最新Machine Reading Comprehension数据集和方法总结
这篇文章是我的Machine Reading Comprehension相关论文的阅读笔记,归纳介绍了一些最新的MRC的数据集和方法,如有写的不对的地方,欢迎指正。
一、数据集
1、 datasets with extractive answers
(1)SQuAD
(2)CNN/Daily Mail
(3)CBT
(4)NewsQA
(5)TriviaQA
(6)WIKIHOP
2、 datasets with descriptive answers
(1)MS MARCO
(2)NarrativeQA
3、 datasets with multiple-choice answers
(1)MCTest
(2)RACE
(3)CLOTH
(4)MCScript
(5)ARC
(6)CoQA
二、MRC方法
1、Non-Neural Method
(1)TF-IDF
(2)sliding window
(3) logistic regression
(4)boosted method
2、neural-based models
(1)mLSTM+Ptr
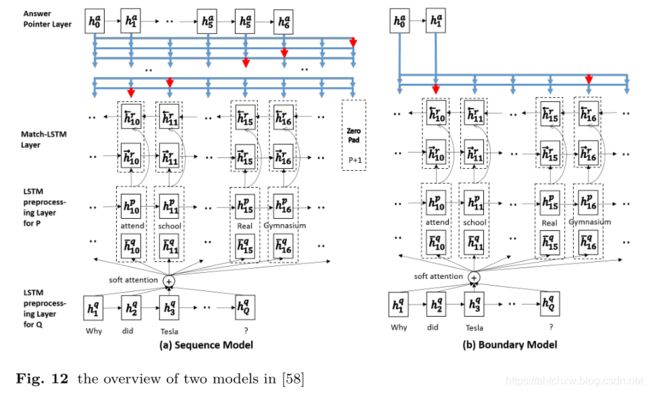
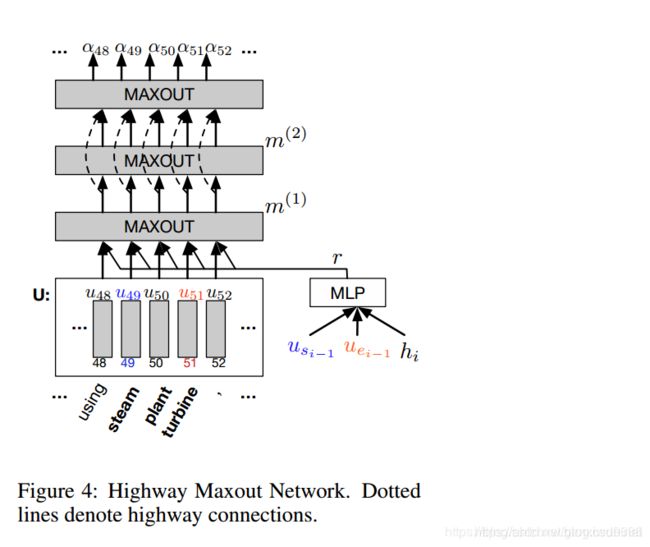
模型整体分为三部分:
LSTM预处理层:编码原文以及上下文信息
match-LSTM层:匹配原文和问题
Answer-Pointer层:使用Ptr-Net网络,从原文中选取答案。这里又提出了两种预测答案的模式:
1、Sequence model:不做连续性假设,预测答案存在与原文的每一个位置。
2、边界模型:直接预测答案在原文中起始和结束位置。相比于 Sequence Model 极大地缩小了搜索答案的空间,最后的实验也显示简化的 Boundary Model 相比于复杂的 Sequence Model 效果更好,因此 Boundary Model 也成为后来的模型用来预测答案范围的标配。
简单的说:带着问题去阅读原文,然后用得到的信息去回答问题
- 先利用LSTM阅读一遍passage,得到输出的encoding 序列。
- 然后带着question的信息,重新将passage的每个词输入LSTM,再次得到passage的encoding信息。但是这次的输入不仅仅只有passage的信息,还包含这个词和question的关联信息,它和question的关联信息的计算方式就是我们在seq2seq模型里面最常用的attention机制。
- 最后将信息输入answer模块,生成答案。
Match-LSTM layer
match-LSTM原先设计是用来解决文版蕴含任务:有两个句子,一个是前提H,另外一个是假设T,match-LSTM序列化地经过假设的每一个词,然后预测前提是否继承自假设。而在问答任务中,将question当做H,passage当做T,则可以看作是带着问题去段落中找答案。这里利用了attention机制(soft-attention)。
对段落p中每个词,计算其关于问题q的注意力分布α,并使用该注意力分布汇总问题表示;将段落中该词的隐层表示和对应的问题表示合并,输入另一个 LSTM 编码,得到该词的 query-aware 表示。具体结构如下:
- 针对passage每一个词语输出一个α向量,这个向量维度是question词长度,故而这种方法也叫做question-aware attention passage representation。

- 将attention向量与原问题编码向量点乘,得到passage中第i个token的question关联信息,再与passage中第i个token的编码向量做concat,粘贴为一个向量
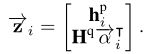
- 最后输出到LSTM网络中。
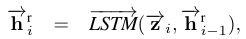
- 反向同样来一次,最后两个方向的结果拼起来。得到段落的新的表示,大小为2lxP.
