Tacotron-2 实验记录
Try the Std Version
1. Get Tacotron-2-master.zip from https://github.com/Rayhane-mamah/Tacotron-2
2.Unzip Tacotron-2-master.zip on Unbuntu
3.Terminal: cp -r training_data ./Tacotron-2 #training_data is folder which was preparing by LJSpeech-1.1 & dataset
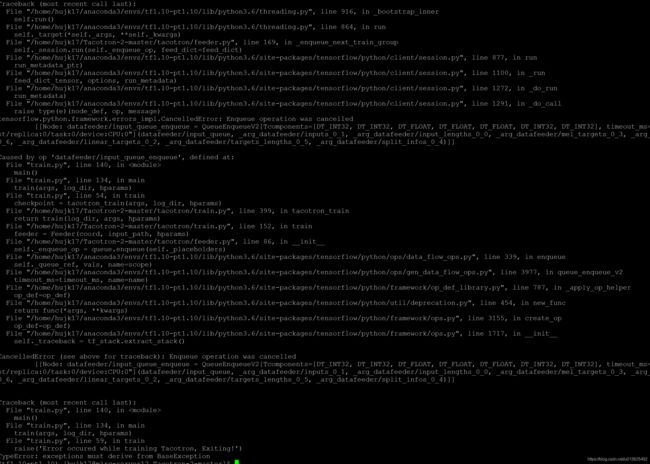
4.Terminal: python train.py --model='Tacotron-2':
CancelledError (see above for traceback): Enqueue operation was cancelled
[[Node: datafeeder/eval_queue_enqueue = QueueEnqueueV2[Tcomponents=[DT_INT32, DT_INT32, DT_FLOAT, DT_FLOAT, DT_FLOAT, DT_INT32, DT_INT32], timeout_ms=-1, _device="/job:localhost/replica:0/task:0/device:CPU:0"](datafeeder/eval_queue, _arg_datafeeder/inputs_0_1, _arg_datafeeder/input_lengths_0_0, _arg_datafeeder/mel_targets_0_3, _arg_datafeeder/token_targets_0_6, _arg_datafeeder/linear_targets_0_2, _arg_datafeeder/targets_lengths_0_5, _arg_datafeeder/split_infos_0_4)]]
Traceback (most recent call last):
File "train.py", line 138, in
main()
File "train.py", line 132, in main
train(args, log_dir, hparams)
File "train.py", line 57, in train
raise('Error occured while training Tacotron, Exiting!')
TypeError: exceptions must derive from BaseException
Maybe this wrong is caused by gpu collide,
Write code:
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "6, 7"Then it can be training.(step1, 2, 3......)
(Befor it , sys need to get conda env including requirment. It's not a easy thing. Here need to add)
Then the time of trainnint this batch(32) is 4.5 sec, although use two gpus, but the memory seems to only use the forst one.
(Need to test gpu_nums = 4, and use 4gpus; And set different batch_size, and training steps)
###from now is test
File:train.py
'5, 6'
File:hyparam.py
tacotron_num_gpus = 2
tacotron_batch_size = 32 * 2
parser.add_argument('--summary_interval', type=int, default=250,
help='Steps between running summary ops')
parser.add_argument('--embedding_interval', type=int, default=5000,
help='Steps between updating embeddings projection visualization')
parser.add_argument('--checkpoint_interval', type=int, default=2500,
help='Steps between writing checkpoints')
parser.add_argument('--eval_interval', type=int, default=5000,
help='Steps between eval on test data')
change =>
parser.add_argument('--summary_interval', type=int, default=1000,
help='Steps between running summary ops')
parser.add_argument('--embedding_interval', type=int, default=5000,
help='Steps between updating embeddings projection visualization')
parser.add_argument('--checkpoint_interval', type=int, default=1000,
help='Steps between writing checkpoints')
parser.add_argument('--eval_interval', type=int, default=5000,
help='Steps between eval on test data')
Train successfully, but batch_size = 64 make the single step's time = 5, don't know wether this is good for train both 10w steps compared with batch_size = 32, single gpu.
###end here
Now let's just wait.
After steps 25000, suddenly, it occurs the error: data feeder...
Just reuse terminal python train --model=' Tacotron-2', then it can work.
Don't know the reason, maybe test later. But for now, if it happens again, decrease steps between the save model by half.
Happened again, decrease to 250 steps. Don't know why, maybe is gpu_nums problem. And again, find gpus were used, maybe because this. Error is:

change GPUs from '5, 6' => '3, 4'
But still error:
改为默认的gpu_num = 1, batch_size = 32, "6"
5. ToDo. Error cause training stoped happens every day, needs to write sh to restart and need to use the free GPUs.
6. Tacotron-2-log/wav 's waves are better then eval/wav's, read code to see why. Maybe the text unseen in the training data. All of this is no teacher forced. Finished: wavs is in training set, eval/waves is in testing set, if all is teacherforced, then just for avoiding overfitting.
