
本文为 AI 研习社编译的技术博客,原标题 :
Image Generator - Drawing Cartoons with Generative Adversarial Networks
作者 |* Greg Surma*
翻译 | GAOLILI
校对 | 酱番梨 审核 | 约翰逊 · 李加薪 整理 | 立鱼王
原文链接:
https://towardsdatascience.com/image-generator-drawing-cartoons-with-generative-adversarial-networks-45e814ca9b6b

在今天的文章里,我们将实现一个机器学习模型。这个模型可以基于给定的数据集生成无数的相似图像样本。为了实现这个目标,我们将启动生成对抗网络(GANs)并且将包含有“辛普森家族”图像特征的数据作为输入。在这篇文章的最后,你将会熟悉GANs背后的基础知识,而且你也可以建立一个你自己的生成模型。
为了更好的理解GANs的功能,看一下下面的辛普森家族训练过程中的变化。
很神奇是不是?
让我们研究一些理论来更好的理解它实际上是如何工作的。
** 生成对抗网络(GANs)**
让我们通过定义一下我们要解决的问题来开启GAN之旅吧。
我们提供一组图像作为输入,基于输入会生成样本作为输出。
Input Images -> GAN -> Output Samples
根据以上的问题定义,GANs就属于无监督学习,因为我们没有输入任何专家知识(比如分类任务中的样本标注)给模型。
基于给定的数据集,不用任何的人为监督就生成样本听起来非常的有前途。
让我们弄明白GANs是如何让这成为可能的!
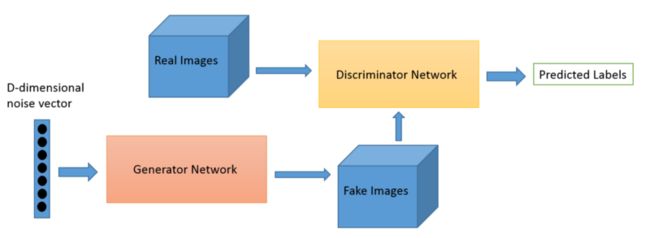
GAN背后潜在的原理就是在一个零和博弈的框架里包含了两个彼此相互对抗的神经网络,即生成器和鉴别器。
生成器
生成器将随机噪声作为输入,并生成样本作为输出。它的目标是生成实际上看起来是假的,但会让判别器认为是真实图像的样本。我们可以将生成器视为一个造假者。
判别器
判别器接收从输入数据集来的真实图像和生成器来的造假图像,并判断出这个图像是真实的还是伪造的。我们可以将判别器看作是一个警察在抓住一个坏人,并放走好人。
极小极大表示
如果我们再一次思考一下判别器和生成器的目标,我们就可以看到它们是互相对立的。判别器判别成功了那么生成器就是生成失败了,反之亦然。这就是为什么我们将GANs框架表示为极小极大游戏框架而不是优化问题的原因。


GANs被设计成达到了一种纳什均衡,在这种博弈中每一个玩家都不能在不改变另一个玩家的情况下降低他们的成本。
对于熟悉博弈论和极小极大算法的人,这个想法看起来很好理解。对于不熟悉的人,我建议你们去看看我之前的讲极小极大算法基础的文章。
数据流和反向传播
尽管极小极大表示两种对抗网络相互对抗看起来很合理,但是我们依然不知道如何让它们自我改进,最终将随机噪声转变成一个逼真图像。


让我们从判别器开始吧。
判别器接收真实的图像和伪造的图像并且试图给出它们的真假。我们作为系统的设计者是知道它们是真实的数据集还是生成器生成的伪造图的。因此我们可以利用这个信息相应地去标注它们,并且执行一个分类的反向传播来允许判别器反复学习,让它更好的辨别图像的真伪。如果判别器正确的将伪造图分类为伪造图,真实图分类为真实图,我们就以损失梯度的方式给它一个正的反馈。如果它判别失败,就给它一个负反馈。这个机制会让判别器更好的进行学习。
现在让我们转到生成器。
生成器将随机噪声作为输入,将样本输出来欺骗判别器让它认为那是一个真实的图像。一旦生成器的输出经过判别器,我们就能知道判别器判断出了那是一个真实图像或者是一个伪造图像。我们可以将这个信息传给生成器并且再一次反向传播。如果判别器将生成器的输出判断为真实的,那么这就意味着生成器的表现是好的并且应该被奖励。另一方面,如果判别器判断出那是一个伪造的,那么生成器就生成失败了,会给它一个负反馈作为惩罚。
如果你仔细想一下,你将会发现通过上面的方法,我们结合博弈理论、监督学习和一点的强化学习解决了无监督学习问题。
GAN的数据流可以被表示成下面的流程图。
和一些基础数学。

