机器学习->推荐系统->userCF算法
一:
推荐系统任务:联系用户和信息,一方面帮助用户发现对自己有价值的信息,另一方面让信息能够展现在对它感兴趣的用户面前,从而实现信息消费者和信息生产中的双赢。
长尾理论:传统80/20(%80销售额来自于20%热门商品)原则在互联网加入下受到挑战。长尾商品销售额是个不容小觑的数字,也许会超过热门商品带来的销售额。热门商品代表绝大多数用户需求,而长尾商品代表一小部分用户个性化需求。因此要发掘长尾以提高销售,就必须充分研究用户兴趣。
社会化推荐:通过社交关系来获得推荐。
基于内容的推荐:例如通过演员获取电影。
基于协同过滤:通过排行榜。
个性化推荐成功两个条件:①存在信息过载②用户大部分时候没有特别明确的需求。
推荐系统评测:什么是好的推荐系统?一个推荐系统一般有三个参与方:用户,物品提供者,提供推荐系统的网址。首先推荐系统要满足用户需求,给用户推荐他们感兴趣的物品;其次推荐系统要让各个物品能够被推荐给感兴趣的用户,而不是只推荐几个热门的物品;推荐系统本身能够收集高质量的用户反馈,不断完善推荐质量。因此评测一个推荐系统,需要同时考虑三方利益,一个好的推荐系统能够令三方共赢。
推荐系统实验方法:
1离线方法:从实际系统日志中提取数据,划分训练集测试集训练模型。
优点:不需要有对实际系统控制权,不需要用户参与,速度快,可测试大量算法
缺点:无法计算商业上关心指标。离线实验指标和商业指标存在差距。
2:用户调查:即直接询问用户。优点:可用获取很多体现用户主观感受指标,缺点招募用户代价较大很难组织大规模测试用户,因此测试结果统计意义不大。
3:在线实验:推荐系统上线做AB测试,将它和旧的算法进行比较。(用户分组,不同组采用不同算法).
优点:公平获取不同算法实际在线时性能指标包括商业上关注指标。
缺点:周期长,必须进行长期的实验才能得到比较靠谱的结果。
评测标准:
1.用户满意度
用户调查或者在线实验获得。
2.预测准确度
在离线数据集,划分训练集和测试集,通过在训练集上建立用户行为和兴趣模型,预测用户在测试集上行为,并计算预测行为和测试集上实际行为重合度作为预测准确度。
①:评分预测:一般通过均方根误差(RMSE)和平均绝对误差(MAE)计算
RMSE:
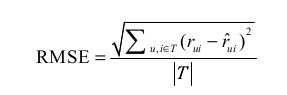
MAE:

import math
def RMSE(records):
return math.sqrt(sum([(rui-pui)*(rui-pui) for u,i,rui,pui in records]))/float(len(records))
def MAE(records):
return sum([math.fabs(rui-pui) for u,i,rui,pui in records])/float(len(records))②:TopN推荐:网站提供推荐服务时,一般是给用户一个个性化的推荐列表,这个推荐叫做TopN推荐。预测准确度通过准确率和召回率度量。
令R(u)是根据用户在训练集上的行为给用户做出推荐列表,而T(u)是用户在测试集上的行为列表。
召回率定义:
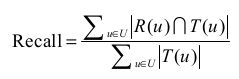
准确率定义为:
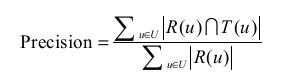
T(u)是实际的行为列表,R(u)是预测的行为列表。
def PrecisionRecall(test,N):
hit=0
n_recall=0
n_precision=0
'''
test.items():user,items测试集中对应用户和对该用户的实际行为列表
rank是该用户预测的行为列表。
'''
for user,items in test.items():
rank=Recommend(user,N)
hit+=len(rank&items)
n_recall+=len(items)
n_precision+=N
return [hit/(1.0*n_recall),hit/(1.0*n_precision)]3:覆盖率
描述一个推荐系统对物品长尾的发掘能力;定义为推荐系统能推荐出来的物品占总物品集合的比例。
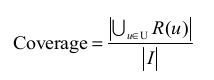
但上面定义过于粗略。覆盖率为100%的推荐系统可以有无数的物品流行度分布。为了更好的发掘长尾能力,需要统计推荐列表中不同物品出现次数的分布。因此可以通过研究物品在推荐列表中出现次数分布描述发掘长尾的能力。有两个指标可以用来定义覆盖率。
①:信息熵:
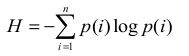
这里p(i)表示物品i流行度除以所有物品流行度之和。
②:基尼系数(Gini Index):
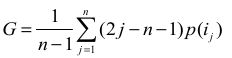