7. Liang dada's picture paper about teacher forced rate. Finished: teacher_forcing-mode in haparm.py, but not know it's details.
8. optimize
- (Song Changhe) 可能是特征这块出现问题, (这一步主要是为了验证加入线性谱的影响, 加入后线性谱介于MEL和WaveNet之间, 但音质还是不行, 同时看看线性谱对loss的影响, 到底是好是坏?)把提取出来的线谱直接用GL恢复一下, 看看有没有颤音 来排除taco2的原因.
- 严格按照https://github.com/Rayhane-mamah/Tacotron-2, python train.py --model='Tacotron-2'
- tacotron_num_gpus = 1. wavenet_num_gpus = 1. split_on_cpu = False, 改成这个不会出错
-
maybe out of GPU memory? Try running withtensorflow.python.framework.errors_impl.InternalError: Failed to create session.CUDA_VISIBLE_DEVICES='' speaker分为0, 1, 2, 3是怎么回事, 数据集明明没有多说话人.- Ground Truth Aligned synthesis (DEFAULT: the model is assisted by true labels in a teacher forcing manner). This synthesis method is used when predicting mel spectrograms used to train the wavenet vocoder. (yields better results as stated in the paper) 没理解, 不过平时也不用, 先跳过.
- CUDA_VISIBLE_DEVICES='' python synthesize.py --model='Tacotron-2' --mode='live' 或者增加GPU (这样跑出来的是mel转wav, 可以跑eval)
- 接着训练, 跑完全部的.
- 训练速度上, 去掉线性谱, outputs_per_step调大, 会加快. 并行也再看看, teacherForce Ratio也会影响收敛速度.
- (Song Changhe) mel到线谱这个网络会添加比较大的扰动, 训练的时候, 最好一般是这个网络都不会使用的, 直接用mel位置的输出.
- 平时不带线性谱, 临时听效果就听Mel的, 仔细听效果用WaveNet.
- 其实WaveRNN版本真心不赖.
- (Song Changhe) 数据集应该问题不大, taco2在LJSpeech上是可以的.(!!!!需要尝试)
- (Song Changhe) 如果这样还不行的话, 可以考虑换个声码器, GL的一个缺点在实际应用的时候就是会出现高频的杂音, 非常明显. 尝试直接使用mel谱恢复语音, 用Merlin, WaveNet, WaveRNN, LPCNET, ClariNet, Voiceloop, Transformer TTS.
- WaveNet. 使用https://r9y9.github.io/wavenet_vocoder/ 的版本, 直接在colaboratory上跑, https://colab.research.google.com/github/r9y9/Colaboratory/blob/master/Tacotron2_and_WaveNet_text_to_speech_demo.ipynb. Rayhane-mamah的Tacotron2 (Tensorflow) 版本, 以及r9y9/wavenet_vocoder (Pytorch)版本, pre_train model 189k steps and over 1000k steps. @Lab10: test_t2_wavenet + Tacotron-2 + wavenet_vocoder. 但是服务器环境conda tf1.1中pysptk (静北师兄帮忙配的). 目前在colab跑, 环境不矛盾 (ubuntu的原因? conda的原因?) 可以合成声音, 但是waveNet合成速度非常慢. "This is text-to-speech online demonstration by Tacotron 2 and WaveNet", 需要15min大约 (colab默认的GPU, 但代码对GPU的利用不知道). (WaveNet慢, 不知道用没用Fast优化, 以及并行计算版本)
- WaveNet. 较快的WaveNet并行训练版本: https://github.com/andabi/parallel-wavenet-vocoder (声音质量太差, 但这个思路是个突破口)
- WaveNet. 日本人实现的, 公司开源的版本, 看不懂WaveNet版本, 而且没有公布速度, 但是有colab的代码, 代码测试速度33919 samples 60s以上, https://github.com/kan-bayashi/PytorchWaveNetVocoder. (WaveNet慢, 没有仔细看)
- WaveNet. https://github.com/NVIDIA/nv-wavenet 英伟达版本, git的说明写的不好, 但应该是最快的waveNet版本, 毕竟有工程化的角度. 但是目前没有去尝试, 不熟悉这部分代码和他的部署. (没有实验过)
- 尝试LPCNET.
- https://github.com/mozilla/LPCNet
- The code also supports very low bitrate compression at 1.6 kb/s.
- The same functionality is available in the form of a library. See include/lpcnet.h for the API.
