用小模块替换原始预训练模型的大模块,这个比较好理解。在引出论文之前,要说明一下Ship of Theseus问题,假如老部件每一次被替换之后,都重新用于建造一艘新的船。到了最后,旧船的部件被完全替换,而新船的部件完全使用了旧船的原部件。最终,这艘「新船」没有一处不来自原来的忒修斯船,而旧船在物质上则已经变成不同的样貌。所以后续问题为:「新船」还是「旧船」才是「忒修斯船」?这就是忒修斯悖论。
Xu受到忒修斯悖论启示,提出了悖论压缩,使用更少参数的模块来替换原始模型的对应模块,速度提高了1.94倍,性能是原始模型的98%
8、预训练模型应用下游任务
尽管预训练任务可以从大规模语料中获得通用的语言知识,但是这些知识表示在下游任务中的效果仍然是一个大的话题,现在从迁移学习和fine-tuning两个角度去分析一下:
8.1、迁移学习:
迁移学习是为了从原任务中获得到知识,应用到目标任务,结构如下图:
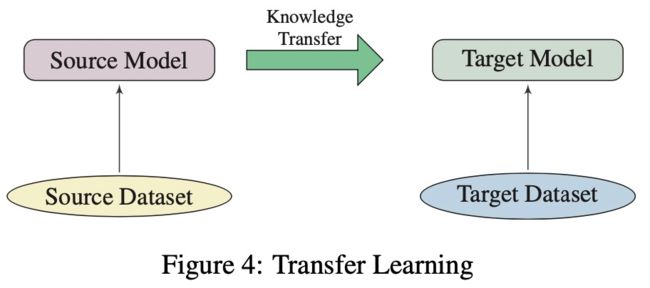
在NLP领域,一般有如下几种迁移学习方式:域适应、跨语言学习、多任务学习。把预训练模型应用到下游任务是序列迁移任务,任务被顺序的学习,而且目标任务有label数据。
那么具体如何进行迁移学习呢?有哪些注意的地方呢?
1)选择合适的预训练任务、模型架构和语料
比如NSP任务可以使得预训练模型理解两个句子间的关系,那么这些预训练就会更适应Question Answering (QA) and Natural Language Inference (NLI)。
在模型方面,比如BERT在很多任务上表现出众,但是不适合在生成任务
当然目标任务的语料和预训练语料越接近越好,和机器学习的训练集和测试集的原理一样。
2)选择合适的模型层
对于预训练模型,不同的层包含不同的信息,例如词性标注、句法解析、长依赖、语义角色、指代消解。
对于基于RNN的模型,Belinkov和Melamud的论文指出:对于不同的任务,多层LSTM编码器不同层可以学习到不同的表示,比如词性和词义。对于基于Transformer的预训练模型,Tenney发现BERT模型可以表示传统NLP的pipeline,浅层表示句法信息,深层表示语义信息。一般来说,选择预训练模型有如下三种方式:一、只选择预训练模型的静态embedding信息,任务模型从零开始训练;二、把预训练模型的最后一层表示直接加入到任务模型中,比如直接在BERT模型CLS的输出上做文本分类;三、自动选择模型最好的层,比如ELMo,对每一层进行加权求和,公式如下:
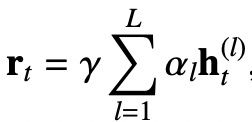
其中αl是softmax归一化权重,求和表示所有层进行加权求和,γ是标量
3)如何选择是否tune
目前模型迁移的两种方式是feature extraction(预训练模型的参数不变)和fine-tuning(预训练模型的参数需要变)两个模式。特征抽取方式一般需要更复杂的架构,所以fine-tuning方式更普遍一些,具体到预训练模型,可以参考如下表
8.2、Fine-tuning策略:
1)两阶段fine-tuning
第一个阶段预训练模型通过中间任务或者预料来fine-tuned,第二阶段在目标任务上进行fine-tuned。
Sun表明在与目标相关的预料上进行fine-tuned后,BERT的性能在8个文本分类的任务上达到SOTA
paper:How to fine-tune BERT for text classification?
Phang和Garg介绍使用与目标任务相关的中间任务进行fine-tuned后,在BERT、GPT、ELMo上都有提升。
paper:Story ending predic- tion by transferable bert
Li使用两阶段做故事结尾预测,发现TransBERT不仅可以从大规模的无监督数据中学习到通用的语言知识,而且也可以从不同的监督任务中学习到不同的语义知识。
2)多任务fine-tuning
Liu发现BERT在多任务和预训练是互补的
paper:Multi-task deep neural networks for natural language understanding
3)加入调整模块进行fine-tuning
fine-tuning的主要缺点是参数的利用率低,因为都调整了,另一个方案是原始的预训练模型参数不变,然后加入和目标任务相关的模块。
Houlsby在BERT的基础上增加了一个调节模块,是一个扩展的模块,每个新任务只需要增加少量的训练参数就可以了,原始预训练模型的参数固定,模型顶层的参数共享即可。
paper:Parameter-efficient transfer learning for NLP
最后送上福利