用博客记录自己的学习历程(莫等闲,白了少年头,空悲切)
Kite学习框架的第四天
今天的的学习内容: 基于代理 Dao 实现 MyBatis中的CRUD操作的实现(增删改查操作)
使用要求:
1、持久层接口和持久层接口的映射配置必须在相同的包下
2、持久层映射配置中 mapper 标签的 namespace 属性取值必须是持久层接口的全限定类名
3、SQL 语句的配置标签,,,的 id 属性必须和持久层接口的 方法名相同。
1. 根据 ID 查询
1.1 在接口UserDao中新建方法:findById()
/**
* 根据id查询信息
* @param userID
* @return
*/
User findById(Integer userID);
1.2 在配置文件UserDao.xml添加findById()的配置信息
注释:
resultType 属性: 用于指定结果集的类型。
parameterType 属性: 用于指定传入的数据类型
sql语句中的 #{} : 它代表占位符,相当于?,都是用于执行语句时替换实际的数据。 具体的数据是由#{}里面的内容决定的。
#{}中的数据: 数据类型是基本数据类型,可以随意填写,但尽量跟数据库中对应的数据名称保持一致,或者稍作修改
<select id="findById" parameterType="INT" resultType="com.kiteYY.domain.User">
select *from user where id=#{userid};
</select>
1.3 在测试类MyBatisTest中新建测试方法:findByIdTest()
因为我们前面添加了findAll()方法的单元测试,其中获取代理对象,释放资源的方法跟今天的CRUD操作相同,所以我将其提取为了init()方法,desroy()方法。
其中注释: @Before 表示在执行测试方法前进行执行
init()方法
@Before //在执行测试方法前进行执行
public void init(){
try {
//1.读取配置文件获取字节输入流
in = Resources.getResourceAsStream("SqlMapConfig.xml");
//2.获取SqlSessionFactor工厂
SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder();
SqlSessionFactory build = builder.build(in);
session = build.openSession();
//3.获取代理对象
mapper = session.getMapper(UserDao.class);
} catch (IOException e) {
e.printStackTrace();
}
}
desroy()方法
注释@After:表示在执行测试方法后进行执行
@After //在执行测试方法后进行执行
public void destroy(){
//事务的提交
session.commit();
//5.释放资源
session.close();
try {
in.close();
} catch (IOException e) {
e.printStackTrace();
}
}
测试方法:findByIdTest() ``
注释@Test :表示单元测试,可以直接运行(注意其中好像单元测试中不能进行控制台输入)
@Test
public void findByIdTest(){
User byId = mapper.findById(1);
System.out.println(byId);
}
测试结果截图:

2. 数据的存储操作
2.1 在持久层UserDao接口中添加saveUser()方法
/**
数据存储操作
*/
public void saveUser(User user)
2.2 在用户的映射配置文件UserDao.xml中配置
#{username}也可以写成#{user.username}:
原因:#{user.username}它会先去找 user 对象,然后在 user 对象中找到 username 属性,并调用 getUsername()方法把值取出来。但是我们在 parameterType 属性上指定了实体类名称,所以可以省略 user. 而直接写 username。
<insert id="saveUser" parameterType="com.kiteYY.domain.User">
insert into user(username,brithday,sex,address)
values (#{username},#{brithday},#{sex},#{address});
</insert>
2.3 在测试类MyBatisTest中新建测试方法:saveUserTest()
saveUserTest()方法
/**
* 测试存用户信息
*/
@Test
public void saveUserTest(){
User user = new User();
user.setUsername("select_insert_id");
user.setAddress("四川");
user.setSex("男");
user.setBrithday(new Date());
mapper.saveUser(user);
}
2.4 拓展知识:可以在插入数据后获得插入数据的id值
因为id我们在数据库中定义为自动增长序列:auto_increment 所以在存储数据时不需要输入id值,所以有了一个需求获取id值
首先在UserDao.xml中数据插入中添加语句:
注释:
keyProperty = “id” :实体类中的
keyColumn=“id” :数据库表中类容
order=“AFTER” :在插入数据后执行
<insert id="saveUser" parameterType="com.kiteYY.domain.User">
-- 获取存入数据后的id值
<selectKey keyProperty="id" keyColumn="id" resultType="Integer" order="AFTER">
select last_insert_id();
</selectKey>
insert into user(username,brithday,sex,address)
values (#{username},#{brithday},#{sex},#{address});
</insert>
UserDaoTest测试方法:
/**
* 测试存用户信息
*/
@Test
public void saveUserTest(){
User user = new User();
user.setUsername("select_insert_id");
user.setAddress("四川");
user.setSex("男");
user.setBrithday(new Date());
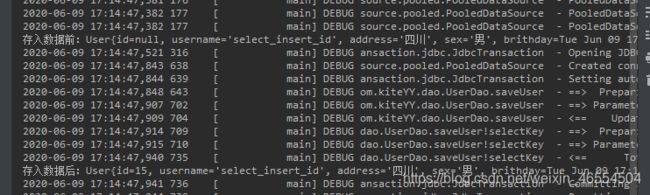
System.out.println("存入数据前:"+user);
//执行保存数据方法
mapper.saveUser(user);
System.out.println("存入数据后:"+user);
}
测试截图:id值由 null变为15
3. 数据的更新操作
3.1 在持久层UserDao接口中添加upDateUser(User user)方法
注意:根据数据的id值为依据修改其他属性值
/**
* 更新数据操作
* @param user
*/
public void upDateUser(User user);
3.2 在用户的映射配置文件UserDao.xml中配置
<update id="upDateUser" parameterType="com.kiteYY.domain.User">
update user set username=#{username},brithday=#{brithday},sex=#{sex},address=#{address} where id=#{id};
</update>
3.3 添加新的测试方法
/**
* 数据更新测试方法
*/
@Test
public void upDateUserTest(){
User user = new User();
user.setId(8);
user.setUsername("updateUser");
user.setAddress("四川");
user.setSex("男");
user.setBrithday(new Date());
mapper.upDateUser(user);
}
运行结果图:哈哈这个可以自己进行输出 或者在 mysql中进行查看
4. 数据的删除操作
4.1 在持久层UserDao接口中添加deleteUser(Integer userId)方法
注意:根据数据的id值进行数据的删除
/**
* 数据的删除功能
* @param userId
*/
public void deleteUser(Integer userId);
4.2 在用户的映射配置文件UserDao.xml中配置
<update id="deleteUser" parameterType="java.lang.Integer">
delete from user where id = #{userId}
</update>
4.3 添加新的测试方法
/**
* 数据删除测试方法
*/
@Test
public void deleteUserIdTest(){
mapper.deleteUser(9);
}
运行结果图:哈哈这个可以自己进行输出 或者在 mysql中进行查看
5. 数据的模糊查询
5.1 在持久层UserDao接口中添加findByName(String userName)方法
注意:根据数据的name值进行模糊的数据查询
/**
* 模糊查询
* @return
*/
List<User> findByName(String userName);
5.2 在用户的映射配置文件UserDao.xml中配置
<select id="findByName" parameterType="java.lang.String" resultType="com.kiteYY.domain.User">
select * from user where username like #{username};
</select>
5.3 添加新的测试方法
@Test
public void findByNameTest(){
List<User> byName = mapper.findByName("%老%");
System.out.println(byName);
}
运行结果图:

