人脸目标检测的多任务级联神经网络MTCNN在Pytorch中的实现
MTCNN网络
这两周下班花了很多时间理解MTCNN网络,从综述到博客,再到代码和原论文,最终又回过去看代码和博客,总算把MTCNN的数据前处理,结构和内部的一些算法搞清楚了。总的来说,个人认为MTCNN难点主要在第一阶段,包括训练数据的前处理,测试数据的输入等。
文章主要参考了:http://www.sfinst.com/?p=1683
https://www.cnblogs.com/the-home-of-123/p/9857056.html
https://blog.csdn.net/autocyz/article/details/82799529
https://zhuanlan.zhihu.com/p/31761796
级联神经网络从一个小网络开始,逐层训练,最终形成一个多层的结构。MTCNN是多任务级联CNN的人脸检测深度学习模型,该模型不仅考虑了人脸检测概率,还综合训练了人脸边框回归和面部关键点检测,多任务同时建立loss function并训练,因此为MTCNN。
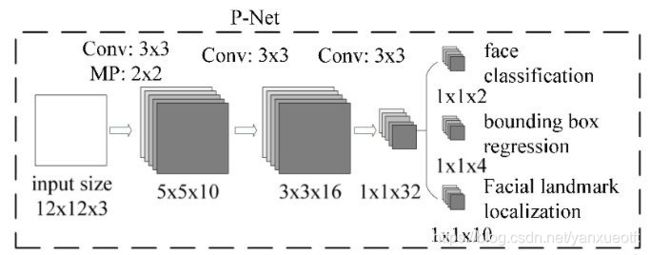
MTCNN的网络结构主要包括P-NET,R-NET和O-NET(Proposal Network, Refinement Network和 Output Network),运算量最大的是Pnet,耗时也最多。各层级网络结构如下:

Pnet输入是12123尺寸的图片,用来获取面部分类概率,面部窗口和相应的候选框的回归向量。然后采用非极大值抑制方法non-maximum suppression(NMs)对生成的面部候选框进行合并操作。

RNET对PNET输出的面部候选框进一步训练矫正人脸候选框的回归向量,并同样对候选框执行非极大值抑制

ONet是最后的输出网络,生成最终的人脸识别概率,人脸回归框以及面部关键点。
MTCNN训练和预测的关键点包括输入数据的前处理,Bounding Box的生成,交并比的计算,非极大值抑制,回归框偏移量等。
数据前处理
PNET输入的训练数据是12123的图片,对图片进行预处理是训练的第一步。MTCNN原文作者训练的数据主要来源WIDER FACE数据集以及对应的annotation,可从如下地址下载:http://mmlab.ie.cuhk.edu.hk/projects/WIDERFace/
数据集包括训练集,验证集合测试集,并且annotation中均被标记人脸框(Guarant True Box),annotation格式如下:
0–Parade/0_Parade_marchingband_1_849.jpg 448 329 570 478
*.jpg为图片命名,后四个数字为人脸框的左上角和右下角坐标,如果不止一个人脸框,则数字会继续在后面append。如下代码可以把上面这幅图以及人脸框画出来:

