这个系列是把《机器学习实践》书上的项目,以自己理解的形式梳理一遍,算是对自己学习过程的总结。
0.项目介绍
书中第一个项目,内容包括获取数据、数据可视化、分析数据、切分数据集、数据清理、流水线过程、选择和训练模型,走了一遍做一个完整的机器学习模型的大致流程。
1.数据查看及分析
数据加载:
下面代码中有两个函数,fetch_housing_data是自动下载网络文件并存放在本地中,load_housing_data是获取文件数据。
import os
import tarfile
from six.moves import urllib
import pandas as pd
DOWNLOAD_ROOT = "https://raw.githubusercontent.com/ageron/handson-ml/master/"
HOUSING_PATH = "datasets/housing"
HOUSING_URL = DOWNLOAD_ROOT + HOUSING_PATH + "/housing.tgz"
def fetch_housing_data(housing_url=HOUSING_URL, housing_path=HOUSING_PATH):
if not os.path.isdir(housing_path):
os.makedirs(housing_path)
tgz_path = os.path.join(housing_path, "housing.tgz")
urllib.request.urlretrieve(housing_url, tgz_path)
housing_tgz = tarfile.open(tgz_path)
housing_tgz.extractall(path=housing_path)
housing_tgz.close()
def load_housing_data(housing_path=HOUSING_PATH):
csv_path = os.path.join(housing_path,"housing.csv")
return pd.read_csv(csv_path)
数据查看:
housing = load_housing_data() #housing是pandas的DataFrame数据类型
housing.head() # 查看数据前5行
housing.info() # 查看数据的整体基本信息
housing['ocean_proximity'].value_counts() # 查看单一列的统计信息
housing.describe() #查看包括std(标准差)、mean、max、min、不同比例值的信息,如下图

数据的描述信息
切分数据:
要把数据切分成train_set(训练集)和test_set(测试集),有两种方式:随机切分、按层级切分。随机切分效果不好,一般是按层级切分,尽量保证测试集适应数据的特点。
随机切分(不推荐):
import numpy as np
import hashlib
# 1、手动划分数据集-纯随机方式
# 通过每一行数据的唯一标识id,取hash值,取hash值的最后一位是在0~255的值,如果它在256*测试比例大小内,那标记为True,即为测试集中的数据
def test_set_check(identifier,test_ratio,hash):
return hash(np.int64(identifier)).digest()[-1] < 256 * test_ratio
def split_train_test_by_id(data, test_ratio, id_column, hash=hashlib.md5):
ids = data[id_column]
in_test_set = ids.apply(lambda id_: test_set_check(id_,test_ratio,hash))
return data.loc[~in_test_set], data.loc[in_test_set]
housing_with_id = housing.reset_index()
train_set,test_set = split_train_test_by_id(housing_with_id, 0.2, "index")
# 2、使用Scikit-Learn来划分数据集-纯随机方式
from sklearn.model_selection import train_test_split
train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42)
按层级切分(推荐):
# 3、将数据集进行分层抽取测试集和训练集,依据的标准是收入平均数,因为预测房价,收入中位数是个非常关键的属性。
# i:数据分析:从收入图上来看,数据集中在2~5之间,如果要按层级抽样,那每一个层级应该足够大最好。
# 书上是这样处理的,先把收入/1.5(限制类别的数量),并且取整,再把大于5的数据归到5的层级中。
housing['income_cat'] = np.ceil(housing['median_income'] / 1.5)
housing['income_cat'].where(housing['income_cat'] < 5, 5.0, inplace=True)
# 4、进行分层抽样
from sklearn.model_selection import StratifiedShuffleSplit
split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)
for train_index, test_index in split.split(housing, housing['income_cat']):
print(len(train_index))
print(len(test_index))
strat_train_set = housing.loc[train_index]
strat_test_set = housing.loc[test_index]
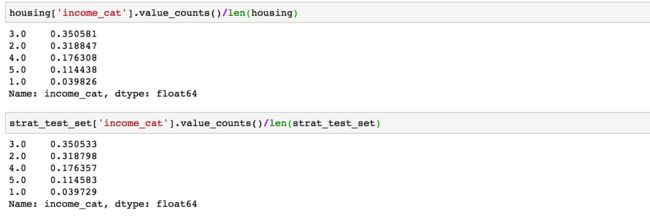
完整数据集和测试集的分布概率
数据可视化:
- 把所有列按直方图形式查看:
%matplotlib inline
import matplotlib.pyplot as plt
housing.hist(bins=50,figsize=(20,25))
plt.show
#把所有列以直方图形式显示
- 将地理数据可视化
#1.将地理数据可视化
housing = strat_train_set.copy()
housing.plot(kind='scatter',x='longitude',y='latitude', alpha=0.4,
s=housing['population']/100, label='population',
c='median_house_value',cmap=plt.get_cmap('jet'), colorbar=True)
plt.legend()

地理数据可视化
数据探索
- 寻找数据属性间的相关性,又称皮尔逊相关性
# 查看所有属性跟房价中位数的相关性,范围-1~1,负数代表负相关
corr_matrix = housing.corr()
corr_matrix['median_house_value'].sort_values(ascending=False)

