一文搞定并查集
一文搞定并查集
并查集是什么?
并查集是一种树型的数据结构,用于处理一些不相交集合的合并及查询问题,常常在使用中以森林来表示。并查集通常用来解决管理若干元素的分组问题
并查集可以高效完成下列操作 (并与查的功能) :
- 并:合并元素a和元素b所在的组
- 查:查询元素a和元素b是否属于同一组
并查集的结构
并查集使用树形结构形成,实际上可以看作是森林
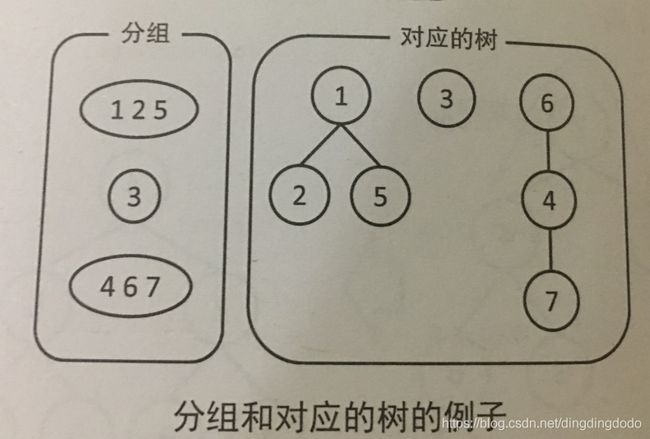
如图所示,我们可以将左侧的分组以右侧的森林的形式表示。其中每个元素对应树中的一个节点,每一个组对应着森林中的一颗树,在并查集中,通常我们不在意父节点与子节点的顺序,实际上树的形状也无关紧要,只需要令同一组的元素对应到同一个树上即可。
并查集的逻辑实现
-
初始化
准备n个节点表示n个元素,在初始化时,彼此之间无关联,即均单独成树
-
合并
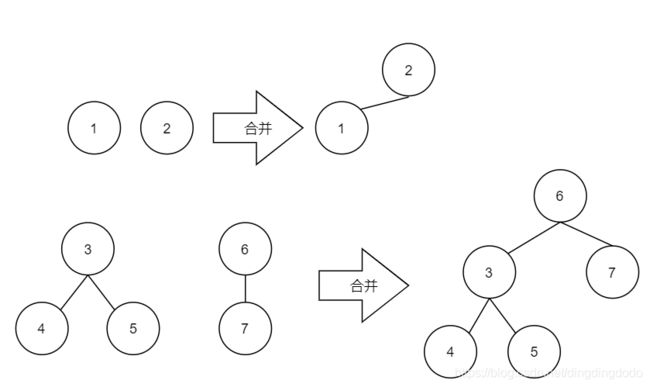
合并即为合并两个树,由于每个树表示一个集合(即相同类别,无顺序之分),故只需要让一个树的根节点指向另一个树即可。合并的例子:
-
查询
查询即查询两个元素是否是同一集合中,即查询对应的两个节点是否在同一个树上,因此只需要查询两个节点所对应的树的根节点是否一致即可。
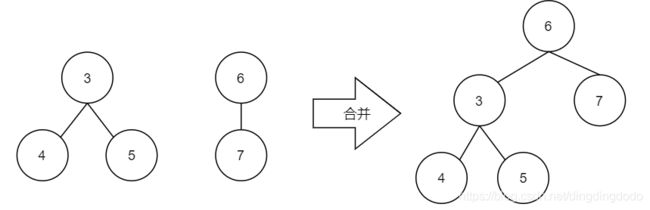
分析该图,在合并前,4对应的根节点是3,而7对应的根节点是6,故不在同一树中,不属于同一集合。当合并后,4对应的根节点是6,7对应的根节点也是6,故二者根节点相同,说明它们在同一集合中。
并查集逻辑实现的优化
主要优化思路为尽可能使树的高度降低,从而尽可能减少查询的时间复杂度
-
当进行合并时,尽可能使高树的根节点作为合并后的根节点。通常方法是记录每个树的高度rank,当合并时,比较两个树的rank,将rank值大的树的根作为合并后的根节点。这样可以避免树的复杂度过高
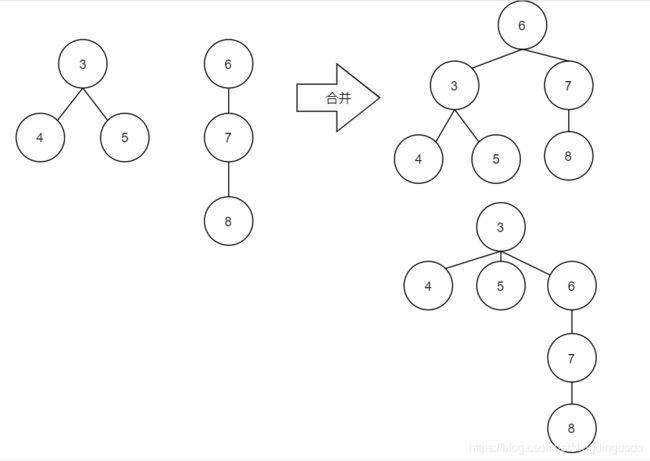
上图是两种合并方式,显然,如果以6为合并后的根节点,则树的高度为3,反之则为4。故当合并时,如果考虑到两个树的高度,将使得最终树的高度尽可能小
-
进行路径压缩,使得并查集更高效。对于每个节点,一旦向上走到了一次根节点,就把这个节点的父亲节点直接指向根节点。即若一个节点的根节点已经计算出,则直接将其指向根节点,尽可能避免重复计算
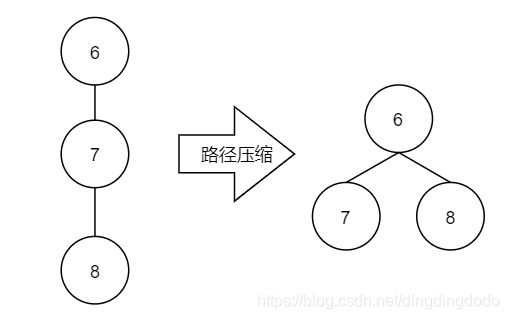
如果已计算得到8的根节点为6,则直接将8指向6即可,从而降低树的高度实际上,由于查询过程是自下而上的,因此可以将查询过程的路径上遇到的所有节点均直接指向最终的根节点,也就意味着实际上每次查询均附带着实现了路径压缩
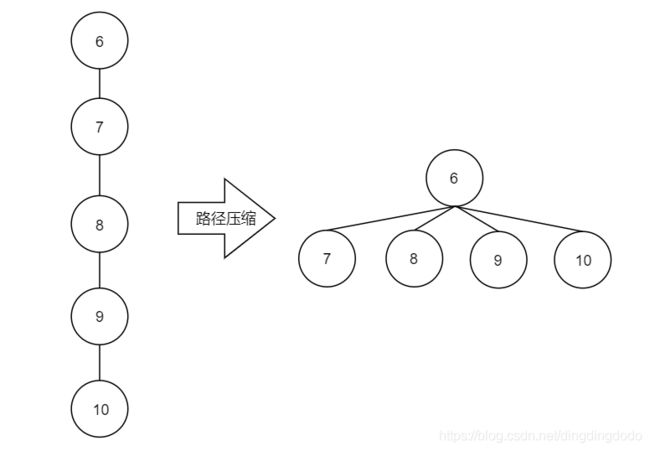
查询节点10的根节点的过程中,实际上将得到节点10、节点9、节点8、节点7对应的树的根节点均为节点 6,因此可以直接将其指向节点6,实现路径压缩。为了简化起见,路径压缩过程通常不去修改树的高度值
并查集的复杂度
易知,进行优化后,并查集的效率将非常高,比O(log n) 还快
并查集的实现(C++)
