Murmurhash-go源码阅读
源码地址:
https://github.com/spaolacci/murmur3
如何理解它说的原生go实现:底层实现不依赖c和c++的库,只用go的标准库实现。
分析一下TestRefStrings中的对于128位的murmur3算法进行分析
// New128WithSeed returns a 128-bit hasher set with explicit seed value
func New128WithSeed(seed uint32) Hash128 {
d := new(digest128)
d.seed = seed
d.bmixer = d // 这里有点奇怪
d.Reset()
return d
}
type digest128 struct {
digest
h1 uint64 // Unfinalized running hash part 1.
h2 uint64 // Unfinalized running hash part 2.
}
type digest struct {
clen int // Digested input cumulative length.
tail []byte // 0 to Size()-1 bytes view of `buf'.
buf [16]byte // Expected (but not required) to be Size() large.
seed uint32 // Seed for initializing the hash.
bmixer
}
// 另外digest重写了bmixer的函数,先省略,等用的时候看。
type bmixer interface {
bmix(p []byte) (tail []byte)
Size() (n int)
reset()
}
type Hash128 interface {
hash.Hash
Sum128() (uint64, uint64)
}
看下这一段代码,很有意思,用var来保证digest128实现了所有的方法。
// Make sure interfaces are correctly implemented.
var (
_ hash.Hash = new(digest128)
_ Hash128 = new(digest128)
_ bmixer = new(digest128)
)
可以看到我们创建一个hasher,type=interface, 然后实现了各种各样的function。
关于
d.bmixer = d
这一行代码,这么写,猜测只是用来实现bmixer的方法。方便digest128 重写一系列函数。
murmur128.go
func (d *digest128) bmix(p []byte) (tail []byte) {
//...
}
//等
总之,我们现在new得到了一个hasher,并且做了一些初始化工作:
func (d *digest) Reset() {
d.clen = 0
d.tail = nil
d.bmixer.reset()
}
func (d *digest128) reset() {
d.h1, d.h2 = uint64(d.seed), uint64(d.seed)
}
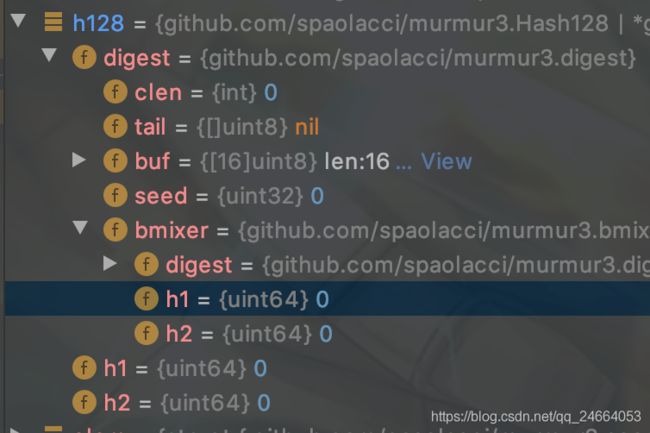
这里可以看到digest中bmixer里面的digest指针指向的就是digest本身。。。这是个俄罗斯套娃。
接着把需要hash的string写进去:
h128.Write([]byte(elem.s))
更新了digest中的buf、tail、clen等内容。然后就进行hash
v1, v2 := h128.Sum128()
func (d *digest128) Sum128() (h1, h2 uint64) {
h1, h2 = d.h1, d.h2
var k1, k2 uint64
switch len(d.tail) & 15 {
case 15:
k2 ^= uint64(d.tail[14]) << 48
fallthrough
case 14:
k2 ^= uint64(d.tail[13]) << 40
fallthrough
case 13:
k2 ^= uint64(d.tail[12]) << 32
fallthrough
case 12:
k2 ^= uint64(d.tail[11]) << 24
fallthrough
case 11:
k2 ^= uint64(d.tail[10]) << 16
fallthrough
case 10:
k2 ^= uint64(d.tail[9]) << 8
fallthrough
case 9:
k2 ^= uint64(d.tail[8]) << 0
k2 *= c2_128
k2 = bits.RotateLeft64(k2, 33)
k2 *= c1_128
h2 ^= k2
fallthrough
case 8:
k1 ^= uint64(d.tail[7]) << 56
fallthrough
case 7:
k1 ^= uint64(d.tail[6]) << 48
fallthrough
case 6:
k1 ^= uint64(d.tail[5]) << 40
fallthrough
case 5:
k1 ^= uint64(d.tail[4]) << 32
fallthrough
case 4:
k1 ^= uint64(d.tail[3]) << 24
fallthrough
case 3:
k1 ^= uint64(d.tail[2]) << 16
fallthrough
case 2:
k1 ^= uint64(d.tail[1]) << 8
fallthrough
case 1:
k1 ^= uint64(d.tail[0]) << 0
k1 *= c1_128
k1 = bits.RotateLeft64(k1, 31)
k1 *= c2_128
h1 ^= k1
}
h1 ^= uint64(d.clen)
h2 ^= uint64(d.clen)
h1 += h2
h2 += h1
h1 = fmix64(h1)
h2 = fmix64(h2)
h1 += h2
h2 += h1
return h1, h2
}
func fmix64(k uint64) uint64 {
k ^= k >> 33
k *= 0xff51afd7ed558ccd
k ^= k >> 33
k *= 0xc4ceb9fe1a85ec53
k ^= k >> 33
return k
}
golang 里面的switch case 满足其中一条分支的话会选择其分支执行,执行完毕会自动break,但fallthrough指令会强制执行下一个分支。
注意位运算的^和&
算法思路:
1 拿string的len & 15, 其实就是对16取膜运算。
拿前7位分别左移48、40、32、24、16、8、0位然后一起做或运算。得到k2. 然后用k2✖️一个很大的数,然后左移33位,然后再乘一个很大的数得到h1.
拿后8位分别左移56、48、40、32、24、16、8、0位然后一起做或运算,✖️一个很大的数,左移31位然后在✖️一个很大的数得到k1.
然后对string.len 取或运算。
互相加
最后得到h1和h2.
参考一下64和32位的实现
func (d *digest64) Sum64() uint64 {
h1, _ := (*digest128)(d).Sum128()
return h1
}
func (d *digest32) Sum32() (h1 uint32) {
h1 = d.h1
var k1 uint32
switch len(d.tail) & 3 {
case 3:
k1 ^= uint32(d.tail[2]) << 16
fallthrough
case 2:
k1 ^= uint32(d.tail[1]) << 8
fallthrough
case 1:
k1 ^= uint32(d.tail[0])
k1 *= c1_32
k1 = bits.RotateLeft32(k1, 15)
k1 *= c2_32
h1 ^= k1
}
h1 ^= uint32(d.clen)
h1 ^= h1 >> 16
h1 *= 0x85ebca6b
h1 ^= h1 >> 13
h1 *= 0xc2b2ae35
h1 ^= h1 >> 16
return h1
}
所以murmur快是因为位运算,那为什么这一堆位运算能够使碰撞低呢。
参考一下:https://kknews.cc/zh-hk/code/naglky2.html
核心就是不断进行左移,至于某些const数字为什么是那个值,是通过计算、实验得出来的。。。然后具体的也没资料说,难受啊。