这里ij表示按照物品流行度p()从小到大排序的物品列表中第j个物品。
def Gini_index(p):
j=1
n=len(p)
G=0
for item,weight in sorted(p.items(),key=itemgetter(1)):
G+=(2*j-n-1)*weight
return G/float(n-1)马太效应:强者更强,弱者更弱。判断推荐系统是否有马太效应:如果G1是从初始用户行为中计算出的物品流行度的基尼系数,G2是从推荐列表中计算出的物品流行度的基尼系数,如果G2>G1,就说明推荐算法具有马太效应。
4:多样性
用户兴趣具有多样性,推荐列表比较多样,则覆盖了用户绝大多数兴趣点,那么就会增加用户找到感兴趣物品的概率。
多样性和相似性是对应的。假设
定义了物品i和物品j之间的相似度, 那么用户u的推荐列表的多样性定义如下:

注:R(u)是用户u的推荐列表
推荐系统整体多样性可以定义为所有用户推荐列表多样性的平均值:
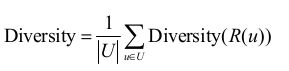
5:新颖性
新颖的推荐是指给用户推荐他们以前没有听说过的物品。,评测新颖性最简单的方法是利用推荐结果的平均流行度,因为越是不热门的物品越有可能令用户感到新颖。
6:惊喜度
如果推荐结果和用户的历史兴趣不相似,但却让用户觉得满意,那么说推荐结果的惊喜度比较高。而推荐的新颖度仅仅取决于用户是否听说过这个推荐结果。
二:
用户行为数据:
最简单的存在形式是日志,这些日志记录了用户各种行为。
显式反馈行为:用户明确表示对物品的喜好行为。
隐式反馈行为:指那些不能明确反应用户喜好的行为。相比显式反馈行为,隐式反馈行为数据量更大。
很多时候我们并不使用统一结构表示所有行为,而是针对不同的行为给出不同表示。
①:无上下文信息的隐性反馈数据集:每一条记录仅仅包含物品ID和用户ID
②:无上下文信息的显性反馈数据集:每一条记录包含物品ID和用户ID和用户对物品评价。
③:有上下文信息的隐形反馈数据集:……….用户对物品产生行为的时间戳。
④:有上下文信息的显性反馈数据集:
用户行为分析:
长尾分布:将一文本中的词按照它们在文本中的出现(或使用)次数由高至低排列,以r表示序号(又称等级),g(r)表示序号为r的词在文本中的出现次数,则r的某一幂次r(β)和g(r)的乘积渐近为一常数,即g(r)*r(β)≈c。即每个单词出现的频率和他在排序的序号的常数次幂成反比。
用户行为数据也蕴含这种规律:物品流行度高的物品在总的物品数里只占少数;活跃度很高的用户只占少数。
用户活跃度和物品流行度关系:用户越活跃,月倾向于浏览冷门的物品。
协同过滤算法:仅仅基于用户行为数据设计的推荐算法。
基于用户的协同过滤算法(userCF):给用户推荐和他兴趣相似的其他用户喜欢的物品。
基于物品的协同过滤算法(itemCF):给用户推荐和他之前喜欢的物品相似的物品。
userCF算法主要包括两个部分:
①:找到和目标用户相似的用户集合
②:找到这个集合中用户喜欢的,且目标用户没有听说过的物品推荐个目标用户。
首先计算两两用户相似度。协同过滤算法主要利用行为的相似度计算兴趣的相似度。给定两个用户u,v,令N(u)表示用户u曾经做出的有过正反馈的物品集合,N(v)表示用户v曾经做出的有过正反馈的物品集合。
可通过余弦相似度计算:
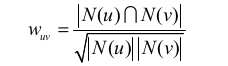
上面用户兴趣相似度计算过于粗略,比如两个用户同样买过热门物品并不代表他们兴趣相似,换句话说只有买过相同的冷门物品才能表示两个用户兴趣相似。故有改进版本的计算相似度:
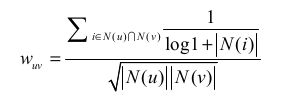
其中N(u)表示与用户u产生过行为的物品列表;N(i)表示与物品i产生过行为的用户列表。
可用看出该公式通过
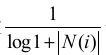
惩罚了用户u和用户v共同兴趣列表中热门物品对他们相似度的影响。
那在实际计算时应该如何计算相似度呢?
首先建立物品到用户的倒排表,一个物品可能有多个用户与其产生过行为,对于每个物品都保存对该物品产生行为用户的列表。假设用户u和用户v同时属于倒排表中K个物品对应的用户列表,那么C[u][v]=k,从而可用扫描倒排表中每个物品对应的用户列表,依次算出C[u][v],最终得到所有用户之间不为0的C[u][v]。
得到用户之间兴趣相似度以后,userCF算法会给用户推荐和他兴趣最相似的k个用户喜欢的物品,如下公式计算用户u对物品i的感兴趣程度:
![]()
其中S(u,K)表示和用户u最为相似的k个用户,N(i)表示和物品i产生行为的用户列表。Wuv表示用户u和用户v的相似度。rvi表示用户v对物品i的兴趣,因为使用的是单一行为的隐反馈,故所有rvi=1.