import cv2
from dface.core.detect import create_mtcnn_net, MtcnnDetector
import dface.core.vision as vision
import matplotlib.pyplot as plt
import pylab
img = cv2.imread("0_Parade_Parade_0_904.jpg")
annotation = [360, 97, 623, 436 ]
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
figure = pylab.figure()
# plt.subplot(121)
pylab.imshow(img_rgb)
figure.suptitle('DFace Detector', fontsize=20)
rect = pylab.Rectangle((annotation[0], annotation[1]),
annotation[2] - annotation[0],
annotation[3] - annotation[1], fill=False,
edgecolor='yellow', linewidth=0.9)
pylab.gca().add_patch(rect)
pylab.show()
对数据集中的每张照片进行大于1212尺寸的随机裁剪,并根据不同的交并比(IOU)将裁剪后的图片归类到不同类别中并标注,主要分为三个类别,分别是负样本,正样本,部分人脸样本:
1 Negatives: IOU < 0.3
2 Positives: IOU > 0.65
3 Part faces: 0.4 < IOU < 0.65。
训练数据由四部分组成:pos,part,neg,landmark,比例为1:1:3:1
首先对图片随机裁剪并缩减到1212的尺寸,方法:
import cv2
import numpy as np
import numpy.random as npr
from PIL import Image, ImageDraw
from pylab import *
img = cv2.imread("0_Parade_Parade_0_904.jpg")
height, width, channel = img.shape
size = npr.randint(12, min(width, height) / 2)
#top_left
nx = npr.randint(0, width - size)
ny = npr.randint(0, height - size)
#random crop
crop_box = np.array([nx, ny, nx + size, ny + size])
cropped_im = img[ny : ny + size, nx : nx + size, :]
resized_im = cv2.resize(cropped_im, (12, 12), interpolation=cv2.INTER_LINEAR)
#cv2.imwrite("resize.jpeg", resized_im)
imshow(cropped_im)
imshow(resized_im)
show()
裁剪后未缩放与缩放的图片如下:
对裁剪的图像计算IOU并分类,IOU(Intersection-Over-Union)的计算流程如下:
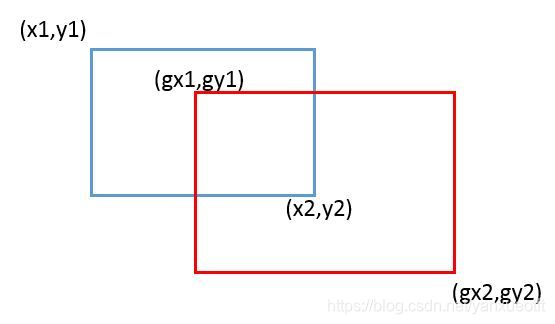
蓝色的框为生成的滑动窗口,红色的框为Guarant Box,其中(x, y)表示回归框的顶点坐标。IOU为两个框相交的面积除以两个框的总面积,如果IOU越大表示生成的滑动窗口和真实的窗口越接近。这样IOU的计算公式可以表示为:
IOU=((x2-gx1)(y2-gy1))/(((x2-x1)(y2-y1)+(gx2-gx1)(gy2-gy1))-((x2-gx1)(y2-gy1)))
def IoU(box, boxes):
box_area = (box[2] - box[0] + 1) * (box[3] - box[1] + 1)
area = (boxes[:, 2] - boxes[:, 0] + 1) * (boxes[:, 3] - boxes[:, 1] + 1)
xx1 = np.maximum(box[0], boxes[:, 0])
yy1 = np.maximum(box[1], boxes[:, 1])
xx2 = np.minimum(box[2], boxes[:, 2])
yy2 = np.minimum(box[3], boxes[:, 3])
# compute the width and height of the bounding box
w = np.maximum(0, xx2 - xx1 + 1)
h = np.maximum(0, yy2 - yy1 + 1)
inter = w * h
ovr = inter / (box_area + area - inter)
return ovr
其中box为滑动窗口,boxes为多个guarant box(一个图片可以有多个人脸,所以会有多个guarant box)。
利用Bounding Box Regression算法算出其相对于原图脸框的offset值并记录下来,考虑到直接采用坐标信息进行回归框的预测,网络收敛比较慢。所以在回归框预测的时候一般采用回归框的坐标偏移进行预测,相当于归一化的一种方式。回归框的坐标偏移如下图所示:

生成裁剪图片后,对应滑动窗口和Guarant True Box的偏移值,即可算出来,如下所示:
offset_x1 = (gx1 - x1) / float(x2-x1)
offset_y1 = (gy1 - y1) / float(y2-y1)
offset_x2 = (gx2 - x2) / float(x2-x1)
offset_y2 = (gy2 - y2) / float(y2-y1)
这样生成裁剪图片的时候,对正样本及中间样本,同时保存相应的offset值,如下所示:
positive/0.jpg 1 0.02 -0.01 -0.20 -0.06
positive/1.jpg 1 0.08 0.04 -0.18 -0.06
positive/2.jpg 1 0.16 0.10 -0.03 0.09
positive/3.jpg 1 0.00 -0.04 0.08 0.28
positive/4.jpg 1 0.08 0.03 -0.12 0.01
总结:训练图片包含各种尺寸,每张图片也可能包含多张脸框。训练数据的前处理主要对每张图片基于标记好的人脸框随机生成不同尺寸和位置的人脸框,并裁剪成图片后缩放到12*12的尺寸喂给Pnet训练,训练的目标就是图片含人脸的概率,人脸框的回归以及面部关键点的回归。
MTCNN网络的训练
训练中需要最小化的损失函数来自3方面:
face/non-face classification + bounding box regression + facial landmark localization
1 face classification
对于每个样本xi,计算交叉熵损失函数:
![]()
不过后面的(1 - log(pi))好像应该是log(1 - pi)。pi是网络预测的xi是人脸的概率;yi当然就是xi的标签了,0或1。那么这个交叉熵损失函数表达的就是“预测的是人脸的概率”与“事实到底是不是人脸”的接近程度,越接近,熵越小,损失越小。那么目标也就是min(Li)
2 bounding box regression
对于每个样本xi,计算欧氏距离:
![]()
y是(左上角x, 左上角y, 高度, 宽度)组成的四元组。第一个yi是预测的,第二个yi是真实的。预测的bounding box与真实的越接近,欧氏距离越小。目标是min(Li)
3 facial landmark localization
对于每个样本xi,计算欧氏距离:
![]()
y是(左眼x, y, 右眼x, y, 鼻子x, y, 左嘴角x, y, 右嘴角x, y)的十元组。第一个yi是预测的,第二个yi是真实的。预测的landmarks位置与真实的越接近,欧氏距离越小。目标是min(Li)
合起来就是:

