目录
一, 索引与B树介绍
1. B树 ,B+树 ,B*树
2. 聚集索引
3. 辅助索引
3.1 普通辅助索引
3.2 覆盖辅助索引
4. 唯一索引
二. 索引管理命令
1. 索引的增删查(重点*******)
2. 查看执行计划explain(desc)
三. 不走索引的情况(开发规范, 重点*******)
四. 建立索引的原则(运维规范)
=======================================================================.
建索引与不建索引, 在数据量50w条时, 性能差距近1w倍, 亲测
https://www.jianshu.com/p/7939a78e9088
=======================================================================
一, 索引与B树介绍
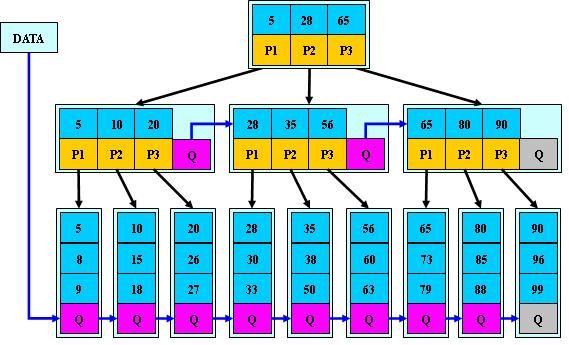
1. B树 ,B+树 ,B*树:
如图(蓝色部分先不看):
第一排为根节点, 蓝色部分存的是下面一个子节点存储的最小值, 黄色为对应子节点的指针
第二排为子节点(可能有多个子节点), 蓝色部分存的是下面数据页存储的最小值, 黄色为对应数据页的指针
第三排为数据页存的是正正的数据,
每一个框规定存的大小为16K, 索引存的数据越多, 子节点就越多, 树就越高. 对应的性能就会变差
举例: 查找数字 63
1. 在根节点找, 63在28-65之间, 进入p2节点
2. 63比56大,进入p3数据页
3. 找到63
这就是B树(把图中蓝色部分不看就是)
如果要查找大于63的数字怎么办? 在每个数据页中存入旁边的指针, 这样就可以在数据页上直接跳转了, 这就是B+树
在子节点存旁边的指针叫B树*
2. 聚集索引:
基于主键,自动生成的,一般是建表时创建主键.如果没有主键,自动选择唯一键做为聚集索引
在图中, 将数字改为表的主键的值, 根节点与子节点只存主键的值, 数据页上存主键的值与对应的一条记录
根据主键查询的时候效率会大大提高
如果业务中很少根据主键 , 而是根据其他字段查的最多呢, 例如name?
这就需要用到辅助索引了
3. 辅助索引:
人为创建的(普通,覆盖)
3.1 普通辅助索引:
将表的某个字段设为索引, 图中的数字就替换为这个字段的值, 数据页中存的是这个字段的值与对应的主键, 根据这个字段的某个值, 找到对应的主键, 再去聚集索引拿到数据(这一步叫回表)
例如根据name字段找到一条数据, 就可以将name字段设为辅助索引
如果数据页中除了主键还存了其他值呢, 那就不需要再去回表了, 这就是覆盖辅助索引了
3.2 覆盖辅助索引:
如果需要根据name字段拿到phone与sex的值, 可以将sex, phone一并存到数据页中, 这样就不用回表了
4. 唯一索引:
人为创建(普通索引,聚集索引)
二. 索引管理命令
1. 索引键(key),表中的某个列
1. 辅助索引(BTREE)
怎么生成的:
根据创建索引时,指定的列的值,进行排序后,存储的叶子节点中
好处:
1.优化了查询,减少cpu mem IO消耗
2.减少的文件排序
创建普通辅助索引(MUL)
# 给表blog_userinfo的email字段添加索引
alter table blog_userinfo add key idx_email(email);
# 给表blog_userinfo的phone字段添加索引
create index idx_phone on blog_userinfo(phone);
查看索引
desc blog_userinfo;
show index from blog_userinfo;
删除索引
alter table blog_userinfo drop index idx_email;
drop index idx_phone on blog_userinfo;
2. 前缀索引:
有时候需要用很长的字符串作为索引, 这会让索引变得大且慢, 通常可以索引开始的部分字符,这样可以大大节约索引空间,从而提高索引效率。
# 查看password字段的前20个字符是否重复
select count(*),substring(password,1,20) as sbp from blog_userinfo group by sbp;
# 将password前10个字符设为索引
alter table blog_userinfo add index idx(password(10));
3. 唯一键索引(UNI,如果有重复值是创建不了的)
alter table blog_userinfo add unique key uni_email(email);
4. 覆盖索引(联合索引)
作用:不需要回表查询,不需要聚集索引,所有查询的数据都从辅助索引中获取
alter table t1 add index idx_gam(gender,age,money);
当where gender age money 这三个条件时, 效率就会变得很高
注意, 设索引时的字段顺序与where条件的字段顺序, 最好一样,
第一个条件不一样就不走索引
第二个条件不一样效率就会降低
好处:
减少回表查询的几率
2. 查看执行计划explain(desc)
在需要执行的select语句前面加上 explain 或者 desc
返回的结果字段分析
type字段: 索引类型
值(性能从上往下为越来越高):
ALL:全表扫描
例如: select * from t1;
Index:全索引扫描
例如: select 索引字段 from city ;
range:索引范围扫描
例如: 在where中用了 > < >= <= in or between and like 'CH%'
ref:辅助索引的等值查询
select * from city where 辅助索引字段='XXX'
eq_ref: 多表链接查询(join on )
const ,system :主键或唯一键等值查询
Extra字段:额外信息
using filesort: 文件排序
将order by , group by , distinct 后的列和where条件列建立联合索引
注意, 必须将where条件里的字段放在前面
possible_keys: 可能会走的索引
key: 真正走的索引
三. 不走索引的情况(开发规范)
1. 重点关注
-
没有查询条件,或者查询条件没有建立索引
select * from tab; 全表扫描。 select * from tab where 1=1; 改为: select * from tab where id=1; -
查询结果集是原表中的大部分数据
查询的结果集,超过了总数行数25%,优化器觉得就没有必要走索引了。
假如: tab表有数据100w条, id有索引,要查后50w条, select * from tab where id>500000; 改为: select * from city where id > 500000 and id < 600000 union all select * from city where id >= 600000 and id < 700000 union all select * from city where id >= 700000 and id < 700000 ...; -
索引本身失效,统计数据不真实
索引有自我维护的能力。
对于表内容变化比较频繁的情况下,有可能会出现索引失效。 -
查询条件使用函数在索引列上,或者对索引列进行运算,运算包括(+,-,*,/,! 等), 子查询
错误的例子:select * from test where id-1=9; 正确的例子:select * from test where id=10; 隐式转换
导致索引失效.这一点应当引起重视.也是开发中经常会犯的错误.
t1表的telnum字段为char类型
错误的例子: select * from t1 where telnum=110;
改正: select * from t1 where telnum='110';
原因, 用数字110去查,其实使用了函数将数字转为字符串
<> ,not in , !=不走索引, like "%_" 百分号在最前面不走索引单独引用联合索引里非第一位置的索引列.作为条件查询时不走索引.
四. 建立索引的原则(运维规范)
- 选择唯一性索引
- 经常需要排序、分组和联合操作的字段建立联合索引
- 为常作为where查询条件的字段建立索引
- 尽量使用前缀来索引
- 限制索引的数目, 尽量的少
- 索引维护要避开业务繁忙期