实战:UserCF算法 实现代码:
数据源
#coding:utf-8
import random
import math
from numpy import *
import csv
import datetime
NumOfUsers=1000
def GetData(datafile='u.data'):
'''
把datafile文件中数据读出来,返回data对象
:param datafile: 数据源文件名称
:return: 一个列表,每一个元素是一个元组(userId,movieId)
'''
data=[]
try:
file=open(datafile)
except:
print ("No such file name"+datafile)
for line in file:
line=line.split('\t')
try:
data.append((int(line[0]),int(line[1])))
except:
pass
file.close()
return data
def SplitData(data,M,k,seed):
'''
划分训练集和测试集
:param data:传入的数据
:param M:测试集占比
:param k:一个任意的数字,用来随机筛选测试集和训练集
:param seed:随机数种子,在seed一样的情况下,其产生的随机数不变
:return:train:训练集 test:测试集,都是字典,key是用户id,value是电影id集合
'''
test=dict()
train=dict()
random.seed(seed)
# 在M次实验里面我们需要相同的随机数种子,这样生成的随机序列是相同的
for user,item in data:
if random.randint(0,M)!=k:
# 相等的概率是1/M,所以M决定了测试集在所有数据中的比例
# 选用不同的k就会选定不同的训练集和测试集
if user not in test.keys():
test[user]=set()
test[user].add(item)
else:
if user not in train.keys():
train[user]=set()
train[user].add(item)
return train,test
def Recall(train,test,N,k):
'''
:param train: 训练集
:param test: 测试集
:param N: TopN推荐中N数目
:param k:
:return:返回召回率
'''
hit=0# 预测准确的数目
totla=0# 所有行为总数
W,relatedusers=ImprovedCosineSimilarity(train)
for user in train.keys():
tu=test[user]
rank=GetRecommendation(user,train,N,k,W,relatedusers)
for item in rank:
if item in tu:
hit+=1
totla+=len(tu)
return hit/(totla*1.0)
def Precision(train,test,N,k):
'''
:param train:
:param test:
:param N:
:param k:
:return:
'''
hit=0
total=0
W, relatedusers = ImprovedCosineSimilarity(train)
for user in train.keys():
tu = test[user]
rank = GetRecommendation(user, train, N, k, W, relatedusers)
for item in rank:
if item in tu:
hit += 1
total += N
return hit / (total * 1.0)
def Coverage(train,test,N,k):
'''
计算覆盖率
:param train:训练集 字典user->items
:param test: 测试机 字典 user->items
:param N: topN推荐中N
:param k:
:return:覆盖率
'''
recommend_items=set()
all_items=set()
W,relatedusers=ImprovedCosineSimilarity(train)
for user in train.keys():
for item in train[user]:
all_items.add(item)
rank=GetRecommendation(user,train,N,k,W,relatedusers)
for item in rank:
recommend_items.add(item)
return len(recommend_items)/(len(all_items)*1.0)
def Popularity(train,test,N,k):
'''
计算平均流行度
:param train:训练集 字典user->items
:param test: 测试机 字典 user->items
:param N: topN推荐中N
:param k:
:return:覆盖率
'''
item_popularity=dict()
W,relatedusers=ImprovedCosineSimilarity(train)
for user,items in train.items():
for item in items:
if item not in item_popularity:
item_popularity[item]=0
item_popularity[item]+=1
ret=0
n=0
for user in train.keys():
rank= GetRecommendation(user, train, N, k, W, relatedusers)
for item in rank:
if item!=0:
ret+=math.log(1+item_popularity[item])
n+=1
ret/=n*1.0
return ret
def CosineSimilarty(train):
'''
计算训练集中每两个用户的余弦相似度
这个函数没有实际价值,复杂度相当高,而且容易Out Of Memory,即在训练集大的时候容易产生内存不足的错误
但是这个函数比较容易看出公式的原型,可以借此理解公式运用
:param train: 训练集,字典user->items
:return: 返回相似度矩阵
'''
W=dict()
print (len(train.keys()))
for u in train.keys():
for v in train.keys():
if u==v:
continue
W[(u,v)]=len(train[u]&train[v])
W[(u,v)]/=math.sqrt(len(train[u])*len(train[v])*1.0)
W[(v,u)]=W[(u,v)]
return W
def ImprovedCosineSimilarity(train):
'''
计算用户相似度
:param train:
:return: 返回用户相似度矩阵W,W[u][v]表示u,v的相似度
:return: 返回相关用户user_relatedusers字典,key为用户id,value为和而用户有共同电影的用户集合。
'''
#建立电影->用户倒排表
item_user=dict()
for u,items in train.items():
for i in items:
if i not in item_user:
item_user[i]=set()
item_user[i].add(u)