MTCNN网络的测试
与训练不同MTCNN测试图片对图片的尺寸没有要求,任何尺寸都可以输入到训练好的PNET中。将原图进行缩放生成一系列不同尺寸的图像金字塔,最小尺寸到预先定义好的minsize,原文取得minsize=20。生成图像金字塔的目的主要是因为输入图像中的人脸大小不确定,可能很大也可能很小,这样对原图进行缩放可以使的图中不同的人脸总有合适的尺寸适合PNET运算,毕竟PNET是基于1212的图片训练出来的。
这边有个需要注意的是为什么不同scale尺寸的图片都可以输入到PNET中,是因为PNET是一个全卷积结构,没有全连接层,因此PNET输出的也是特征图而不是特征向量。另外原文中的PNET的图有些误导人,训练的是有是12123的输入,1132的输出,但是这里的1212输入只是一个示意,实际测试的时候输入任意尺寸的图片矩阵经过Pnet后可以看做经历了一个完整的卷积(卷积核=1212,stride=2),输出并不是1132。例如如果输入是48483的图片矩阵,经过Pnet后输出为191932了,并且1919中每个二维点对应到原图中都是一个1212的视野区域,可以理解为对原图进行了卷积的滑动并分别计算每个1212窗口的人脸概率以及框回归。
经过PNET后根据设定的人脸概率阈值face classfication选出可能含有人脸的图,映射还原到没有scale的图中,得到候选区域并预测出回归框(boudingbox regression)提取出来,经过NMS算法进一步筛选后resize成24*24的图片输入到Rnet中。Onet与Rnet的输入操作类似,ONET同时会输出Facial landmark localization。
下面是整个系统的工作流图
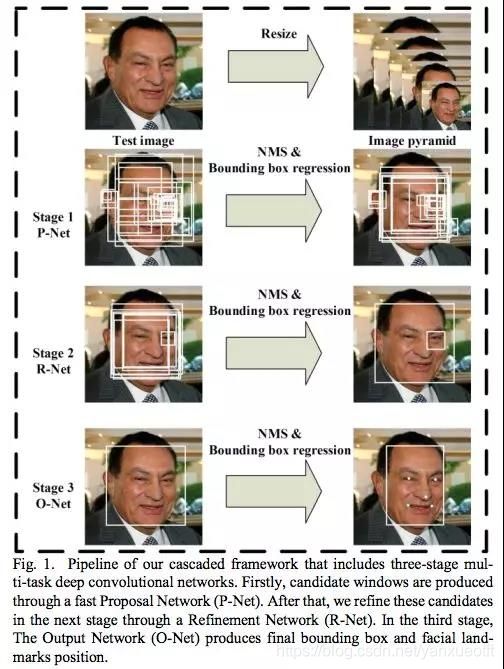
算法实现的是有后两个有意思的注意点:
- 实际计算的时候是将255的RGB图像归一化到了-1,1的区间,归一化操作,加快收敛速度。由于图片每个像素点上是[0, 255]的数,都是非负数,对每个像素点做(x – 127.5)/128,可以把[0, 255]映射为(-1, 1)。具体的理论原因可以自行搜索,但实践中发现,有正有负的输入,收敛速度更快。训练时候输入的图片需要先做这样的预处理,推断的时候也需要做这样的预处理才行。
- NMS非极大值抑制算法非极大值抑制:Non-Maximum Suppression, NMS
参考:非极大值抑制(Non-Maximum Suppression,NMS)
比如在下图中,假设5个框是人脸的概率由高到低排序为ABCDE。对于A,检查BCDE中是否有与A的IOU(交并比)>阈值的(如BD,说明BD与A重复区域很多),那就删掉BD,A保留;继续对于C,重复上述步骤。最后留下的框就是NMS后的结果。(具体参考https://www.jianshu.com/p/2f749b07e09f)

测试时各个网络的耗时
虽然PNET最简单,ONET最复杂,但是由于PNET设计到大量的裁剪原图,计算时间反而最长,从本机的测试结果来看,一张96012803的图片,pnet 1.032s rnet 0.250s onet 0.047s.
另外其实运算的效率可以进一步提升,比如优化minsize可以直接减少图像金字塔的裁剪,降低计算时间。
这段http://www.sfinst.com/?p=1683做了很详细的讲解。
总结
个人觉得第一部分的理解是至关重要的,尤其是训练图片的输出和输入图片的裁剪,这些理解了其实其他的网路结构以及cost function反而是相对来说水到渠成。TCNN推断流程的第一阶段,蕴含了许多CNN的技巧,个人认为是比较精华也具有启发性的部分。并且MTCNN的推断过程中,第一阶段时间消耗占80%左右,所以如果需要优化和理解MTCNN的读者,在第一阶段投入再多精力都不为过
。
下一步做人脸识别主要依赖于图片中人脸的检测,人脸的检测作准了人脸识别的特征提取才能进行。一般是将裁剪出的图像对齐后输入到网络中,一般为Inception网络, 得到输出向量。
源码实现
源码借用的Dface中的MTCNN,感谢作者的实现!https://github.com/kuaikuaikim/DFace/blob/master/README_zh.md
注意的是有一处BUG需要修复,dface/core/image_tools.py中第19行 image = image.astype(np.float32)这行删除掉,否则会报以下错误:Expected object of type torch.DoubleTensor but found type torch.FloatTensor for argument #2 ‘weight’