属性跟房价中位数的相关性
- 尝试不同的属性组合
#尝试不同属性的组合
housing['rooms_per_household'] = housing['total_rooms']/housing['households']
housing['bedrooms_per_room'] = housing['total_bedrooms']/housing['total_rooms']
housing['population_per_household'] = housing['population']/housing['households']
corr_matrix = housing.corr()
corr_matrix['median_house_value'].sort_values(ascending=False)
#可以看到bedrooms_per_room比total_rooms和total_bedrooms的系数都高的多。
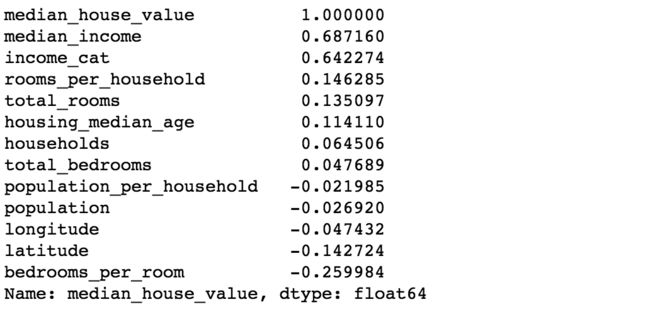
属性组合的相关性
2、机器学习算法的数据准备
这一部分最好要用函数,甚至流水线程序来执行,方便之后的项目重用。
housing = strat_train_set.drop('median_house_value', axis=1)
housing_labels = strat_train_set['median_house_value'].copy()
处理数据缺失
数据中当出现某些值缺失时,要考虑将其填充成平均值或者直接舍弃。
# 丢弃有三种方式:
# housing.dropna(subset=['total_bedrooms'])
# housing.drop('total_bedrooms', axis=1)
# median = housing['total_bedrooms'].median()
# housing['total_bedrooms'].fillna(median)
# 填充一般是按中位数填充
from sklearn.preprocessing import Imputer
imputer = Imputer(strategy='median')
housing_num = housing.drop('ocean_proximity', axis=1)
imputer.fit(housing_num)
# imputer.statistics_
# housing_num.median().values
X = imputer.transform(housing_num)
housing_tr = pd.DataFrame(X, columns=housing_num.columns)
处理文本和分类属性
有些属性的值不是数字,这时候最好把文本值转换成数字,方便之后的处理
from sklearn.preprocessing import LabelEncoder
encoder = LabelEncoder() #转换器
housing_cat = housing['ocean_proximity']
housing_cat_encoded = encoder.fit_transform(housing_cat)
housing_cat_encoded
所有转换后的数值
#查看所有类型
print(encoder.classes_)
转换钱的所有文本值类型
OneHot编码
如果只是把数据转换成0,1,2...这种连续的数字,机器学习算法会默认0和4的距离比2和3的距离要远,但在文本类型中不存在这种关系,所以要转成01编码,以10000,01000,00100...的这种方式,即为OneHot编码。最终为二维数组
from sklearn.preprocessing import OneHotEncoder
oneHotEncoder = OneHotEncoder()
housing_cat_1hot = oneHotEncoder.fit_transform(housing_cat_encoded.reshape(-1,1))
housing_cat_1hot.toarray()
可以一次性转换成OneHot形式:
from sklearn.preprocessing import LabelBinarizer
encoder = LabelBinarizer()
housing_cat_1hot = encoder.fit_transform(housing_cat)
特征缩放
两种方式:最小最大值缩放和标准化。
标准化受数据异常值的影响较小。
可以自定义转换器
scikit-learn中,可以创建自定义转换器,只要类中应用这三个方法:fit()、transform()、fit_transform()。如下代码:
#自定义转换器
from sklearn.base import BaseEstimator, TransformerMixin
rooms_ix, bedroom_ix, population_ix, household_ix = 3,4,5,6
class CombinedAttributesAdder(BaseEstimator, TransformerMixin):
def __init__(self, add_bedrooms_per_room = True):
self.add_bedrooms_per_room = add_bedrooms_per_room
def fit(self, X, y=None):
return self
def transform(self, X, y=None):
rooms_per_household = X[:, rooms_ix] / X[:, household_ix]
population_per_household = X[:, population_ix] / X[:, household_ix]
if self.add_bedrooms_per_room:
bedrooms_per_room = X[:, bedroom_ix] / X[:, rooms_ix]
return np.c_[X, rooms_per_household, population_per_household, bedrooms_per_room]
else:
return np.c_[X, rooms_per_household, population_per_household]
attr_adder = CombinedAttributesAdder(add_bedrooms_per_room=False) #为了将准备步骤更自动化,添加这个属性Flag
housing_extra_attribs = attr_adder.transform(housing.values)
class DataFrameSelector(BaseEstimator, TransformerMixin):
def __init__(self, attribute_names):
self.attribute_names = attribute_names
def fit(self, X, y=None):
return self
def transform(self, X):
return X[self.attribute_names].values
转换流水线
可以用流水线的方式来顺序执行数据处理步骤。
from sklearn.pipeline import FeatureUnion
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
num_attribs = list(housing_num)
cat_attribs = ['ocean_proximity']
num_pipeline = Pipeline([
('selector', DataFrameSelector(num_attribs)),
('imputer', Imputer(strategy='median')),
('attribs_adder', CombinedAttributesAdder()),
('std_scaler', StandardScaler())
])
cat_pipeline = Pipeline([
('selector', DataFrameSelector(cat_attribs)),
('label_binarizer', LabelBinarizer())
])
full_pipeline = FeatureUnion(transformer_list=[
('num_pipeline', num_pipeline),
('cat_pipeline', cat_pipeline)
])
housing_prepared = full_pipeline.fit_transform(housing)
housing_prepared.shape