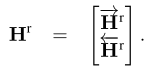
(2)BiDAF
同时引入了Char 和 Word Embdeeing.
在interaction交互层引入了双向注意力机制。Match-LSTM只有Passage对Question的注意力,Passage中每个单词关注Question中的哪些单词。这里引入了Question看Passage的注意力在哪,这样可以计算得到Question眼中的Passage哪些单词重要哪些不重要。
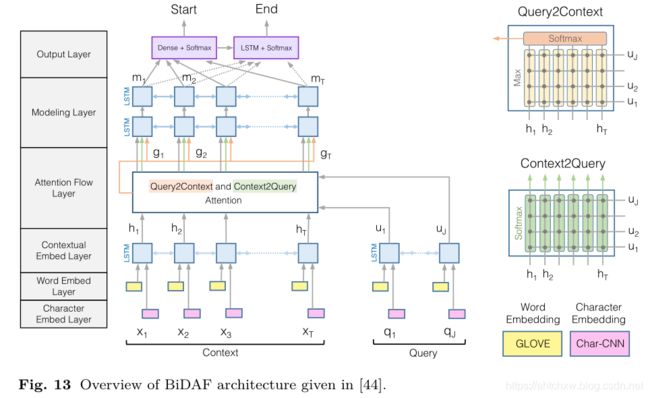
Character Embedding Layer
利用character level CNN将每个词映射到一个高位向量空间
Word Embedding Layer
利用GloVe将每个词映射到一个高维向量空间
然后把character embedding和word embedding拼接青睐,通过两层Highway Network处理后得到passage矩阵和query矩阵,在输入到后面的层。
Contextual Embedding Layer
将前两步拼接得到的结果利用Bi-LSTM进行编码,以获得contextual embedding,分别得到passage矩阵H和query矩阵U
Attention Flow Layer
定义相似度矩阵S如下:

其中o表示element-wise multiplication,w表示一个可训练的向量,后面的相似度计算均采用这里定义的公式。
Context-to-query Attention(C2Q)这个方向的attention需要确定对于每一个passage中的词,query中那个词和它最接近。将query中每个词和passage中的一个词计算相似度,然后经过softmax层归一化后,计算query向量加权和。结果作为对应于passage这个词的问题表示向量,最后得到矩阵U~。
Query-to-context Attention(Q2C)这个方向的attention需要确定对于每一个query中的词,哪一个passage中的词和它最相似,也就是对于回答比较重要。取每列最大值,然后讲这些最大值经过softmax归一化后,计算passage向量加权和。将这个向量平铺V(passage词汇的个数)次得到矩阵H~。
最终将这三个矩阵拼接:
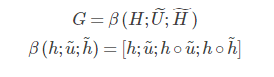
这样就得到了每个passage中词的query-aware representation
Modeling Layer
将G中的向量再经过一个Bi-LSTM得到矩阵M
Output Layer
这一步预测span的开始为值和结束位置,如下:
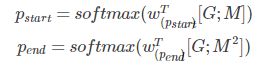
