自定义Partitioner分区
在Hadoop的MapReduce过程中,每个map task处理完数据后,如果存在自定义Combiner类,会先进行一次本地的reduce操作,然后把数据发送到Partitioner,由Partitioner来决定每条记录应该送往哪个reducer节点,默认使用的是HashPartitioner,其核心代码如下:
1) 自定义Partitioner类必须继承自Partitioner类,重写getPartition方法
package com.root.PartitionDemo;
import com.root.flowsum.FlowBean_2;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class provicePartition extends Partitioner
@Override
public int getPartition(Text text, FlowBean_2 flowBean_2, int i) {
String prePhoneNum = text.toString();
int partition = 4;
if ("Sci&Tech".equals(prePhoneNum)) {
partition = 0;
} else if ("Comm&Mgmt".equals(prePhoneNum)) {
partition = 1;
} else if ("Others".equals(prePhoneNum)) {
partition = 2;
} else {
//我的测试文本文件中以上三个key字段之外没有其他字段,
//所以第四个分区文件内为空
partition = 3;
}
return partition;
}
}
2) map与reduce自定义代码
Map阶段:
package com.root.PartitionDemo;
import com.root.flowsum.FlowBean_2;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class FlowCountMapper extends Mapper
Text k = new Text();
FlowBean_2 v = new FlowBean_2();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1.获取一行
String line = value.toString();
//2.切割,文件以","分割每个字段
String[] fields = line.split(",");
if(fields.length>1 && !fields[fields.length - 5].isEmpty() && !fields[fields.length - 3].isEmpty()) {
//3.封装对象
k.set(fields[1]);
Float etest = Float.parseFloat(fields[fields.length - 5]);//etest在倒数第五个位置
Float mba = Float.parseFloat(fields[fields.length - 3]); //mba在倒数第三个位置
v.setEtest(etest);
v.setMba(mba);
//4. 写出
context.write(k, v);
}
}
}
Reduce阶段:
package com.root.PartitionDemo;
import com.root.flowsum.FlowBean_2;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class FlowCountReducer extends Reducer
FlowBean_2 v = new FlowBean_2();
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
//1.累加求和
float sum_upFlow = 0;
float sum_downFlow = 0;
for (FlowBean_2 flowBean : values) {
sum_upFlow += flowBean.getEtest();
sum_downFlow += flowBean.getMba();
}
//这里我做了一个简单的upFlow(etest)与downFlow(mba)求和。
v.set(sum_upFlow,sum_downFlow);
//2.写出
context.write(key,v);
}
}
3)封装获取文本文件获取到的数据:
package com.root.flowsum;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class FlowBean_2 implements Writable {
private float mba; //mba
private float etest; //etest
private float summe;
//空参构造,为了后续反射用
public FlowBean_2() {
super();
}
public FlowBean_2(float mba, float etest) {
super();
this.mba = mba;
this.etest = etest;
summe = mba + etest;
}
//序列化方法
public void write(DataOutput out) throws IOException {
out.writeFloat(mba);
out.writeFloat(etest);
out.writeFloat(summe);
}
//反序列化方法
public void readFields(DataInput in) throws IOException {
//必须要求和序列化方法顺序一致
mba = in.readFloat();
etest = in.readFloat();
summe = in.readFloat();
}
public float getMba() {
return mba;
}
public void setMba(float mba) {
this.mba = mba;
}
public float getEtest() {
return etest;
}
public void setEtest(float etest) {
this.etest = etest;
}
public float getSumme() {
return summe;
}
public void setSumme(float summe) {
this.summe = summe;
}
public void set(float etest2, float mba2) {
etest = etest2;
mba = mba2;
summe = etest + mba;
}
@Override
public String toString() {
return etest + "\t"
+ mba +
"\t" + summe;
}
}
3) 提交job程序:
package com.root.PartitionDemo;
import com.root.flowsum.FlowBean_2;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class FlowsumDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//将项目打包上传至服务器 下一行代码不加,
//服务器运行jar包,会要求用户跟测试文件以及文件输出路径
args = new String[]{“F:\scala\Workerhdfs\input3\”,“F:\scala\Workerhdfs\output3”};
//1.获取job对象
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//2.设置jar路径
job.setJarByClass(FlowsumDriver.class);
//3.关联mapper和reducer
job.setMapperClass(FlowCountMapper.class);
job.setReducerClass(FlowCountReducer.class);
//4 设置mapper输出的key和value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean_2.class);
//5. 设置最终输出的key和value类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean_2.class);
job.setPartitionerClass(provicePartition.class);
job.setNumReduceTasks(4);
//6.设置输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//7.提交job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
idea运行以上程序: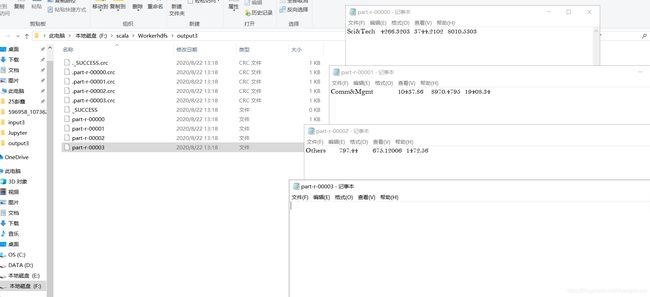
与我们预想的一样按照key值相同的进行分区以及汇总,part-r-00003文件内容为空.
