数据挖掘---银行案例_预测违约概率
数据集及源码 https://download.csdn.net/download/qq_42363032/12643050
文章目录
- Bank数据介绍
- 表关系分析
- 读取并筛选数据
- 1.读取csv文件
- 2.将csv文件的文件名作为Key, 内容作为value,存入到局部变量中
- 3.对贷款表(Loans)的还款状态做词频统计
- 还款状态映射为数值类型
- 4.对贷款表和客户表做连接查询(因为贷款表和客户表没有直接的主外键关系,这里通过权限分配表【Disp】)来连接
- 5.在4.表基础上,再与人口地区统计表 (District)建立连接
- 6.对贷款表(Loans)和交易表 (Trans)做连接
- 7.日期类型转换
- 8.金额类型转换
- 筛选发放贷款日期比交易日期大、发放贷款日期比交易日期加365小
- 9.对发起交易的账户号(account_id)做分组查询,统计账户余额(balance2)的均值和标准差
- 10.在9.的基础上计算变异系数
- 11.对借贷类型(type)做分组查询,统计金额(amount2)总数
- 制作关于借贷类型和金额的数据透视表
- 在上述基础上加上变异系数
- 12.连接以上的表形成最终筛选完的表
- 做变异系数
- 模型建立
- 1.样本随机抽样,建立训练集与测试集
- 2.向前逐步法
- 3.采用向前逐步法进行逻辑回归建模
- 4.模型效果评估
- 5.模型应用---预测
- 6.使用随机森林对上述测试
- 7.随机森林预测
Bank数据介绍
- 截取自一家银行的真实客户与交易数据
- 涉及客户主记录、帐号、交易、业务和信
用卡数据 - 可用于做客户贷款违约预测、客户信用卡
精准营销、客户细分等多中数据挖掘主题
表关系分析
- 一个人可以有多个账户,一个account账户号可以对应有多
个client顾客号,即多个人可以共管一个账户,账户与客户
号的对应关系,在disp中进行列示 - “loan” 和 “credit card” 为银行提供给客户的服务
- 一个账户可以多张信用卡
- 一个账户只能一笔贷款





读取并筛选数据
1.读取csv文件
import pandas as pd
import numpy as np
import os
# 查看当前文件所在路径
os.getcwd()
# 修改当前工作路径
os.chdir(os.getcwd())
# 列出当前路径下的所有文件名称和文件夹名称
loanfile=os.listdir()
print(loanfile)

2.将csv文件的文件名作为Key, 内容作为value,存入到局部变量中
csv文件才是我们从数据库中提取的,是有用的
这里用pandas读取,写入到locals()局部变量中
# 定义一个局部变量,以字典形式存储
createVar=locals()
# 对当前路径下的每个文件循环,判断是否以csv结尾,如果是csv文件,用pandas读取并写入局部变量中,形成key-value的结果
for i in loanfile:
if i.endswith("csv"):
createVar[i.split('.')[0]]=pd.read_csv(i,encoding='gbk')
print(i.split('.')[0])
'''
对健 i.split('.')[0] 的解释:
i = 'clients.csv'
i.split('.')
['clients', 'csv']
'''
此时内存中已经存在一个字典,盛放的就是以csv文件名为Key的,各自内容为value
# print(clients.head())

查看客户信息表(Clients)的前五行
print(clients.head())
# jupyter直接可以clients.head()

3.对贷款表(Loans)的还款状态做词频统计
loans.status.value_counts()
# loans['status'].value_counts()
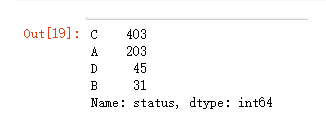
A:代表合同终止,没有问题
B:代表合同终止,贷款没有支付
C:代表合同处于执行期,至今正常
D:代表合同处于执行期,欠债状态
还款状态映射为数值类型
bad_good={'B':1, 'D':1, 'A':0, 'C': 2}
loans['bad_good']=loans.status.map(bad_good) # 新增一列
loans.head()

4.对贷款表和客户表做连接查询(因为贷款表和客户表没有直接的主外键关系,这里通过权限分配表【Disp】)来连接
# 对贷款表(Loans)和 权限分配表(Disp)做连接查询,通过account_id连接,how='left' 左外连接
data2=pd.merge(loans,disp,on='account_id',how='left') # on:通过连接的列索引名称
# 在通过client_id和客户信息表(Clients)连接
data2=pd.merge(data2,clients,on='client_id',how='left')
# 筛选出客户权限是“所有者”的,因为只有“所有者”身份才可以进行增值业务操作和贷款
data2=data2[data2.type=='所有者']
data2.head()