注意:
我们在配置文件中没有加入%来作为模糊查询的条件,所以在传入字符串实参时,就需要给定模糊查询的标 识%。配置文件中的#{username}也只是一个占位符,所以 SQL 语句显示为“?”。

6. 数据的删除操作
6.1 在持久层UserDao接口中添加findTotal()方法
/**
* 查询总记录数
* @return
*/
Integer findTotal();
6.2 在用户的映射配置文件UserDao.xml中配置
<select id="findTotal" resultType="Integer">
select count(id) from user;
</select>
6.3 添加新的测试方法
@Test
public void findTotal(){
Integer total = mapper.findTotal();
System.out.println(total);
}
运行结果图:

7. MyBatis与JDBC的比较
1.数据库链接创建、释放频繁造成系统资源浪费从而影响系统性能,如果使用数据库链接池可解决此问题。 解决: 在 SqlMapConfig.xml 中配置数据链接池,使用连接池管理数据库链接。
2.Sql 语句写在代码中造成代码不易维护,实际应用 sql 变化的可能较大,sql 变动需要改变 java 代码。 解决: 将 Sql 语句配置在 XXXXmapper.xml 文件中与 java 代码分离。
3.向sql语句传参数麻烦,因为sql语句的where 条件不一定,可能多也可能少,占位符需要和参数对应。 解决: Mybatis自动将 java 对象映射至 sql 语句,通过 statement 中的 parameterType 定义输入参数的 类型。
4.对结果集解析麻烦,sql 变化导致解析代码变化,且解析前需要遍历,如果能将数据库记录封装成 pojo 对 象解析比较方便。 解决: Mybatis自动将 sql执行结果映射至 java 对象,通过statement中的resultType 定义输出结果的 类型。
8. 在UserDao.xm中定义数据类型的封装操作
(
注意执行前要做的改动
将实体类User中的属性进行更改
id改为userId
username 改为userName
sex改为userSex
address改为userAddress
birthday改为userBirthday
)
resultMap 结果类型 :
resultMap 标签可以建立查询的列名和实体类的属性名称不一致时建立对应关系。从而实现封装。 在 select 标签中使用 resultMap 属性指定引用即可。同时 resultMap 可以实现将查询结果映射为复杂类 型的 pojo,比如在查询结果映射对象中包括 pojo 和 list 实现一对一查询和一对多查询。
8.1 定义resultMap:
注解:
id 标签:用于指定主键字段
result 标签:用于指定非主键字段
column 属性:用于指定数据库列名
property 属性:用于指定实体类属性名称
<!--配置查询结果的列名和实体类的属性名的对应关系-->
<resultMap id="userMap" type="com.kiteYY.domain.User">
<!--主字段名进行对应-->
<id property="userId" column="id"></id>
<!--配置其他非字段名-->
<result property="userName" column="username"></result>
<result property="userBrithday" column="brithday"></result>
<result property="userSex" column="sex"></result>
<result property="userAddress" column="address"></result>
</resultMap>
8.2 映射配置:
<!-- 配置查询所有操作 -->
<select id="findAll" resultMap="userMap">
select * from user
</select>
运行结果图:

上午与下午的学习结果
加油
2020/6/9/17:46