我希望你不要被上面的公式吓到了,它们将会变的非常容易理解,因为我们将要开始真正的GAN的实现了。
** 图像生成器(DCGAN) **
一如既往,你可以在GitHub上找到图像生成器的完整代码库。所有的东西都在一个单独的Jupyter notebook文件里,你可以运行在你想使用的平台上。关于数据集更多的信息你可以点击阅读原文来查看这个文件,我建议你去看一下并且按着这个来。
由于我们需要处理图像数据,我们就不得不寻找一个能更有效表示它的方法。这可以被DCGAN实现,即深度卷积生成对抗网络。
模型
在我们的项目里,我们使用了由Radford 等人在2015年提出的经过充分测试的模型结构,如下图所示。
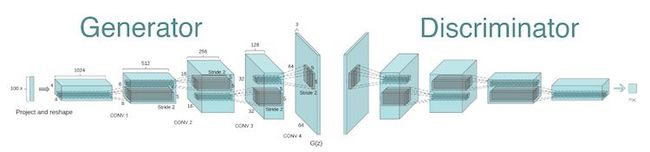
你可以在这里的判别器和生成器函数里找到我们在Tensorflow上对这个模型的实现。
正如你所看见的在上面这个可视化图里,生成器和判别器有着几乎一样的结构,但是是反转的。我们现在不会去深入了解CNN的详细,但是如果你更关心潜在的详细内容,你可以随便去看一下下面这篇文章:
https://towardsdatascience.com/image-classifier-cats-vs-dogs-with-convolutional-neural-networks-cnns-and-google-colabs-4e9af21ae7a8
损失函数
为了让我们的判别器和生成器多次学习,我们需要提供损失函数来让反向传播发生。
def model_loss(input_real, input_z, output_channel_dim):
g_model = generator(input_z, output_channel_dim, True)
noisy_input_real = input_real + tf.random_normal(shape=tf.shape(input_real),
mean=0.0,
stddev=random.uniform(0.0, 0.1),
dtype=tf.float32)
d_model_real, d_logits_real = discriminator(noisy_input_real, reuse=False)
d_model_fake, d_logits_fake = discriminator(g_model, reuse=True)
d_loss_real = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_real,
labels=tf.ones_like(d_model_real)*random.uniform(0.9, 1.0)))
d_loss_fake = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_fake,
labels=tf.zeros_like(d_model_fake)))
d_loss = tf.reduce_mean(0.5 * (d_loss_real + d_loss_fake))
g_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_fake,
labels=tf.ones_like(d_model_fake)))
return d_loss, g_loss
虽然上面的损失声明和前一章的理论解释一致,但你可能会注意到两件事:
在第四行高斯噪声被加入到了真实图像的输入里。
在第十二行对被判别器识别出来的真实图像进行了单边标注平滑。
你将会发现训练GANs是相当的难,因为这里有两个损失函数(生成器的和判别器的),而且在它们之间找到一个平衡是得到好的结果的关键。
由于实际中判别器比生成器更大是非常常见的,因此有时我们需要去减小判别器,我们正在通过上面的修改来实现它。后续我们将介绍其他的实现平衡的技巧。
优化
我们使用下面的Adam优化算法来实现我们模型的优化。
def model_optimizers(d_loss, g_loss):
t_vars = tf.trainable_variables()
g_vars = [var for var in t_vars if var.name.startswith("generator")]
d_vars = [var for var in t_vars if var.name.startswith("discriminator")]
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
gen_updates = [op for op in update_ops if op.name.startswith('generator')]
with tf.control_dependencies(gen_updates):
d_train_opt = tf.train.AdamOptimizer(learning_rate=LR_D, beta1=BETA1).minimize(d_loss, var_list=d_vars)
g_train_opt = tf.train.AdamOptimizer(learning_rate=LR_G, beta1=BETA1).minimize(g_loss,var_list=g_vars)
return d_train_opt, g_train_optt
和损失函数的声明类似,我们还可以使用适当的学习率来平衡判别器和生成器。
LR_D = 0.00004LR_G = 0.0004BETA1 = 0.5
由于上面的超参数是特定于用例的,所以请去调整它们,不要犹豫。但也要记住GANs对学习率的改变是非常敏感的,因此请非常小心的进行微调。
训练
终于,我们可以开始训练了。
def train(get_batches, data_shape, checkpoint_to_load=None):
input_images, input_z, lr_G, lr_D = model_inputs(data_shape[1:], NOISE_SIZE)
d_loss, g_loss = model_loss(input_images, input_z, data_shape[3])
d_opt, g_opt = model_optimizers(d_loss, g_loss)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
epoch = 0
iteration = 0
d_losses = []
g_losses = []
for epoch in range(EPOCHS):
epoch += 1
start_time = time.time()
for batch_images in get_batches:
iteration += 1
batch_z = np.random.uniform(-1, 1, size=(BATCH_SIZE, NOISE_SIZE))
_ = sess.run(d_opt, feed_dict={input_images: batch_images, input_z: batch_z, lr_D: LR_D})
_ = sess.run(g_opt, feed_dict={input_images: batch_images, input_z: batch_z, lr_G: LR_G})
d_losses.append(d_loss.eval({input_z: batch_z, input_images: batch_images}))
g_losses.append(g_loss.eval({input_z: batch_z}))
summarize_epoch(epoch, time.time()-start_time, sess, d_losses, g_losses, input_z, data_shape)
上面的函数包含了标准的机器学习训练方案。将我们的数据集划分成特定大小的批次,给定一个训练次数就开始执行训练了。
核心的训练部分是第22到23行训练判别器和生成器的部分。和损失函数、学习率一样,这里也是一个可以平衡判别器和生成器的地方。一些研究者发现调整判别器和生成器之间的训练运行比率对结果也有好处。在我的项目里1:1的比率是表现最好的,但也能随意使用它。
此外,我还使用了以下的超参数,但是它们不是一成不变的,你可以大胆的去进行修改。
IMAGE_SIZE = 128NOISE_SIZE = 100BATCH_SIZE = 64EPOCHS = 300
经常观察模型的损失函数和它的表现是非常重要的。我建议每一个批次就做一次观察,就像上面的代码段里的。我们来看一下训练过程中产生的一些样本。
我们可以清晰地看到我们的模型越来越好并且在学着如何产生更加逼真的辛普森。
让我们关注主角,家里的男主人,Homer辛普森(也有的叫荷马)。