5.在4.表基础上,再与人口地区统计表 (District)建立连接
# 与人口地区统计表 (District)建立连接 left_on:根据左表的行索引 right_on:右标的行索引 左连接
data3 = pd.merge(data2, district, left_on = 'district_id', right_on = 'A1', how = 'left')
data3.head()

6.对贷款表(Loans)和交易表 (Trans)做连接
只取贷款表的账户号(account_id)、发放贷款日期(date)
交易表的账户号(account_id)、贷款类型(type)、金额(amount)、账户余额(balance)、交易日期(date)
data_4temp1=pd.merge(loans[['account_id','date']],trans[['account_id','type','amount','balance','date']],on='account_id') # 默认内连接
data_4temp1.columns=['account_id','date','type','amount','balance','t_date'] # 修改新表的列名
data_4temp1.head()

对account_id和t_date(交易表)排一下序
data_4temp1=data_4temp1.sort_values(by=['account_id','t_date'])
data_4temp1.head()

看一下详细信息
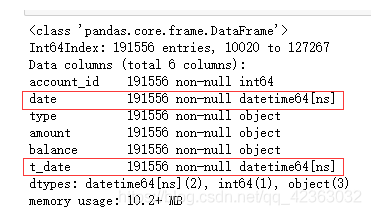
data_4temp1.info()

这里我们可以看到,两个时间类型的都是object,我们需要转换成datetime,才方便进行时间的筛选

7.日期类型转换
data_4temp1['date']=pd.to_datetime(data_4temp1['date'])
data_4temp1['t_date']=pd.to_datetime(data_4temp1['t_date'])
data_4temp1.info()
8.金额类型转换

此时金额类型为Object类型,我们需要转换成int类型,方便处理
# 对balance列做数值映射
data_4temp1['balance2'] = data_4temp1['balance'].map(
lambda x: int(''.join(x[1:].split(','))))
# 对amount列做数值映射
data_4temp1['amount2'] = data_4temp1['amount'].map(
lambda x: int(''.join(x[1:].split(','))))
data_4temp1.head()

筛选发放贷款日期比交易日期大、发放贷款日期比交易日期加365小
import datetime
# 筛选发放贷款日期比交易日期大、发放贷款日期比交易日期加365小
data_4temp2=data_4temp1[data_4temp1.date>data_4temp1.t_date][data_4temp1.date<data_4temp1.t_date+datetime.timedelta(days=365)]
data_4temp2.head()

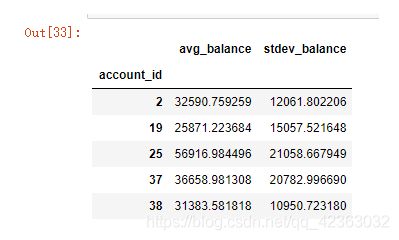
9.对发起交易的账户号(account_id)做分组查询,统计账户余额(balance2)的均值和标准差
data_4temp3=data_4temp2.groupby('account_id')['balance2'].agg([('avg_balance','mean'),('stdev_balance','std')])
data_4temp3.head()
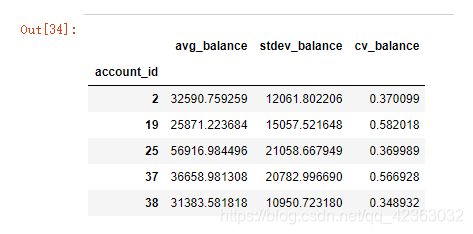
10.在9.的基础上计算变异系数
变异系数,消除量纲、越小越好越稳定
data_4temp3['cv_balance']=data_4temp3[['avg_balance','stdev_balance']].apply(lambda x:x[1]/x[0],axis=1)
data_4temp3.head()
11.对借贷类型(type)做分组查询,统计金额(amount2)总数
type_dict={'借':'out','贷':'income'}
data_4temp2['type1']=data_4temp2.type.map(type_dict)
data_4temp4=data_4temp2.groupby(['account_id','type1'])[['amount2']].sum()
data_4temp4.head(2)

制作关于借贷类型和金额的数据透视表
pd.pivot_table(index='account_id',columns='type1',values='amount2',aggfunc='sum',data=data_4temp2).head()

在上述基础上加上变异系数
data_4temp5=pd.pivot_table(data_4temp4,values='amount2',index='account_id',columns='type1')
data_4temp5.fillna(0,inplace=True)
data_4temp5['r_out_in']=data_4temp5[['out','income']].apply(lambda x:x[0]/x[1],axis=1)
data_4temp5.head(2)

12.连接以上的表形成最终筛选完的表
data4=pd.merge(data3,data_4temp3,left_on='account_id',right_index=True,how='left')
data4=pd.merge(data4,data_4temp5,left_on='account_id',right_index=True,how='left')
data4