#C[u][v] 表示用户u和用户v之间共同喜欢的电影
C=zeros([NumOfUsers,NumOfUsers],dtype=float16)
#N[u]表示u评价的电影数目
N=zeros([NumOfUsers],dtype=int32)
# user_relatedusers[u]表示u的相关用户(共同电影不为零的用户)
user_relatedusers=dict()
# 对于每个电影,把它对应的用户组合C[u][v]加一
for item,users in item_user.items():
for u in users:
N[u]+=1
for v in users:
if u==v:
continue
if u not in user_relatedusers:
user_relatedusers[u]=set()
user_relatedusers[u].add(v)
C[u][v]+=(1/math.log(1+len(users)))
#用户相似度矩阵
W=zeros([NumOfUsers,NumOfUsers],dtype=float16)
for u in range(1,NumOfUsers):
if u in user_relatedusers:
for v in user_relatedusers[u]:
W[u][v]=C[u][v]/sqrt(N[u]*N[v])
return W,user_relatedusers
def Recommend(user,train,W,relatedusers,k,N):
'''
通过相似度矩阵W得到和user相似的rank字典
:param user:用户id
:param train: 训练集
:param W: 相似度矩阵
:param relatedusers:
:param k: 决定了从相似用户中取出多少进行计算
:param N:
:return: rank字典,包含了所有兴趣程度不为0的电影,按照从大到小排序
'''
rank=dict()
for i in range(1,1700):
rank[i]=0# i表示user可能喜欢的电影id,初始兴趣程度为0
k_users=dict()
try:
for v in relatedusers[user]:
k_users[v]=W[user][v]
except KeyError:
print ("User "+str(user)+" doesn't have any related users in train set")
k_users=sorted(k_users.items(),key=lambda x:x[1],reverse=True)
k_users=k_users[0:k]#取前k个用户
for i in range(1700):
for v,wuv in k_users:
if i in train[v] and i not in train[user]:#取出被user相似用户v产生行为的电影,同时user没有和这部电影产生行为
rank[i]+=wuv*1
return sorted(rank.items(),key=lambda d:d[1],reverse=True)
def GetRecommendation(user,train,N,k,W,relatedusers):
'''
获得N个推荐
:param user: 用户
:param train: 训练集
:param W: 相似度矩阵
:param N: 推荐数目N
:param k: 决定了从相似用户中取出多少个进行计算
:return: recommend字典,key是movie id,value是兴趣程度
'''
rank=Recommend(user,train,W,relatedusers,k,N)
recommend=dict()
for i in range(N):
recommend[rank[i][0]]=rank[i][1]
return recommend
def evaluate(train,test,N,k):
##计算一系列评测标准
recommends=dict()
W,relatedusers=ImprovedCosineSimilarity(train)
for user in test:
recommends[user]=GetRecommendation(user,train,N,k,W,relatedusers)
recall=Recall(train,test,N,k)
precision=Precision(train,test,N,k)
coverage=Coverage(train,test,N,k)
popularity=Popularity(train,test,N,k)
return recall,precision,coverage,popularity
def test1():
data=GetData()
train,test=SplitData(data,2,1,1)
del data
user=int(input("Input the user id \n"))
print("The train set contains the movies of the user: ")
print(train[user])
N=int(input("Input the number of recommendations\n"))
k=int(input("Input the number of related users\n"))
starttime=datetime.datetime.now()
W,relatedusers=ImprovedCosineSimilarity(train)
endtime=datetime.datetime.now()
print("it takes ",(endtime-starttime).seconds," seconds to get W")
starttime=datetime.datetime.now()
recommend=GetRecommendation(user,train,N,k,W,relatedusers)
endtime=datetime.datetime.now()
print("it takes ",(endtime-starttime).seconds," seconds to get recommend for one user")
W,relatedusers=ImprovedCosineSimilarity(train)
recommend=GetRecommendation(user,train,N,k,W,relatedusers)
print(recommend)
for item in recommend:
print(item),
if(item in test[user]):
print(" True")
else:
print(" False")
def test2():
N=int(input("Input the number of recommendations: \n"))
k=int(input("Input the number of related users: \n"))
data = GetData()
train, test = SplitData(data, 2, 1, 1)
del data
recall,precision,coverage,popularity=evaluate(train,test,N,k)
print("Recall: ",recall)
print("Precision: ",precision)
print("Coverage: ",coverage)
print("Popularity: ",popularity)
if __name__=='__main__':
test2()