M^2表示将M输入到另一个Bi-LSTM中的结果。
训练目标采用:

(3)GA
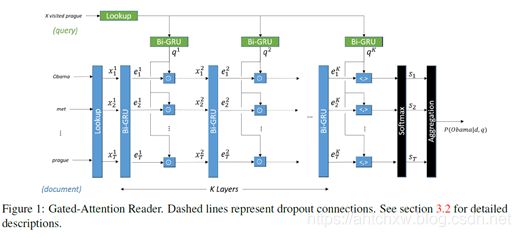
首先用双向GRU编码问题query,将正向和逆向的最后一个表示作为查询向量的表示q,每层采用一个GRU编码器。
![]()
用查询的表示对每一层的每一个文档中的词操作,作者称之为gate-attention,这个操作是多个点乘的方式,和传统的attention机制不同,传统的attention机制是对每一个词做权重的加和。
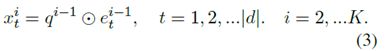
最后一层做内积(dot-product between two vectors),得到概率分布,然后利用sum-reader思想,将相同的文档词语预测加和。这个概率分布是针对文档中的词来讲的,若文档中有相同词多次出现,则把每一个位置的词概率加和,得到最终这个词预测的概率。这样的方式,就是直接在文档中寻找答案,阅读理解有一个假设就是回答的答案应该出现在文档中至少一次,如此,在学习的最后阶段我们可以直接从文档中找寻答案。
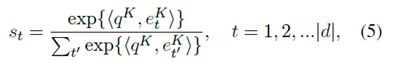
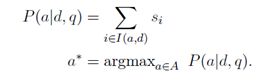
(4)DCN
整体结构
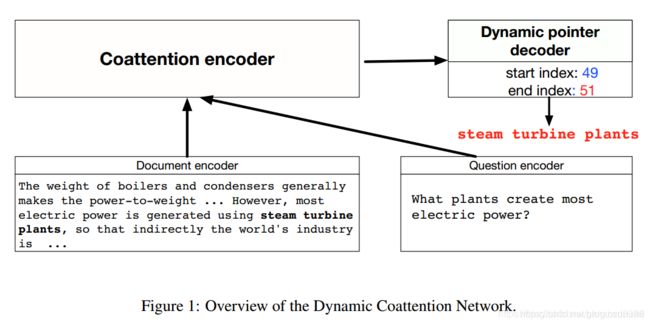
主要就是两部分:
coattention encoder
dynamic pointer
coattention encoder
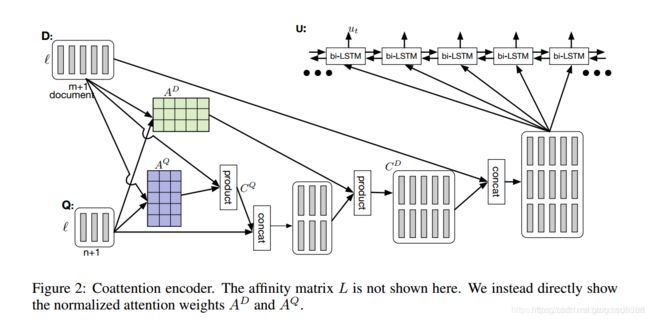
1、文档和问题表示:
输入就是文档和问题,输出是答案起止位置对应的index
首先xQ表示问题,xD表示文档中的每个词对应的词向量,经过LSTM后得到
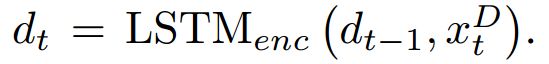
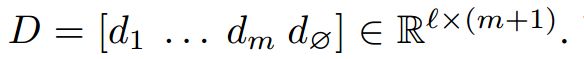
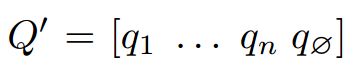
同理经过LSTM也得到了qt,然后得到Q‘
接着,做一个非线性变化,最终得到问题表示:
![]()
2、encoder
经过上面的表示,文档有m+1个词,问题有n+1个词。下面进行attention计算:
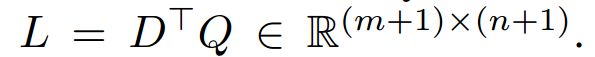
![]()
AQ相当于做完点积之后,按行softmax;而AD相当于对列做softmax。得到CQ,然后和问题做连接,与AD相乘得到CD。
![]()
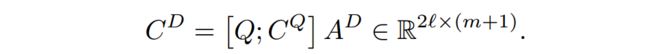