最后的结果
最终,在NVIDIA P100(谷歌云)上经过8个小时300个批次的训练,我们可以看到我们人为的生成的辛普森一家真正开始看起来像是真实的了!看一下下面选出来的一些比较好的样本。

正如所料,也有一些看起来比较有趣的异常的脸。

接下来呢?
尽管GAN图象生成被证明非常成功,但是这并不是生成对抗网络唯一可能的应用。比如可以看一下下面利用CycleGAN实现的图像到图像的转变。
是不是很神奇?
我建议你可以深入的了解一下GANs这个领域,因为那里还有很多可以探索!
别忘了去github上看看这个项目:
https://github.com/gsurma/image_generator
想要继续查看该篇文章相关链接和参考文献?
点击[图像生成器——用GAN生成辛普森家族](https://ai.yanxishe.com/page/TextTranslation/1527
?from=jianshu)或长按下方地址:
https://ai.yanxishe.com/page/TextTranslation/1527?from=jianshu
AI研习社今日推荐:
李飞飞主讲王牌课程,计算机视觉的深化课程,神经网络在计算机视觉领域的应用,涵盖图像分类、定位、检测等视觉识别任务,以及其在搜索、图像理解、应用、地图绘制、医学、无人驾驶飞机和自动驾驶汽车领域的前沿应用。
加入小组免费观看视频:https://ai.yanxishe.com/page/groupDetail/19?from=jianshu
