hbase安装
Hbase 安装
前提条件: 虚拟机上搭建好java 和 hadoop
若无安装 跳转 https://blog.csdn.net/qq_42432141/article/details/107691720
1、上传文件
使用Fz 在op/software/下创建hbase,并将压缩文件拉进来
2、解压
[root@jsu usr]# cd /opt/software/hbase/
[root@jsu hbase]# ls
hbase-2.0.0-bin.tar.gz
[root@jsu hbase]# tar -zxvf hbase-2.0.0-bin.tar.gz
[root@jsu hbase]# ls
hbase-2.0.0 hbase-2.0.0-bin.tar.gz
3、修改配置文件
[root@jsu conf]# vi /base-site.xml
# 修改成自己的java路径

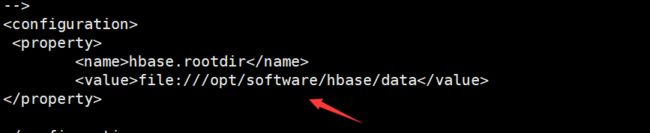
[root@jsu conf] vi hbase-site.xml
# 此处的value为安装hbase的路径 设置后会自动生成data
4、开启服务
# 进入bin目录下
[root@jsu conf]# cd ..
[root@jsu hbase-2.0.0]# cd bin
[root@jsu bin]# ls
considerAsDead.sh hbase-cleanup.sh hbase-daemon.sh local-regionservers.sh replication stop-hbase.cmd draining_servers.rb hbase.cmd hbase-daemons.sh master-backup.sh rolling-restart.sh stop-hbase.sh get-active-master.rb hbase-common.sh hbase-jruby region_mover.rb shutdown_regionserver.rb test graceful_stop.sh hbase-config.cmd hirb.rb regionservers.sh start-hbase.cmd zookeepers.sh hbase hbase-config.sh local-master-backup.sh region_status.rb start-hbase.sh
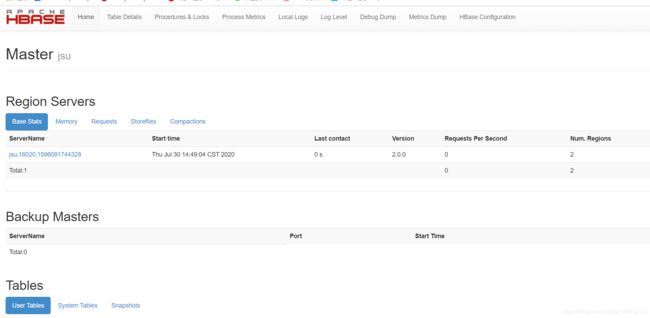
[root@jsu bin]# ./start-hbase.sh # 开启服务
查看管理页面 http://192.168.21.116:16010/master-status
5、进入客户端
[root@zhiyou bin]# ./hbase shell
# 显示这行 说明进入成功
hbase(main):001:0>
6、shell基本语句
# 创建user表,包含info、data两个列族
create 'user', 'info1', 'data1' # 第一个字段是表名,后面的是列族名
# 插入数据 user表名 rk0001 主键(自己随意设置) info:name列名属性 zhangsan值
put 'user', 'rk0001', 'info:name', 'zhangsan'
# 获取user表中row key为rk0001,info1、data列族的信息
get 'user', 'rk0001', 'info1', 'data'
get 'user', 'rk0001', {COLUMN => ['info1', 'data']}
get 'user', 'rk0001', {COLUMN => ['info:name', 'data:pic']}
###########################################################################################################
# 创建表2 NAME => 'info 列明 VERSIONS => '3' 版本号
create 'user', {NAME => 'info', VERSIONS => '3'}
hbase(main):007:0> put 'user1', 'rk0001', 'info:age', '20' hbase(main):008:0> put 'user1', 'rk0001', 'info:age', '30' hbase(main):009:0> put 'user1', 'rk0001', 'info:age', '40'
hbase(main):010:0> put 'user1', 'rk0001', 'info:age', '50'
hbase(main):011:0> put 'user1', 'rk0001', 'info:age', '60'
# 无论修改多少次 只能找到版本号对应的数据次数
hbase(main):012:0> get 'user1', 'rk0001', {COLUMN => 'info:age', VERSIONS => 3}
COLUMN CELL
info:age timestamp=1596092477443, value=60
info:age timestamp=1596092473667, value=50
info:age timestamp=1596092469992, value=40
# 获取user表中row key为rk0001,!列! 标示符中含有a的信息
get 'user', 'rk0001', {FILTER => "(QualifierFilter(=,'substring:a'))"}
# 获取user表中row key为rk0002,!值! 标示符中含有中国的信息
get 'user', 'rk0002', {FILTER => "ValueFilter(=, 'binary:中国')"}
# 查询user表中列族为info的信息
scan 'people', {COLUMNS => 'info'}
# Scan时可以设置是否开启Raw模式,开启Raw模式会返回包括已添加删除标记但是未实际删除的数据
scan 'user', {COLUMNS => 'info', RAW => true, VERSIONS => 3}
# 查询user表中列族为info和data的信息
scan 'user', {COLUMNS => ['info', 'data']}
scan 'user', {COLUMNS => ['info:name', 'data:pic']}
# 查询user表中列族为info,rk范围是[rk0001, rk0003)的数据
scan 'people', {COLUMNS => 'info', STARTROW => 'rk0001', ENDROW => 'rk0003'}
# 查询user表中row key以rk字符开头的
scan 'user',{FILTER=>"PrefixFilter('rk')"}
# 查询user表中时间戳指定范围的数据
scan 'user', {TIMERANGE => [1392368783980, 1392380169184]}
# 删除数据
# 删除user表row key为rk0001,列标示符为info:name的数据
delete 'people', 'rk0001', 'info:name'
# 删除user表row key为rk0001,列标示符为info:name,timestamp为1392383705316的数据
delete 'user', 'rk0001', 'info:name', 1392383705316
# 清空user表中的数据
truncate 'user'
# 修改表结构
# 首先停用user表(新版本不用)
disable 'user'
# 删除表
disable 'user'
drop 'user'
```
# 清空user表中的数据
truncate 'user'
# 修改表结构
# 首先停用user表(新版本不用)
disable 'user'
# 删除表
disable 'user'
drop 'user'