- https://people.xiph.org/~jm/demo/lpcnet_codec/
- https://zhuanlan.zhihu.com/p/54952637
- 需要有个转换网络, 或者直接用LPC的特征训练, 因为和使用pretrained Model不太合适, (等掌握了局部图变量赋值)
- https://github.com/alokprasad/LPCTron 尝试代码, 长河在看.
- ClariNet
- https://github.com/ksw0306/ClariNet
- https://github.com/ksw0306/FloWaveNet
- demo不错, 介绍有点并行WaveNet的感觉, 没细看, 也没有跑代码, 等有时间再说吧, 也没有Pre-trained Model
- WaveRNN.比WaveNet本身就快, 但是还不成熟. 尝试了一个: https://github.com/fatchord/WaveRNN
- Merlin应该指的传统的SSPS吧, 单独作为Mel vocoder不知道怎么样. 问下长河.
- CNN的Tacotron, 不主流, 但听说训练快, 汉语合成不错. https://github.com/ruclion/dc_tts
- VoiceLoop, 应该用的是world, 没看. https://github.com/facebookarchive/loop
- 最初原始的Tacotron1, 并且有详细的数据和评测. https://github.com/kyubyong/tacotron
- Transformer TTS, 等翔宇的调查和思考实验. https://github.com/soobinseo/Transformer-TTS
- (Song Changhe) 音质的明显问题调参数是解决不了的, 没动默认参数, 更不可能是调参的问题.
- (Song Changhe) 其实还有个英伟达的pytorch版本, 用的waveglow, 那个跑过, 不靠谱, 效果不好, 他给taco2做了一些简化, 并不是完全复现.
- (Wu Xixin) 得用下wavenet, wavernn去进一步提高音质.
- https://github.com/NVIDIA/tacotron2
- WaveGlow: https://developer.download.nvidia.com/video/gputechconf/gtc/2019/presentation/s91022-text-to-speech-overview-of-the-latest-research-using-tacotron2-and-waveglow-with-tensor-core-performance.pdf
- https://ngc.nvidia.com/catalog/model-scripts/nvidia:tacotron_2_and_waveglow_for_pytorch
- (Wu Xixin) Tacotron1仍然能跑出来较好声音. 训练时间也是大约4天.
- 不知道要怎么测试, 因为T2比T1是"进步"了.
- (Wu Xixin) 训练到到达10w步, 再去看声音, 一锤定音, 而且到时候应该会好很多.
- (Wu Xixin) 训练的时候, 第一个epoch训练样本从短到长排列, 然后训练, 第二个epoch开始再打乱. (不是特别清楚...), 现在是先排序, 再分batch, 然后随机.
- (Liu Liangqi) Rayham那个版本的tacotron2中的wavenet写的有问题, 跑的效果不好.
- 尝试直接全部开源Rayham + WaveNet, 以及100W+steps的pre_trained model.
- (Liu Liangqi) GL的话, 合成的时候prenet 有加dropout吗? 不加的话, 如果模型训得过拟合会有噪音的情况.
- hypama.py中有droupout的设置, 应该是对的.
- (Liu Liangqi) 尝试去年10月份那个版本.
- 1. 重新处理数据: python preprocess.py --base_dir '/home/data/LJSpeech-1.1/' 或者 cp -r ../Tacotron-2-master/training_data ./ 或者 train时候指定文件目录. 最终还是选了最保险的下载数据集, tar -jxvf ×××.tar.bz2, 然后用preprocess "python preprocess.py" 重新提取.
- 2. 训练参数的指定
- 3. python train.py --model='Tacotron'
- (Liu Liangqi) 要是之后想用wavenet去合成就不带, 否则用GL看效果的话都会带上线性谱.
Try to Synthesis
ValueError: Defined synthesis batch size 1 is smaller than minimum required 2 (num_gpus)! Please verify your synthesis batch size choice.num_gpu = 1
CUDA_VISIBLE_DEVICES='' python synthesize.py --model='Tacotron-2' --mode='live' 或者增加GPU
Try to Train CN version
From https://github.com/awesome-archive/tacotron_cn down zip
conda tf1.10-pt1.10
Then pip install pypinyin
Try bash train.sh, but have not set the right path and training_data, so just stop now.
Wait for Xingchen's successful version.
Try Pytorch Version Tacotron2
1. "nvcc -V" to see cuda vesion
2. install pytorch1.2
conda install pytorch torchvision cudatoolkit=10.0 -c pytorch !!!!!!!!!Always Time out.3. git clone https://github.com/NVIDIA/tacotron2.git
4.mv tacotron Pt-Tacotron
5.git submodule init; git submodule update
6.sed -i -- 's,DUMMY,/home/data/LJSpeech-1.1/wavs,g' filelists/*.txt