在并查集的实现过程中,通常我们用一个数组即可实现,数组的下标表示所对应的节点,数组的值代表该节点所在的树的根节点标号
par数组表示节点,存储内容为根节点的序号,rank数组表示树的高度,不需做非常精确的计算
//并查集的实现
#include掌握并查集的实现的几个函数即可轻松应付大多数并查集题目
并查集题目的练习
最近疫情非常严重,在此以 poj 上一个SARS病毒传播的题目为始:
poj 1611
http://poj.org/problem?id=1611
Title :The Suspects
题目描述: 严重急性呼吸道综合症(SARS)是一种病因不明的非典型肺炎,在2003年3月中旬被认为是全球性威胁。为了最大程度地减少向他人的传播,最好的策略是将嫌疑犯与其他人分开 。在一所大学中,有许多学生团体, 同一学生团体中的学生经常互相交流,一个学生可以加入多个学生团体。为了防止可能的SARS传播,该大学收集所有学生团体的成员列表,并在其标准操作程序(SOP)中制定以下规则: 一旦组中的某个成员成为可疑对象,该组中的所有成员都将成为可疑对象。但是,他们发现,当已确认一个学生为可疑对象的情况下,识别出所有可疑对象并不容易。你的工作是编写一个找到所有嫌疑犯的程序
输入: 输入文件包含多种情况:每个测试用例都以一行中的两个整数n和m开头,其中n是学生数,m是组数。您可以假设0
输出:输出对于每种情况的可疑对象数量
分析:根据题目描述,很容易确定出最终的可以对象数量即为与组员0有直接或间接关系的人数,因此采用并查集,根据所给的关系实现集合的分类,然后检测与组员0在同一集合的人数即可
/*
核心题意:组员0有传染病,给出很多人之间的关系,求出和组员0有直接或者间接关系的人数即可
利用并查集,根据每个组员关系建立并查集后,检测是否处于同一类中即可
*/
#includepoj 2524
http://poj.org/problem?id=2524
Title : Ubiquitous Religions
题目描述: 当今世界上有太多不同的宗教,很难一一掌握。你有兴趣找出你所在大学中有多少不同宗教信仰的学生。大学中有n个学生(0
( 0 < = m < = n ( n − 1 ) 2 ) (0<=m<=\frac{n(n-1)}{2}) (0<=m<=2n(n−1))对学生,并询问他们是否信仰同一宗教(例如,他们可能知道他们是否都参加同一宗教)教会)。从这些数据中,您可能不知道每个人的信仰,但是您可以大致了解在校园中可以代表多少种宗教。您可以假设每个学生最多订阅一种宗教 输入: 输入包含多种情况。每种情况都以指定整数n和m的行开头。接下来的m行分别由两个整数i和j组成,指定学生i和j信仰相同的宗教。学生从1到n编号。输入的结尾由其中n = m = 0的行指定
输出:对于每个测试用例,在一行上打印例号(以1开头),然后是大学学生所信奉的不同宗教的最大数量
分析:很显然该题目为并查集的利用,利用数据采用并查集的方式建立森林,森林中树的个数即为宗教的最大数量
/*
分析:共有n个人,m种关系,每种关系意味着彼此属于同一类别,故并查集即可,最终求出不同的根结点的最大值即可得到。
*/
#includeCF771A
https://www.luogu.com.cn/problem/CF771A
贝尔利马克研究社交网络,社交网络的特点是两个成员可以成为朋友。