打包到服务器上运行,上传测试文件以及jar包至hadoop文件系统,这里请读者自行将文件放入linux系统:
之前我的项目有
Flowsum.jar包,也就不折腾了重命名partition.jar包
查看测试文件大致内容:
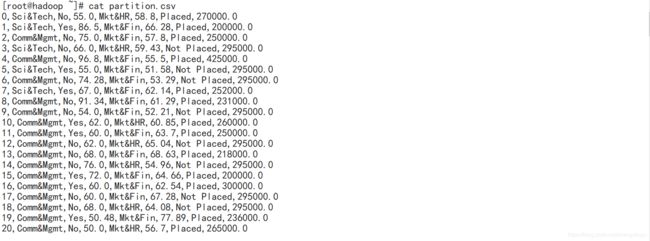
这里请注意,测试文件必须以",“作为分割(以其他字符作为分割符必须更改自定义Map代码中String[] fields = line.split(”,"); 的分割符,以及测试文件不能有缺失值
**上传jar包至hadoop文件系统,相关命令:hadoop dfs -put partition.jar /input
**:
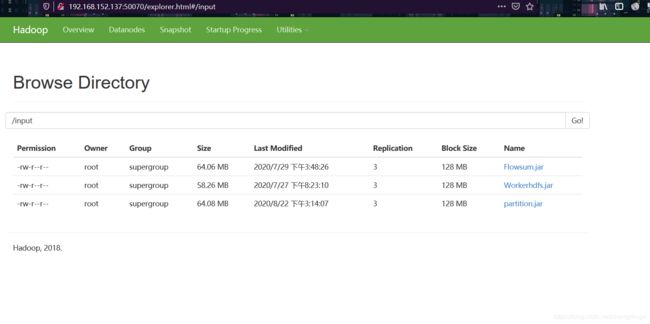
**上传测试文件partition.csv,相关命令:hadoop dfs -put partition.csv /tmp/input3
**
**运行partiton.jar包: **
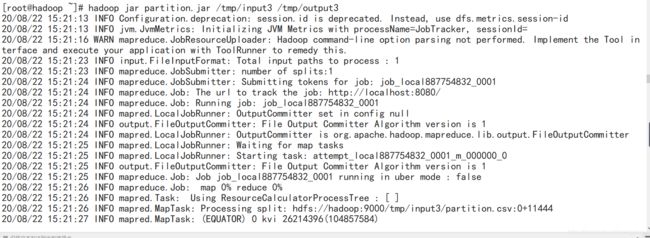
结果如下:
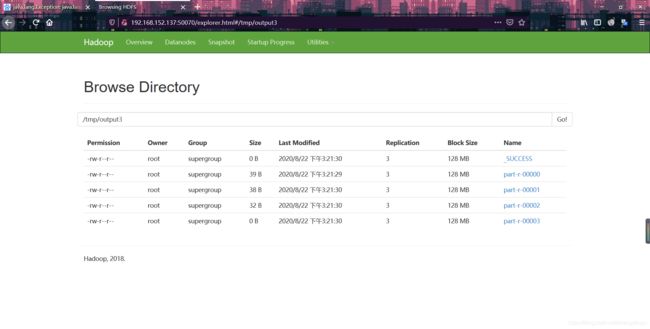
查看分区文件内容:
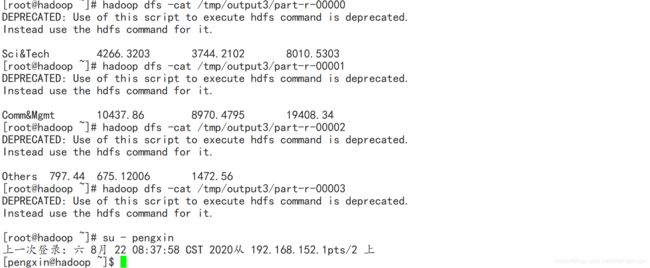
自定义分区Partitioner分区成功