做变异系数
data4['r_lb']=data4[['amount','avg_balance']].apply(lambda x:x[0]/x[1],axis=1)
data4['r_lincome']=data4[['amount','income']].apply(lambda x:x[0]/x[1],axis=1)
data4.head(10)

模型建立
1.样本随机抽样,建立训练集与测试集
data_model=data4[data4.status!='C']
for_predict=data4[data4.status=='C']
train=data_model.sample(frac=0.7,random_state=1235).copy()
test=data_model[~data_model.index.isin(train.index)].copy() # ~取非,不在这里面
print('训练集样本量:%i\n测试集样本量:%i'%(len(train),len(test)))
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wTGxJ31y-1595244241407)(473051ED1A0D4D259E8E78C5F0020C1F)]](http://img.e-com-net.com/image/info8/3abb3ff50f2346109e9bb18423d20eed.png)
2.向前逐步法
import statsmodels.formula.api as smf
import statsmodels.api as sm
def forward_select(data, response):
import statsmodels.api as sm
import statsmodels.formula.api as smf
remaining = set(data.columns)
remaining.remove(response)
selected = []
current_score, best_new_score = float('inf'), float('inf')
while remaining:
aic_with_candidates=[]
for candidate in remaining:
formula = "{} ~ {}".format(
response,' + '.join(selected + [candidate]))
aic = smf.glm(
formula=formula, data=data,
family=sm.families.Binomial(sm.families.links.logit)
).fit().aic
aic_with_candidates.append((aic, candidate))
aic_with_candidates.sort(reverse=True)
best_new_score, best_candidate=aic_with_candidates.pop()
if current_score > best_new_score:
remaining.remove(best_candidate)
selected.append(best_candidate)
current_score = best_new_score
print ('aic is {},continuing!'.format(current_score))
else:
print ('forward selection over!')
break
formula = "{} ~ {} ".format(response,' + '.join(selected))
print('final formula is {}'.format(formula))
model = smf.glm(
formula=formula, data=data,
family=sm.families.Binomial(sm.families.links.logit)
).fit()
return(model)
3.采用向前逐步法进行逻辑回归建模
candidates=['bad_good','A1','GDP','A4','A10','A11','A12','amount','duration','A13','A14','A15','a16','avg_balance','stdev_balance','cv_balance','income','out','r_out_in','r_lb','r_lincome']
data_for_select=train[candidates]
lg_m1=forward_select(data=data_for_select,response='bad_good')
lg_m1.summary().tables[1]
4.模型效果评估
import sklearn.metrics as metrics
import matplotlib.pyplot as plt
fpr, tpr, th = metrics.roc_curve(test.bad_good, lg_m1.predict(test))
plt.figure(figsize=[6, 6])
plt.plot(fpr, tpr, 'b--')
plt.title('ROC curve')
plt.show()
print('AUC = %.4f' %metrics.auc(fpr, tpr))
5.模型应用—预测
for_predict['prob']=lg_m1.predict(for_predict)
for_predict['label'] = for_predict['prob'].map(lambda x:1 if x > 0.5 else 0)
for_predict[['account_id','prob','label']].head()
6.使用随机森林对上述测试
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier()
train = train.dropna()
features=['A1','GDP','A4','A10','A11','A12','amount','duration','A13','A14','A15','a16','avg_balance','stdev_balance','cv_balance','income','out','r_out_in','r_lb','r_lincome']
target = 'bad_good'
trainx = train[features]
trainy = train[target]
clf.fit(trainx,trainy)
clf.score(trainx,trainy)
tmp = pd.DataFrame()
tmp['features'] = features
tmp['weights'] = clf.feature_importances_ # 特征重要性
tmp

7.随机森林预测
data4 = data4.dropna()
data_model=data4[data4.status!='C']
for_predict=data4[data4.status=='C']
train=data_model.sample(frac=0.7,random_state=1235).copy()
test=data_model[~data_model.index.isin(train.index)].copy()
print('训练集样本量:%i\n测试集样本量:%i'%(len(train),len(test)))
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GBlwyJCq-1595244241411)(0CC8D44C188D4659AB56DB3E185B420D)]](http://img.e-com-net.com/image/info8/a3ba2ab4a00f40d2b93526cd1e6023bd.png)
model = RandomForestClassifier()
trainx = train[['cv_balance','r_lb']]
testx = test[['cv_balance','r_lb']]
trainy = train[target]
testy = test[target]
model.fit(trainx,trainy)
import sklearn.metrics as metrics
import matplotlib.pyplot as plt
fpr, tpr, th = metrics.roc_curve(testy, model.predict(testx))
plt.figure(figsize=[6, 6])
plt.plot(fpr, tpr, 'b--')
plt.title('ROC curve')
plt.show()
print('AUC = %.4f' %metrics.auc(fpr, tpr))