有n个成员,序号为从1到n。两个成员之间可以是朋友,自己与自己不能是朋友。
让A-B表示A和B成员是朋友。当且仅当满足以下条件时,网络是合理的:对于每三个不同的成员(X,Y,Z),如果X-Y和Y-Z,那么X-Z也应该存在。
例如:如果艾伦和鲍勃是朋友,鲍勃和茜莉是朋友,那么艾伦和茜莉也应该是朋友。
你能帮我查一下网络是否合理吗?相应地打印“是”或“否”输入:n表示成员数,m表示关系数,其中( 3 < = n < = 150000 3<=n<=150000 3<=n<=150000, 0 < = m < = m i n ( 150000 , n ( n − 1 ) 2 ) 0<=m<=min(150000,\frac{n(n-1)}{2}) 0<=m<=min(150000,2n(n−1))),之后为m行数字对, a i , b i a_i,b_i ai,bi 表示二者之间是朋友
输出:YES或NO
分析:该题的一个解决思路为采用并查集,首先将全部人数进行分离,形成一个个小集合,即集合内部的人至少和集合中的其他一个人是朋友。判断网络是否合理时,实际上也就是判断该图是否为完全图,判断完全图的方法:结点为n的完全图,具有 n ( n − 1 ) 2 \frac{n(n-1)}{2} 2n(n−1) 条边
*/
//主要是检验每一个朋友圈是否是每个元素间均互为朋友,即判断是否为完全图
//则利用并查集分类,分别检验每个组是否为完全图(完全图具有特性:节点为n*(n-1)/2)
#includepoj 1182
http://poj.org/problem?id=1182
Title: 食物链
描述:物王国中有三类动物A,B,C,这三类动物的食物链构成了有趣的环形。A吃B, B吃C,C吃A。
现有N个动物,以1-N编号。每个动物都是A,B,C中的一种,但是我们并不知道它到底是哪一种。
有人用两种说法对这N个动物所构成的食物链关系进行描述:
第一种说法是"1 X Y",表示X和Y是同类。
第二种说法是"2 X Y",表示X吃Y。
此人对N个动物,用上述两种说法,一句接一句地说出K句话,这K句话有的是真的,有的是假的。当一句话满足下列三条之一时,
这句就是假话,否则就是真话。
1) 当前的话与前面的某些真的话冲突,就是假话;
2) 当前的话中X或Y比N大,就是假话;
3) 当前的话表示X吃X,就是假话。
你的任务是根据给定的N(1 <= N <= 50,000)和K句话(0 <= K <= 100,000),输出假话的总数输入:第一行是两个整数N和K,以一个空格分隔。
以下K行每行是三个正整数 D,X,Y,两数之间用一个空格隔开,其中D表示说法的种类。
若D=1,则表示X和Y是同类。
若D=2,则表示X吃Y输出:只有一个整数,表示假话的数目
分析:
由于有三种集合A,B,C;故对于每只动物i创建三种关系i-A,i-B,i-C;并用3*N个元素构成并查集。
维护如下: i-x表示"i属于种类x" 并查集中的每一个组内所有元素代表的情况同时发生或者不发生
故对于每一条信息,这样操作即可:
- x和y属于同一种类-----合并x-A和y-A,x-B和y-B,x-C和y-C
- x吃y-----------------合并x-A和y-B,x-B和y-C,x-C和y-A
- 在合并之前,需要判断是否与之前的信息已经矛盾
#include