最后将CD和文档连接,得到最后的表示,再经过LSTM得到passage中每一个word的表示。
dynamic pointer
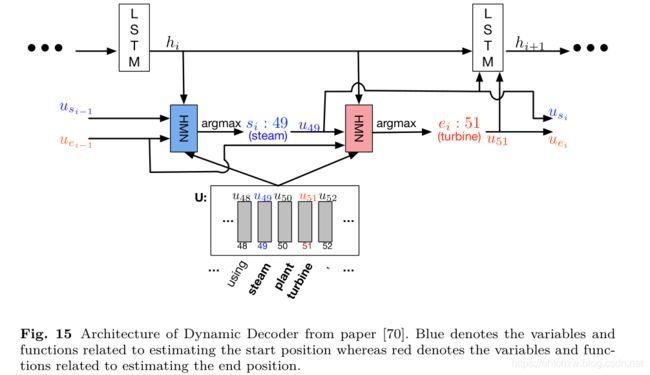
之所以称为动态原因是由于,对于位置的确定时代用iterate,迭代模式进行更新,由于对于一个问题question和document对可能在文档多个可能答案的位置,这个迭代的方式可以允许模型从局部最优解答案也就是错误的答案中跳转出来,这个迭代方式的预测是仿照lstm的state状态完成的,每一次迭代加入前一时刻的状态以及start和end位置通过lstm进行预测新的start和end位置
1、解码端,轮流开始预测起止位置,先定义LSTM计算方式,更新state

2、通过两次softmax得到开始、结束位置,计算如下:
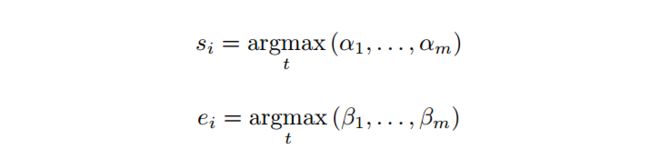
其中α,根据前一时刻的起止位置和当前时刻的隐层state,通过一个HMN网络得到,β同理,只不过需要用当前时刻的开始位置:
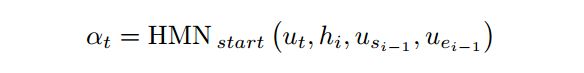
3、HMN具体展开如下:
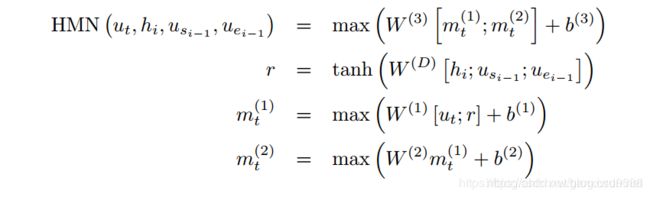
最后直到答案起止位置不变,或者达到最大迭代次数终止。
(5)FastQA
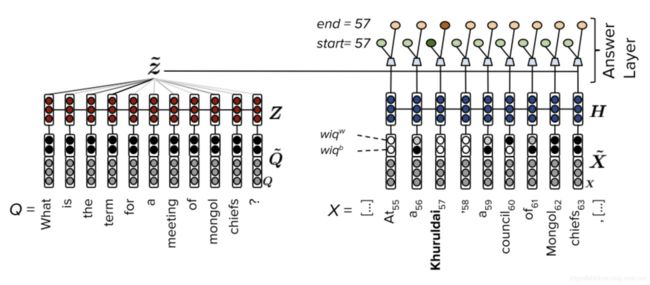
FastQA以简单的体系结构获得了具有竞争力的性能,这对提高QA系统复杂性的必要性提出了质疑。与许多使用复杂交互层来捕获查询和上下文之间的交互的系统不同,FastQA只使用word级别上的可计算特性。FastQA体系结构概述如图17所示。
二进制问题字(wiq b)特性指示在相应的查询中是否出现段落中的token。
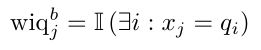
加权特征(wiq w),定义如下,考虑了词频和查询与上下文之间的相似性。
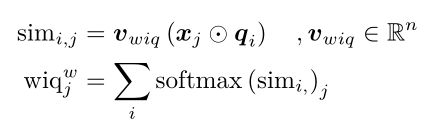
将这两个特性的连接和每个单词的原始表示形式输入到Bi-LSTM中,以获得最终的隐藏状态。答案层由一个简单的两层前馈网络和beam search组成。
(6)RNET
R-NET模型一共分为四个步骤,分别为QUESTION AND PASSAGE ENCODER, GATED ATTENTION-BASED RECURRENT NETWORKS, SELF-MATCHING ATTENTION, OUTPUT LAYER, 基本结构可观察上面所示的结构图。
R-NET首先采用双向GRU对问题和段落进行编码。然后利用一个基于gated attention-base的递归网络将问题和文章中的信息进行融合。然后,使用自匹配层进行微调,并获得文章的最终表示形式。输出层是基于与match-LSTM相似的指针网络来预测答案的边界。
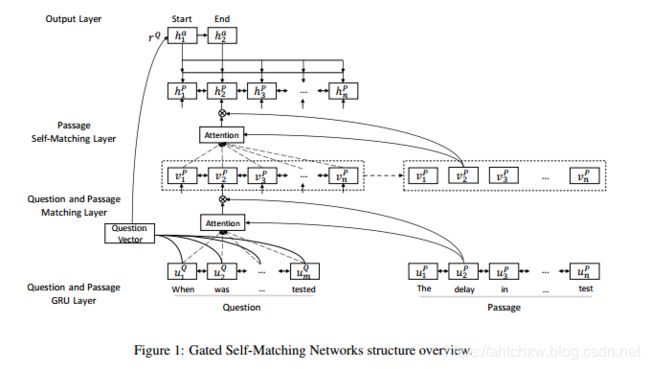
(7)ReasoNet
ReasoNet与之前的模型不同,之前的模型在阅读或推理时循环次数固定,而不考虑查询和段落的复杂性,它利用强化学习来动态确定阅读和推理的深度。因为同一个数据集中不同问题的难度可能会有很大的不同,以及人类通常会重温文章和问题的重要部分来更好地回答问题。推理机结构概况如图19所示。
外部Memory M通常是由Bi-RNN编码的嵌入式单词。 Internal State s通过s t+1 = RNN(st,xt;θs)来更新。x t是Attention向量:x t = fatt(st,M;θx)。 Termination Gate决定了何时停止更新上述状态,并根据二进制变量t t 预测答案,根据当前内部状态产生一个binary随机变量。如果为1,那么结束推理预测答案;如果为0,那么继续推理
![]()
这样推理机就可以模拟人的推理过程,更好地利用篇章,更好地回答问题。
(8)QAnet
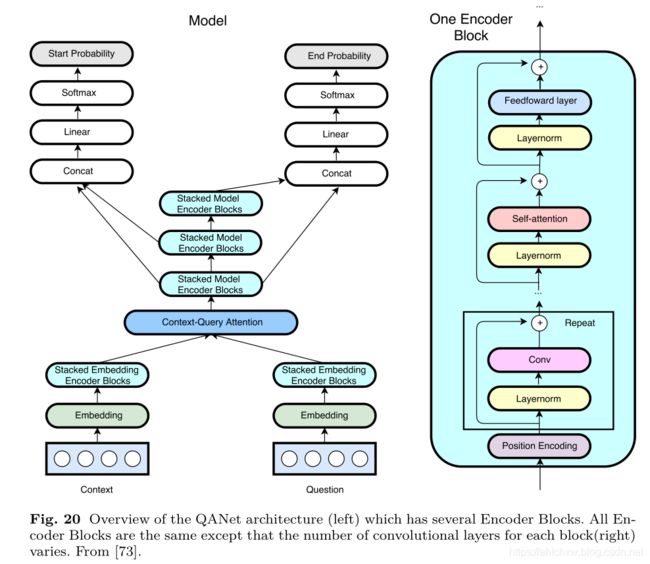
模型由五层结构组成:
input embedding layer
embedding encoder layer
context-query attention layer
model encoder layer
output layer
1、input embedding layer

2、embedding encoder layer
由encoder block组成,单个encoder block结构自底向上一次包含位置编码(position encoding),卷积(conv)层,self attention层和前馈网络(fnn)层。每个基本操作(conv/self-attention/fnn)都放在残差块(residual block)里。卷积层和self-attention层的作业解释是:卷积能够捕获上下文局部结构,而self-attention则可以捕捉文本之间全局的相互作用。
3、context-query attention layer

4、model encoder layer
由3个model encoder block组成,每个model encoder block由7个encoder block堆叠而成,3个model encoder block之间共享参数。与BIDAF类似,每个位置的输入是[c,a,c⊙a,c⊙b],a和b分别为attention矩阵A和B的行,c是context对于位置的单词中间表示。
5、output layer
分别预测每个为是answer span的起始点和结束点的概率,分别记为p1、p2,计算公式如下:
